






前言
本篇介绍分组查询注意力机制。
在大模型技术中,GQA(Grouped Query Attention)是一种注意力机制,它介于MHA(Multi-Head Attention)和MQA(Multi-Query Attention)之间,旨在结合两者的优点,以实现在保持MQA推理速度的同时接近MHA的精度 。
MHA是一种基础的注意力机制,它通过将输入分割成多个头(heads)来并行计算注意力,每个头学习输入的不同部分,最终将结果合并,以捕获序列的不同方面信息 。
MQA则是一种优化的注意力机制,它通过让所有头共享相同的键(keys)和值(values),减少了参数量和计算量,从而加快了推理速度,但可能会牺牲一些精度 。
GQA作为MHA和MQA的折中方案,它将查询头(query heads)分组,每组共享一个键和值,而不是所有头都共享。这样,GQA能够在减少计算量的同时,保持更多的多样性,从而在推理速度和模型精度之间取得平衡 。
-
GQA-1:一个单独的组,等同于 Multi-Query Attention (MQA)。
-
GQA-H:组数等于头数,基本上与 Multi-Head Attention (MHA) 相同。
-
GQA-G:一个中间配置,具有G个组,平衡了效率和表达能力。
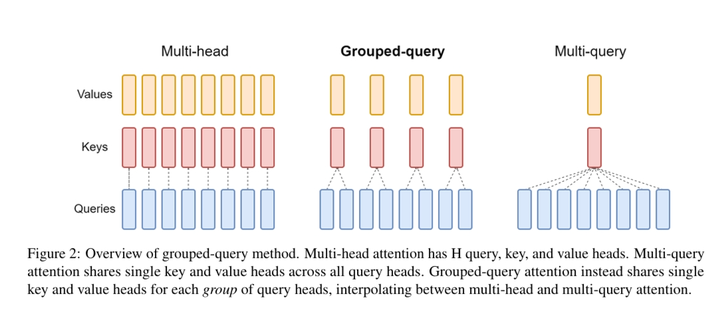
具体来说,GQA通过分组的方式,减少了需要缓存的键和值的数量,从而减少了内存的使用,同时由于不是所有头都共享键和值,它能够比MQA更好地保持MHA的多样性和精度 。例如,如果GQA使用2个头的键和值,那么每个组包含4个查询头,这样在保持速度的同时,精度损失会比MQA小 。
此外,GQA的实现并不复杂,可以通过对现有MHA模型进行少量的训练调整来实现,这使得从MHA到GQA的过渡相对容易 。GQA已经在一些大型语言模型中得到应用,例如Meta开源的LLAMA系列模型 。
总结来说,GQA是一种有效的注意力机制,它通过在MHA和MQA之间进行插值,旨在实现更快的推理速度和接近MHA的模型质量,是高负载系统优化的有力工具 。
class MultiQueryAttention(Attention):
r"""
https://arxiv.org/pdf/1911.02150.pdf
"""
def __init__(self, word_size: int = 512, embed_dim: int = 64, n_query:int=8) -> None:
super().__init__(word_size, embed_dim)
self.n_query = n_query
self.proj = nn.Linear(in_features=embed_dim * n_query,
out_features=embed_dim, bias=False)
delattr(self, 'query')
self.querys = nn.ModuleList([
nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
for _ in range(n_query)
])
self.key = nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
self.value = nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
def forward(self, x: Tensor, mask:Optional[BoolTensor]=None) -> Tensor:
K = self.key(x)
V = self.value(x)
Z_s = torch.cat([
self.self_attention(query(x), K, V, mask) for query in self.querys
], dim=1)
Z = self.proj(Z_s)
return Z
class GroupedQueryAttention(Attention):
r"""
https://arxiv.org/pdf/2305.13245.pdf
"""
def __init__(self, word_size: int = 512, embed_dim: int = 64,
n_grouped: int = 4, n_query_each_group:int=2) -> None:
super().__init__(word_size, embed_dim)
delattr(self, 'query')
delattr(self, 'key')
delattr(self, 'value')
self.grouped = nn.ModuleList([
MultiQueryAttention(word_size, embed_dim, n_query=n_query_each_group)
for _ in range(n_grouped)
])
self.proj = nn.Linear(in_features=embed_dim * n_grouped,
out_features=embed_dim, bias=False)
def forward(self, x: Tensor, mask:Optional[BoolTensor]=None) -> Tensor:
Z_s = torch.cat([head(x, mask) for head in self.grouped], dim=1)
Z = self.proj(Z_s)
return Z
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2135
2135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









