







请先看【专栏介绍文章】:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等)
文章目录
- 背景介绍
- 数据集
- 评估指标
- 参赛队伍
- 主要ideas和架构
- 各团队的具体方法
- 第1名EMSR:蒸蒸日上
- 第2名XiaomiMM:SPAN加加速就第2了
- 第3名ShannonLab:Reparameterization深层特征提取部分是不增加计算开销同时提升性能的有效手段
- 第4名TSSR:Method只有一句话就拿了第4
- 第5名Davinci:大杂烩
- 第6名SRCB:我不配出现在报告中?
- 第7名Rochester:SPAN变变变
- 第8名mbga:SPAN继续变变变
- 第9名IESR:DIPNet轻量化
- 第10名ASR:同样的思路为什么我第10你第9
- 第11名VPEG_O:SAFMN改进1
- 第12名mmSR:SAFMN改进2
- 第13名ChanSR:高通滤波器助力捕获边缘细节
- 第14名Pixel Alchemists:在线卷积重新参数化
- 第16名LZ:卷积分解
- 第17名Z6:SPAN+RFDN
- 第18名TACO SR:新卷积块TenInOneConv
- 第19名AIOT AI:重新组合模块
- 第20名JNU620:RepRFN+RLFN
- 第21名LVGroup HFUT:SPAN卷积重新参数化
- 第23名YG:成熟的文章
- 第24名NanoSR:我不配出现在参赛队伍里?
- 第25名MegastudyEdu Vision AI:大核卷积
- 第26名XUPTBoys:在轻量化赛道是不是有点复杂了
- 第27名MILA:应该是一篇不错的文章
- 第28名AiMF SR:
- 第29名EagleSR:丢了
- 第30名BVIVSR:带着论文来参赛
- 第31名HannahSR:改进SPAN中原点对称激活函数存在的问题
- 第32名VPEG_C:在这也能看见Restormer
- 第33名CUIT HTT:引入频域操作
- 第34名GXZY AI:DVMSR中的RSSB替换为MambaIR中的RSSB
- 第36名IPCV:HiT-SR实战
- 第37名X-L:PartialConv+通道分割
- 第38名Quantum Res:轻量化MambaIRv2蒸馏网络
- SylabSR:完全放弃性能?
- NJUPCA:空间域与频域结合
- DepthIBN:改进卷积层
- Cidaut AI:只有3个块
- IVL:SPAN的块集成到EFDN主干中
- 总结与思考
- 所属专栏
- 相关链接
- 与我联系
背景介绍
报告链接:The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
第十届NTIRE2025单图像高效超分辨率(Single-Image Efficient Super-Resolution,ESR)挑战赛,旨在推进优化关键计算指标(即运行时间、参数和FLOP)的深度模型的开发,至少在DIV2K_LSDIR_valid上PSNR达到26.90,在DIV2K_LSDIR_test上PSNR达到26.99。
Baseline介绍:EFDN(Edge-enhanced Feature Distillation Network for Efficient Super-Resolution) 是NTIRE2023的第一名,
- idea:块组合、架构搜索和损失设计的组合;
- 参数量为0.276 M;
- 在DIV2K_LSDIR_valid和DIV2K_LSDIR_test的平均 PSNR 分别为 26.93 dB 和 27.01 dB(比挑战赛的要求高,说明给了容错);
- 使用 PyTorch 2.0.0+cu118 和单个 NVIDIA RTX A6000 GPU 在验证集和测试集上的平均运行时间为 22.18ms。
- 大小为 256 × 256 的输入的 FLOP 数为 16.70 G。
挑战赛的目标:(i)促进单想象高效超分辨率领域的研究,(ii)促进各种方法效率之间的比较,以及(iii)为学术和工业参与者提供一个平台参与、讨论和潜在建立合作。
总结:设计一个网络,达到EFDN验证集和测试集指标要求,比较runtime, parameters, and FLOPs,指标越低越好。
数据集
- DIV2K:共1000张图像,800张训练集、100张验证集、100张测试集;
- LSDIR:共86,991张图像,84,991训练集、1000张验证集、1000张测试集;
- LR:x4,BD(Bicubic);
在推理阶段,使用DIV2K验证集和LSDIR验证集。在测试阶段,使用DIV2K测试集和LSDIR测试集。测试 HR 隐藏,防止操作。
允许使用额外数据集(如Flickr2K)增强训练,严禁将验证集和测试集加入训练,仅使用DIV2K和LSDIR的验证集和测试集。
评估指标
- 验证和测试的PSNR:裁掉边缘4个像素边界计算(因为是x4)。
- runtime:在验证和测试的200个LR上计算平均运行时间作为最终结果。
- FLOPs:256×256的输入图像上计算。
- parameters:模型的参数量。
上述指标中,runtime是最重要的!
排名计算遵循上一届比赛的规则: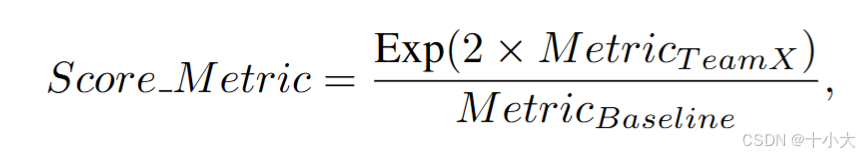
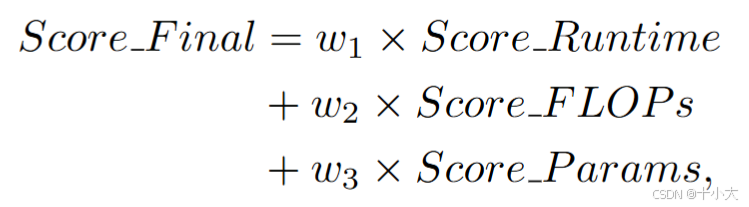
w1、w2 和 w3 分别设置为 0.7、0.15 和 0.15。
EFDN 模型、预训练参数和验证演示脚本:https://github.com/Amazingren/NTIRE2025_ESR
参赛队伍
共244人参与,43支队伍成绩有效(一如既往的激烈,去噪赛道你看看人家。。。):
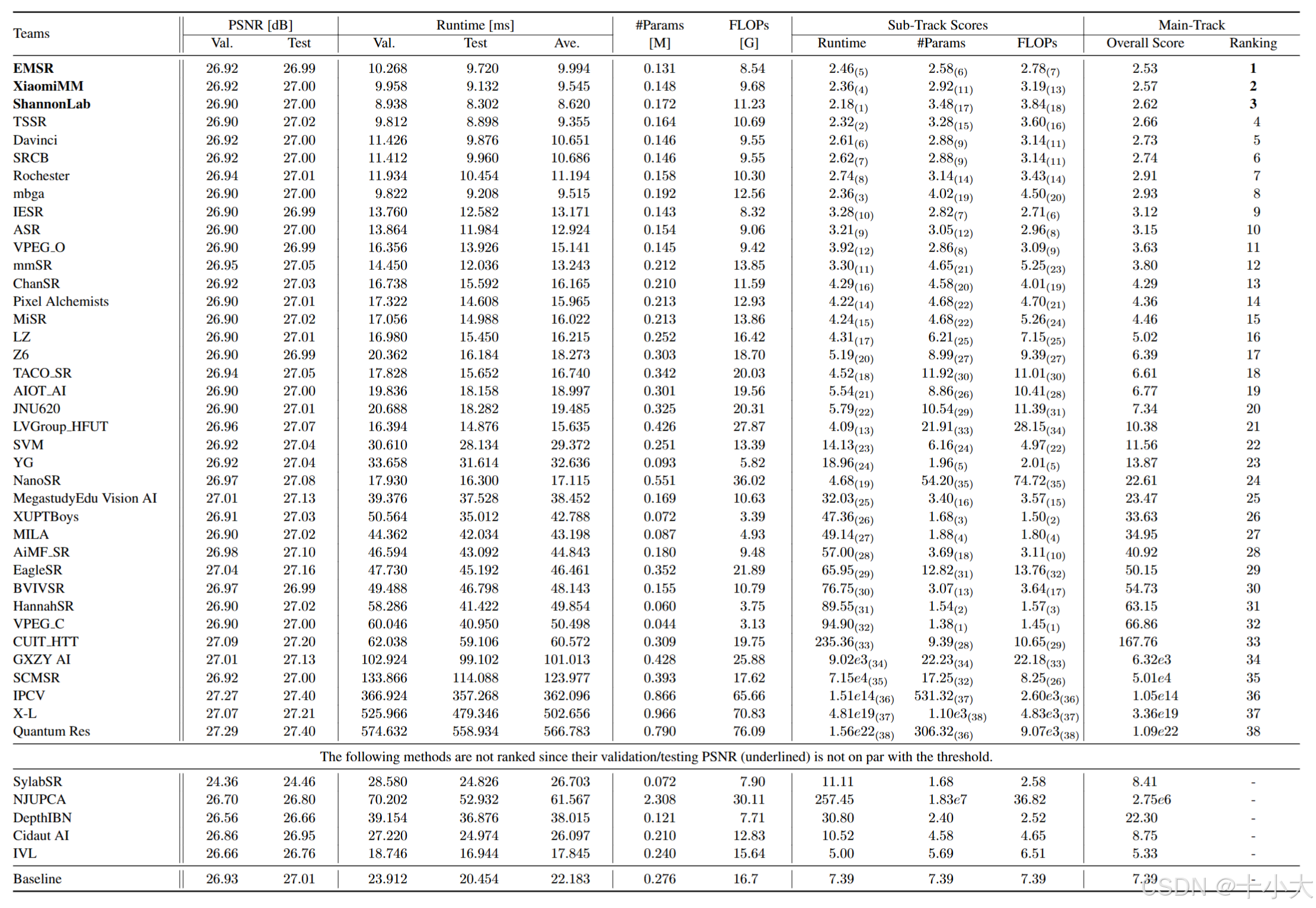
综合评定标准下,几个有特点的成绩:
- 第一是EMSR,第二的XiaomiMM是去年比赛的冠军;
- PSNR:性能最优的是Quantum Res;
- Runtime:ShannonLab的运行时间最少,前 13 个团队展示了平均运行时间低于 16 ms;
- Params:VPEG_C的模型参数只有0.044M,HannahSR 和 XUPTBoys的模型参数分别为0.060M和0.072M;
- FLOPs:VPEG_C的FLOPs只有3.13G;
主要ideas和架构
- Distillation(蒸馏):在推理过程中在不增加计算成本的情况下保持PSNR性能的有效方法,自蒸馏和渐进式学习;
- Re-parameterization(重新参数化):训练阶段参数化具有多个操作的卷积层,推理过程中重新参数化卷积的多个操作为单个卷积;
- Parameter-free attention mechanism(无参数注意机制):XiaomiMM 提出了一种基于无参数注意力的快速无参数注意力网络,保持PSNR的同时实现了最低的运行时间;
- Multi-scale information and hierarchical module design(多尺度信息和分层模块设计):保持性能的手段;
- Network pruning(网络剪枝):压缩网络的同时不会造成性能损失;
- 新架构探索:除了CNN和Transformer,还有用mamba的;
- 其他:网络架构搜索、ViT、频域处理、多阶段设计、高级训练策略等;
各团队的具体方法
前情提要:枯燥乏味,全是SPAN。去年的冠军含金量还在上升!即插即用模块改进大赏!
第1名EMSR:蒸蒸日上
Title: Distillation-Supervised Convolutional Low-Rank Adaptation for Efficient Image Super-Resolution
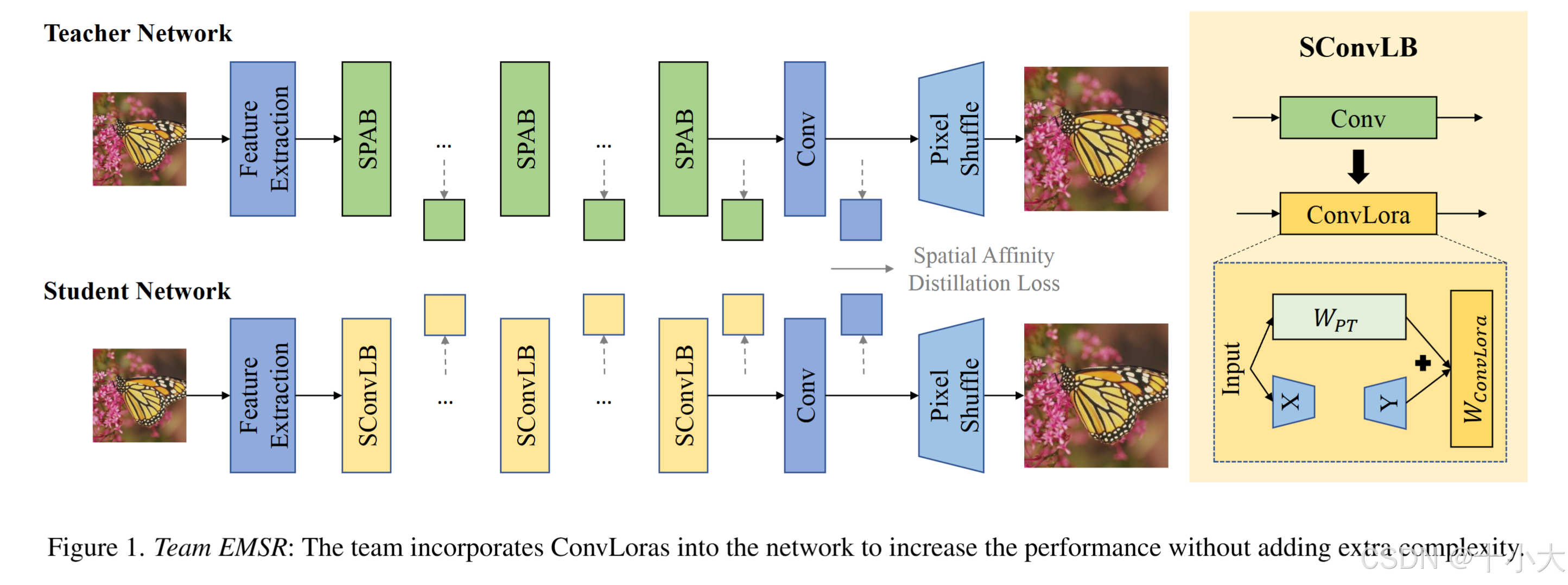
- 网络结构:Teacher-student网络,基于SPAN改进,受ConvLora启发提出SconvLB,合并到SPAB中而不增加复杂度。
- 损失函数:
- 在每个SconvLB后应用蒸馏损失(spatial affinity-based knowledge distillation):
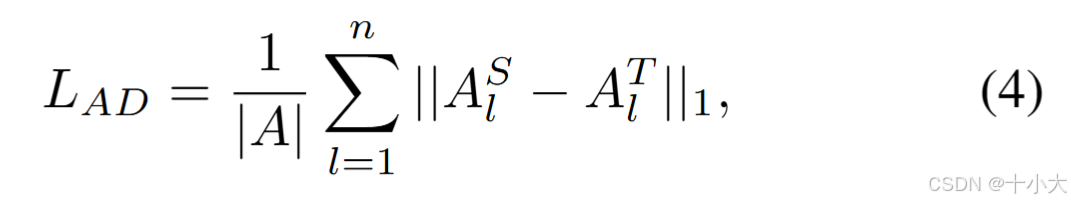
- 像素级蒸馏损失:
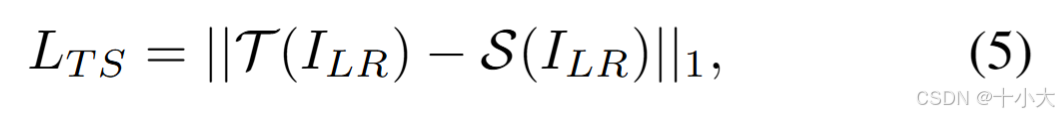
- L2损失:
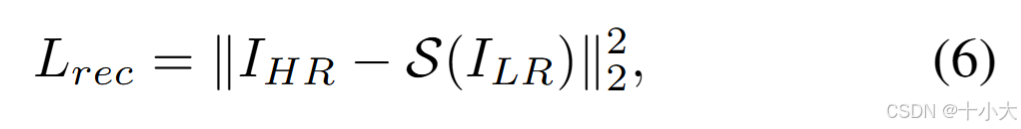
- 总损失:
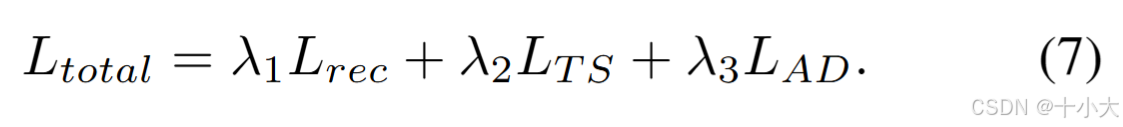
- 在每个SconvLB后应用蒸馏损失(spatial affinity-based knowledge distillation):
- 训练策略:训练集使用DIV2K和LSDIR,常规数据增强。两阶段训练,第一阶段HR随机裁剪为192 × 192,第二阶段扩大为256 × 256,使用EMA。
PS:
SPAN:Swift Parameter-free Attention Network for Efficient Super-Resolution
ConvLora:CONVLORA AND ADABN BASED DOMAIN ADAPTATION VIA SELF-TRAINING
第2名XiaomiMM:SPAN加加速就第2了
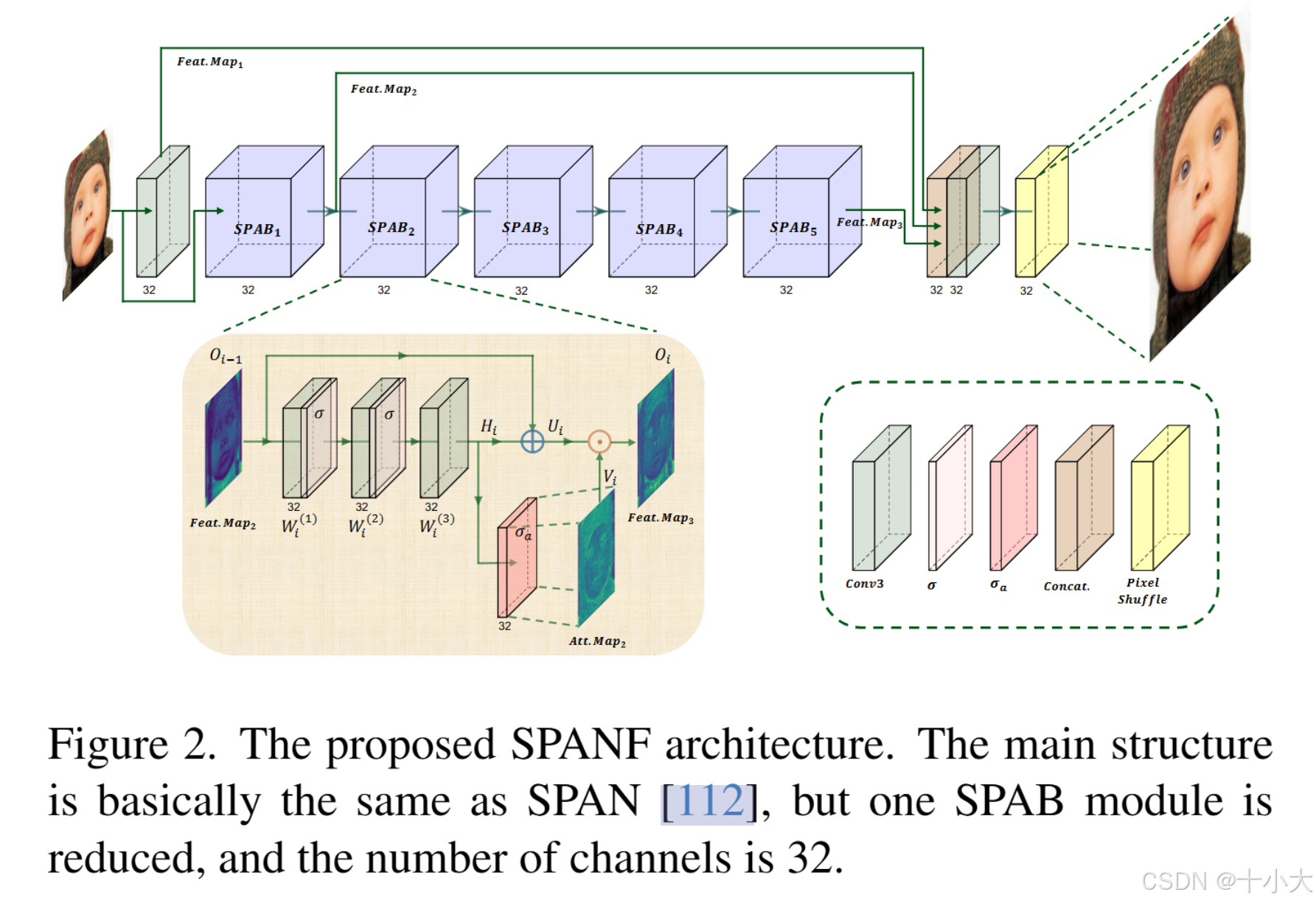
Title: SPANF
SPANF和原始SPAN结构图对比
SPANF:
SPAN:
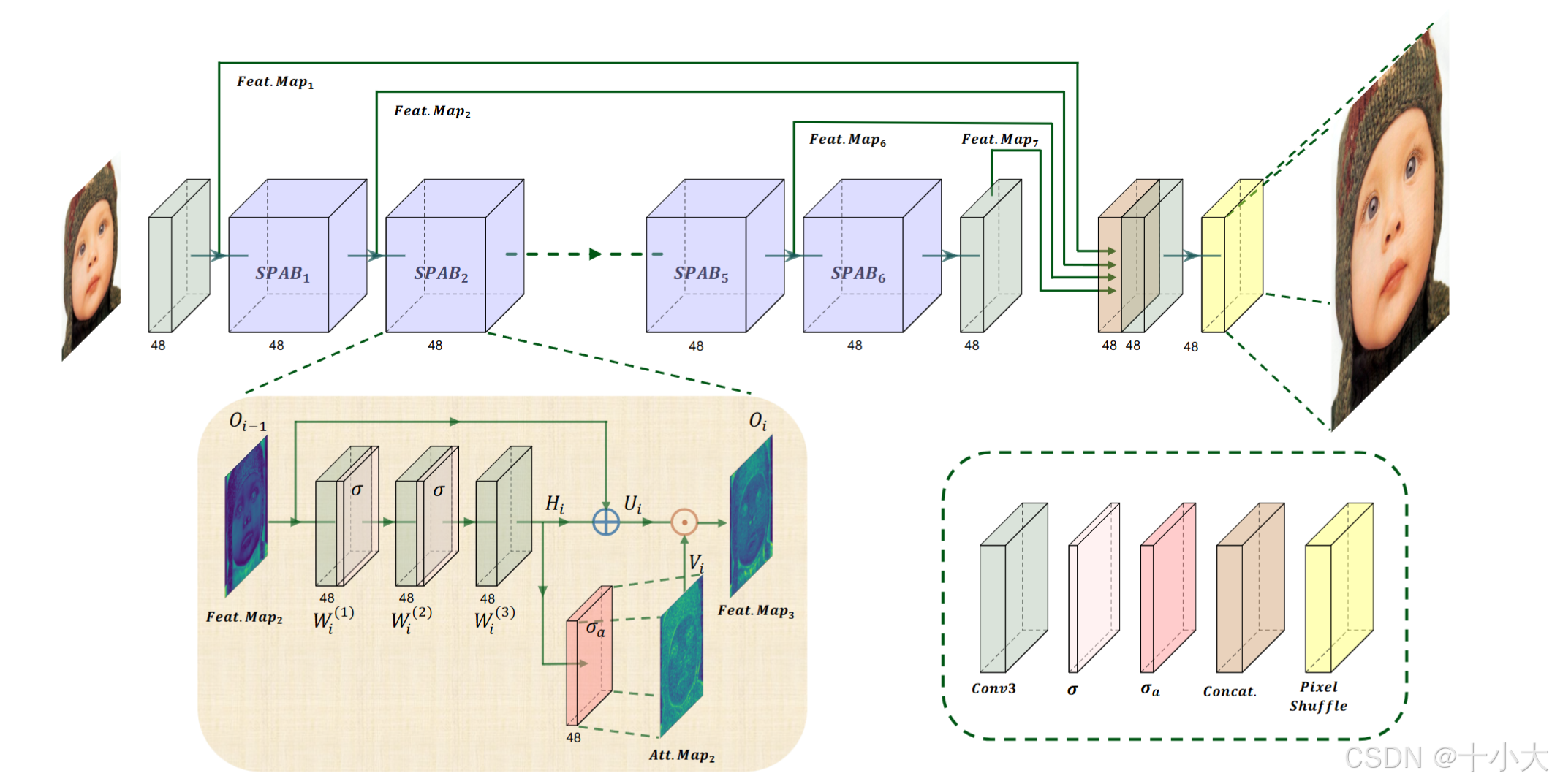
- 网络结构:SPAN的加速变体SPANF。
- 主要改进:删除最后一个SPAB块,通道数增加到 32,第一个卷积层替换为最近邻上采样。
- 训练策略:训练集使用DIV2K 和 LSDIR,初始HR为256 × 256,使用L1损失训练,然后使用L1和L2损失微调,HR为512×512。共四个模型(batch64和128,L1和L2损失),集成四个模型参数作为最终模型。
PS:学习轻量化方式,删除冗余块(原始SPAN是6个SPAB块),降低通道数(原始SPAN通道数是48)。报告中写的“增加通道数为32”显然是不对的,做轻量化哪有增加通道数的。

第3名ShannonLab:Reparameterization深层特征提取部分是不增加计算开销同时提升性能的有效手段
Title: Reparameterization Network for Efficient Image Super-Resolution
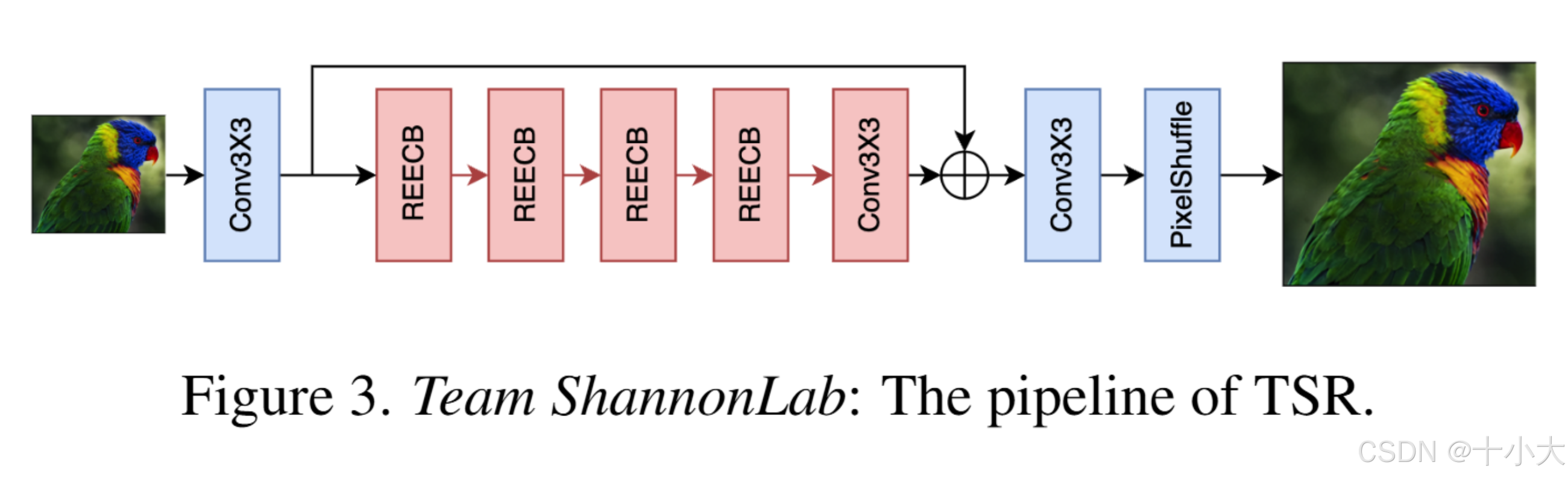
- 网络结构: ECBSR 和 SPAN 灵感结合。首先,他们通过在输入张量进入ECB模块之前引入1x1卷积层来优化ECB模块。处理后,另一个 1x1 卷积恢复原始通道维度,同时合并残差连接。在推理过程中,这些组件可以通过重新参数化合并到标准的 3x3 卷积中,从而在不增加计算开销的情况下增强 ECB 模块的有效性。如图3所示,TSR的完整模型架构包括一个浅层特征提取卷积、重构卷积、PixelShuffle模块和四个REECB块,由堆叠的优化ECB组成。
- 训练策略:使用 DIV2K 和 LSDIR 训练集+数据增强,5步训练。HR从256×256逐渐变为512×512,mini-batch、损失函数、学习率依次变化。
第4名TSSR:Method只有一句话就拿了第4
Title: Light Network for Efficient Image Super-Resolution
- Method:重新参数化和注意力机制结合。
- 训练策略:3步训练,HR大小、mini-batch、损失函数、学习率逐渐变化。
第5名Davinci:大杂烩
Title: PlayerAug
核心思想:SPAN作为base,SwinFIR作为pipeline,CoDe中提出的内容解耦策略,Ref中的预训练微调范式,以及所讨论的模型修剪和知识蒸馏等模型压缩技术。
Method:SPAN最后一层的模型剪枝,l2 范数基线,并引入混合增强尽可能保留原始参数分布。
训练策略:在 DIV2K和LSDIR上训练,HR大小为512×512。L1损失。
第6名SRCB:我不配出现在报告中?
Title: SPAN with pruning
PS:去噪赛道和x4超分赛道三星都是冠军,ESR赛道弃赛了?还是报告里忘写了?
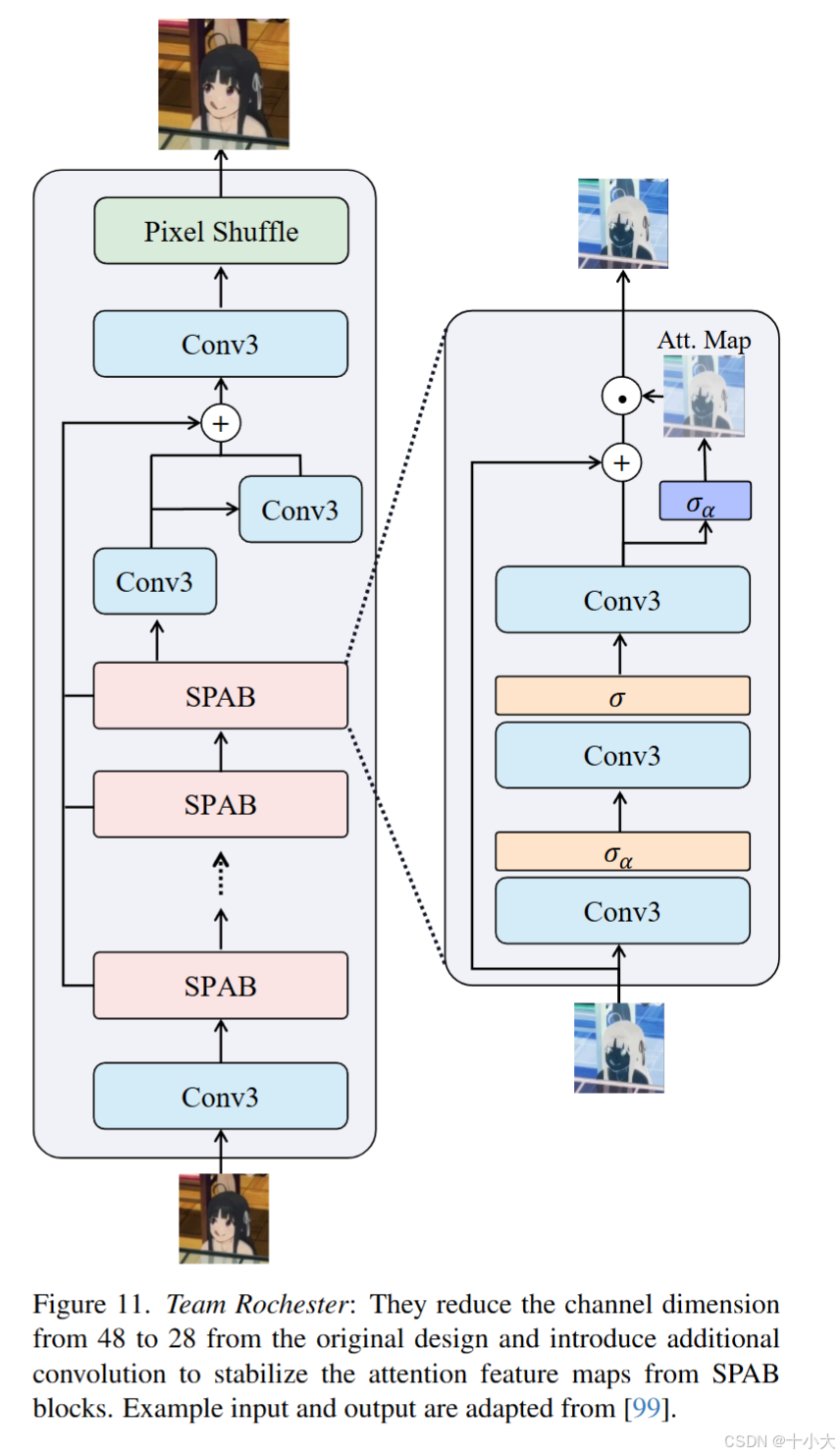
第7名Rochester:SPAN变变变
Title: ESRNet: An enhanced version of SPAN for Efficient Super-Resolution
-
SPAN变体ESRNet,降低计算开销、增强训练稳定性,提高推理速度的同时性能近似。
-
ESRNet相对于SPAN的改动:
- 轻量化卷积替代原始卷积;
- 通道数从48降低到26;
- 上述改动提升了验证速度,降低模型参数和FLOPs,参数数量和 FLOP 约为SPAN的一半;
-
三阶段训练策略:
- Char损失训练,lr为2e-4;
- lr从2e-4线性降低到2e-5;
- L2损失微调,lr从2e-5降低到1e-6;
PS:SPAN多了一种轻量化方式:卷积变轻量化卷积。
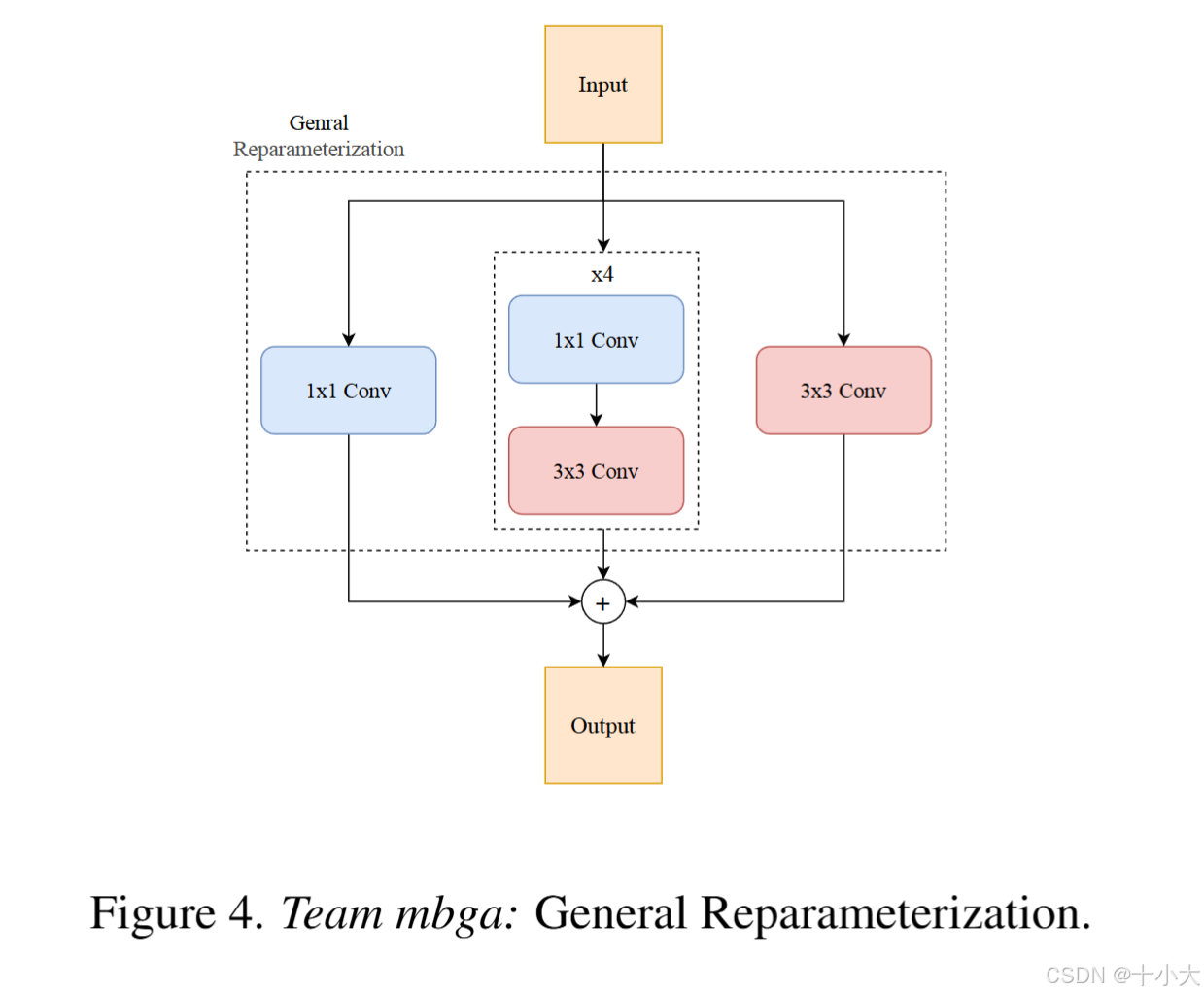
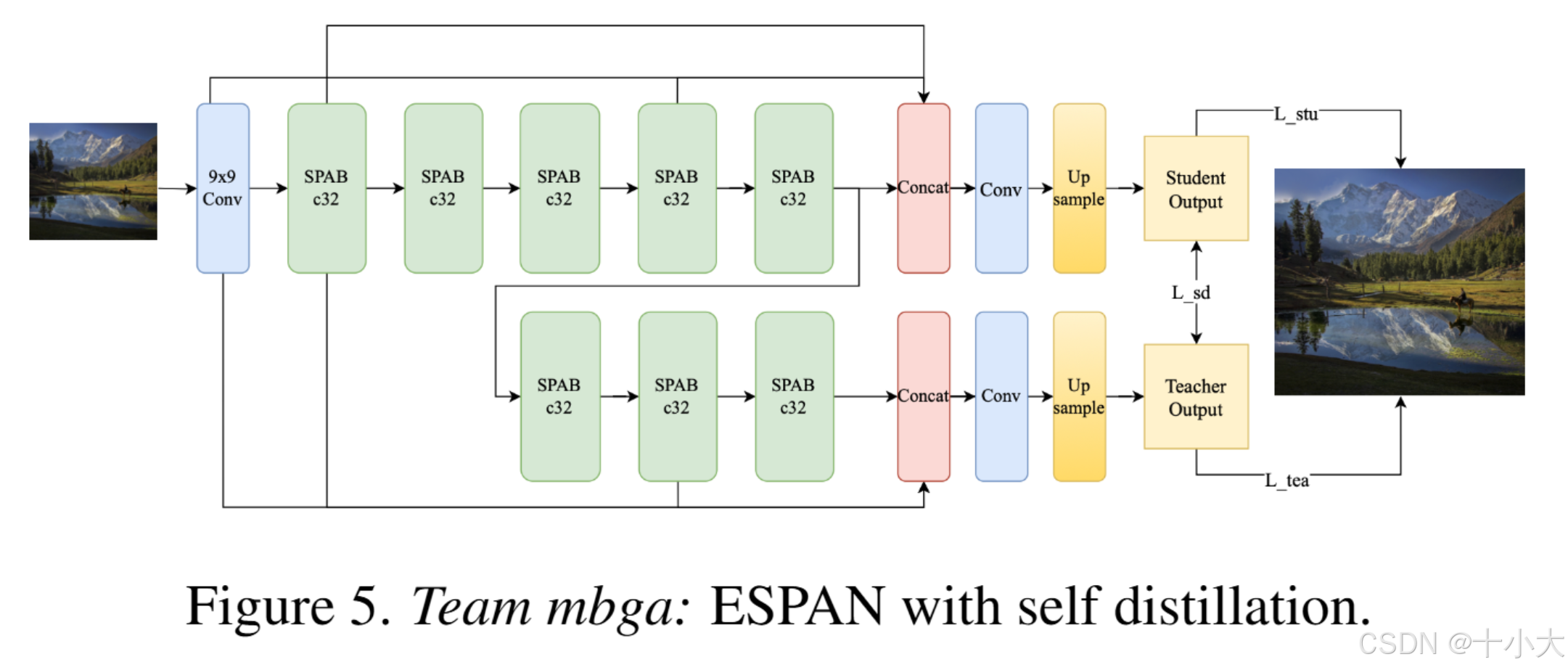
第8名mbga:SPAN继续变变变
Title: Espanded SPAN for Efficient Super-Resolution
- Method:基于 SPAN 的 ESPAN。评估通道深度,将通道数设置为32比28效率高。网络总深度为6,用9×9Conv比3×3Conv更快。以上效率的提高都是基于A6000 GPU。
- Reparameterization:4个(1×1Conv+3×3Conv)分支 + 1×1Conv分支 + 3×3Conv分支。
- Self distillation and progressive learning:
- Frequency-Aware Loss:discrete cosine transform (DCT)损失+L1损失。
- 训练策略:两大阶段共5步。
PS:SPAN通道数从48降到32优于降到28,9×9卷积核优于3×3。用了Reparameterization和自蒸馏。
第9名IESR:DIPNet轻量化
Title: Inference Efficient Super-Rosolution Net
技巧类方法IESRNet,Baseline为23年的冠军DIPNet,以及相应的Tricks。
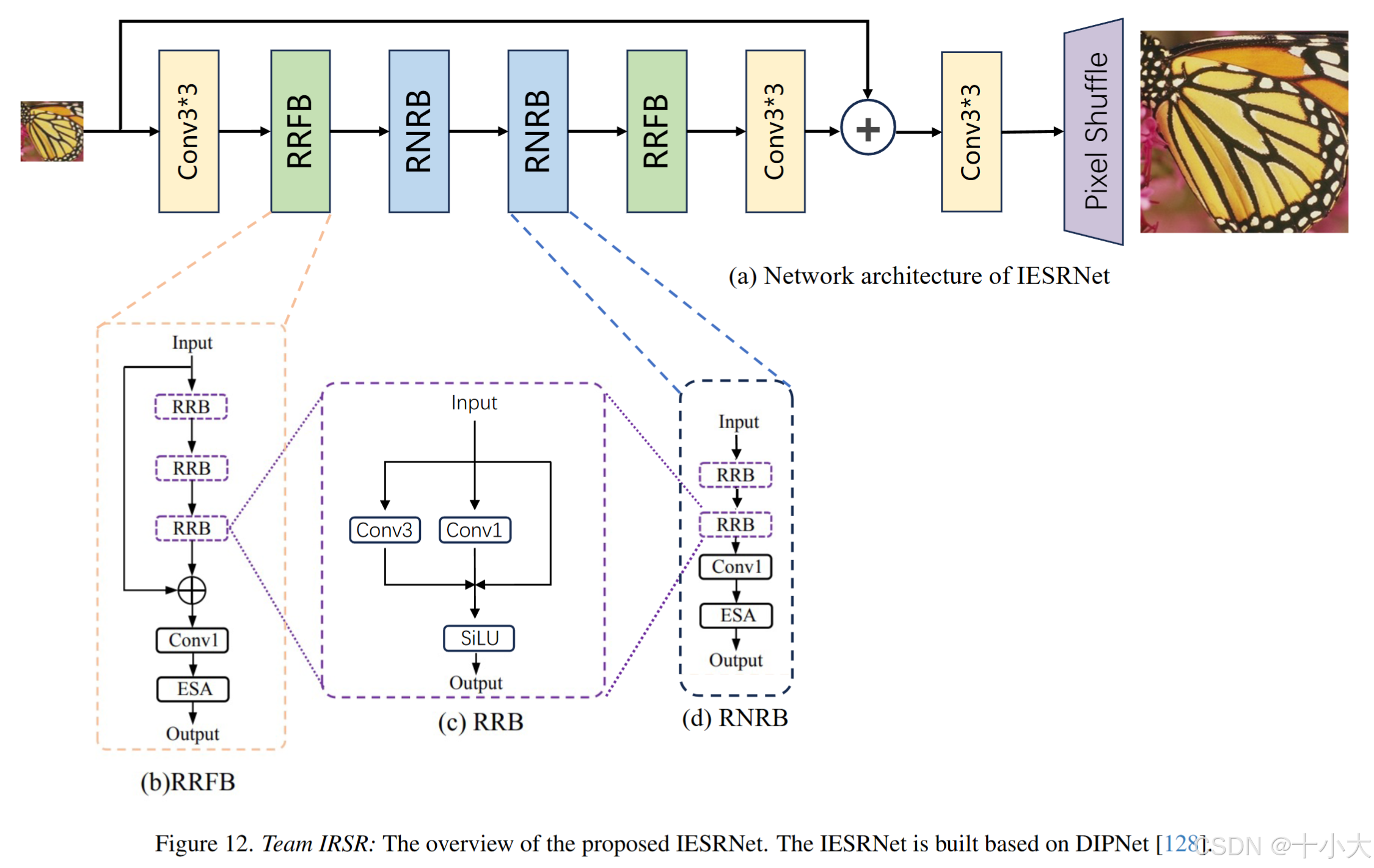
Tricks描述:
- 去除Conv中的Bias:bias是Conv中的低效操作,删除除了ESA模块外的所有卷积层偏置;
- 更少的残差链接:将DIPNet的两个中间的RRFB替换为重新参数化无残差块(RNRB);
- Conv的通道数:48通道的3×3Conv比30通道的更快,FLOPs翻倍。于是将通道数设置为32,ESA的通道数为16;
- 高效的激活函数:用SiLU替换原始结构的全部激活函数;
- 重新参数化:采用重新参数化来增强模型的表征能力,使用复杂的重新参数化结构在训练期间进行训练,并在推理过程中将它们合并到常规卷积中,而不会产生额外的计算开销;
训练策略:多阶段训练。
PS:无论是DIPNet还是SPAN,Tricks应该都通用。
第10名ASR:同样的思路为什么我第10你第9
Title: ASR
基于DIPNet,前年runtime赛道冠军。
轻量化方式:
- 通道数为32,ESA通道数为16;
- 重新参数化所有的3×3Conv;
- 残差链接的3×3Conv变成1×1Conv;
- SiLU替换RELU;
第11名VPEG_O:SAFMN改进1
Title: SAFMNv3: Simple Feature Modulation Network for Real-Time Image Super-Resolution
SAFMNv3:
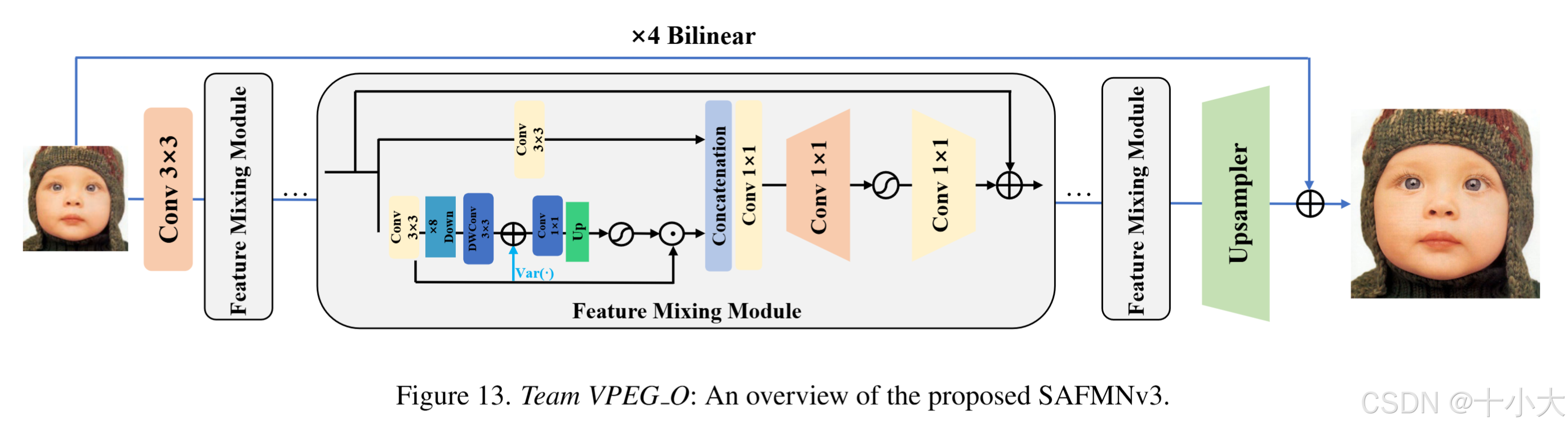
SAFMN原始结构:
主要改进:FMM块中的SAFM层,SAFMNv3不拆分通道,使用两个3×3卷积来投影输入,并在通道较少的分支中使用方差约束特征调制算子,最后聚合特征的这两个部分,然后通过前馈神经网络细化聚合特征。
SAFMN的FMM块是8个,通道数为36;
SAFMNv3的FMM块是6个,通道数为40;
PS:SAFMN原作者团队的方法:https://github.com/sunny2109/SAFMN
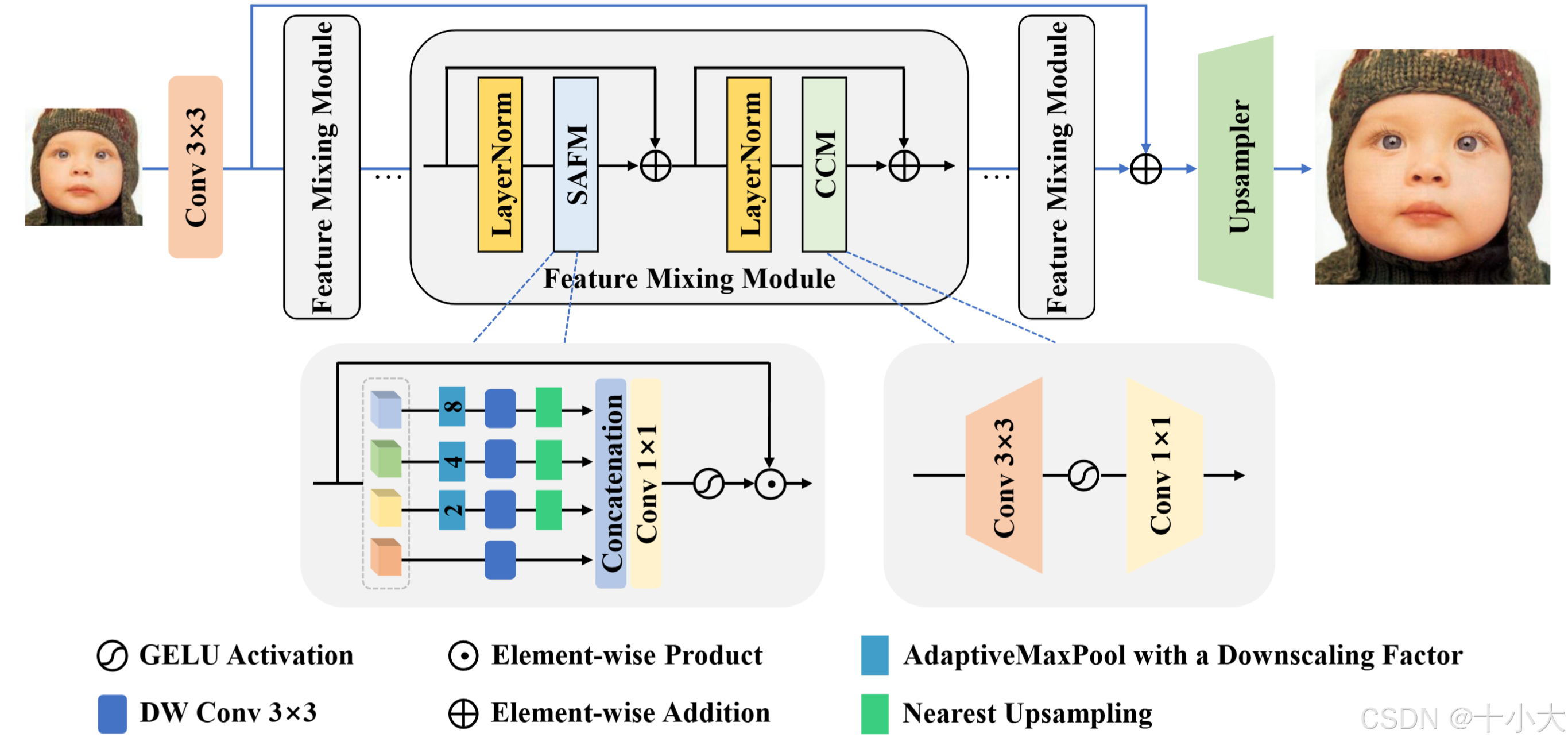
第12名mmSR:SAFMN改进2
Title: Efficient Feature Aggregation Network for Image Super-Resolution
FAnet主要改进:
- 基于SAFMN,将FMM重新参数化变为RFMM,将原始模块的卷积网络改为并行结构。
- SimpleSAFM中的下采样因子调整为16。
- 增加10,800个训练数据,使用Omni-SR等网络生成新的图像。
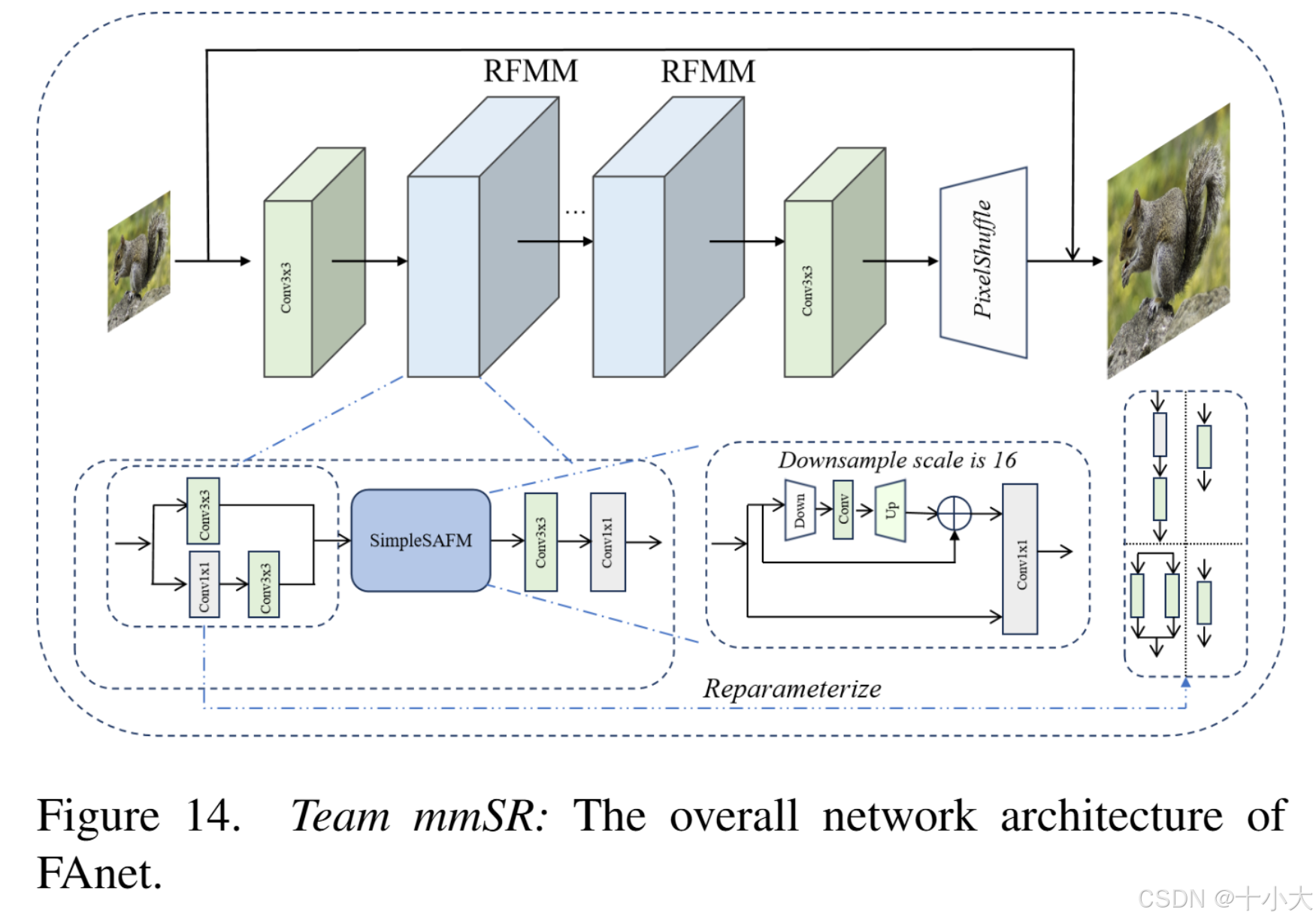
第13名ChanSR:高通滤波器助力捕获边缘细节
Title: EECNet: Edge Enhanced Convolutional Network for Efficient Super-Resolution
基于SRN(A single residual network with esa modules and distillation)
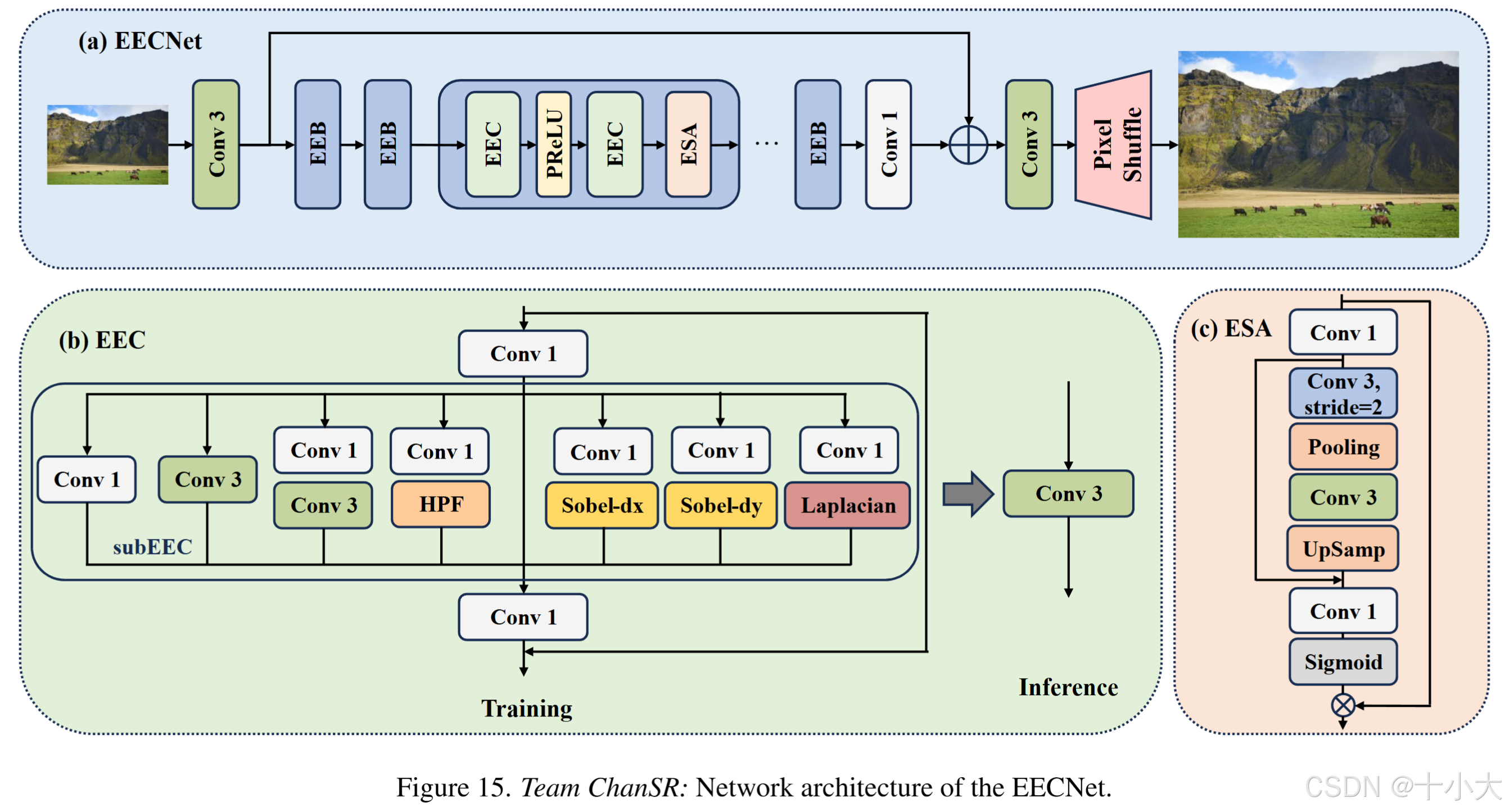
主要做法:
-
引入了一个预定义的高通滤波器 (HPF) :
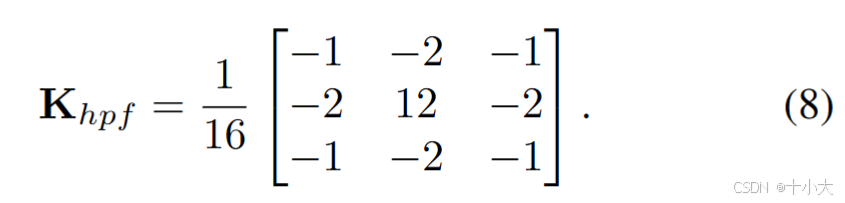
将HPF 集成到 EDBB, 提出 subEEC 模块,等效于 3×3 卷积。 -
将RRRB中的原始 3×3 卷积替换为 subEEC 以获得最终的 EEC 架构。
-
将第一个卷积层的偏差初始化为零,以补偿 subEEC 中的零填充操作。
-
与原始 ESA 相比,去除了 1×1 卷积层,在卷积组中仅使用单个 3×3 卷积。
PS:主干是SPN,HPF整合到EFDN的EDBB中作为subEEC ,subEEC 替代卷积 FMEN- s的RRRB的3×3Conv构成最终的 EEC。
第14名Pixel Alchemists:在线卷积重新参数化
Title: RCUNet
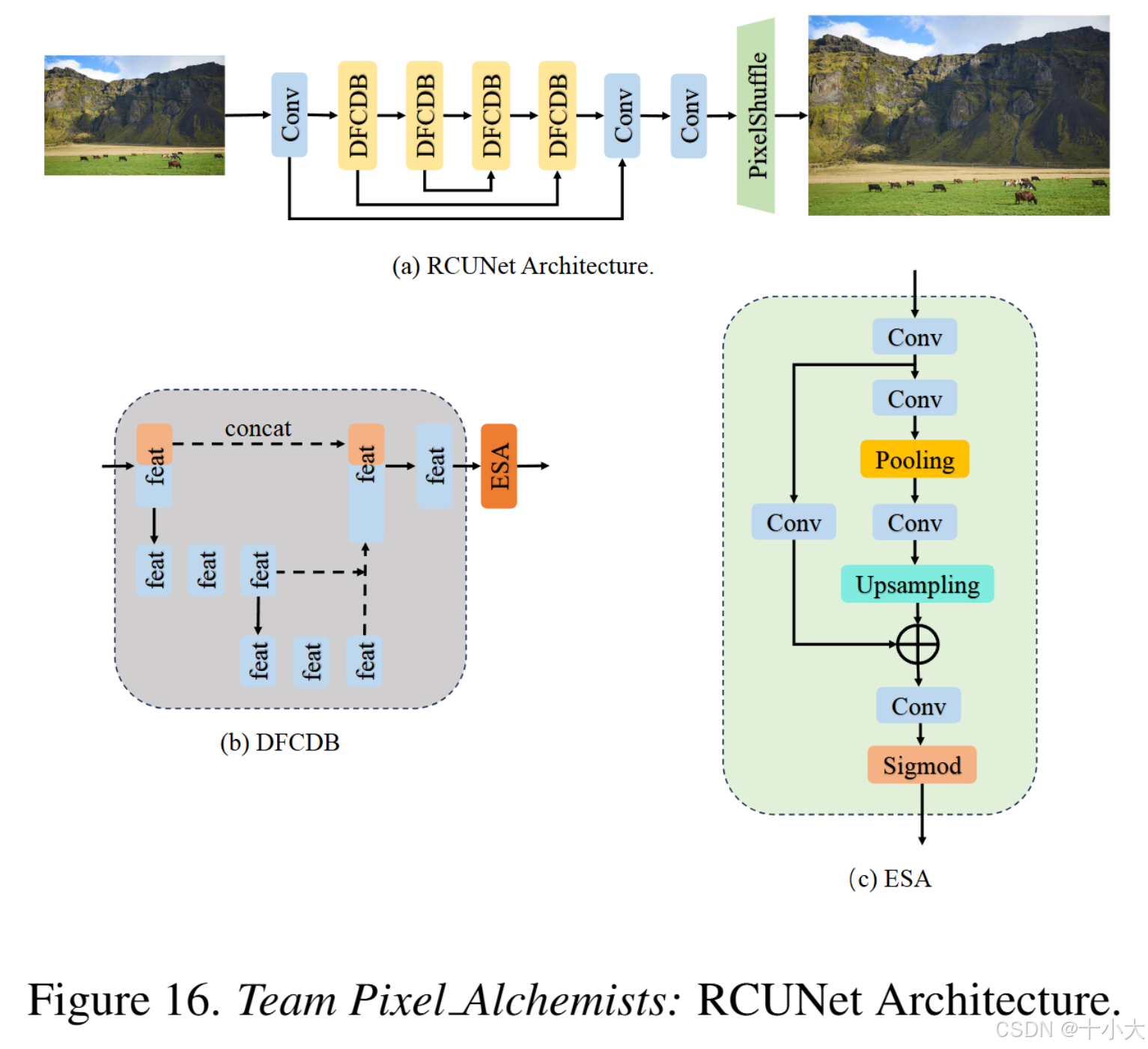
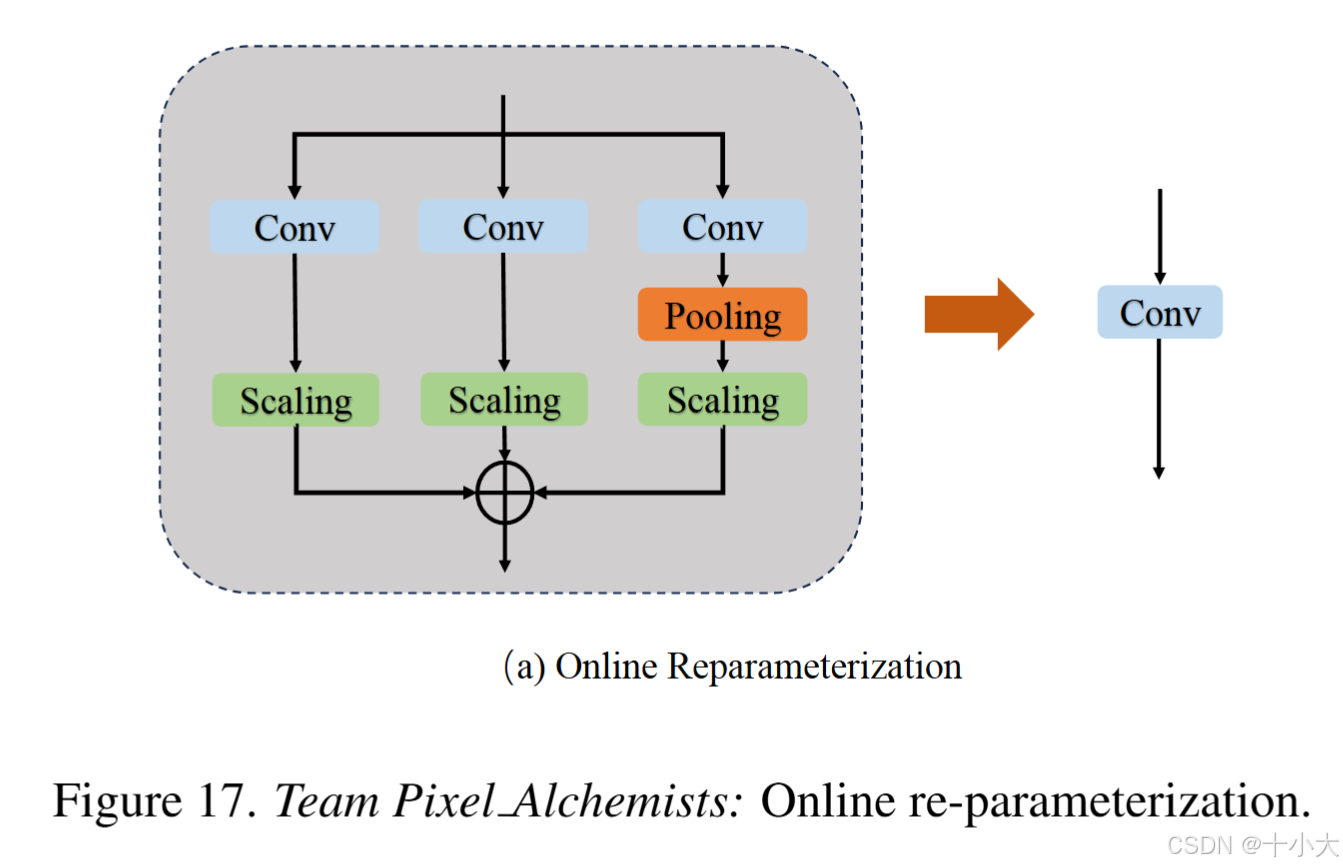
基于GhostSR: Learning Ghost Features for Efficient Image Super-Resolution。
主要做法:
- GhostSR通道分割:输入特征图沿每个块中的通道维度进行分割。然后,四个卷积层处理分割特征图之一以生成互补特征。输入特征和互补特征被连接起来,以避免输入信息的丢失,并由 conv-1 层蒸馏
- 在线卷积重新参数化:将复杂的模块转成单个卷积;
第16名LZ:卷积分解
Title: Tensor decompose efficient super-resolution network
基于ECBSR(Edgeoriented convolution block for real-time super resolution on mobile devices)
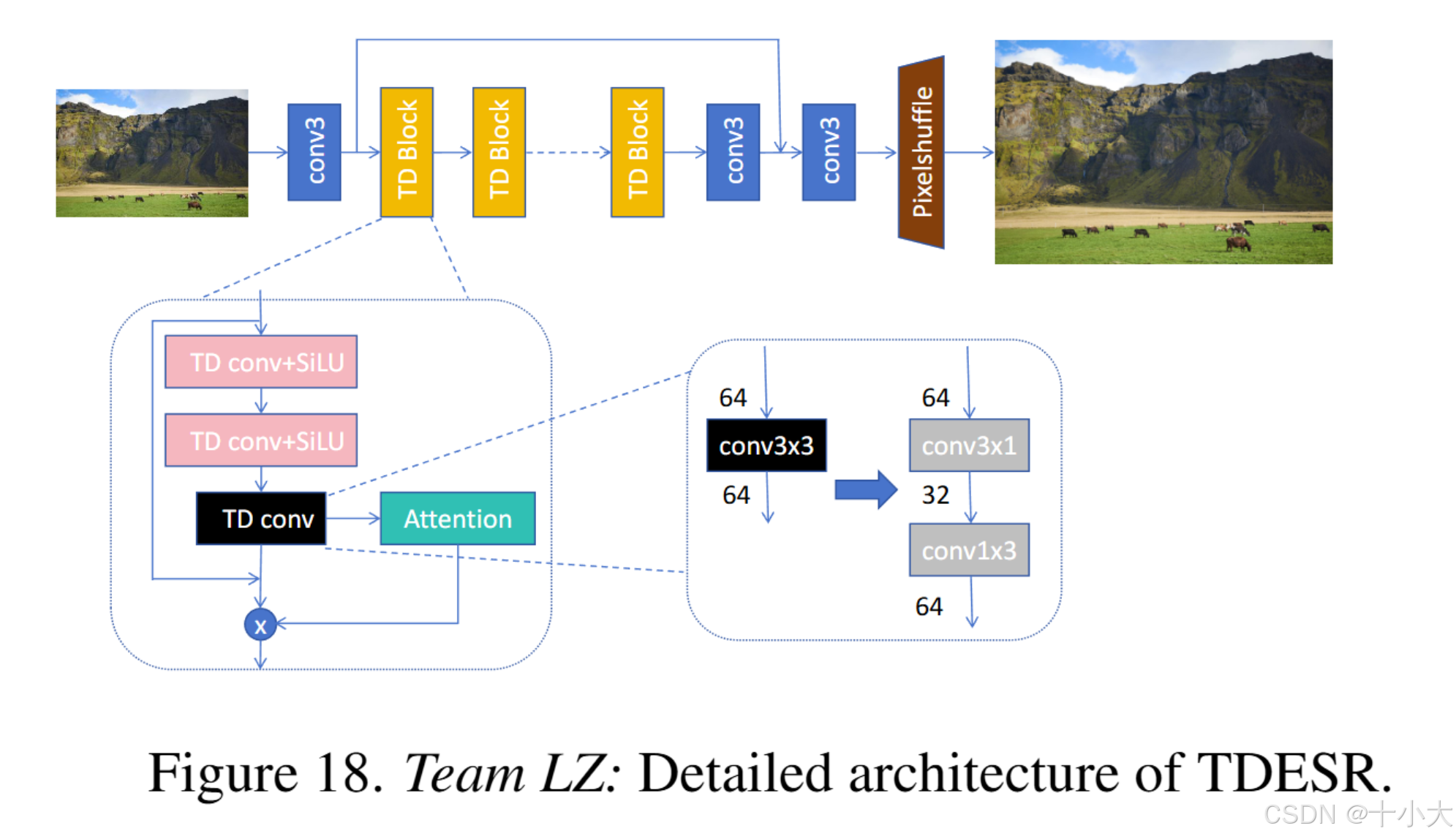
主要做法:
- 重新参数化;
- 卷积分解:3×3Conv分解成3×1Conv和1×3Conv;
架构:5个TD块,通道数64,分解后中间通道数为32,PixelShuffle 前通道数为48。
第17名Z6:SPAN+RFDN
Title: GLoReNet: Global and Local feature Refinement Network for Efficient Super-Resolution
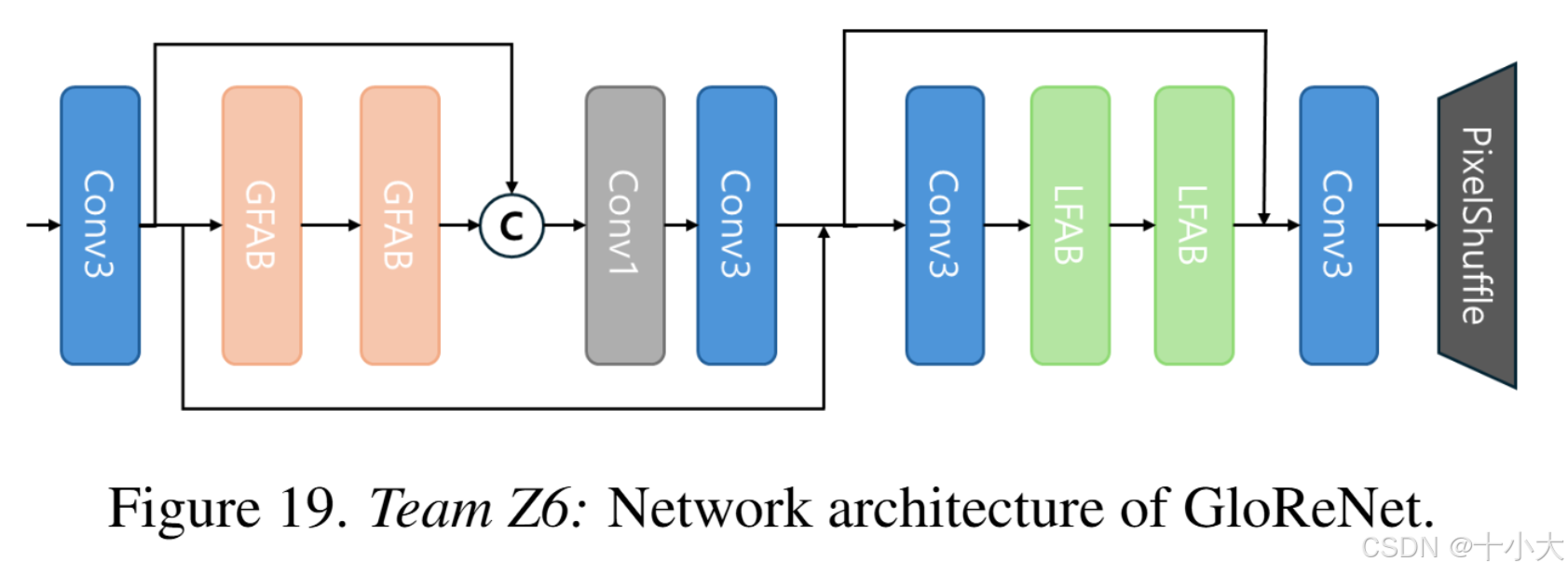
基于SPAN和RFDN,分别对应核心结构GFAB和LFAB。
第18名TACO SR:新卷积块TenInOneConv
Title: TenInOneSR
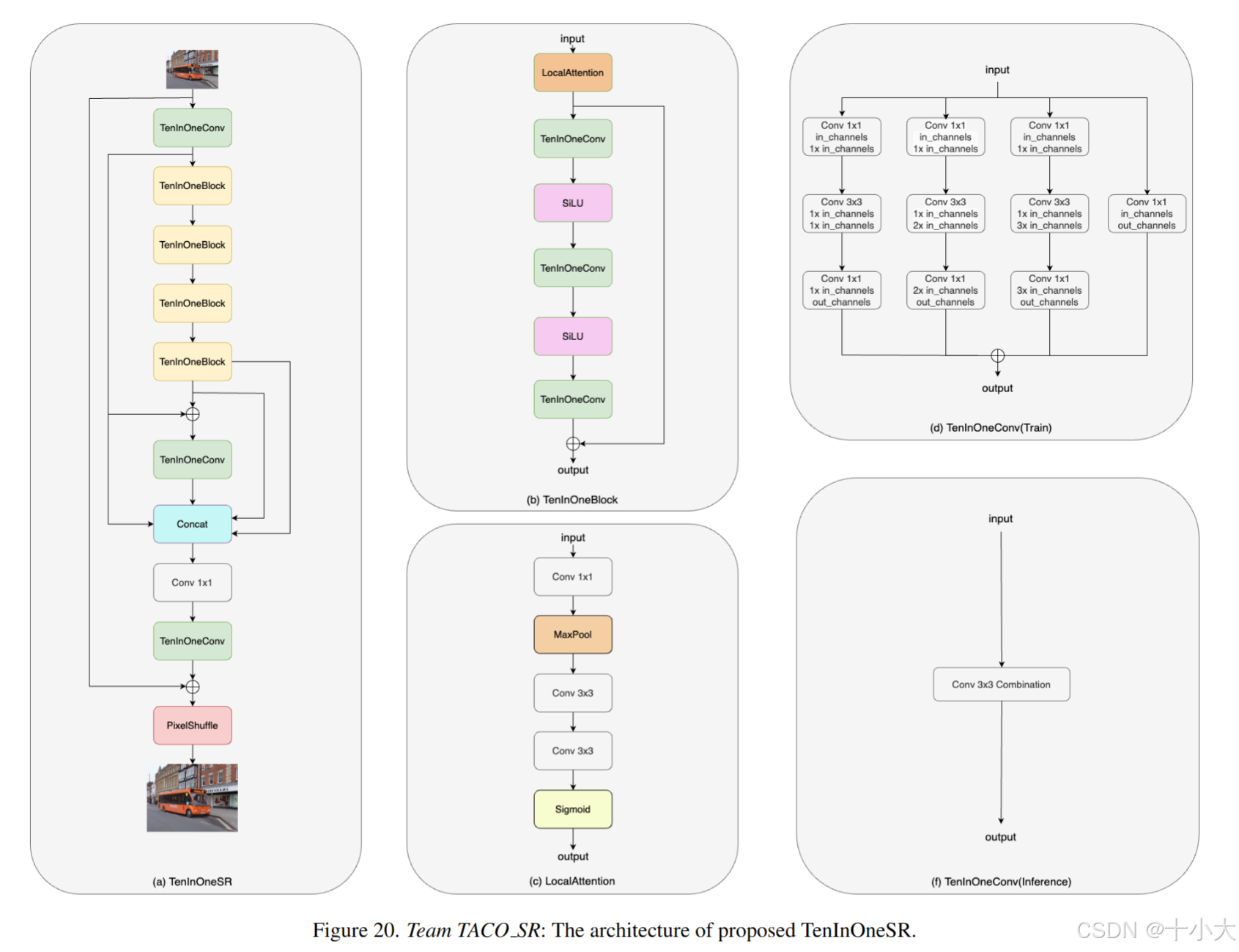
基于SPAN和PFDNLite。
主要做法:
- 新卷积块TenInOneConv:SPAN中的3×C块中加入两个额外的不同通道的并行分支,将多个卷积核融合到单个等效内核中以提高推理效率;
- LocalAttention:PFDNLite;
第19名AIOT AI:重新组合模块
Title: Efficient channel attention super-resolution network acting on space
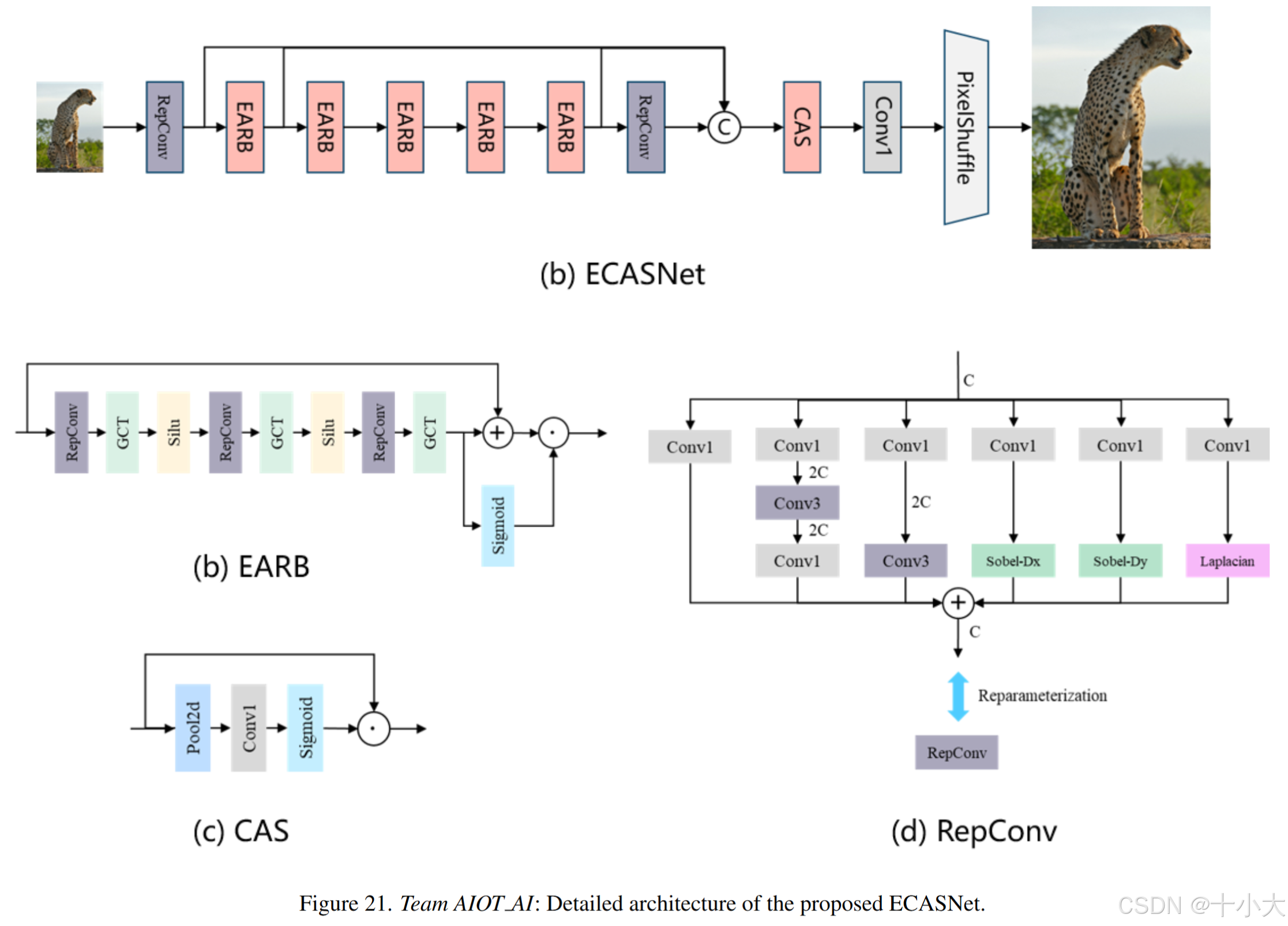
基于SPAN和ECBSR。
主要做法:在 SPAN 的 SPAB 的基础上,他们将面向边缘的卷积块 (ECB) 和正则化模块 (GCT) 结合起来,形成一个新的重新参数化特征提取模块,称为增强注意力和重新参数化块 (EARB),使用作用于空间的高效通道注意模块(CAS)。
第20名JNU620:RepRFN+RLFN
Title: Reparameterized Residual Local Feature Network for Efficient Image Super-Resolution
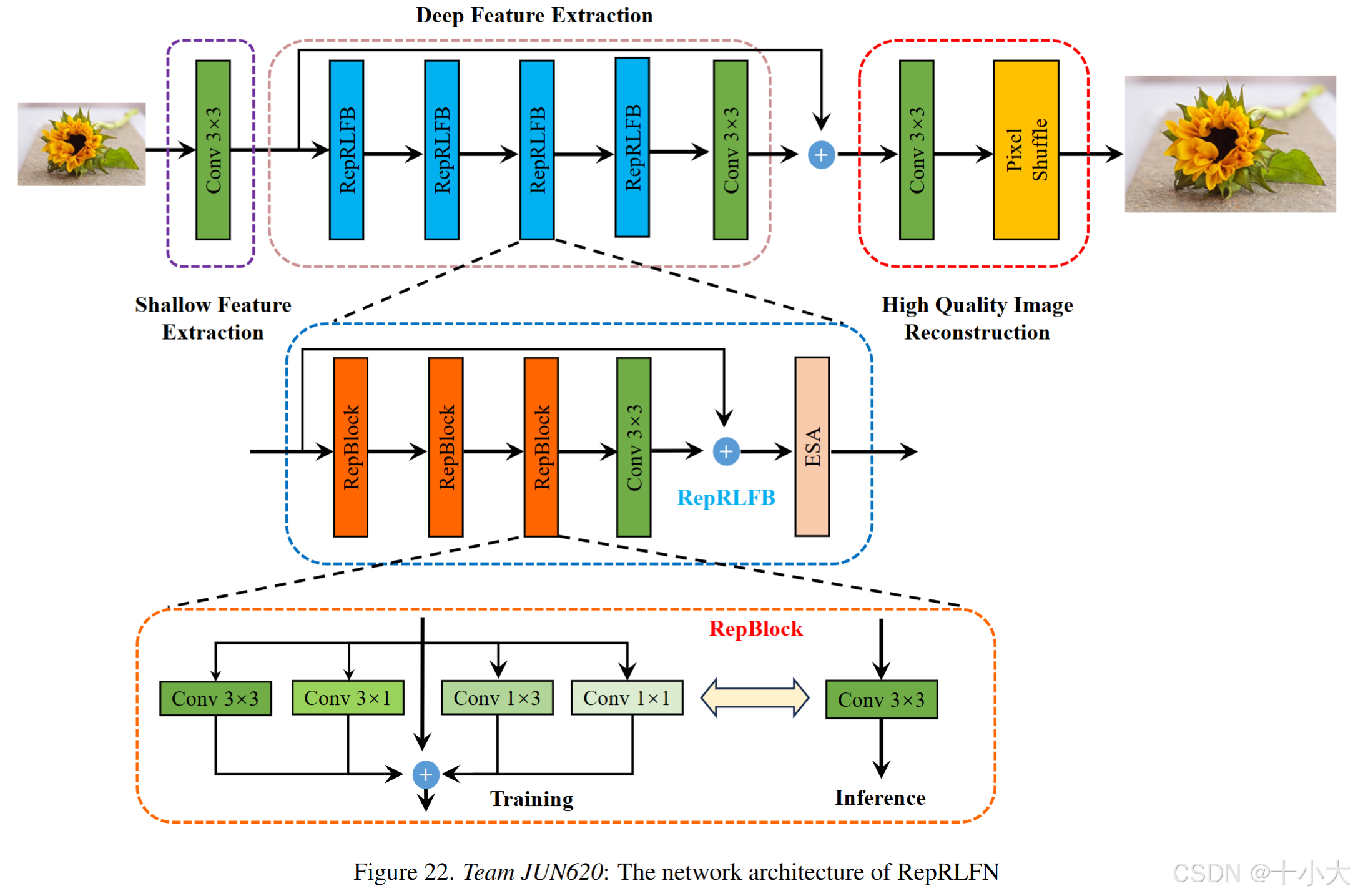
基于RepRFN和RLFN。
核心做法:将RLFN中的RLFB替换为重新参数化的剩余局部特征块(RepRLFB)。RepBlock 是 RepRLFB 的主要组成部分,它采用多个并行分支结构来提取不同感受野和模式的特征以提高性能。同时,利用结构重新参数化技术对训练和推理阶段进行解耦,避免了多分支引入导致计算复杂度增加的问题。
第21名LVGroup HFUT:SPAN卷积重新参数化
Title: Swift Parameter-free Attention Network for Efficient Image Super-Resolution
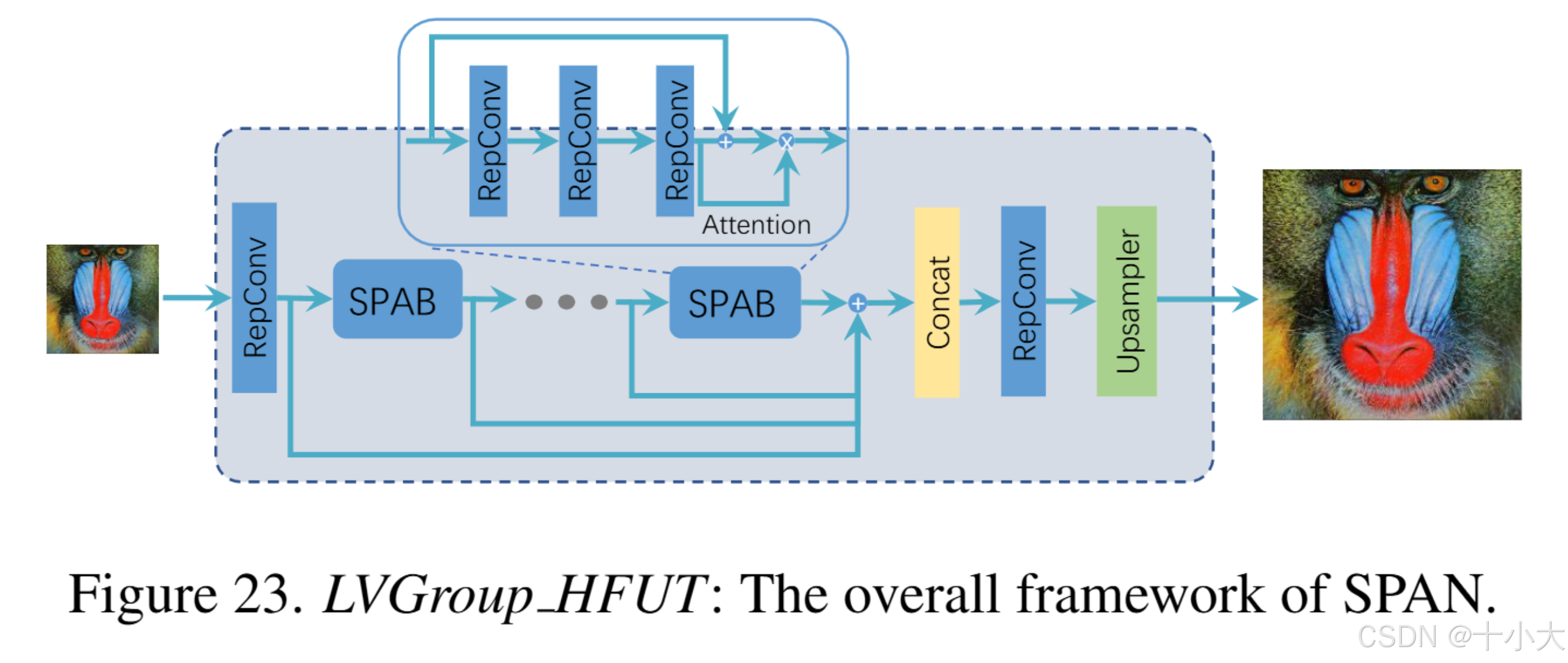
基于SPAN。
核心做法:将SPAN中的Conv重新参数化。
第23名YG:成熟的文章
Title: Spatial-Gate Self-Distillation Network for Efficient Image Super-Resolution
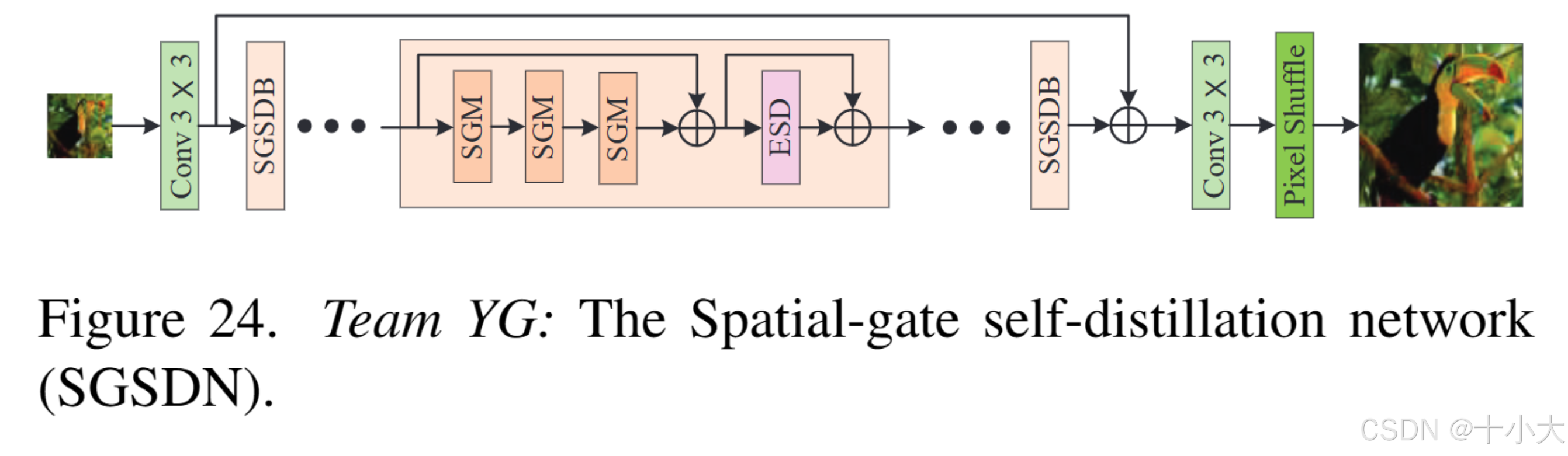
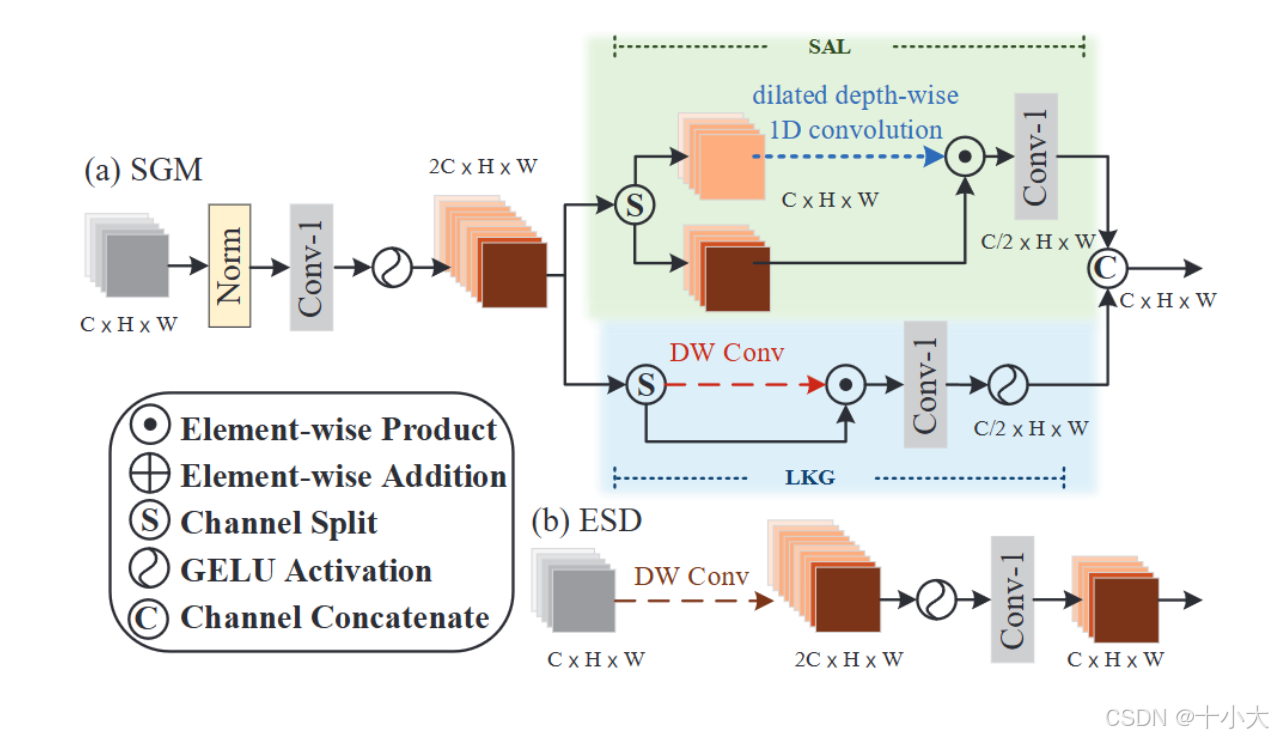
核心思想:以类似SA的方式探索非本地信息,同时对局部细节进行建模,以实现高效的图像超分辨率。
PS:理论描述在报告中非常清晰,非常值得学习,论文Method部分范例。
第24名NanoSR:我不配出现在参赛队伍里?
Title: 没有队伍信息。
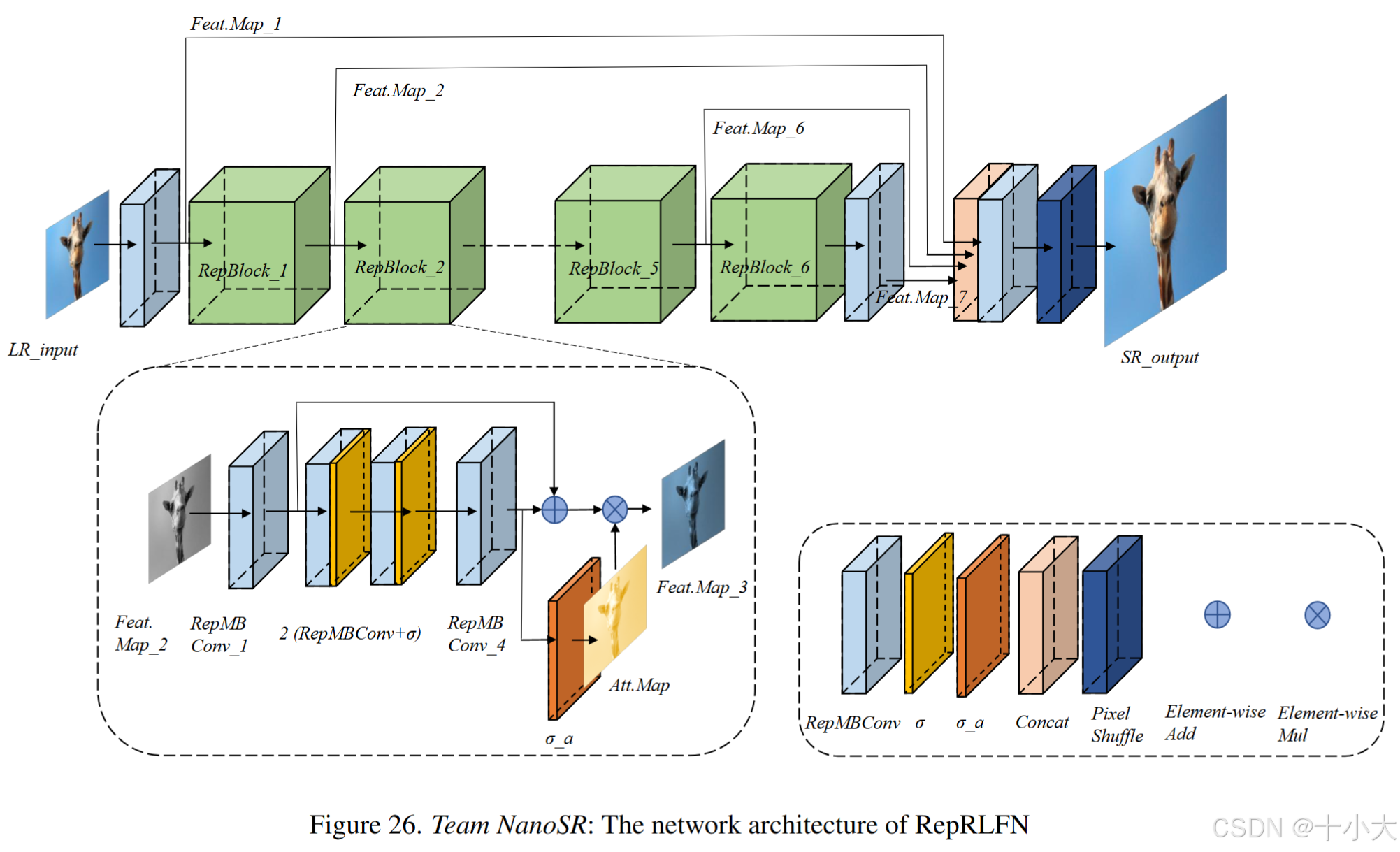
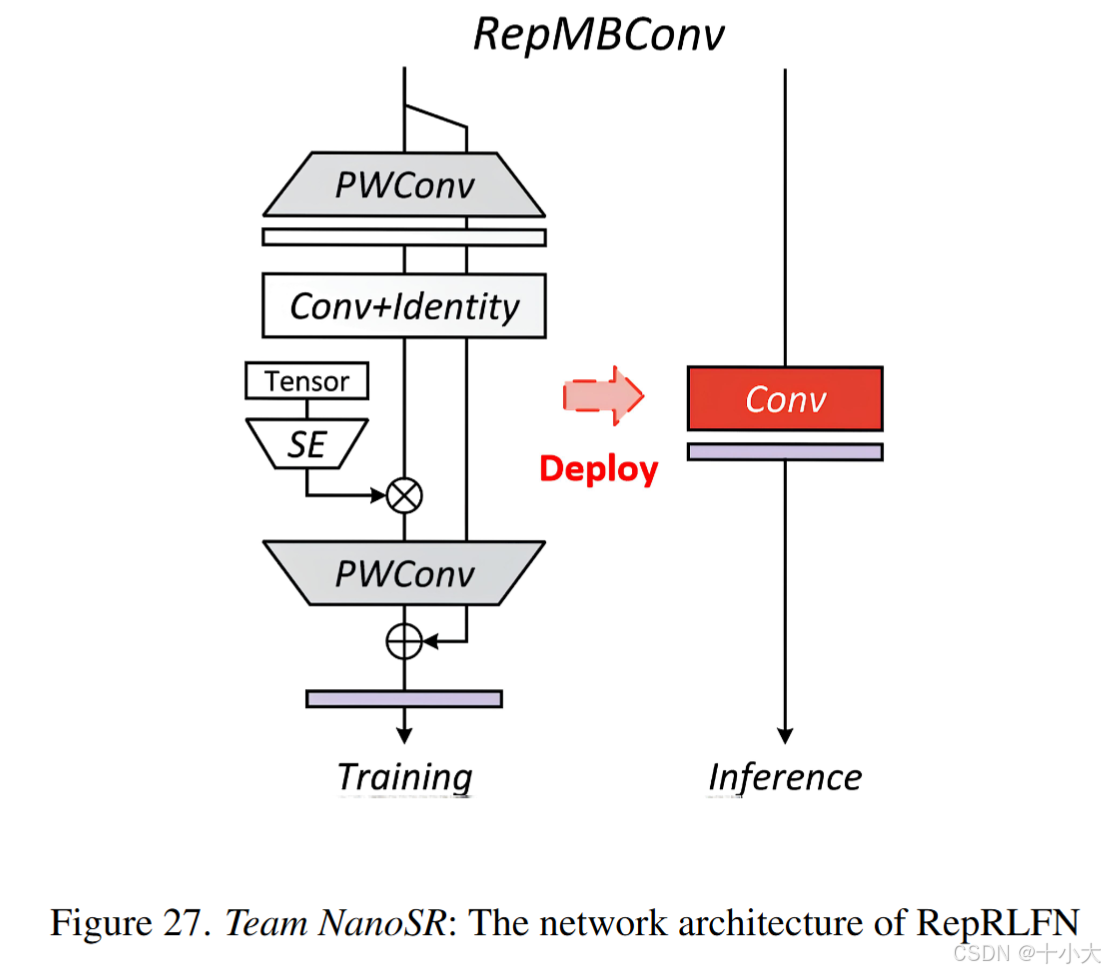
基于SPAN、PAN、PlainUSR。
主要做法:SPAN中的SPAB块替换为RepBlock,使用PlainUSR中的RepMBConv,RepMBConv形成了RepBlock中的所有卷积。RepMBConv 源自 MobileNetV3 Block (MBConv)。
第25名MegastudyEdu Vision AI:大核卷积
Title: Multi-scale Aggrgation Attention Network for Efficient Image Super-resolution
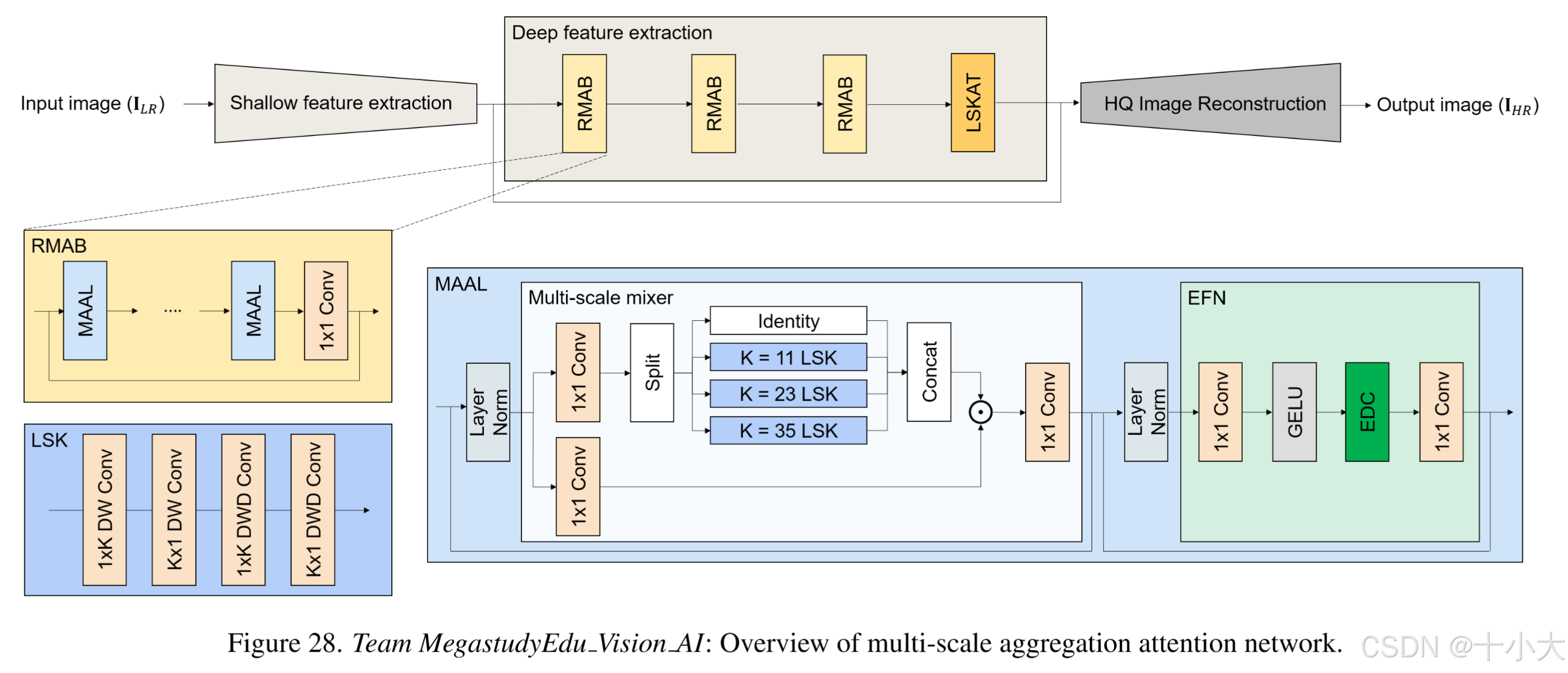
基于CFSR。
MAAN架构:MAAN通过浅层特征提取器重构高质量图像,由多尺度聚合注意层(MAAL)、大可分离核注意尾(LSKAT)和图像重建模块组成的三个残差多尺度聚合块(RMAB)堆栈。LKAT克服CFSR的3×3Conv尾限制重建特征表达的能力。
第26名XUPTBoys:在轻量化赛道是不是有点复杂了
Title: Frequency-Guided Multi-level Dispersion Network for Efficient Image Super-Resolution
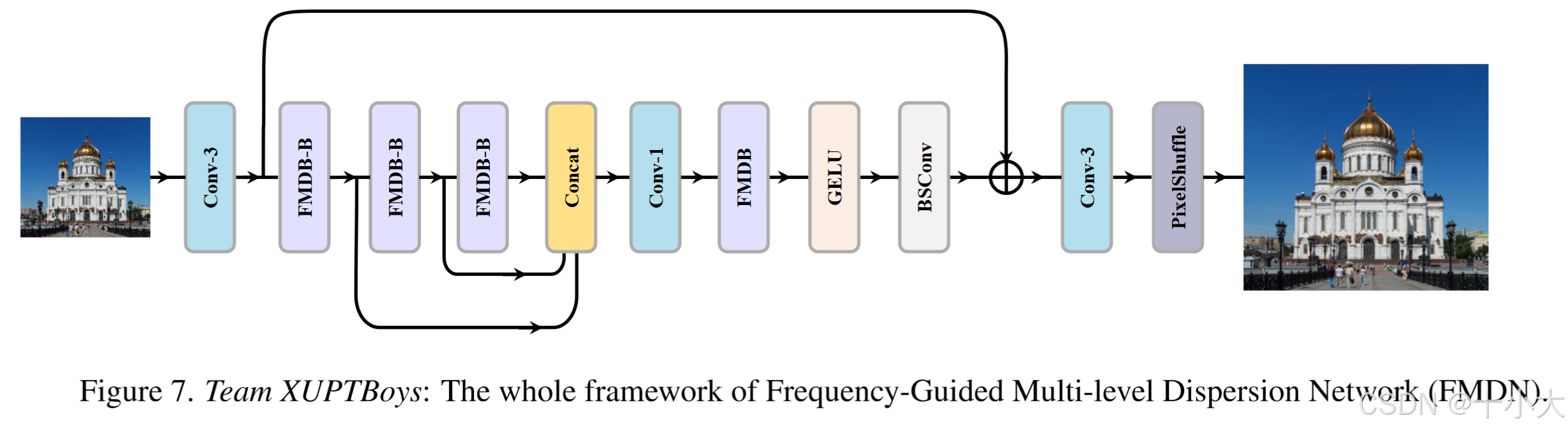
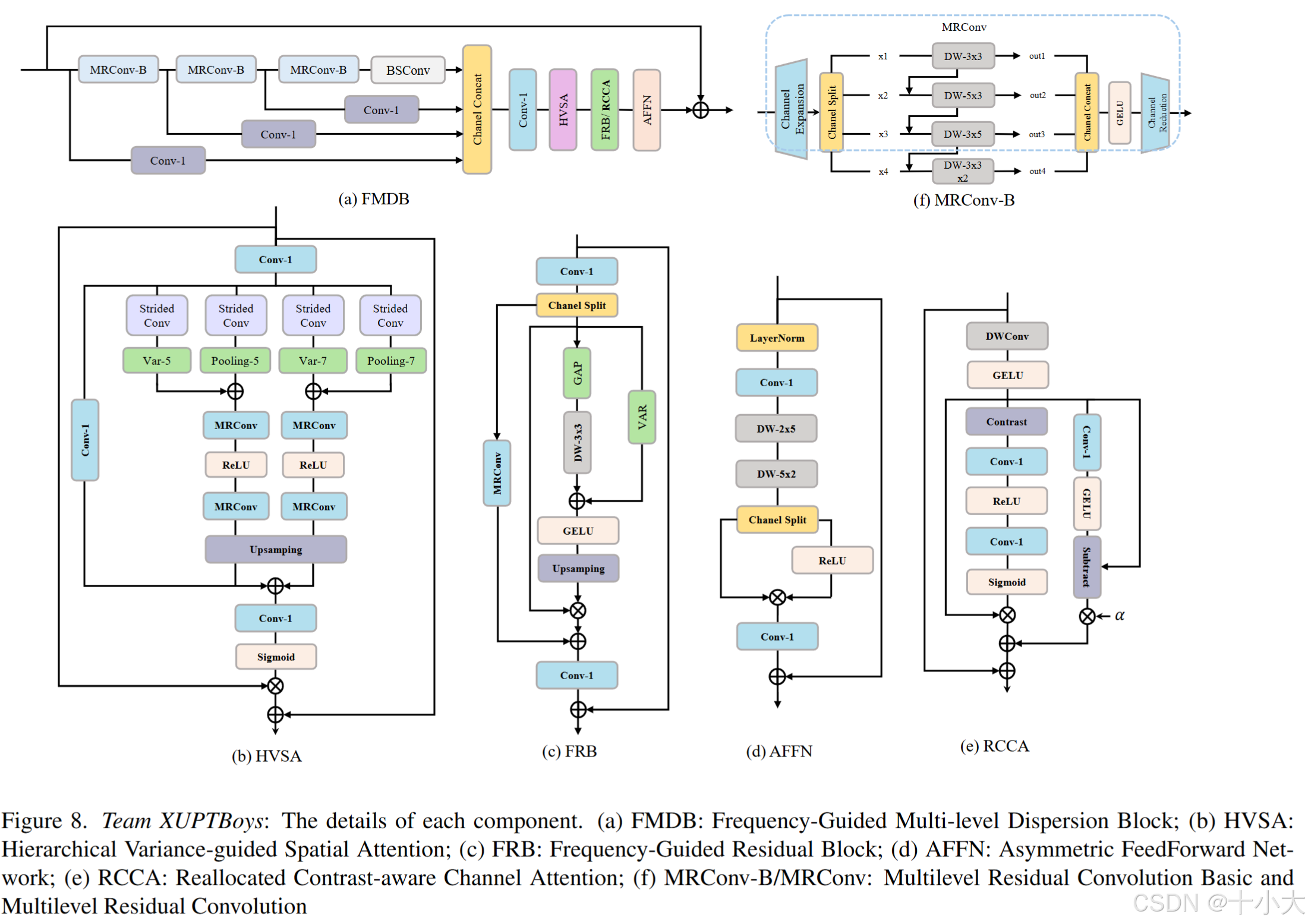
- FMDN:频率引导的多级色散块(FMDB)和新的频率引导的多级色散块FMDB-B,分层方差引导的空间注意(HVSA)、重新分配对比感知通道注意(RCCA)作为增强空间注意(ESA)[73]和对比感知通道注意(CCA)、频率引导剩余块(FRB)、非对称前馈网络(AFFN)、多级残差卷积(MRConv)和多级残差卷积Basic(MRConv-B)的替代方案。FMDB 和 FMDB-B 的区别在于前者使用 MRConv,而后者使用 MRConv-B。
第27名MILA:应该是一篇不错的文章
Title: Multi-Level Variance Feature Modulation Network for Lightweight Image Super-Resolution

SMFANet中的EASA+MDRN+AGDN。
第28名AiMF SR:
Title: Mixture of Efficient Attention for Efficient Image Super-Resolution
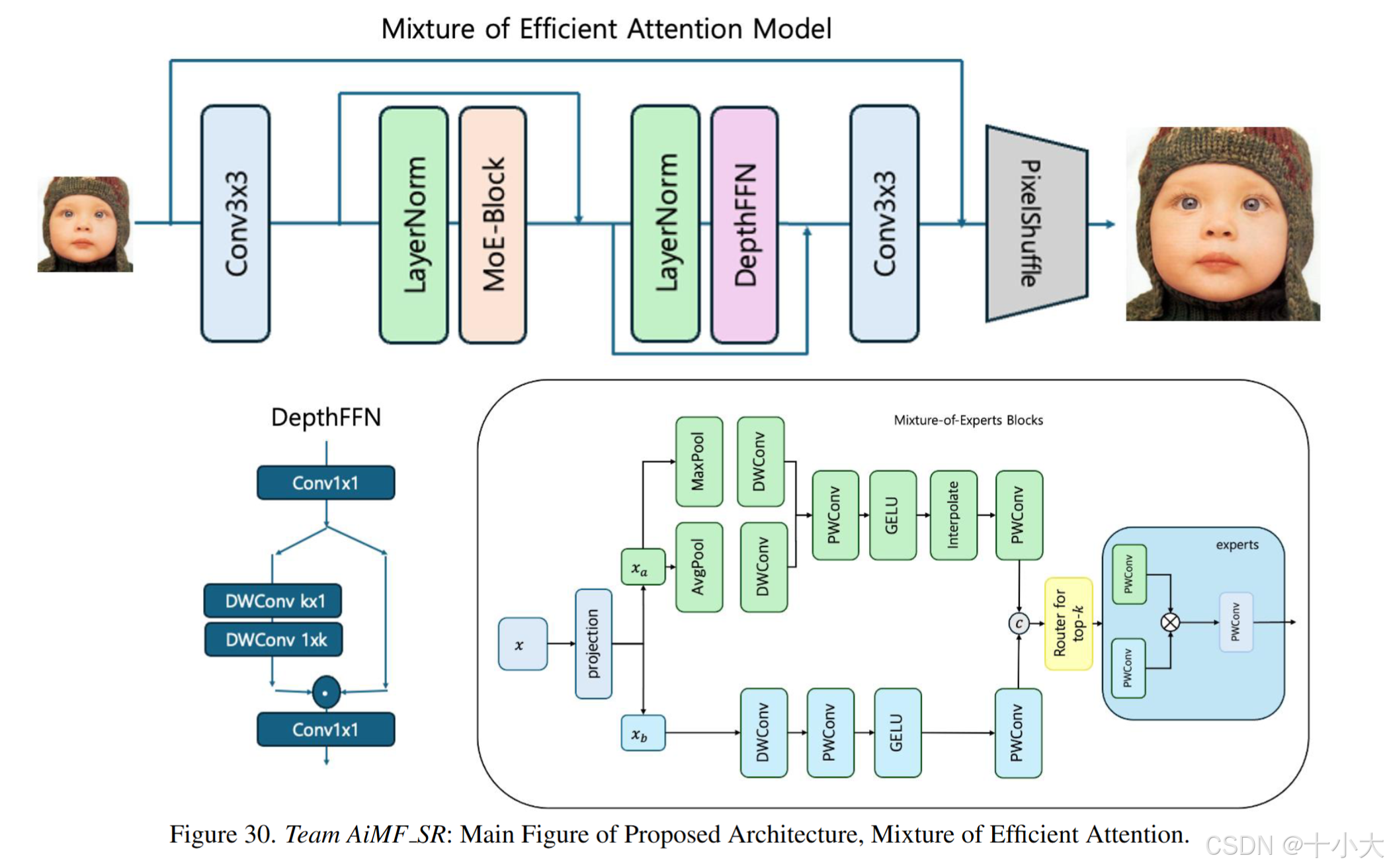
- 新的高效注意混合(MoEA)架构,包括一个浅层特征提取器、多个特征表示模块(FRMs)和一个高效的重构和上采样模块。
第29名EagleSR:丢了
第30名BVIVSR:带着论文来参赛
Title: NTIRE 2025 Efficient SR Challenge Factsheet
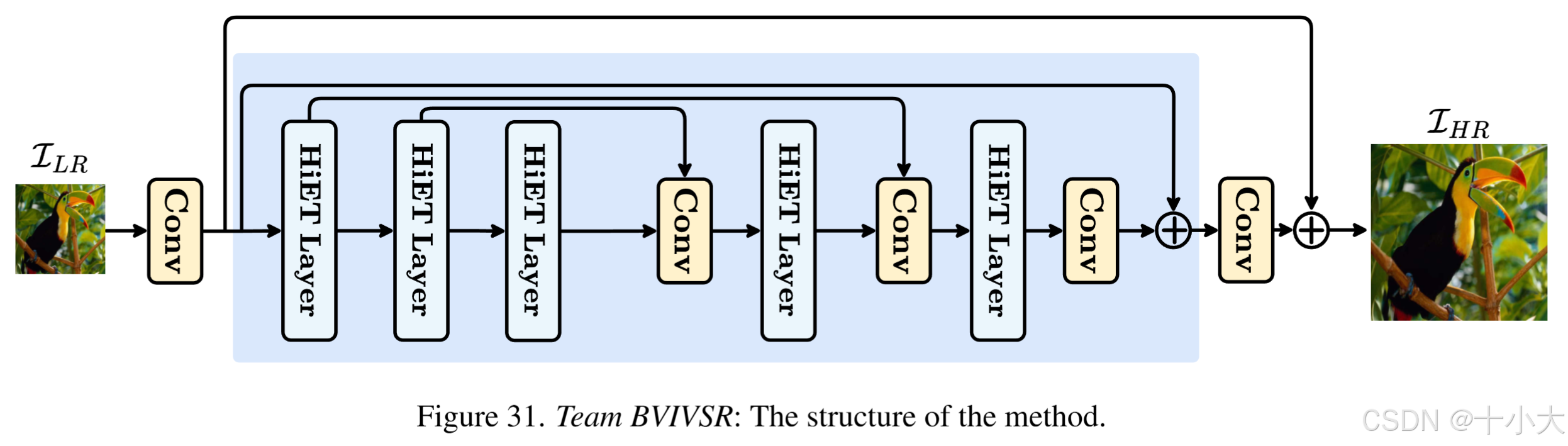
高效的基于 Transformer 的网络架构,核心组件是分层编码 Transformer (HiET) 层,整体架构结合了修改后的 U-Net 结构,其中跳跃连接是在不同深度的对称 HiET 层之间引入的。
多教师知识蒸馏策略来提高轻量级C2D-ISR模型的性能,其中SRFormer、MambaIR和EDSR被用作教师网络。
文章C2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales团队,文章链接https://arxiv.org/html/2503.13740v1。
第31名HannahSR:改进SPAN中原点对称激活函数存在的问题
Title: Frequency-Guided Multi-level Dispersion Network for Efficient Image Super-Resolution
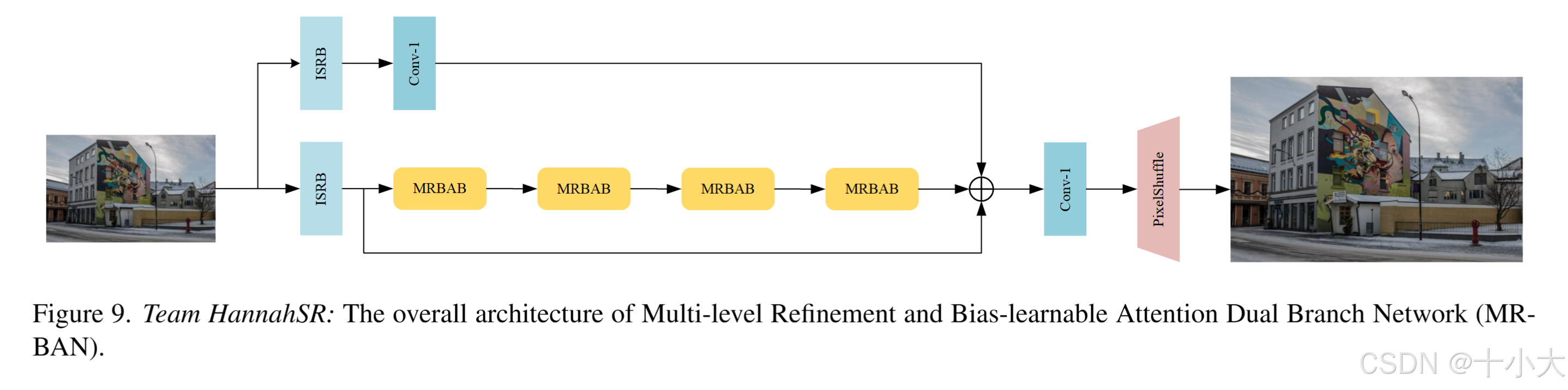
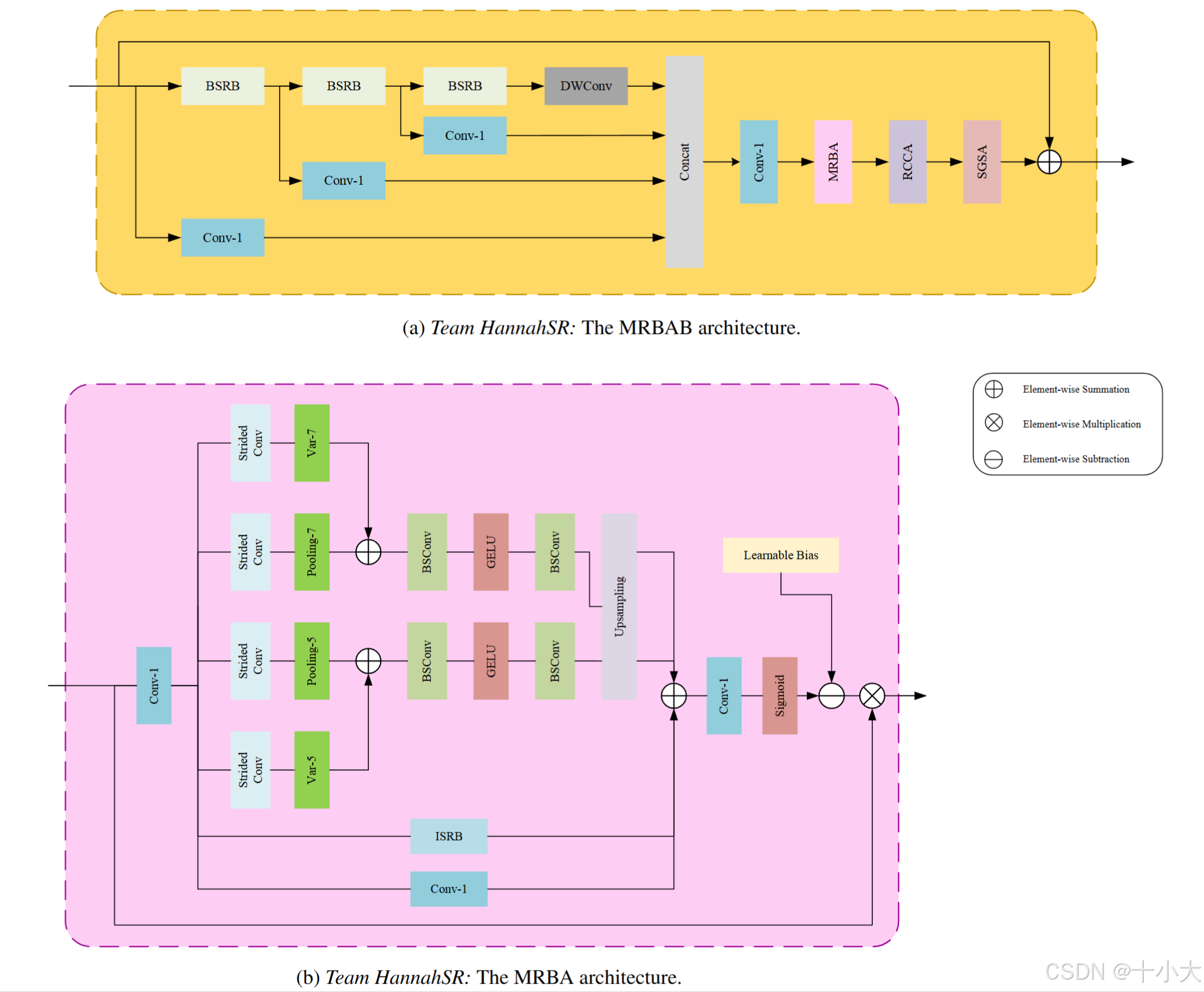
受到AGDN、MDRN和SPAN等先前研究的启发。提出了一种多级细化和偏置可学习注意双分支网络(MRBAN)。更具体地说,通过构建另一个由 3 × 3 卷积层 (ISRB) 和一个 1×1 卷积层组成的分支来构建 AGDN 框架,以可学习的方式提高整体性能。同时,将 AGDN 中的 concat 模块替换为直接逐元素求和,以便显着节省参数。此外,提出了多级细化和偏置可学习注意块(MRBAB)作为网络的基本块。试图最小化 Sigmoid 模块引起的信息丢失。
解决SPAN中原点对称激活函数的问题:处理较大的正输入时,输出近似为0.5,与1.0相比丢失了信息。于是,设置负偏置作为可学习参数动态更新。
将第一个3 × 3卷积层替换为相同的尺度重参数化块。
第32名VPEG_C:在这也能看见Restormer
Title: DAN: Dual Attention Network for lightweight Image Super-Resolution
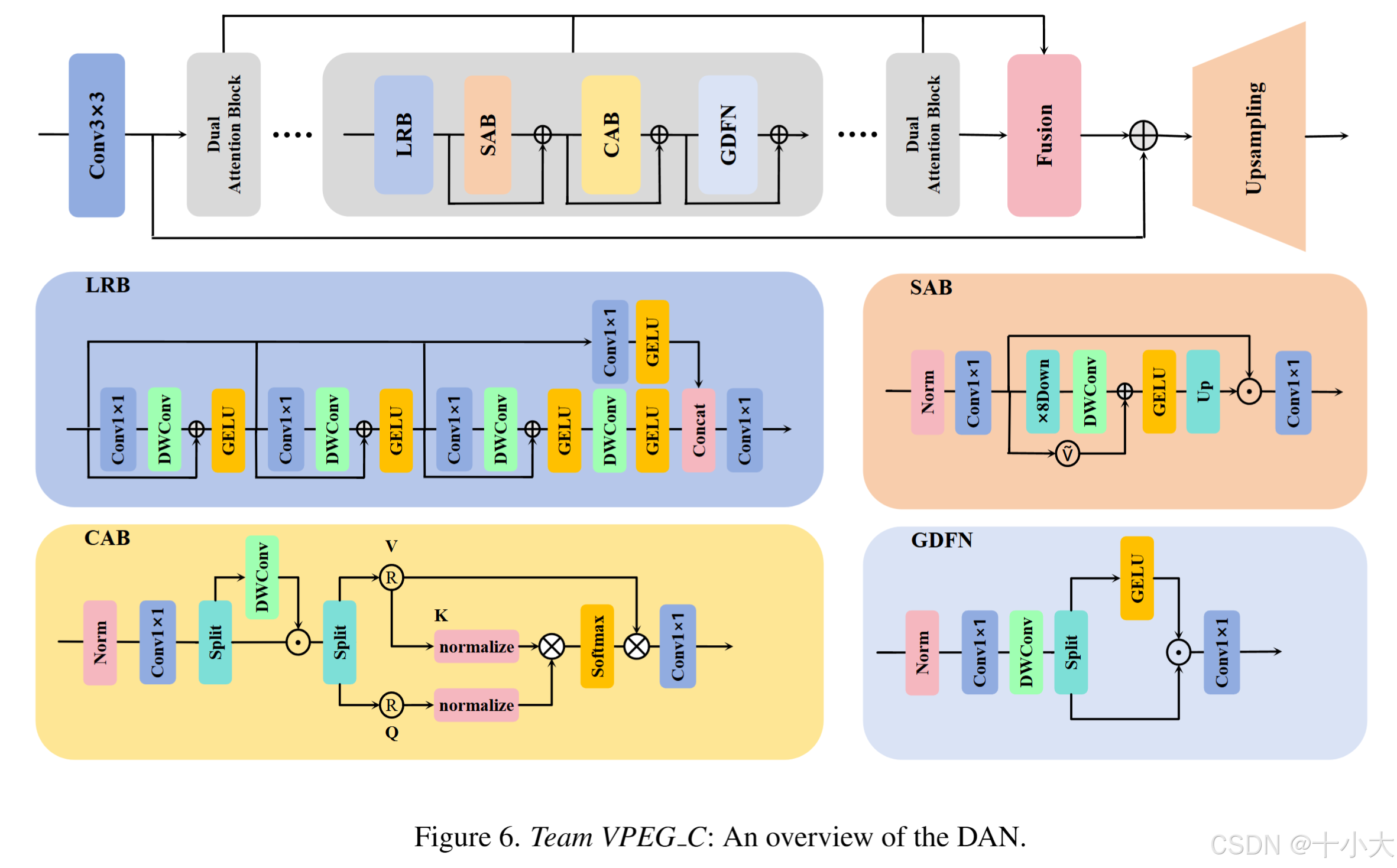
双注意力网络,由局部残差块 (LRB)、空间注意块 (SAB) 和通道注意块 (CAB)构成。
局部残差块 (LRB)。利用 1×1 的卷积层,然后是 3×3 深度卷积作为基本单元,重复 3 次。特别是,GELU 激活应用于每一层,特征以密集连接的方式传递。在块的末尾,使用通道连接聚合不同层次的特征图,有效地捕获局部图像细节。
空间注意块 (SAB)。采用SMFANet的空间注意设计,采用方差约束的特征调制机制来聚合空间特征。这允许以最小的计算成本进行有效的空间交互。
通道注意块(CAB)。全局通道信息通过自门控机制建模,该机制增强局部表示并增加模型非线性。接下来是一个键值共享MDTA,用于全局交互,GDFN用于特征细化。(Restormer)
第33名CUIT HTT:引入频域操作
Title: Frequency-Segmented Attention Network for Lightweight Image Super
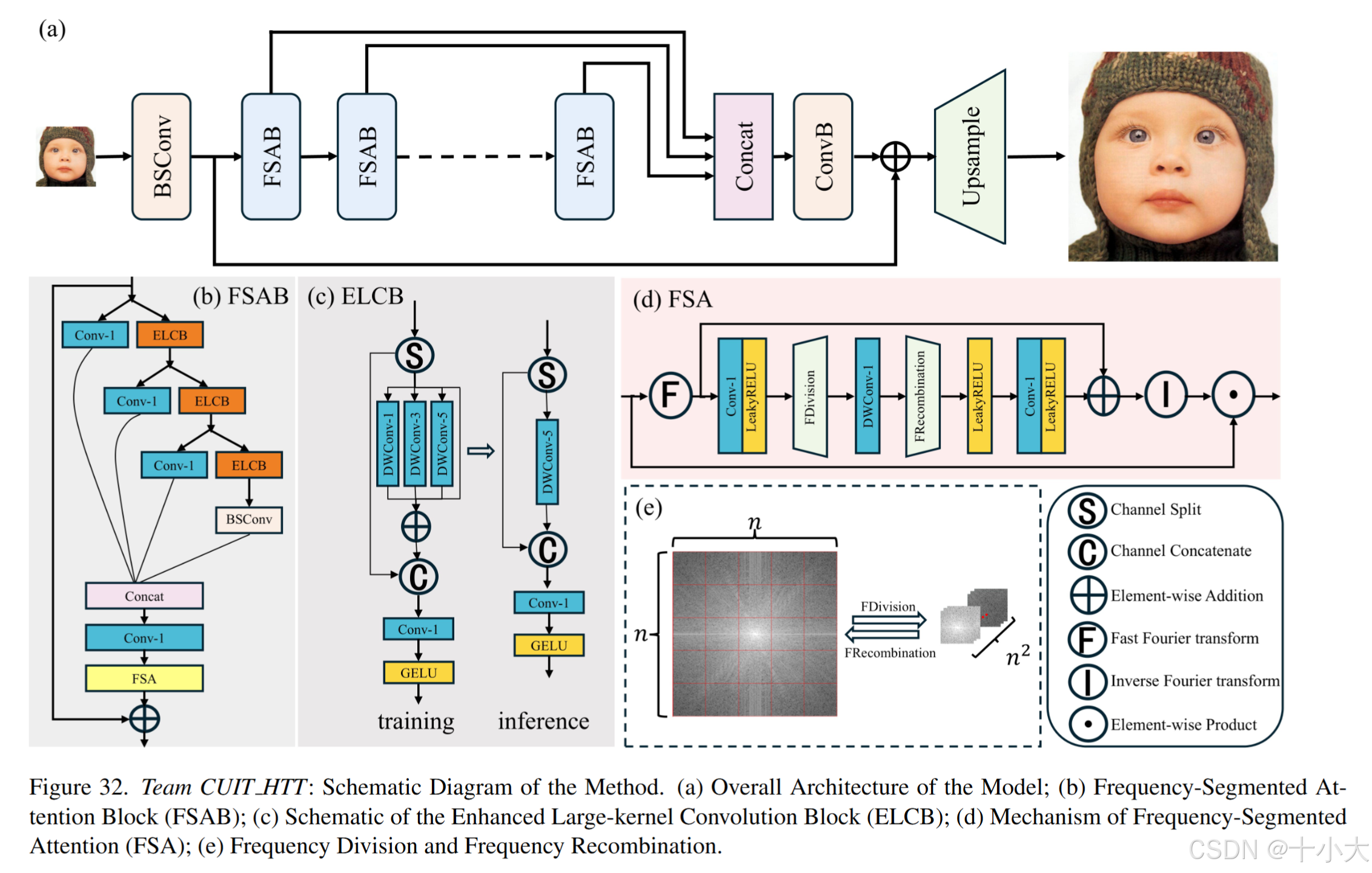
- 架构:浅层特征提取模块、深层特征提取模块和重构和上采样模块。
- 浅层特征提取:BSConv
- 深层特征提取:多个频率分割注意块 (FSAB) ,由用于局部特征处理的信息提取架构和用于全局特征处理的所提出的频率分段注意 (FSA) 机制组成,输入特征映射首先通过快速傅里叶变换(FFT)转换为频域,通过频域操作实现空间域的全局处理。
第34名GXZY AI:DVMSR中的RSSB替换为MambaIR中的RSSB
Title: Parameter Free Vision Mamba For Lightweight Image Super-Resolution
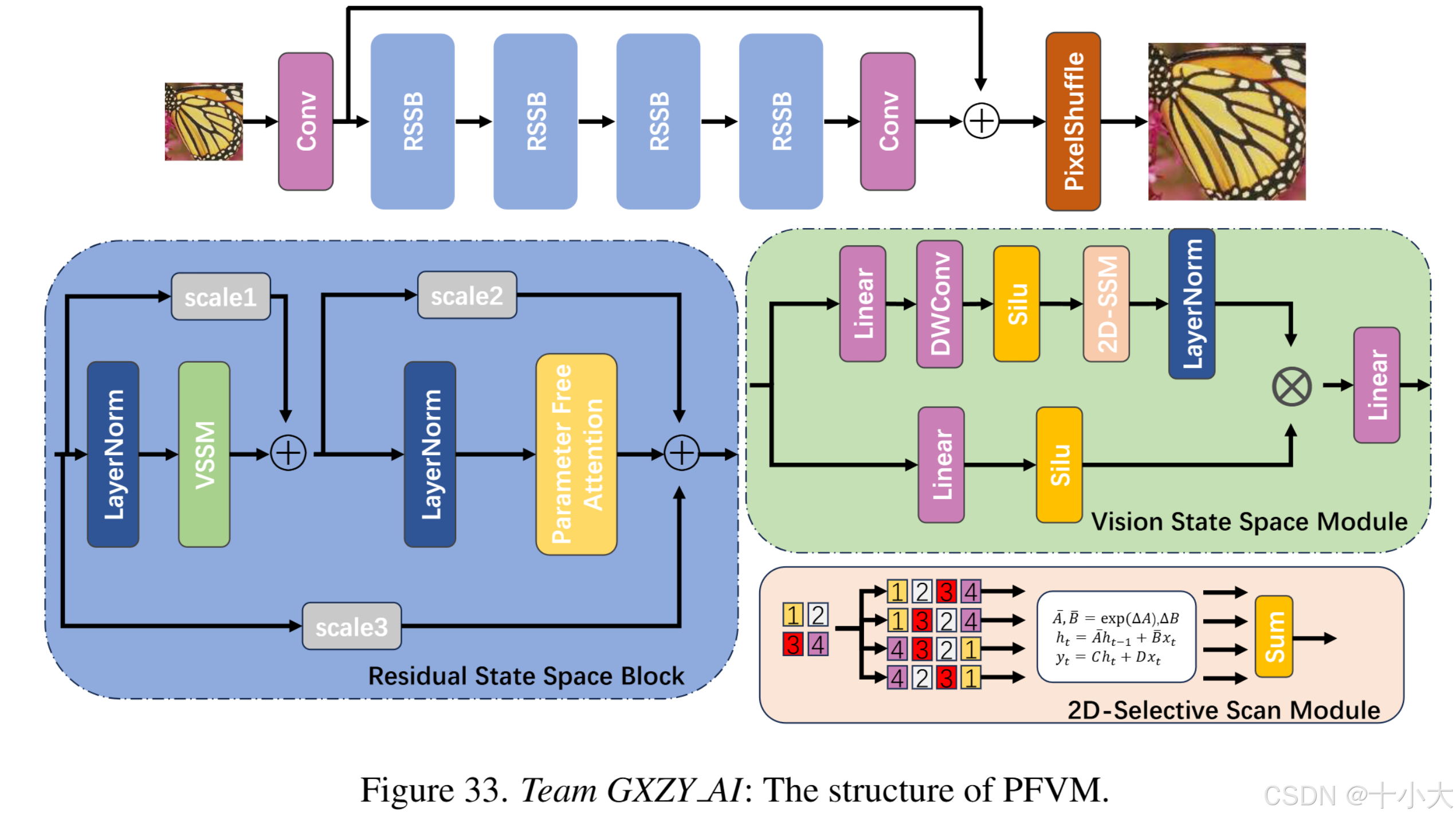
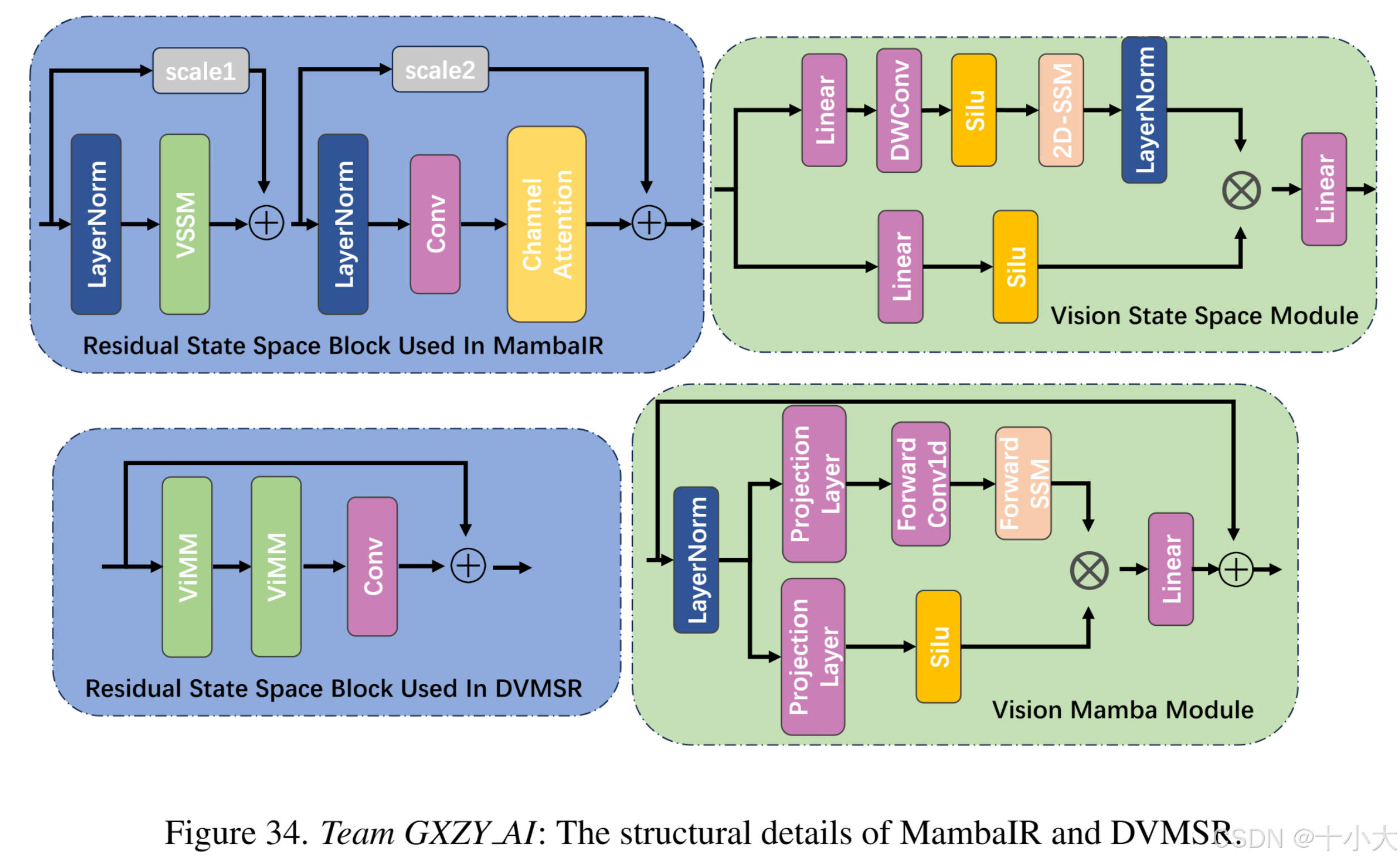
与DVMSR中使用的RSSB不同,PFVM不使用堆叠的ViMM模块,而是遵循MambaIR中RSSB的设计范式,这与MambaIR的不同之处在于使用3个残基分支来最大化残差学习的能力。为了通过近似推理时间获得更好的PSNR,卷积层采用瓶颈结构,将MambaIR中使用的通道注意替换为无参数注意。
第36名IPCV:HiT-SR实战
Title: Efficient HiTSR
使用HiT-SR,文章为:HiT-SR: Hierarchical Transformer for Efficient Image Super-Resolution。
第37名X-L:PartialConv+通道分割
Title: Partial Permuted Self-Attention for Lightweight Super-Resolution
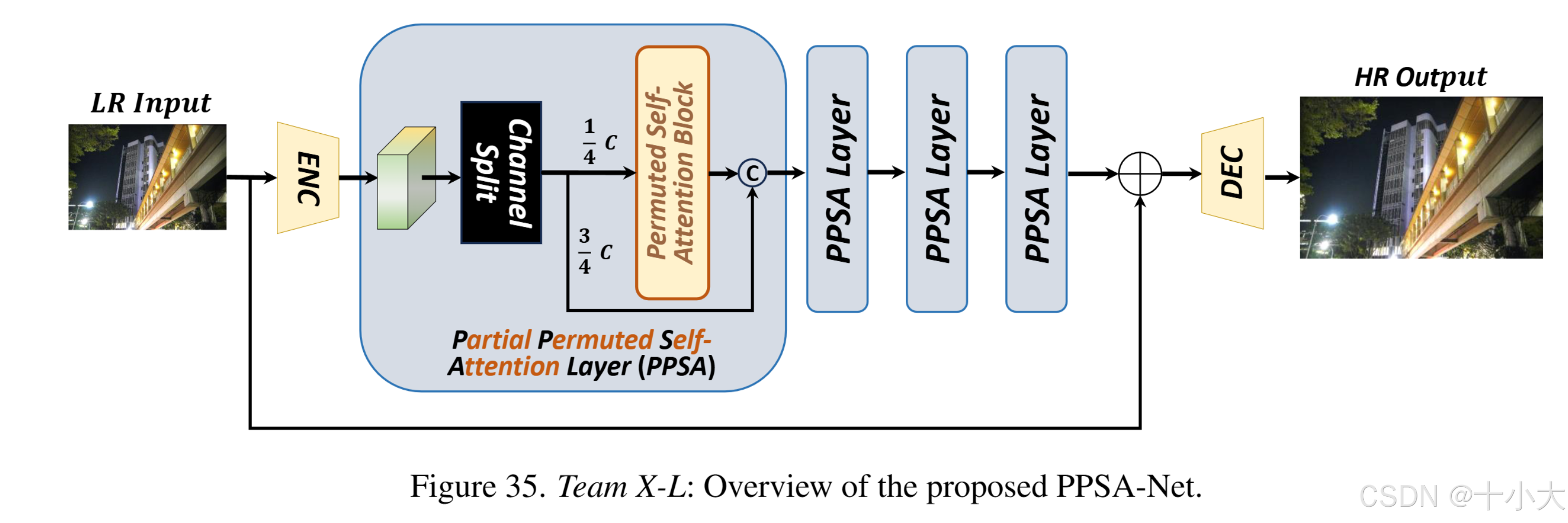
灵感来源:SRFormer+PartialConv,SRFormer存在卷积冗余,于是和PartialConv结合。
核心思路:在每个PPSA层中,他们使用通道分割将原始特征分为两个子特征:一个包含1/4个通道,另一个包含3/4个通道。1/4 子特征由置换自注意力块 处理,而 3/4 子特征保持不变。处理后,两个子特征连接在一起。
第38名Quantum Res:轻量化MambaIRv2蒸馏网络
Title: Efficient Mamba-Based Image Super-Resolution via Knowledge Distillation
学生教师框架,使用 MambaIRv2-Light作为学生模型,而 MambaIRv2-base 作为教师。
以下是无排名团队(PSNR没达标,但轻量化的思想非常值得学习)
SylabSR:完全放弃性能?
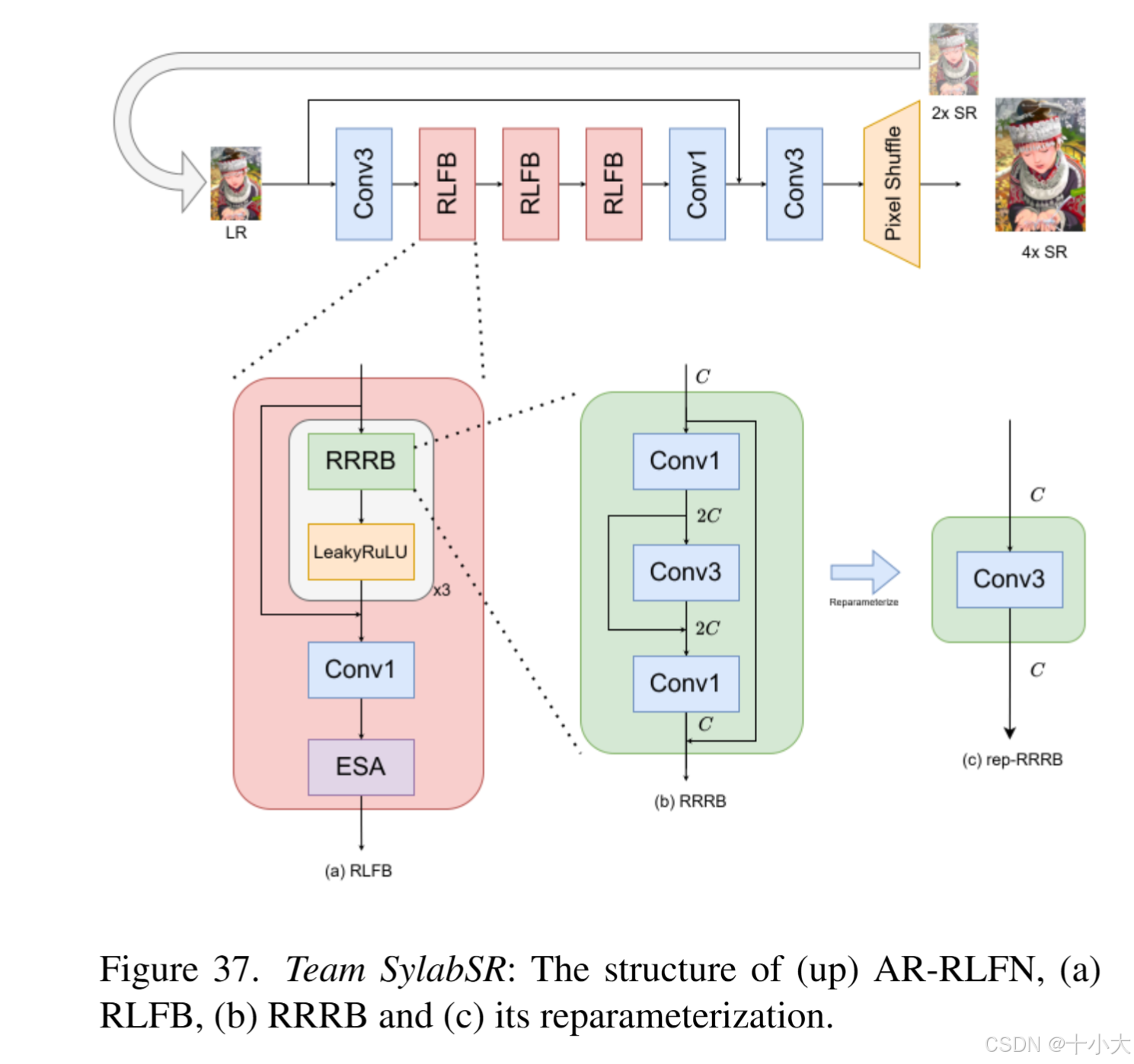
灵感来源:RLFN+VARSR
二阶段框架AutoRegressive Residual Local Feature Network (AR-RLFN):构建了一个针对2×超分辨率的RLFN的轻量级版本,这意味着最终的4× SR图像是由同一模型生成的中间2× SR图像生成的。虽然模型需要运行两次,但与原始模型相比,2× SR任务需要更少的参数和FLOPs,使得该方法总体上是有效的。RLFN的修改结构进一步受到R2Net的启发。得益于两阶段策略,模型能够以更少的参数运行。在他们的框架中,采用了三个残差局部特征块 (RLFB),与原始版本相比通道数减少了。此外,将 ReLU 替换为 LeakyReLU 以减轻梯度消失。
PS:AR-RLFN指标是所有团队中最低的,而且距离达标差很多。但从提出的方法而言,感觉不应该PSNR不应该差这么多才对,难道是没训练好?
NJUPCA:空间域与频域结合

受 SPAN的启发,他们提出了空间频率网络 (SFNet),它充分利用了空间域和频域表示。SFNet在每个空间注意块之后集成了频率知识挖掘器(FKM)模块(SPAB) 捕获频域特征,补充 SPAB 提取的空间特征。这种并行设计使网络能够有效地学习和组合空间和频域表示,提高超分辨率重建的性能。如图38所示,频率知识挖掘器(FKM)旨在从输入中学习频率表示,包括两个核心组件:多频带频率学习器(MBFL)和全频调整学习器(FFAL)。MBFL旨在通过关注不同的频带来增强频率表示,而FFAL从全频的角度调整频域特征。
PS:往频域上靠是非常不错的思路,缺啥补啥。
DepthIBN:改进卷积层
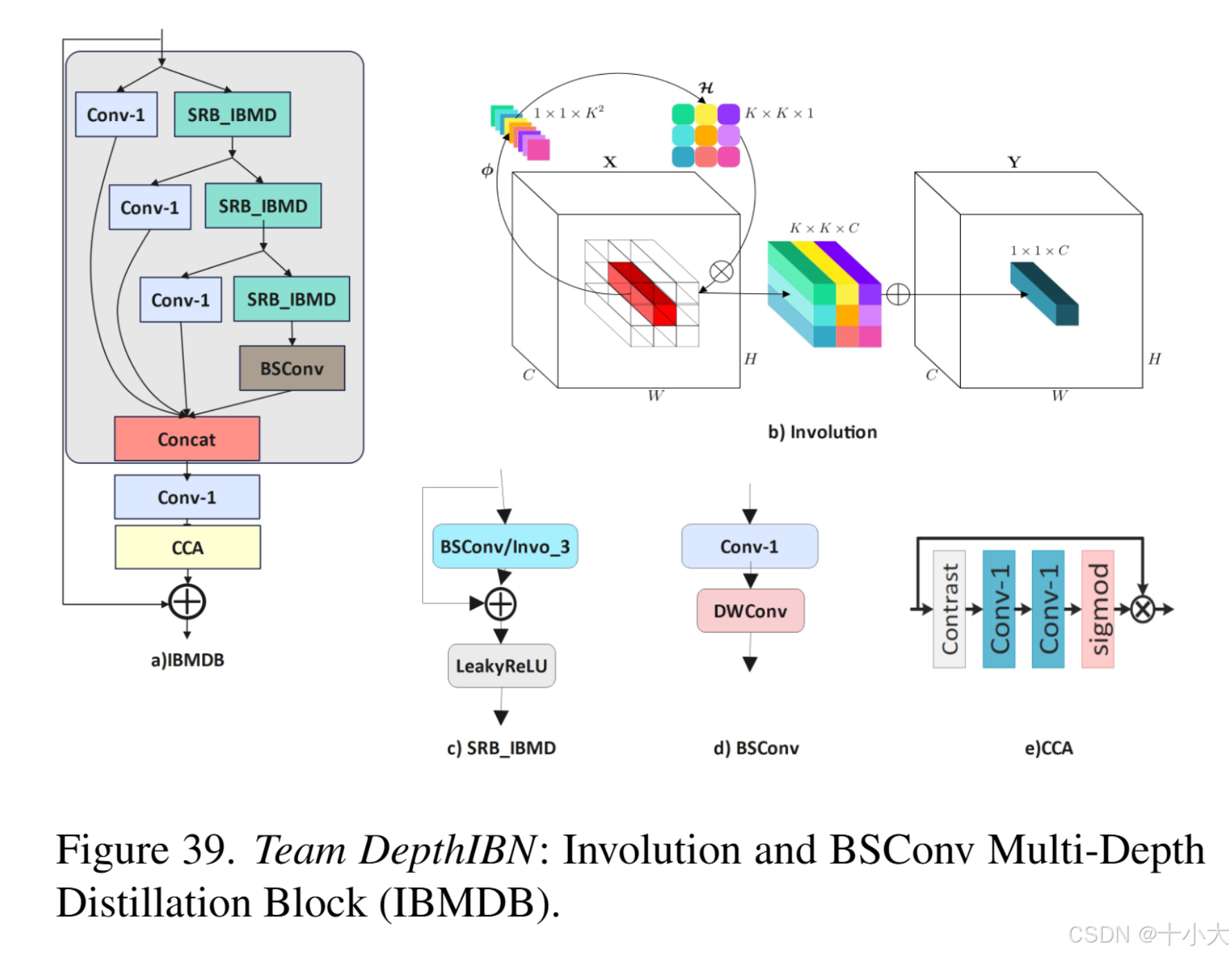
为了降低卷积计算成本,使用DSConv和BSConv。
- IBMDN:由6个对合和BSConv多深度蒸馏块(IBMDB)组成。IBMDB集成了Involution和BSConv来平衡计算效率和特征提取。他们提出的模型的整体架构包括四个主要部分:浅层特征提取、深层特征提取、特征融合和重建。3×3 卷积用于提取浅层特征。然后,通过 6 个 IBMDB 块,使用 1×1 卷积提取和融合深度特征,然后通过 3×3 卷积进行细化。然后将像素混洗操作用作重建模块。
- IBMDB:由三个浅剩余块(SRB IBMD)和一个通道对比注意(CCA)块组成。
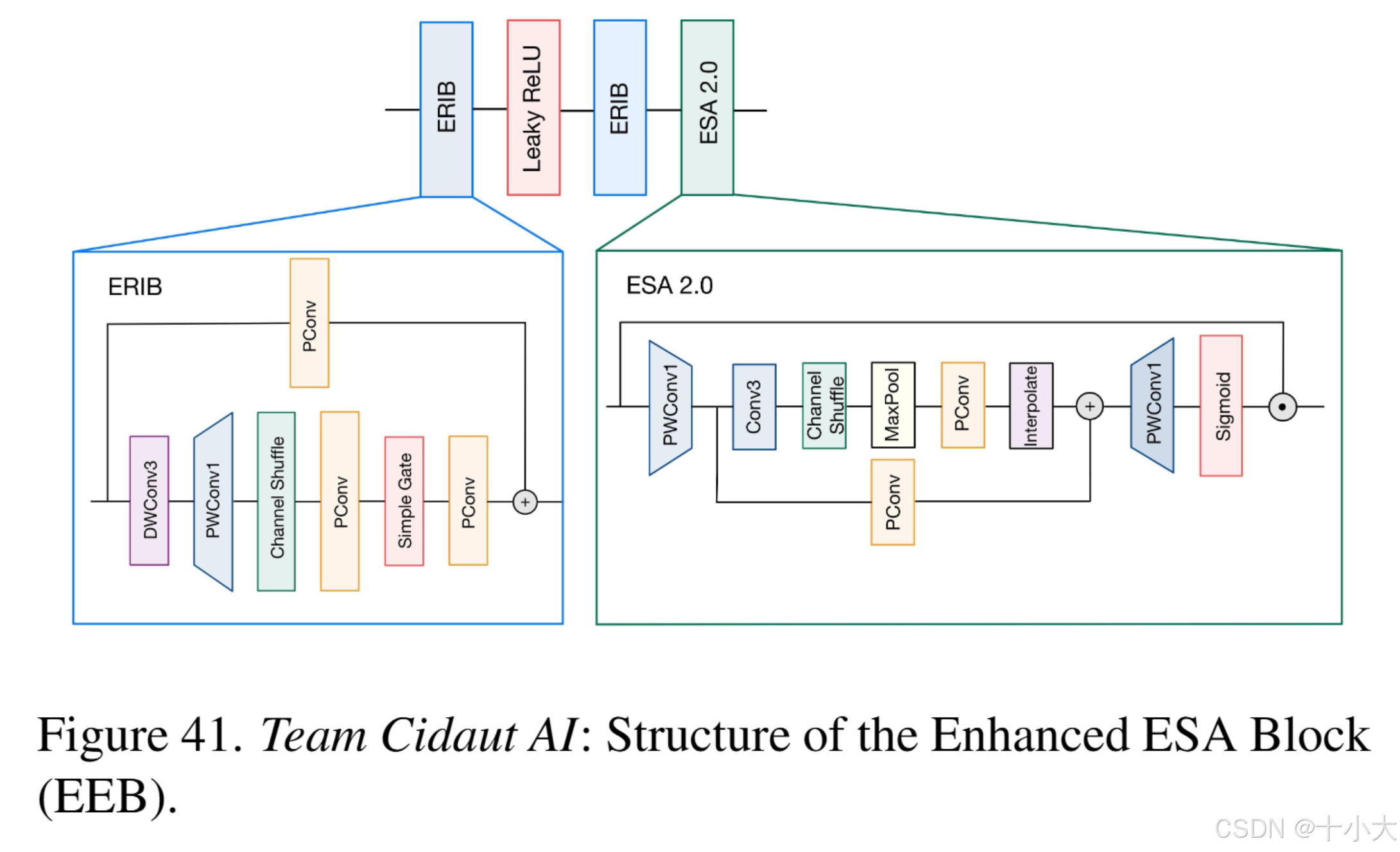
Cidaut AI:只有3个块
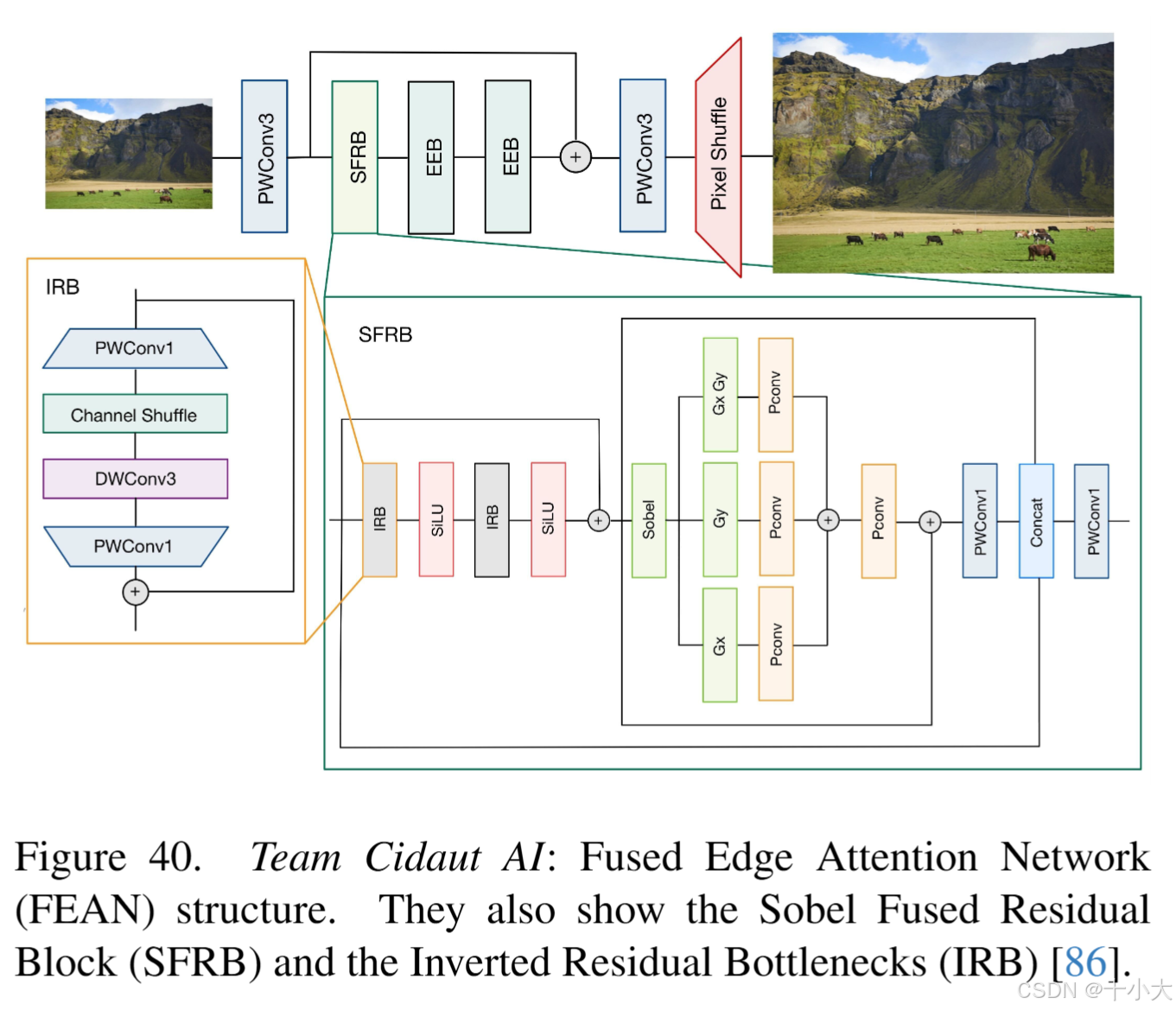
- 整体结构:只有三个块,一个初始的基于Sobel的块和两个基于ESA的边缘细化块,由全局残差连接调节。
IVL:SPAN的块集成到EFDN主干中
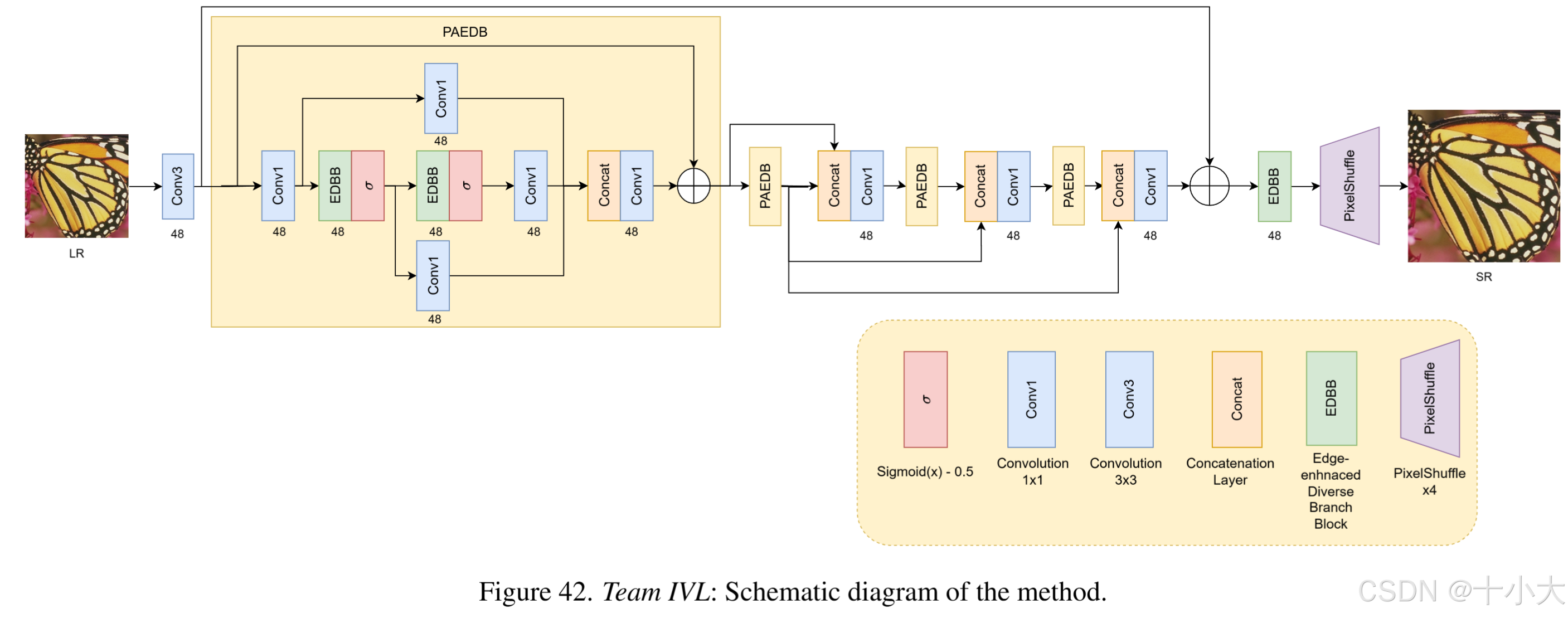
SPAN集成到EFDN中,应用Sobel和Laplacian滤波器来捕获图像的基本结构特征。
总结与思考
轻量化改进方式汇总:
- 网络结构改进:
- 删除冗余结构:删除多余的卷积层、残差链接等;
- 降低卷积通道数:原始通道数很高的往下降,比如48降到32;
- 某个组件的轻量化版本替代原始版本:比如PWConv、BSConv、DWConv等替代原始Conv,SiLU替换ReLU;
- 使用更大的卷积核:大卷积核更轻量
- 串行变并行:增强特征融合;
- 卷积分解:3×3Conv分解为1×3和3×1;
- 通道划分:多分支非平均划分;
- 其他手段:Reparameterization(训练复杂模块,推理当成单个卷积),蒸馏,多阶段渐进式训练;
轻量化超分方向研究思路:复现主流算法,找缺点作为Baseline,针对缺点提出具体模块。
主要Baseline:SPAN、DIPNet、SAFMN,SMFANet,EFDN,RepRFN,RLFN等。
所属专栏
SPAN等轻量化超分方法的论文精读和复现见专栏:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等
请查看目录中的【高效/轻量化超分(Efficient/Lightweight SR,ESR)】部分。
相关链接
SPAN的论文精读与复现:
【图像超分】论文精读:Swift Parameter-free Attention Network for Efficient Super-Resolution(SPAN)
【图像超分】论文复现:CVPR 2024 NTIRE Workshop ESR赛道冠军!SPAN的Pytorch源码复现,跑通源码,图文手把手教程解决源码中存在的各种问题,获得结果,完美复现!
SAFMN的论文精读与复现:
【图像超分】论文精读:Spatially-Adaptive Feature Modulation for Efficient Image Super-Resolution(SAFMN)
【图像超分】论文复现:类ViT的块,融合CNN和Transfomer的特性,全局和局部信息捕获!轻量化超分模型SAFMN的Pytorch源码复现,跑通源码,图文教程,获取结果,结构图与源码对应!
SMFANet的论文精读与复现:
RepRFN的论文精读与复现:
【图像超分】论文精读:Reparameterized Residual Feature Network For Lightweight Image Super-Resolution(RepRFN)
RLFN的论文精读与复现:
【图像超分】论文精读:Residual Local Feature Network for Efficient Super-Resolution(RLFN)
与我联系
超分交流群(QQ):750414192
VX:shixiaodayyds(可加微信交流群,注明来意)
至此本文结束。
如果本文对你有所帮助,请点赞收藏,创作不易,感谢您的支持!
点击下方👇公众号区域,扫码关注,可免费领取一份200+即插即用模块资料!


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











