




 本文主要探讨了两篇关于安全参数估计和分布式系统中传感器攻击的文献。第一篇研究了攻击检测与估计的耦合问题,指出过于严厉的攻击判断可能降低估计精度。第二篇介绍了将攻击信号建模为状态向量,并采用自适应卡尔曼滤波器和优化融合准则来处理传感器攻击。文献中涉及的难点包括理解和应用arginf而非argmax,以及理解融合估计量的下标含义。
本文主要探讨了两篇关于安全参数估计和分布式系统中传感器攻击的文献。第一篇研究了攻击检测与估计的耦合问题,指出过于严厉的攻击判断可能降低估计精度。第二篇介绍了将攻击信号建模为状态向量,并采用自适应卡尔曼滤波器和优化融合准则来处理传感器攻击。文献中涉及的难点包括理解和应用arginf而非argmax,以及理解融合估计量的下标含义。
工作内容
论文
基本结束了名为《Secure parameter estimation: Fundamental tradeoffs》(安全参数估计:基本的权衡)的会议文献。
这篇文献的着眼点,也就是想解决的问题,其实在于这一对矛盾:
判断出受攻击的传感器并削弱其影响是有助于提高估计精度的。但是如果误判了受攻击的传感器,也就是说发生了虚警,实际上是会减弱估计精度。而噪声的存在使我们并不能精确地判断出是否存在攻击。所以实际上对攻击判断的“严厉性”的高低是矛盾的,而且因此攻击的检测与估计是耦合的,不能简单解耦(可能会使估计变成次优)
本文就是在两者耦合的前提下进行的建模和解决,但是最后对最终分解出来的两个子问题的解决确实未能理解。
开启了一篇新的文献,名为《Fusion Estimation for FDI Sensor Attacks in Distributed Systems》(分布式系统中虚假数据注入传感器攻击的融合估计),本文献同样为一篇会议论文。出自2020 IEEE第16届控制与自动化国际会议(ICCA)。
本文的关键点有以下三个:
- 将攻击信号建模为状态向量,对攻击进行估计,后续在受攻击量测中可以讲攻击进行剔除;
- 使用自适应卡尔曼滤波器;
- 引入补偿因子,设计一种优化的承重融合准则,来做融合。
目前看完了系统建模部分。将攻击向量并入了状态向量中(对状态向量做了增广),据文献说可以实现对攻击的估计,目前还不了解如何实现的。
引申
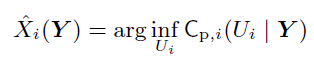
这里为什么要用arg inf 而不是用arg max?
因为后面的C函数实际是一个似然函数,因为Y是果,U是X的估计量,实际是代表了状态值,所以是因。该函数是执果索因。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









