






我们在了解一个靶点信息的时候,通常会全面了解该靶点的生物学特性(功能、名称分类、亚细胞位置)、与疾病关系(特定疾病关联及疾病作用)、序列(蛋白质序列、基因序列等)、相互作用(结合常数、类型)、表达、通路(位置、作用)及对应药物研发(代谢、药代动力学、不良反应、全球同靶点新药研发信息、适应症和企业在各研发阶段的药物数量)等相关信息,使之选择出更具潜力价值的靶点研究方向,提升药物研发的可行性及成功概率。
而在探索查询靶点信息时,可以利用那些专门针对医药领域的数据库,它们提供的资料往往更加系统和详尽,而且查询效率也更高。如摩熵医药-靶点数据库,已经收录了超过8000个药物靶点的详细信息,同时关联了同靶点药物研发、同靶点中国临床试验、同靶点中国注册、同靶点中国上市等药品信息,并且具备了靶点数据库应有的所有功能。是目前药物靶点信息查询应用最为常用的数据库之一。
下面以摩熵医药-靶点数据库中查询靶点‘EGFR’为例,详细展示靶点信息查询方法
首先进入摩熵医药网站-->免费申请试用靶点数据库-->在’竞争情报’栏目中选择’靶点格局’-->在靶点中选择’EGFR’-->点击‘搜索’,图解如下,可以看到该靶点的研发各阶段统计数据,点击对应的数字可以看到该阶段对应药品品种。
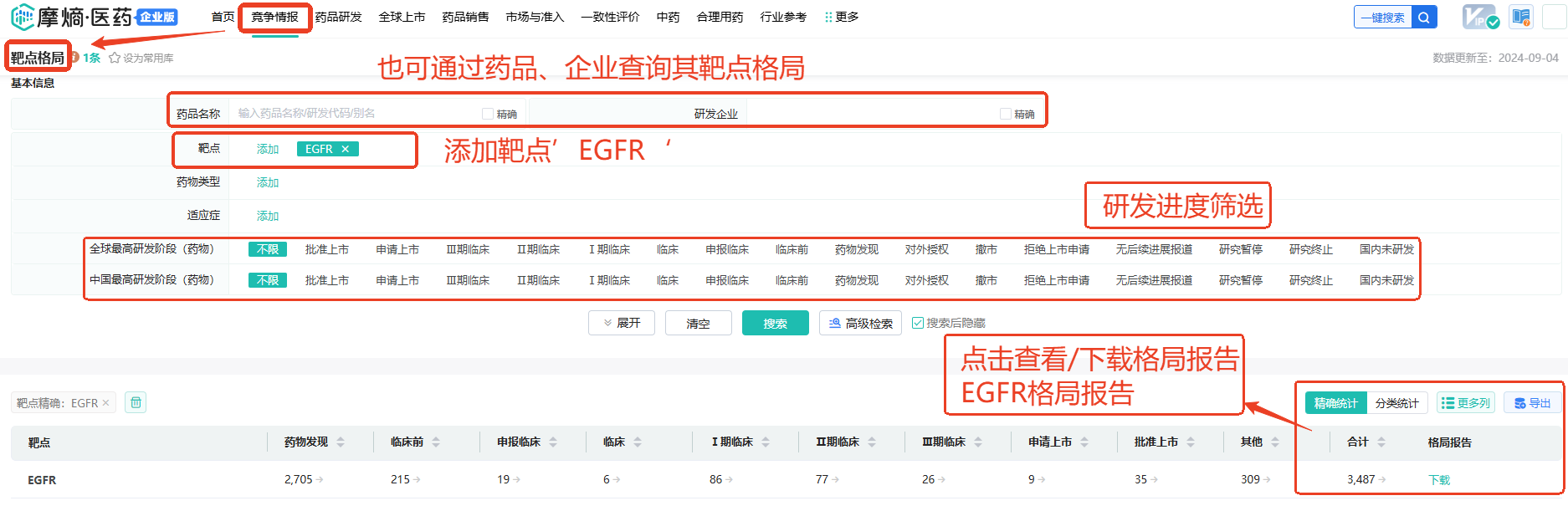
也可通过点击搜索结果中‘EGFR’查看该靶点详细信息,包含了该靶点的基本信息、全球同靶点新药、全球同靶点适应症分析、全球同靶点企业分析、国内同靶点分析等内容。
①目标靶点基本信息
在靶点基本信息中包含了靶点别名、结构信息、序列长度、分子量、功能注释、参与疾病、靶点层级关系、靶点相关通路图,同时关联uniprot(名称和分类、亚细胞位置、疾病与变异、PTM、表达、相互作用、结构、家族、序列和异构体、相似蛋白等)、同靶点药物研发、同靶点中国临床试验、同靶点中国注册、同靶点中国上市等药品信息。
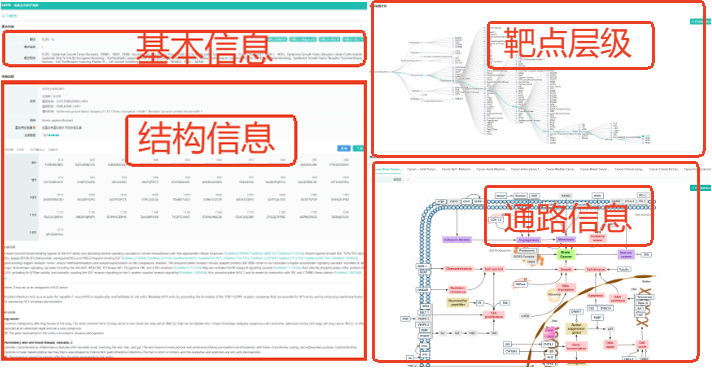
摩熵医药-目标靶点基本信息
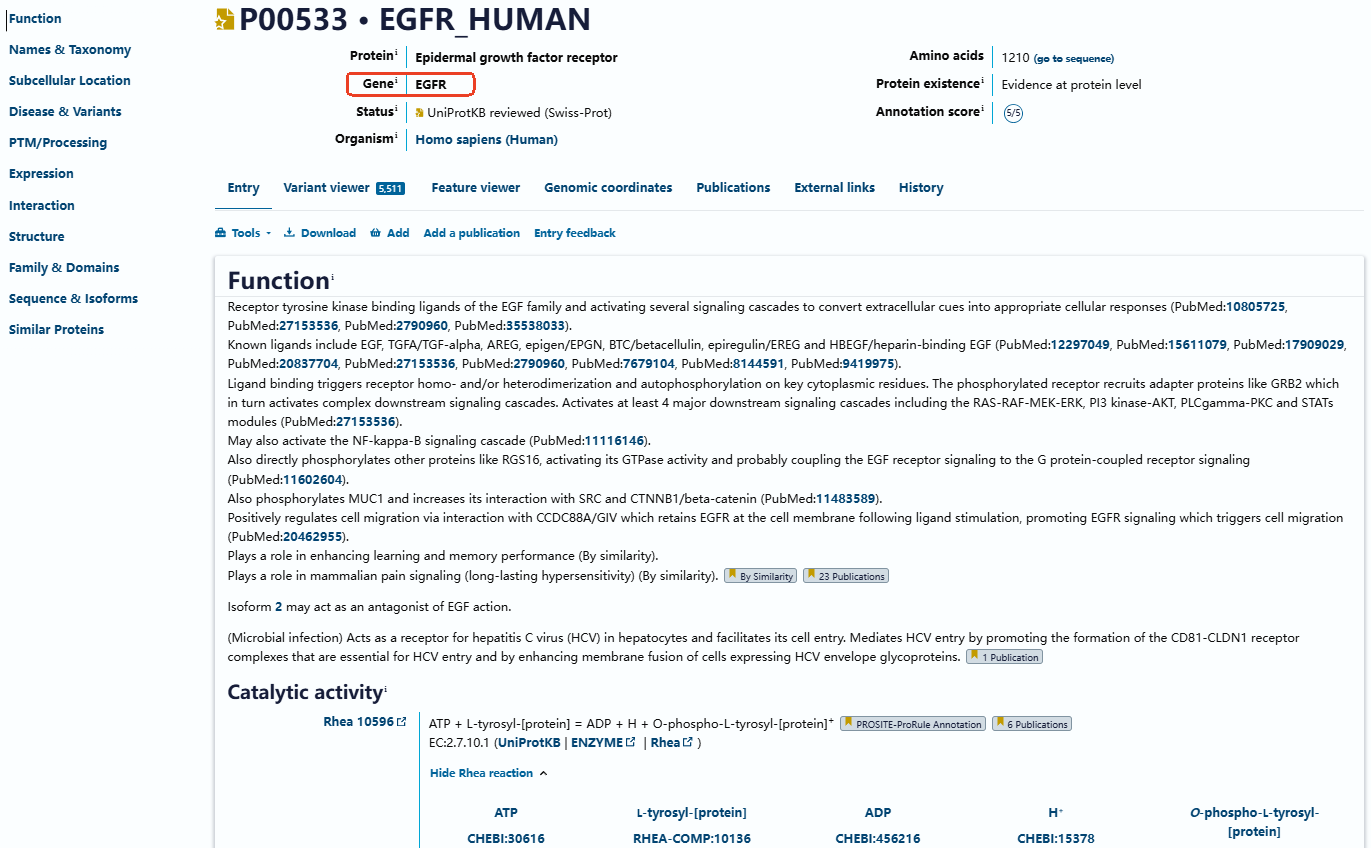
摩熵医药-目标靶点关联信息(uniprot)
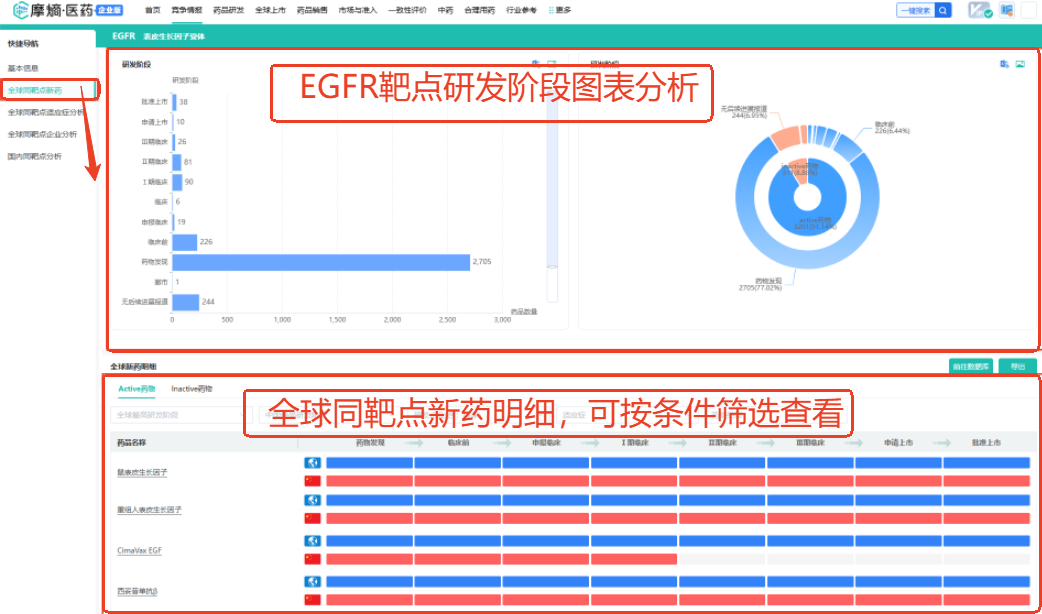
②全球同靶点新药(EGFR)
在全球同靶点新药(EGFR)信息中包含了靶点对应药物在各个研发阶段数量的图表统计,直观查看靶点药物研发趋势难度,并在’全球新药明细’中详细列出了同靶点药品名称及对应的图表进度,可按研发阶段、企业、适应症、药物类型等字段进行二次筛选,数据报告均可导出下载。
③全球同靶点适应症分析(EGFR)
在全球同靶点适应症分析图表中的数据来自于摩熵医药-全球药物研发数据库,可直接点击绿色字体’下载报告’,在图表中的数字均可点击,直接跳转查看信息,除了靶点热力图展示外,也可选择靶点饼状图、柱状图进行查看。
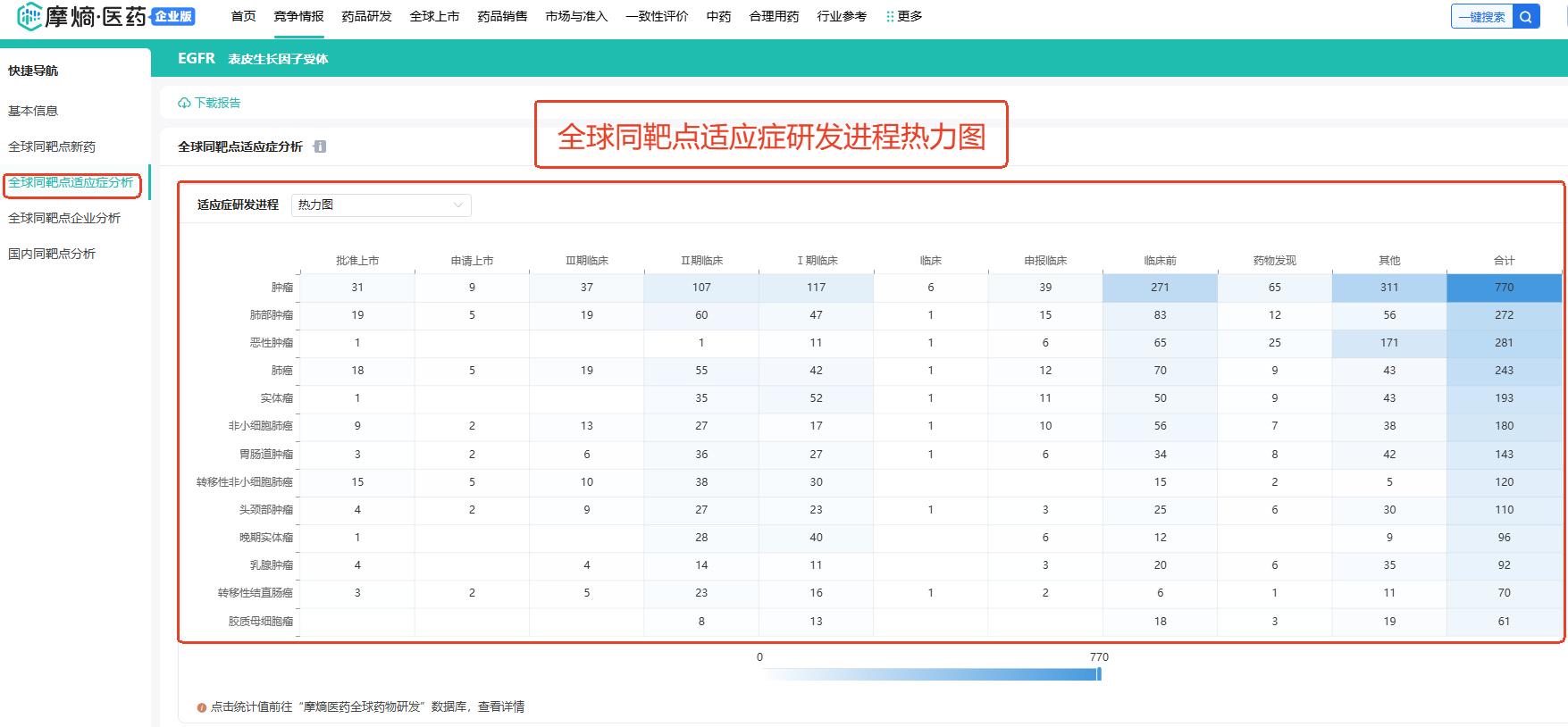
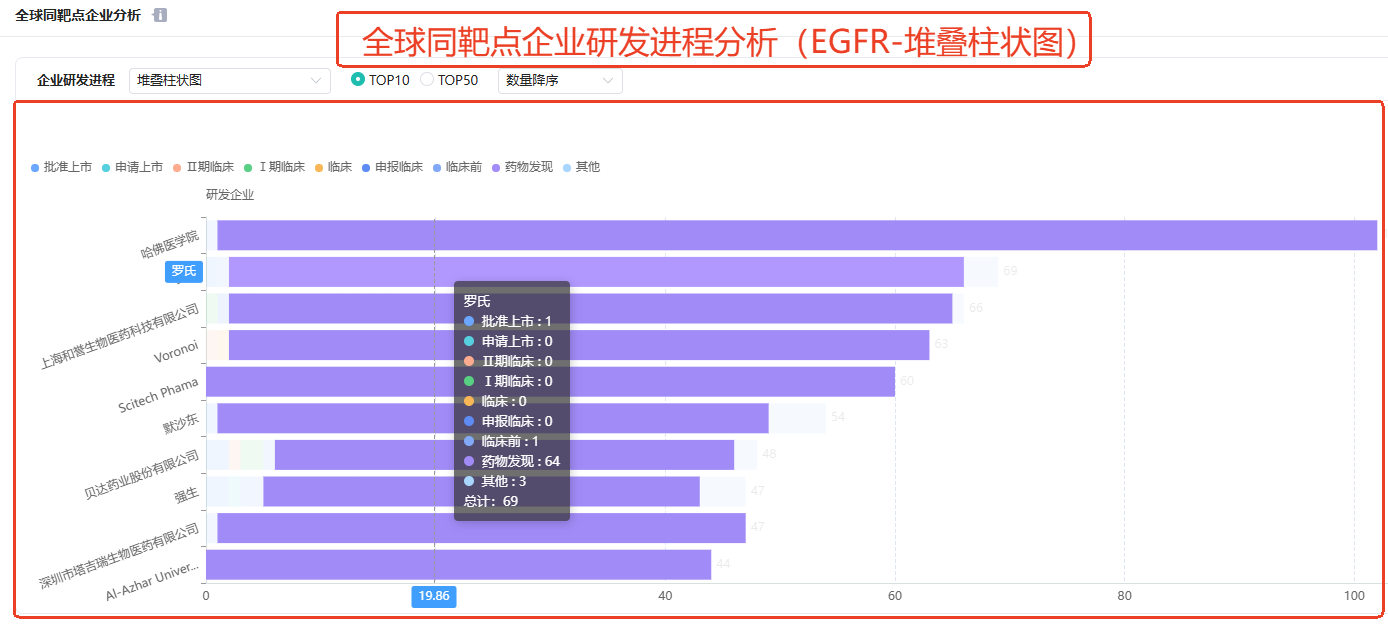
④全球同靶点企业分析(EGFR)
在全球同靶点企业分析中,支持查看靶点EGFR研发的药企,并可根据其同靶点研发的数量进行排序,点击目标企业,查看该企业EGFR靶点研发药物的详细名称。
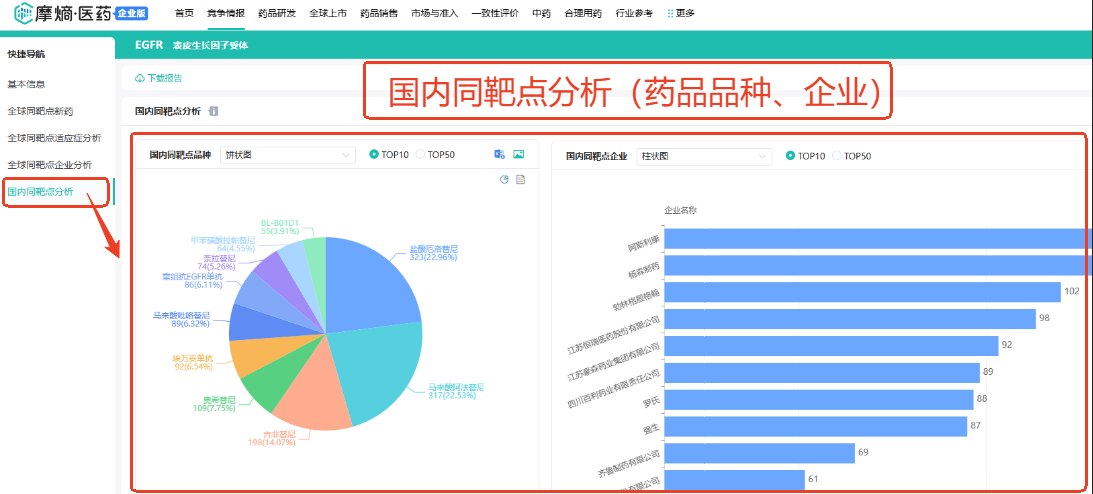
⑤国内同靶点品种-企业格局分析(EGFR)
与上述全球同靶点分析一样,只不过针对范围是国内的靶点格局分析。
摩熵医药靶点数据库收录了靶点的基本信息、蛋白质信息、生物序列、靶点相关的通路图,整合了与靶点相关的全球药物研发数据、全球适应症和企业分析情况、国内品种和企业统计分析等信息。可据此了解到靶点的竞争情况、市场前景和热门靶点的演变趋势、新兴靶点的崛起,帮助药企把握新药研发的趋势和市场的需求变化、明确研发热点、评估竞争态势、合理布局研发管线,为企业研发决策提供参考,从而提高研发效率和市场竞争力。

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









