






作者:PCIPG-LC | 来源:计算机视觉工坊
在公众号「3D视觉工坊」后台,回复「原论文」可获取论文pdf和代码链接。
添加微信:dddvisiona,备注:3D点云,拉你入群。文末附行业细分群。
在点云分析方面,基于点的方法近年来迅速发展。这些方法最近集中在简洁的 MLP 结构上,例如 PointNeXt,它已经证明了与卷积和 Transformer 结构的竞争力。然而,标准 MLP 有效提取局部特征的能力有限。为了解决这个限制,我们提出了一种面向向量的点集抽象,它可以通过高维向量聚合相邻特征。为了促进网络优化,我们使用基于 3D 矢量旋转的独立角度构建从标量到矢量的转换。最后,我们开发了一个遵循 PointNeXt 结构的 PointVector 模型。我们的实验结果表明,PointVector 在 S3DIS Area 5 上实现了最先进的性能 72.3% mIOU,在 S3DIS(6 倍交叉验证)上实现了 78.4% mIOU,而模型参数仅为 PointNeXt 的 58%。我们希望我们的工作将有助于探索简洁有效的特征表示。该代码即将发布。
1 前言
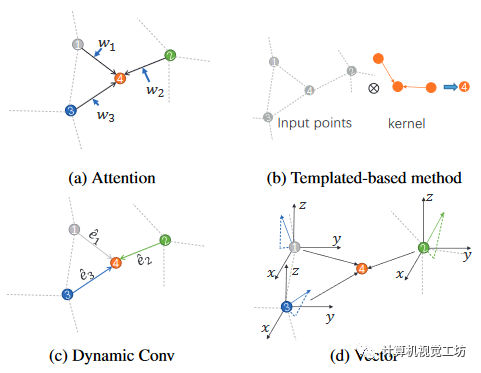
点云分析是各种下游任务的基石。随着PointNet和PointNet++的引入,非结构化点云的直接处理已经成为一个热门话题。许多基于点的网络引入了新颖而复杂的模块来提取局部特征,例如,基于注意力的方法探索如图1(a)所示的注意力机制消耗较低,基于卷积的方法探索如图1(c)所示的动态卷积核,基于图的方法使用图来建模点的关系。这些方法应用到PointNet++的特征提取模块中,带来了特征质量的提升。然而,它们在网络结构方面设计起来有些复杂。PointNeXt 采用了 PointNet++ 的 SetAbstraction (SA) 模块,并提出了 Inverted Residual MLP (InvResMLP) 模块。MLP网络的简单设计取得了良好的效果。受这项工作的激励,我们尝试进一步探索 MLP 结构的潜力。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程》。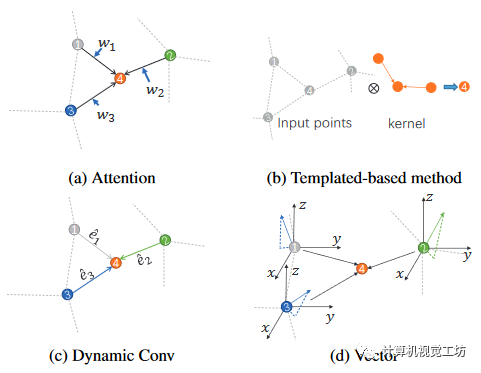 图1 不同方法的核心操作的插图。(a)通过应用像线性层一样的固定/各向同性核(黑色箭头)来单独计算每个点的特征。然后,它通过输入生成的权重赋予各向异性。(b) 位移向量用于过滤近似核模式的点以进行特征聚合。(c) 它对每个点特征应用具有各向异性的独特动态内核。(d)不同的是,我们根据特征生成向量表示,并且由于向量的方向,向量的聚合方法是各向异性的。PointNeXt使用的都是标准MLP,特征提取能力不足。除了注意力和动态卷积机制之外,如图 1(b) 所示的基于模板的方法(例如 3D-GCN)还采用相对位移向量来调制输入点和卷积核之间的关联。我们引入特征的向量表示来扩展特征变化的范围,目的是更有效地调节局部特征之间的连接。我们的方法如图 1(d) 所示,与基于模板的方法不同。我们没有使用位移向量作为内核的属性,而是为每个相邻点生成向量表示并将它们聚合。我们的方法引入了更少的归纳偏差,从而提高了泛化能力。此外,我们通过利用 3D 空间中具有两个独立角度的矢量旋转矩阵来增强 3D 矢量表示的生成。这种方法有利于网络找到更好的解决方案。受PointNeXt 和PointNet++ 的影响,我们提出了VPSA模块。该模块遵循PointNet系列的点集抽象(SA)模块的结构。向量表示是从输入特征获得并使用缩减函数聚合的。然后将每个通道的向量投影为标量以导出局部特征。通过结合 VPSA 和 SA 模块,我们构建了一个具有类似于 PointNeXt 架构的 PointVector 模型。我们的模型在公共基准数据集上进行了全面验证。它在 S3DIS 语义分割基准上实现了最先进的性能,并在 ScanObjectNN 和 ShapeNetPart 数据集上取得了有竞争力的结果。通过结合向量的先验知识,我们的模型在 S3DIS 上以更少的参数获得了优异的结果。详细的消融实验进一步证明了我们方法的有效性。贡献总结如下:
图1 不同方法的核心操作的插图。(a)通过应用像线性层一样的固定/各向同性核(黑色箭头)来单独计算每个点的特征。然后,它通过输入生成的权重赋予各向异性。(b) 位移向量用于过滤近似核模式的点以进行特征聚合。(c) 它对每个点特征应用具有各向异性的独特动态内核。(d)不同的是,我们根据特征生成向量表示,并且由于向量的方向,向量的聚合方法是各向异性的。PointNeXt使用的都是标准MLP,特征提取能力不足。除了注意力和动态卷积机制之外,如图 1(b) 所示的基于模板的方法(例如 3D-GCN)还采用相对位移向量来调制输入点和卷积核之间的关联。我们引入特征的向量表示来扩展特征变化的范围,目的是更有效地调节局部特征之间的连接。我们的方法如图 1(d) 所示,与基于模板的方法不同。我们没有使用位移向量作为内核的属性,而是为每个相邻点生成向量表示并将它们聚合。我们的方法引入了更少的归纳偏差,从而提高了泛化能力。此外,我们通过利用 3D 空间中具有两个独立角度的矢量旋转矩阵来增强 3D 矢量表示的生成。这种方法有利于网络找到更好的解决方案。受PointNeXt 和PointNet++ 的影响,我们提出了VPSA模块。该模块遵循PointNet系列的点集抽象(SA)模块的结构。向量表示是从输入特征获得并使用缩减函数聚合的。然后将每个通道的向量投影为标量以导出局部特征。通过结合 VPSA 和 SA 模块,我们构建了一个具有类似于 PointNeXt 架构的 PointVector 模型。我们的模型在公共基准数据集上进行了全面验证。它在 S3DIS 语义分割基准上实现了最先进的性能,并在 ScanObjectNN 和 ShapeNetPart 数据集上取得了有竞争力的结果。通过结合向量的先验知识,我们的模型在 S3DIS 上以更少的参数获得了优异的结果。详细的消融实验进一步证明了我们方法的有效性。贡献总结如下:
我们提出了一种具有相对特征和位置的新颖的直接向量表示,以更好地指导局部特征聚合。
我们探索了获得矢量表示的方法,并提出了利用3D空间中的矢量旋转矩阵生成3D矢量的方法。
我们提出的 PointVector 模型在 S3DIS area5 上实现了 72.3% 的平均交集 (mIOU),在 S3DIS(6 倍交叉验证)上实现了 78.4% mIOU,仅具有 PointNeXt 的 58% 模型参数。
2 相关工作
基于点的网络。与体素化和多视图方法相比,基于点的方法直接处理点云。PointNet首先提出使用MLP直接处理点云。PointNet++ 随后引入了层次结构来改进特征提取。随后的工作重点是细粒度局部特征提取器的设计。基于图的方法依赖于图神经网络并引入点特征和边缘特征来建模局部关系。基于卷积的方法提出了几种动态卷积核来自适应聚合邻域特征。许多类似变压器的网络通过自注意力提取局部特征。最近,类 MLP 网络通过增强特征,能够用简单的网络获得良好的结果。PointMLP 提出了一种几何仿射模块来规范化特征。RepSurf 通过三角平面拟合表面信息,对伞面进行建模以提供几何信息。PointNeXt 集成了训练策略和模型缩放。类似 MLP 的架构。类似 MLP 的结构最近显示出能够以简单的架构与 Transformer 相媲美。在图像领域,MLP-Mixer首先使用Spatial MLP和Channel MLP的组合。随后的工作通过为空间 MLP 选择对象来降低计算复杂性,同时保持较大的感知场以保持准确性。由于点云太大,类MLP网络一般采用K近邻采样或球采样方法来确定感知场。点云分析中的MLP结构从PointNet和PointNet++开始,使用MLP来提取特征并通过对称函数聚合它们。Point-Mixer提出了三种点集算子,PointMLP通过几何仿射模块修改特征分布,PointNeXt 通过训练策略和模型缩放来扩展PointNet ++模型并提高性能。特征聚合。 PosPool 通过提供无参数的位置自适应池操作改进了 PointNet++ 中定义的归约函数。ASSANet 引入了一种新的各向异性缩减函数。此外,注意力机制的引入为约简函数提供了新的动态权重。向量是有方向的,各向异性聚合函数自然满足这个性质。GeoCNN 基于六个方向上邻近点和质心的向量和角度来投影特征并对它们求和。WaveMLP 将图像块表示为波,并使用波相位和幅度描述特征聚合。矢量神经元构建了一个神经元三元组来重建标准神经网络并通过矢量变换来表示特征。以 3DGCN 为代表的基于模板的方法使用相对位移向量的余弦值来过滤来自更符合内核模式的邻居的聚合特征。局部位移使用局部位移向量通过组合固定内核的权重来更新特征。在我们的方法中,通过修改点特征提取函数来生成中间向量表示。矢量方向是根据特征和位置确定的,以实现各向异性聚合函数。
3 方法
我们提出了一种中间向量表示来增强点云分析中的局部特征聚合。本节包括第 3.1 节中对 PointNet 系列的点集抽象(SA)运算符的回顾,第 3.2 节中介绍的面向向量的点集抽象模块,以及第 3.3 节中对我们从标量扩展向量的方法的描述,以及3.4节中PointVector的网络结构。
3.1 回顾
SA 模块包括用于查询每个点的邻居的分组层(K-NN 或 BallQuery),共享 MLP 以及用于聚合邻居特征的缩减层。SA模块有一个子采样层,用于对第一层中的点云进行下采样。我们将表示为阶段之后提取的点的特征,表示点的邻居,表示输入点的数量。SA模块的内容可以表述如下:其中是聚合点来自其邻居的特征的归约函数,表示共享的 MLP。分别表示点的输入特征、点的位置和i点的位置。在局部聚合操作中,经典方法将权重分配给维特征的分量,如下式所示,并对空间维度上的相邻特征进行求和。我们将维特征的分量视为只有一个非零值的基向量,并将向量变换定义如下:
其中 是标量权重。在方程 3 中,变换改变了向量的一个值。上面的两个方程是等价的。方程中未改变的零点对后续操作没有贡献,可以忽略不计。在物理学中,运动的自由度等于运动导致系统改变的状态量的数量。物理系统中的自由度越大,表明定义其状态的参数的独立变化范围越大。类似地,向量变换的自由度是指向量中可以独立变化的值的数量。所以,我们提到的3D向量意味着向量变换的自由度是3。3.2 面向向量的点集抽象
正如 3.1 节中所讨论的,特征分量可以表示为向量。矢量变换的自由度更高,可以增加变化并改进相邻元素之间连接的表示。向量具有大小和方向属性,在表示特征方面比标量更具表现力。当聚集时,它们由于其方向性而表现出各向异性。因此,我们引入了如图2所示的中间向量表示。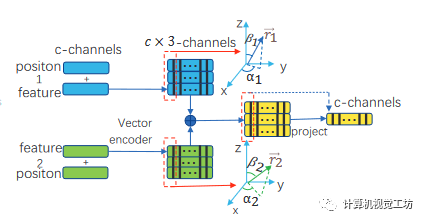 图2 PointVector 的面向矢量的点集抽象(VPSA)模块。它说明了 VPSA 模块从输入特征中获取向量表示,聚合它们,并将它们投影回原始特征样式。如图所示,特征的每个通道可以被认为是一个3D向量,通道之间是相互独立的。需要注意的是,在我们的假设中,维特征的分量表示特征向量沿坐标轴的投影。将向量聚合后得到质心特征,其中分量向量中变化值的数量为3。将它们合并成维特征向量需要将个分量对齐然后求和。由于用这种方法实现组件对齐比较困难,我们直接将个组件投影到标量中,并将它们组合成质心特征。与卷积网络中的中间特征类似,每个通道特征图上的值表示该位置特定特征的响应强度。我们的方法中的输入特征被转换为一系列向量,然后通过归约函数聚合。请注意,向量表示的每个通道中的元素是向量。我们获得了与通道无关的向量表示。我们将表示为相对特征和相对位置的混合特征。矢量引导聚合模块的内容可以表述为:其中是生成向量表示的函数,表示线性变换向量到标量的投影,是通道混合线性,它与每个通道的信息交互,同时变换维度以适应网络。然而,我们引入的特征表示实际上是使用三元组形式来表示的。我们将 表示为向量的维度,为特征的通道。事实上,个维向量的集合以与维特征向量相同的形式表示。归约函数后面是分组卷积,它将向量转换为每个通道的标量,这将中间向量表示与一般特征向量区分开来。当归约函数选择时,和函数一起构成了GroupConv的特例。令表示邻居特征的数量。对于一组,GroupConv 的卷积核是一个参数矩阵,而我们的方法可以看作个相同的 参数矩阵。这是因为我们将向量视为整体并为每个元素分配相同的权重。我们将在补充材料中解释为什么原始的 groupconv 操作不适合我们的向量引导特征聚合。
图2 PointVector 的面向矢量的点集抽象(VPSA)模块。它说明了 VPSA 模块从输入特征中获取向量表示,聚合它们,并将它们投影回原始特征样式。如图所示,特征的每个通道可以被认为是一个3D向量,通道之间是相互独立的。需要注意的是,在我们的假设中,维特征的分量表示特征向量沿坐标轴的投影。将向量聚合后得到质心特征,其中分量向量中变化值的数量为3。将它们合并成维特征向量需要将个分量对齐然后求和。由于用这种方法实现组件对齐比较困难,我们直接将个组件投影到标量中,并将它们组合成质心特征。与卷积网络中的中间特征类似,每个通道特征图上的值表示该位置特定特征的响应强度。我们的方法中的输入特征被转换为一系列向量,然后通过归约函数聚合。请注意,向量表示的每个通道中的元素是向量。我们获得了与通道无关的向量表示。我们将表示为相对特征和相对位置的混合特征。矢量引导聚合模块的内容可以表述为:其中是生成向量表示的函数,表示线性变换向量到标量的投影,是通道混合线性,它与每个通道的信息交互,同时变换维度以适应网络。然而,我们引入的特征表示实际上是使用三元组形式来表示的。我们将 表示为向量的维度,为特征的通道。事实上,个维向量的集合以与维特征向量相同的形式表示。归约函数后面是分组卷积,它将向量转换为每个通道的标量,这将中间向量表示与一般特征向量区分开来。当归约函数选择时,和函数一起构成了GroupConv的特例。令表示邻居特征的数量。对于一组,GroupConv 的卷积核是一个参数矩阵,而我们的方法可以看作个相同的 参数矩阵。这是因为我们将向量视为整体并为每个元素分配相同的权重。我们将在补充材料中解释为什么原始的 groupconv 操作不适合我们的向量引导特征聚合。
3.3 从标量扩展向量
方程 4 中定义的函数最简单的想法是直接用 MLP 获得点的维向量。然而,虽然单层 MLP 的表达能力可能有限,但多层 MLP 可能是资源密集型的。正如 3.1 节中所讨论的,输入特征被视为向量,我们的目标是设计一个具有高自由度的变换。该变换结合了旋转和缩放,分别由旋转矩阵和可学习参数表示。该方法以较低的资源消耗取得了较好的效果。 图3 从一般特征到向量表示的扩展。为了简单起见,我们暂定。左侧表示通过标准MLP生成特征的过程,右侧将特征的每个标量添加2个分量形成向量,然后对其进行旋转。如图3所示,通过添加个零值分量,可以将标量直接转换为维向量。然后,扩展向量表示的每个通道可以被视为沿着特定坐标轴方向的维向量。因此,我们可以通过额外训练旋转矩阵来获得正确的向量方向。直接预测旋转矩阵可能会给非线性优化带来困难,因为矩阵元素是相互依赖的。相反,我们首先预测旋转角度,然后根据该角度推导旋转矩阵。3D矢量的旋转可以分解为绕三个轴的旋转。然而,我们还没有确定如何表示 4D 矢量绕平面的旋转。如图4所示,由于扩展的3D矢量位于坐标轴上,因此可以省略绕该轴的一圈旋转。我们保持默认的旋转方向为逆时针。向量首先绕轴旋转角度,然后绕轴旋转角度,最终得到向量 。旋转可以表述如下:
图3 从一般特征到向量表示的扩展。为了简单起见,我们暂定。左侧表示通过标准MLP生成特征的过程,右侧将特征的每个标量添加2个分量形成向量,然后对其进行旋转。如图3所示,通过添加个零值分量,可以将标量直接转换为维向量。然后,扩展向量表示的每个通道可以被视为沿着特定坐标轴方向的维向量。因此,我们可以通过额外训练旋转矩阵来获得正确的向量方向。直接预测旋转矩阵可能会给非线性优化带来困难,因为矩阵元素是相互依赖的。相反,我们首先预测旋转角度,然后根据该角度推导旋转矩阵。3D矢量的旋转可以分解为绕三个轴的旋转。然而,我们还没有确定如何表示 4D 矢量绕平面的旋转。如图4所示,由于扩展的3D矢量位于坐标轴上,因此可以省略绕该轴的一圈旋转。我们保持默认的旋转方向为逆时针。向量首先绕轴旋转角度,然后绕轴旋转角度,最终得到向量 。旋转可以表述如下:
3.4 网络架构
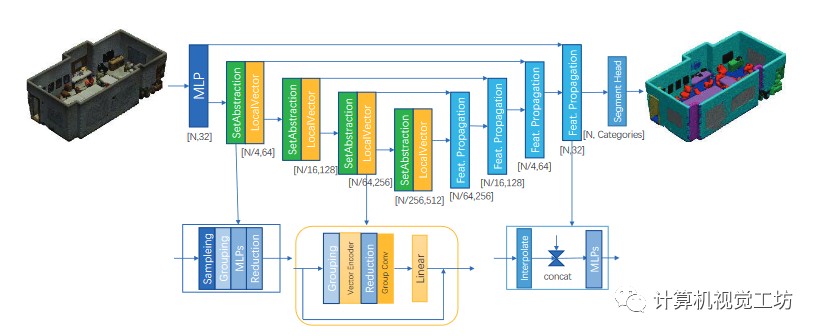 图5 整体架构。我们重用了PointNet++的SA模块和特征传播模块,并提出了VPSA模块来改进采样点云的特征提取。总之,我们提出了 PointVector,它是从 PointNeXt 修改而来,用我们提出的 VPSA 模块替换其 InvResMLP 模块,我们定义其向量维度。该架构如上图所示。参考经典的PointNet++,我们使用包含编码器和解码器的层次结构。对于分割任务,我们使用编码器和解码器。对于分类任务,我们仅使用编码器。为了与PointNeXt进行公平比较,我们参考PointNeXt的参数设置,设置了三种尺寸的模型。我们将表示为最初嵌入MLP的通道,表示SA模块的编号,表示VPSA模块的编号。三种型号尺寸如下:
图5 整体架构。我们重用了PointNet++的SA模块和特征传播模块,并提出了VPSA模块来改进采样点云的特征提取。总之,我们提出了 PointVector,它是从 PointNeXt 修改而来,用我们提出的 VPSA 模块替换其 InvResMLP 模块,我们定义其向量维度。该架构如上图所示。参考经典的PointNet++,我们使用包含编码器和解码器的层次结构。对于分割任务,我们使用编码器和解码器。对于分类任务,我们仅使用编码器。为了与PointNeXt进行公平比较,我们参考PointNeXt的参数设置,设置了三种尺寸的模型。我们将表示为最初嵌入MLP的通道,表示SA模块的编号,表示VPSA模块的编号。三种型号尺寸如下:
PointVector-S: C=32, S=0, V=[1,1,1,1]
PointVector-L: C=32, S=[1,1,1,1], V=[2,4,2,2]
PointVector-XL: C=64, S=[1,1,1,1], V=[3,6,3,3]
由于PointNeXt仅使用PointNeXt-S模型进行分类,因此我们使用我们的VPSA模块而不是PointVector-S中的SA模块进行公平比较。分类任务的详细结构将出现在补充材料中。图5中的VPSA模块中有一条跳过连接路径,它被添加到主路径上,然后通过ReLU层。使用这种求和方法的原因是RepSurf指示了如何组合具有不同分布的两个特征。对于分割任务,需要更精细的局部信息,我们将归约函数设置为sum。对于有利于聚合全局信息的分类任务,我们选择原始的约简函数,例如max。
4 实验
我们在三个标准基准上评估我们的模型:用于语义分割的 S3DIS、用于现实世界对象分类的 ScanObjectNN 和用于零件分割的 ShapeNetPart。请注意,我们的模型是在 PointNeXt 的基础上实现的。由于我们使用PointNeXt提供的训练策略,因此我们参考PointNeXt报告的指标进行公平比较。实验设置。我们使用 CrossEntropy 损失和标签平滑、AdamW 优化器和初始学习率 lr=0.002、weight decay=10−4、余弦衰减和batch_size大小 32 来训练 PointVector。以上是基本设置对于所有任务,特定参数将针对特定任务而更改。我们遵循数据集的训练、有效和测试划分。验证集上的最佳模型将在测试集上进行评估。对于S3DIS分割任务,按照先前的方法对点云进行下采样,体素大小为0.4m。该任务的初始学习率设置为 0.01。对于 100 个 epoch,我们使用固定的 24000 个点作为批次,并将批次大小设置为 8。在训练过程中,输入点是从随机点的最近邻居中选择的。与 Point Transformer类似,我们使用整个场景作为输入来评估我们的模型。对于 ScanObjectNN分类任务,我们将 250 个时期的权重衰减设置为 0.05。按照Point-BERT,输入点数为1024。训练点从点云中随机采样,测试点在评估时均匀采样。数据增强的细节与PointNeXt中的相同。对于 ShapeNetPart 零件分割,我们训练 PointVector-S,批量大小为 32,持续 300 个周期。遵循 PointNet++,使用 2048 个具有法线的随机采样点作为训练和测试的输入。对于投票策略,我们保持与PointNeXt相同,并且仅在部分分割任务上使用它。为了确保与标准方法的公平比较,我们不使用任何集成方法,例如 SimpleView。我们还提供模型参数 (Params) 和 GFLOP。此外,与 PointNeXt 类似,我们提供吞吐量(每秒实例数)作为推理速度的指标。吞吐量计算的输入数据与PointNeXt保持一致,以便公平比较。所有方法的吞吐量均使用 128 × 1024(batch_size大小 128,点数 1024)作为 ScanObjectNN 上的输入和 64 × 2048 作为 ShapeNetPart 上的输入来测量。在 S3DIS 上,按照使用 16 × 15000 个点来测量吞吐量。我们使用 NVIDIA Tesla V100 32 GB GPU 和 48 核 Intel Xeon @ 2.10 Hz CPU 评估我们的模型。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程》。
4.1 S3DIS 上的 3D 语义分割
S3DIS(斯坦福大型3D室内空间)是一个具有挑战性的基准,由6个大型室内区域、271个房间和总共13个语义类别组成。对于我们在S3DIS中的模型,SetAbstraction中的邻居数量是32,Local Vector模块中的邻居数量是8。PointTransformer也采用了PointNeXt使用的大部分训练策略和数据增强,所以这是公平的以便我们与它进行比较。为了进行全面比较,我们分别在表1中报告了PointVector-L和PointVector-XL在S3DIS上经过6倍交叉验证的实验结果,在表2中报告了S3DIS区域5的实验结果。如表 1 和表 2 所示,我们在两种验证选项上都实现了最先进的性能。表 1 显示,我们的最大模式 PointVector-XL 在总体精度 (OA)、平均精度 (mAcc) 和 mIOU 方面分别比 PointNeXt-XL 好 1.6%、3.1% 和 3.5%,而参数仅为 58%。同时,我们的计算消耗以 GFLOP 计算仅为 PointNeXt-XL 的 69%。计算消耗减少,因为邻居数量减少到 8 个。限制是我们大量使用 GroupConv (groups=channel),它在 PyTorch 中没有得到很好的优化,并且比标准卷积慢。因此,我们的推理速度比 PointNeXt-XL 低 6 个实例/秒。我们的模型在所有尺寸上都显示出更好的结果。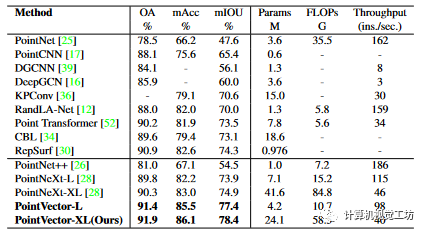 表1 使用 6 倍交叉验证在 S3DIS 上进行语义分割。方法按时间顺序排列。最高分和第二分以粗体标记。
表1 使用 6 倍交叉验证在 S3DIS 上进行语义分割。方法按时间顺序排列。最高分和第二分以粗体标记。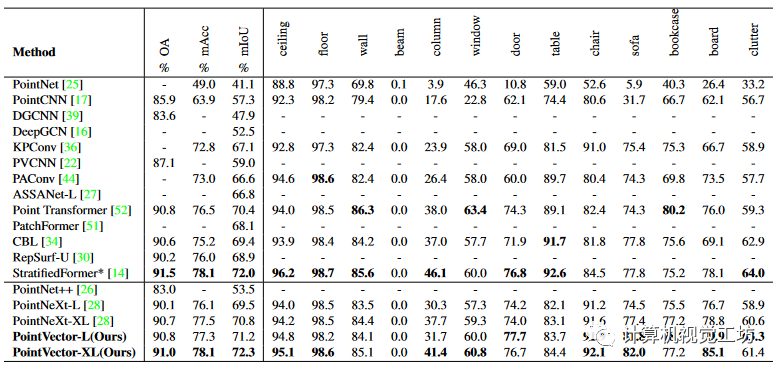 表2 S3DIS Area5 上的语义分割。* 表示 StratifiedFormer 使用 80k 点作为输入点。最高分和第二分以粗体标记。在S3DIS Area 5上,我们选择了PointNeXt报告的最佳结果进行比较,没有重复实验。我们的 PointVector-XL 模型在 mIOU 方面分别优于 StratifiedFormer和 PointNeXt-XL 0.3% 和 1.8%。StratifiedFormer 通过组合高分辨率和低分辨率键来扩展查询范围,同时有效提取上下文信息。尽管它的感受野比我们的模型要广泛得多,但我们仍然表现出有竞争力的表现。此外,我们的模型和它的实验设置存在一些差异,它有 80k 点的输入,比我们的 24k 点的输入大得多。此外,它在第一层使用 KPConv 而不是 Linear。看来这些措施的效果还是显着的。然而,由于实验配置的差异,这种比较对我们来说不够公平。稍后我们会同步其实验配置。此外,我们在 Area 5 上相同尺寸的模型显示出比 PointNeXt 更好的结果。PointVector-L 和 PointVector-XL 在 mIOU 方面分别比 PointNeXt-L 和 PointNeXt-XL 表现好 1.7% 和 1.5%,并且我们在大多数类别上表现更好。
表2 S3DIS Area5 上的语义分割。* 表示 StratifiedFormer 使用 80k 点作为输入点。最高分和第二分以粗体标记。在S3DIS Area 5上,我们选择了PointNeXt报告的最佳结果进行比较,没有重复实验。我们的 PointVector-XL 模型在 mIOU 方面分别优于 StratifiedFormer和 PointNeXt-XL 0.3% 和 1.8%。StratifiedFormer 通过组合高分辨率和低分辨率键来扩展查询范围,同时有效提取上下文信息。尽管它的感受野比我们的模型要广泛得多,但我们仍然表现出有竞争力的表现。此外,我们的模型和它的实验设置存在一些差异,它有 80k 点的输入,比我们的 24k 点的输入大得多。此外,它在第一层使用 KPConv 而不是 Linear。看来这些措施的效果还是显着的。然而,由于实验配置的差异,这种比较对我们来说不够公平。稍后我们会同步其实验配置。此外,我们在 Area 5 上相同尺寸的模型显示出比 PointNeXt 更好的结果。PointVector-L 和 PointVector-XL 在 mIOU 方面分别比 PointNeXt-L 和 PointNeXt-XL 表现好 1.7% 和 1.5%,并且我们在大多数类别上表现更好。
4.2 ScanObjectNN 上的 3D 对象分类
ScanObjectNN 包含大约 15000 个真实扫描对象,这些对象被分为 15 个类,具有 2902 个唯一对象实例。由于遮挡和噪声,该数据集面临重大挑战。与 PointNeXt 一样,我们选择 ScanObjectNN 的最难变体 PB T50 RS 并报告 平均值±标准差 总体精度和平均精度得分。对于我们在 ScanObjectNN 中的模型,SetAbstraction 中的邻居数量为 32。如表 3 所示,我们的 PointVector-S 模型在 OA 中实现了与 ScanObjectNN 相当的性能,而在 mAcc 中比 PointNeXtS 好 0.4%。这说明我们的方法并没有更偏向于某些类别,而且相对稳健。与 SA 模块相比,我们的方法在速度和规模方面处于劣势。由于我们引入了高维向量,因此与标准 SA 模块相比,我们在缩减之前生成了更多的计算。由于群卷积运算和三角函数,存在速度瓶颈。尽管推理速度比 PointNeXt 慢,但我们仍然比其他方法更快。我们的方法在分类任务上表现不佳,其中分类任务的下采样阶段需要最大缩减函数来保留显着的轮廓信息。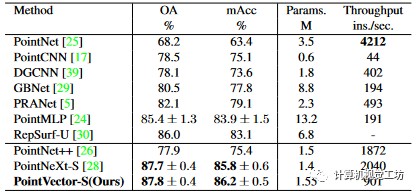 表3 ScanObjectNN 上的对象分类。最高分和第二分以粗体标记。
表3 ScanObjectNN 上的对象分类。最高分和第二分以粗体标记。
4.3 ShapeNetPart 上的 3D 对象部分分割
ShapeNetPart 是用于零件分割的对象级数据集。它由16个不同形状类别的16880个模型组成,每个类别2-6个零件,总共50个零件标签。如表 4 所示,我们的 PointVector-S 和 PointVector-S C64 模型都取得了与 PointNeXt 相当的结果。对于C=160的PointNeXt-S模型,参数数量较多,我们没有给出相应的模型版本。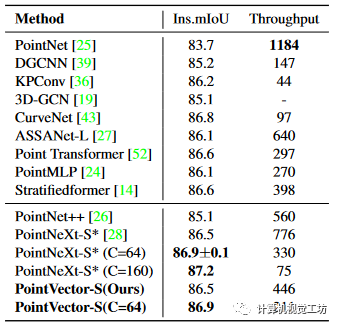 表4 ShapeNetPart 上的对象部分分割。*我们对这项任务的评估结果与该论文得出的吞吐量结果并不一致。其他作品我们没有一一测试。
表4 ShapeNetPart 上的对象部分分割。*我们对这项任务的评估结果与该论文得出的吞吐量结果并不一致。其他作品我们没有一一测试。
4.4 消融学习
我们在S3DIS上进行消融实验来验证该模块的有效性,由于PointVector-XL太大,我们对PointVector-L进行了修改。为了使比较公平,我们没有改变训练参数。面向矢量的点集抽象。我们将模块抽象为两个关键操作:sum和GroupConv(groups=Channel),这表明这部分模块是通道无关的,所以我们添加一个FC来混合通道信息。考虑到通道信息已经使用非GroupConv操作进行混合,通道混合Linear将被删除。卷积和分组卷积部分的卷积核大小为1×k,步幅大小为1。如表5所示,直接使用固定卷积会带来大量参数,并且与不规则结构的拟合效果非常差。点云。max+FC 显示出更好的性能,因为直观地聚合具有更高维度的特征可以保留更多信息。GroupConv 获得较低的 mIOU,因为它为组中的每个元素分配独立的权重;然而,求和时通道的 3D 向量的三个元素应赋予相同的权重。此外,sum+FC 与 sum+GroupConv 没有太大区别,因为 GroupConv 和通道混合 Linear 可以组合到 FC 的特定层中。相比之下,sum+GroupConv 的参数数量最少,性能最好,所以我们选择了它。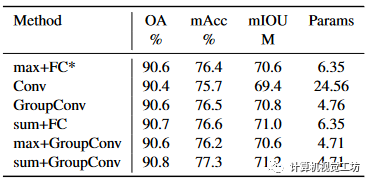 表5 VPSA的核心运营。我们将该模块抽象为 sum 和 GroupConv 操作,并替换这部分。FC 表示 Channel-FC 为线性。* 表示它充当基线。从标量扩展向量。为了验证基于矢量旋转的方法的有效性,我们将其与其他两种方法进行了比较。如表 6 所示,MLP 由两个 Linear 层以及一个 ReLU 激活层和 BatchNorm 层表示。Linear+direction表示Linear预测向量模长度,然后利用MLP得到单位向量作为方向,最终的模长度乘以单位向量。3.3节提出的基于旋转的向量扩展方法领先于其他方法并且参数较少。这表明基于旋转的方法可以使用更少的参数来获得更适合邻居特征的矢量表示。
表5 VPSA的核心运营。我们将该模块抽象为 sum 和 GroupConv 操作,并替换这部分。FC 表示 Channel-FC 为线性。* 表示它充当基线。从标量扩展向量。为了验证基于矢量旋转的方法的有效性,我们将其与其他两种方法进行了比较。如表 6 所示,MLP 由两个 Linear 层以及一个 ReLU 激活层和 BatchNorm 层表示。Linear+direction表示Linear预测向量模长度,然后利用MLP得到单位向量作为方向,最终的模长度乘以单位向量。3.3节提出的基于旋转的向量扩展方法领先于其他方法并且参数较少。这表明基于旋转的方法可以使用更少的参数来获得更适合邻居特征的矢量表示。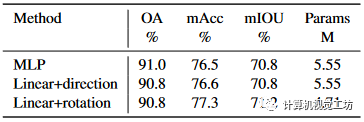 表6 获得矢量表示的方法。向量维度。我们需要探索向量表示的效果与维度之间的联系。直观上,高维向量比较低维向量更能表达特征。表7显示3D向量具有更好的特征表达能力,并且参数数量的增加不是很大。没有我们的向量表示的 mIOU 仍然高于 PointNeXt 的结果。我们将在补充材料中讨论我们网络其他部分的有效性。
表6 获得矢量表示的方法。向量维度。我们需要探索向量表示的效果与维度之间的联系。直观上,高维向量比较低维向量更能表达特征。表7显示3D向量具有更好的特征表达能力,并且参数数量的增加不是很大。没有我们的向量表示的 mIOU 仍然高于 PointNeXt 的结果。我们将在补充材料中讨论我们网络其他部分的有效性。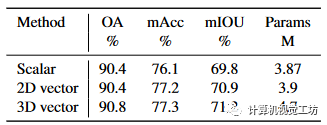 表7 不同维度的向量。鲁棒性。表 8 表明我们的方法对于分层变压器的各种扰动非常稳健。我们使用的球查询无法在缩放点云中获得相同的邻居。如果查询半径一起缩放,那么mIOU是不变的。这表明我们的方法也具有尺度不变性。
表7 不同维度的向量。鲁棒性。表 8 表明我们的方法对于分层变压器的各种扰动非常稳健。我们使用的球查询无法在缩放点云中获得相同的邻居。如果查询半径一起缩放,那么mIOU是不变的。这表明我们的方法也具有尺度不变性。 表8 S3DIS 的稳健性研究 (mIOU %)。我们在测试中应用了z轴旋转(π/2、π、3π/2)、平移(±0.2)、缩放(×0.8、×1.2)和抖动。PointTr:点转换器。分层:分层变压器。
表8 S3DIS 的稳健性研究 (mIOU %)。我们在测试中应用了z轴旋转(π/2、π、3π/2)、平移(±0.2)、缩放(×0.8、×1.2)和抖动。PointTr:点转换器。分层:分层变压器。
5 结论和局限性
我们引入了 PointVector,它在 S3DIS 语义分割任务上取得了最先进的结果。我们的面向向量的点集抽象以更少的参数改进了局部特征聚合。基于旋转的矢量扩展方法弥补了矢量表示和标准特征形式之间的差距。通过优化两个独立的视角,取得了更好的效果。此外,我们的方法对各种扰动表现出鲁棒性。值得注意的是,进一步探索向量表示的含义可能会揭示其他应用,即主导邻居选择。我们的方法的速度受到分组卷积实现的限制。未来工作的一个有趣的途径包括探索三个维度以上的旋转以及将四维旋转分解为平面旋转的组合。此外,分量对齐后的求和比标量投影更符合我们的假设。
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:
[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;
[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;
[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。
[三维重建方向]NeRF、colmap、OpenMVS、MVSNet等。
[无人机方向]四旋翼建模、无人机飞控等。
除了这些,还有求职、硬件选型、视觉产品落地等交流群。
大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
3.1 「3D视觉从入门到精通」技术星球
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
3.2 3D视觉岗求职星球
本星球:3D视觉岗求职星球 依托于公众号「3D视觉工坊」和「计算机视觉工坊」、「3DCV」,旨在发布3D视觉项目、3D视觉产品、3D视觉算法招聘信息,具体内容主要包括:
收集汇总并发布3D视觉领域优秀企业的最新招聘信息。
发布项目需求,包括2D、3D视觉、深度学习、VSLAM,自动驾驶、三维重建、结构光、机械臂位姿估计与抓取、光场重建、无人机、AR/VR等。
分享3D视觉算法岗的秋招、春招准备攻略,心得体会,内推机会、实习机会等,涉及计算机视觉、SLAM、深度学习、自动驾驶、大数据等方向。
星球内含有多家企业HR及猎头提供就业机会。群主和嘉宾既有21届/22届/23届参与招聘拿到算法offer(含有海康威视、阿里、美团、华为等大厂offer)。
发布3D视觉行业新科技产品,触及行业新动向。

第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
科研论文写作:
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
[2]面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]深度剖析面向机器人领域的3D激光SLAM技术原理、代码与实战
[2]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[3](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[4]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[5]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建:
[2]基于深度学习的三维重建MVSNet系列 [论文+源码+应用+科研]
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2] 国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
[4]面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
[5]如何将深度学习模型部署到实际工程中?(分类+检测+分割)
无人机:
[1] 零基础入门四旋翼建模与控制(MATLAB仿真)[理论+实战]

















 2453
2453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









