






作者丨JeffWang@知乎
来源丨https://zhuanlan.zhihu.com/p/480829222
编辑丨3D视觉工坊
做Multi-View Stereo (MVS) 以及 Structure-from-Motion (SfM) 的同学对COLMAP这个词应该不陌生, COLMAP[1] is a general-purpose SfM and MVS pipeline with a graphical and command-line interface. It offers a wide range of features for the reconstruction of ordered and unordered image collections. 说白了, COLMAP是用来做SfM或者MVS的软件,该软件内的算法主要从两篇文章中提炼出来:(1)Structure-from-Motion Revisited[2](2) Pixelwise View Selection for Unstructured Multi-View Stereo[3]. 本文主要针对COLMAP在MVS中的算法原理进行paper解读,即解读第二篇文章。

Pixelwise View Selection for Unstructured Multi-View Stereo发表在2016年的ECCV,由ETH的Marc Pollefeys大佬组发表。本篇知乎blog首先给出该篇文章想要解决的问题 (Problem to be addressed),然后分析其解决方案 (Methods),更多的细节可以参考原文。
Problem to be addressed
"This work presents a Multi-View Stereo system for robust and efficient dense modeling from the unstructured image collection." 这句话是摘要的第一句话,作者想要提出一个的MVS模型,使它能够从unstructured图像输入中稠密重建出3D场景。这并不是说在这篇文章之前没有相关的方案,只不过之前的方案存在一些问题 (1) 重建的accuracy, completness, robustness, efficiency都不令人满意。(2)尤其是在uncontrolled场景(unstructured图像输入,输入图像尺寸不一样,光照不一样等),重建结果更令人堪忧。为了解决这些方案,作者提出了以下解决方案。
Method
作者为了使模型更加robust,一共在baseline[4]上提出了6点算法细节的改进。在详细描述算法改机之前,我们先看一下先前的MVS baseline是怎么解决问题的。
Review of Baseline


————————————
至此位置,说完了baselinede做法,下面开始说本篇paper的几点改进:(1) Pixelwise normal estimation. (2) Pixelwise view selection . (3) Integration of a “temporal” view selection smoothness term. (4) Adaptive window support through bilateral photometric consistency. (5) Introduction of a multi-view geometric consistency term for simultaneous depth/normal estimation and image-based fusion.
Pixelwise Normal Estimation
上面提到的baseline在做homography-warping的时候使用了fronto-parallel 假设,这会导致artifacts for oblique structure。所以我们在估计深度的同时估计surface normals。做法比较简单,只是在之前的基础上多估计了一个 n:

Pixelwise View Selection
对于unstructured image输入,pixelwise view selection可以大大提升robustness,具体来说,本文利用三种指标去选择view:(1)Triangulation Prior去选择基线比较合适的source image;(2)Resolution Prior去选择分辨率和reference近似的source views;(3)Incident Prior去选择normal正常的view(因为不可能拍摄到物体的背面,所以normal应该在0-90°)


View Selection Smoothness

Photometric Consistency
之前在baseline中,采用NCC的方案去计算颜色相似度,NCC对于Gaussian noise是optimal的,但是针对depth discontinuity区域表现很差。所以本文使用了bilaterally weighted adaption of NCC.:

Geometric Consistency

以下是总结部分。把上面提到的所有概率分布联合起来优化:
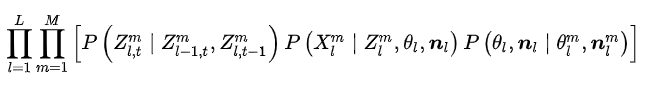
其中第一项代表空间和(迭代)时间上的smooth,第二项代表使用bilateral NCC的photometric consistency。第三项代表geometric consistency。该式子可以用过variational inference去求解(该部分以后跟进)。整篇文章的概率模型还是比较复杂的,如果让我个人用一句话来总结,那就是:根据reference image和source image拍摄的夹角、图像分辨率、法向量角度去计算不同source view(用来描述reference pixel)的权重,然后根据这些权重去计算geometric和photometric的consistency,最后用PatchMatch迭代出每个像素最合适的深度。
参考
1、 https://colmap.github.io/
2、Structure-from-Motion Revisited (https://openaccess.thecvf.com/content_cvpr_2016/papers/Schonberger_Structure-From-Motion_Revisited_CVPR_2016_paper.pdf)
3、Pixelwise View Selection for UnstructuredMulti-View Stereo (https://www.cs.unc.edu/~ezheng/resources/mvs_2016/eccv2016.pdf)
4、https://openaccess.thecvf.com/content_cvpr_2014/papers/Zheng_PatchMatch_Based_Joint_2014_CVPR_paper.pdf
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~















 3368
3368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









