






点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

编辑丨算法邦
今天和大家分享工作的是自动驾驶中高精度语义地图的动态构建。内容主要是解读我们组最新的论文HDMapNet: A Local Semantic Map Learning and Evaluation Framework。
01
什么是高精地图?
高精地图提供了精准的、综合的道路几何与语义信息,是其他自动驾驶模块(如定位、感知、预测和规划)不可或缺的一部分。
02
高精地图提供了哪些要素?
高精地图通常包含两部分,第一部分是影像地图(Imagery Map),主要包括3D雷达点云、反射率、高度、斜率等物理信息。第二部分是语义地图(Semantic Map),主要提供了丰富的标注信息,如道路的向量化表示、类型(车道、自行车道或公交车道)、速度限制、车道线类型(虚线、实线、双实线)等等。那么在本文中,我们主要关注语义地图的构建,因为它是被自动驾驶任务所用到的部分。
03
高精地图是怎样生成的?

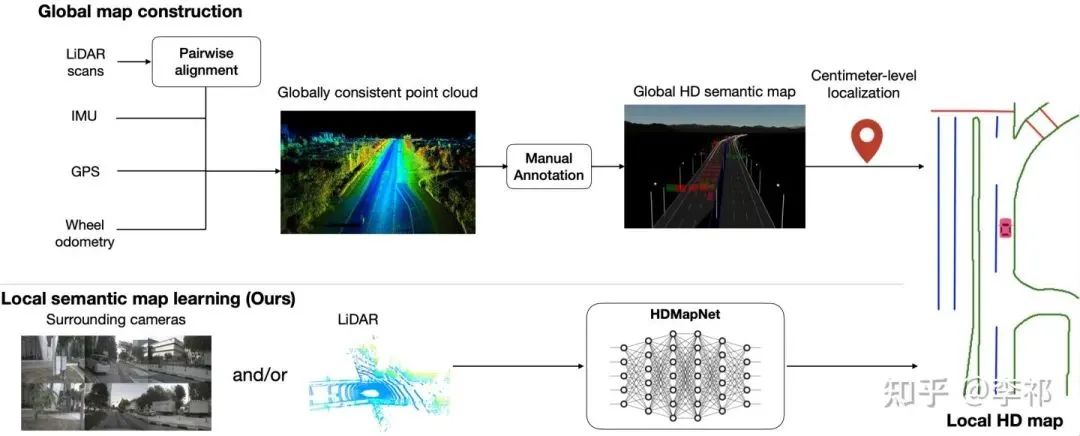
高精地图的生成涉及到了定位、融合、检测、标注等复杂的流程。在生成高精地图之后,还需要不时地对其进行更新,以适应路况信息的变化。
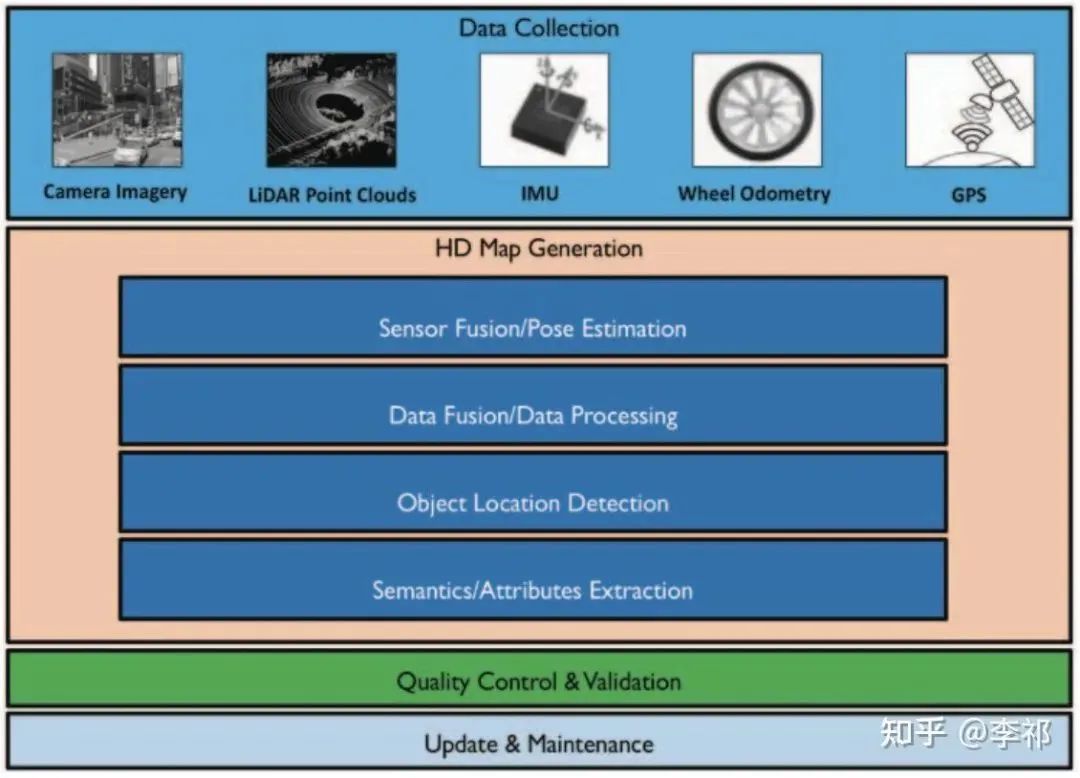
高精度地图的生成流程
04
那么高精地图能做什么呢?
高精地图提供了:
精准的定位
超出相机视觉范围的感知能力
实时的计算能力
举例来说, 高精地图可以提供精确的路标/路灯的3D位置,从而使得自动驾驶汽车不需要对其进行检测和识别。
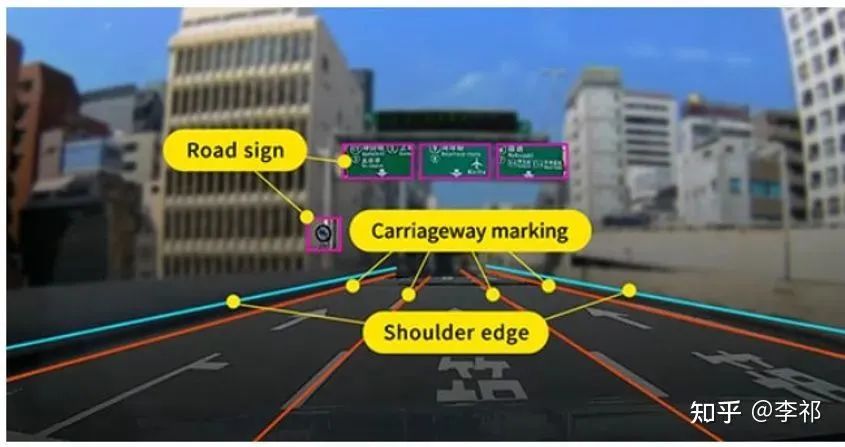
道路信息位置的精确标注
05
HDMapNet
虽然高精地图能够提供丰富的信息,但标注、 维护高精地图需要耗费大量的人力和资源,因而限制了其的可拓展性。为此,我们提出了一种使用车载传感器(相机 and/or 雷达)来动态构建局部高精地图的方法HDMapNet。
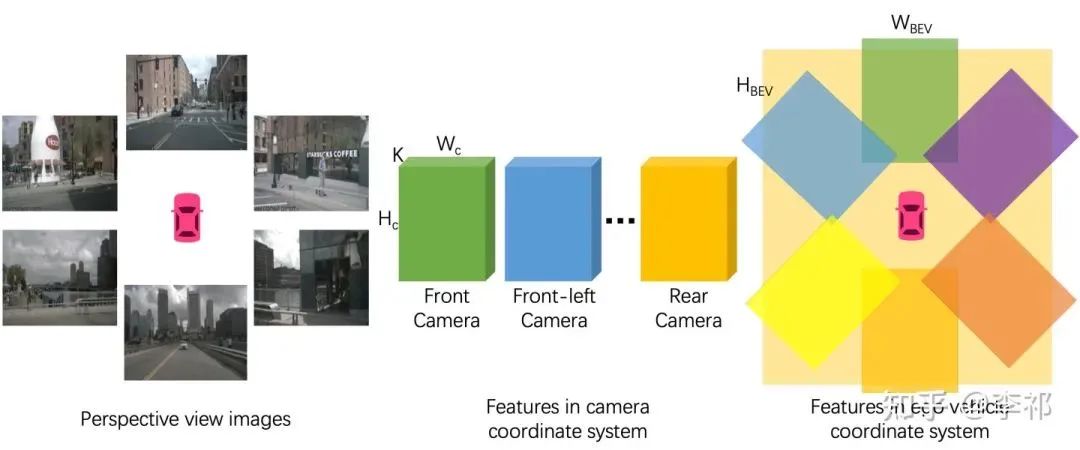
要想使用车载传感器进行高精地图构建,主要需要解决2个问题:道路预测向量化和从相机前视图到鸟瞰图的视角转换。
向量化(Vectorization)是指我们最终得到的地图信息不是图片形式的,而是用点、线、框等几何形状表示的,这种表示在地图的下游任务使用、存储等方面都有巨大优势。HDMapNet的decoder输出3个分支:语义分割semantic segmentation、实例分割instance embedding、方向预测direction prediction。然后通过后处理的手段来将这些信息处理成向量化的道路表达。
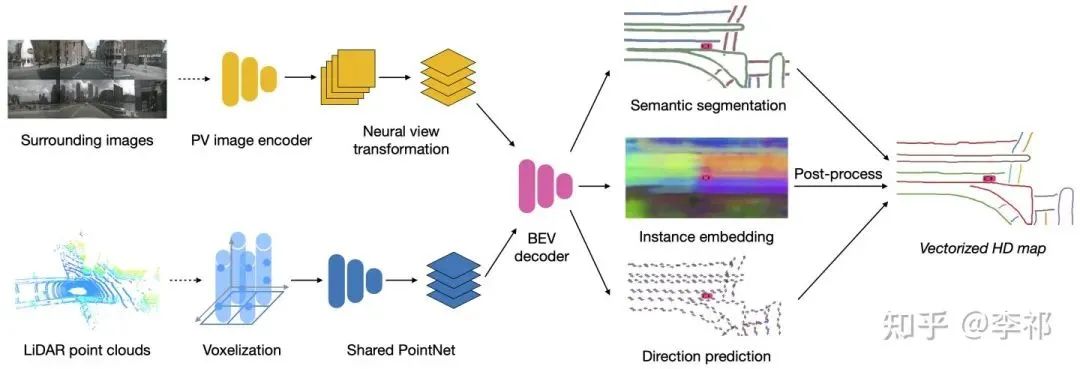
至于从相机前视图到鸟瞰图视角转换,由于没有图片上每个像素点的深度信息,我们无法简单地利用几何投影将图像投回到鸟瞰视角。一种做法是假设地面高度全部为0,直接通过Inverse Perspect Mapping[3]来进行投影。但因为地面会有倾斜,再加上车的颠簸,我们并不能保证车道线被正确的投影到鸟瞰视角。Lift-Splat-Shoot[4] 很巧妙的利用attention的方式端到端地学了一个深度,但是因为没有显式的深度作为监督,所以实际的性能并不是很好。在这里,我们参考了VPN[5]的做法,使用全连接网络来让network自己学习如何进行视角的变换。与其不同的是,我们显式地使用了相机外参来将从不同相机抽取的特征拼接到鸟瞰视角,从而提升了特征在鸟瞰视角的分辨率。
此外,我们还提出了semantic level和instance level结果的评价方式,以方便对semantic HD map的构建进行评价,这里就不赘述了。
我们也可以对HDMapNet的输出进行时序融合,构建出一个随着车的行进不断扩展的高精地图,如下图所示。是不是很有意思!
06
参考
Machine Learning Assisted High-Definition Map Creation https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8377682
HDMapNet: A Local Semantic Map Learning and Evaluation Framework https://arxiv.org/abs/2107.06307
Inverse Perspective Mapping https://csyhhu.github.io/2015/07/09/IPM/
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D https://nv-tlabs.github.io/lift-splat-shoot/
Cross-view Semantic Segmentation for Sensing Surroundings https://view-parsing-network.github.io/
nuScenes 数据集 https://www.nuscenes.org/
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿,加微信:dddvision

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近6000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









