









敢信一块2080Ti就能做大模型数据蒸馏?上交大提出的全新数据集蒸馏方法NFCM做到了,不仅速度提升了20倍,GPU占用更是只有2G!相关论文获得了CVPR 2025满分!
作为DeepSeek的核心技术,数据蒸馏因为能通过压缩数据集或知识迁移,显著降低模型训练成本,成为了资源受限场景(比如移动设备)必备技术。又因为其涉及子领域众多(比如分布匹配),还与生成模型等技术交叉,从而拥有了相当丰富的理论探索空间。可谓产业与学术的双重落地,无疑是机器学习领域的研究焦点。
且单从论文上看,数据蒸馏在CVPR等顶会上接受度日益增高,研究价值有目共睹,想上车的得抓紧了。建议论文er们从技术瓶颈(比如计算成本)切入,尤其在算法优化、跨领域应用和理论深化方向。需要参考的可以看我整理的15篇数据蒸馏新论文,基本都有代码方便复现。
全部论文+开源代码需要的同学看文末
CVPR 2025满分论文 Dataset Distillation with Neural Characteristic Function: A Minmax Perspective
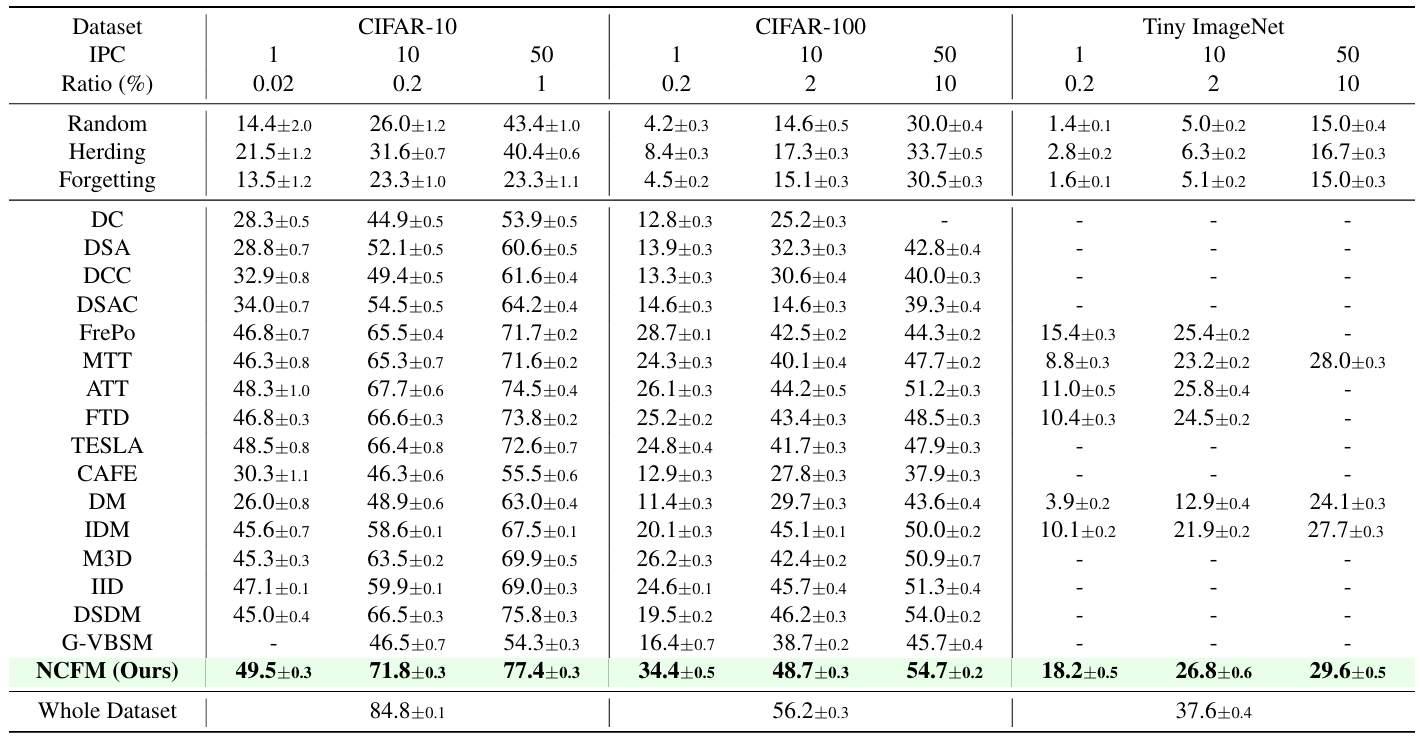
方法:论文提出了一种新的数据蒸馏方法NCFM,通过将数据蒸馏转化为一个 minmax 优化问题,并利用神经特征函数(NCF)来衡量真实数据和合成数据之间的分布差异。该方法通过优化特征函数的采样策略,最大化分布差异,从而生成更接近真实数据的合成数据。
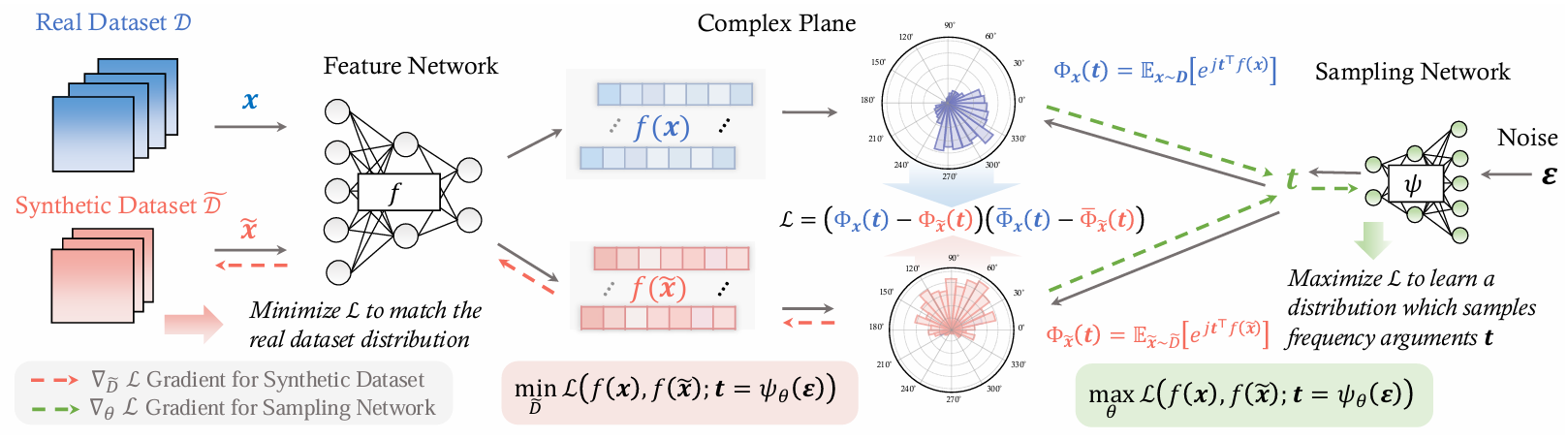
创新点:
-
提出了一种新的度量方法,称为神经特征函数差异度量(NCFD),用于精确捕捉真实数据和合成数据之间的分布差异。
-
基于NCFD,作者引入了一种名为神经特征函数匹配(NCFM)的方法,将数据集蒸馏重新定义为一个极小极大优化问题。
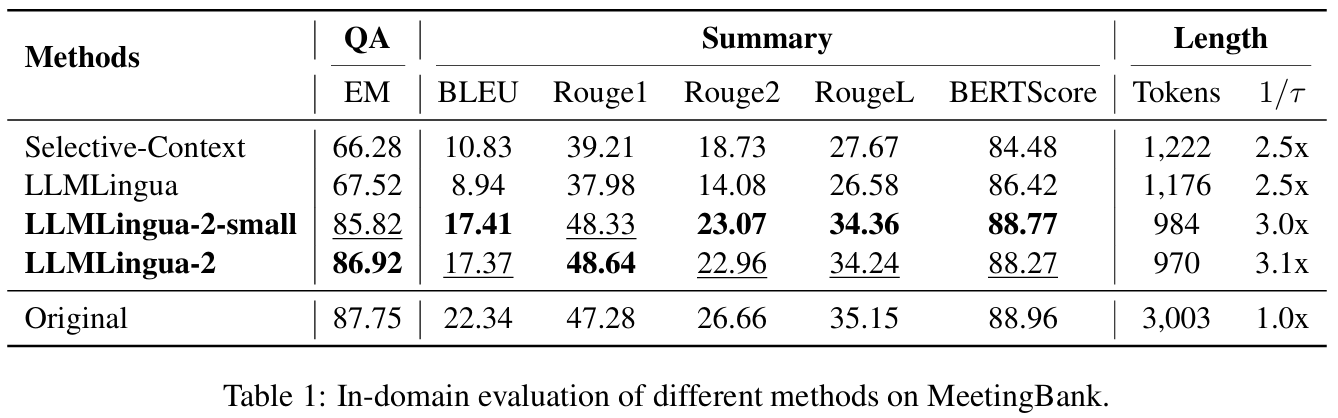
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression
方法:论文提出了一种名为LLMLingua-2的任务无关提示压缩方法,通过数据蒸馏从大型语言模型中提取知识,生成压缩后的提示,同时保留关键信息。该方法将提示压缩建模为标记分类问题,利用 Transformer 编码器捕捉双向上下文信息,压缩速度比现有方法快 3-6 倍,端到端延迟加速 1.6-2.9 倍。
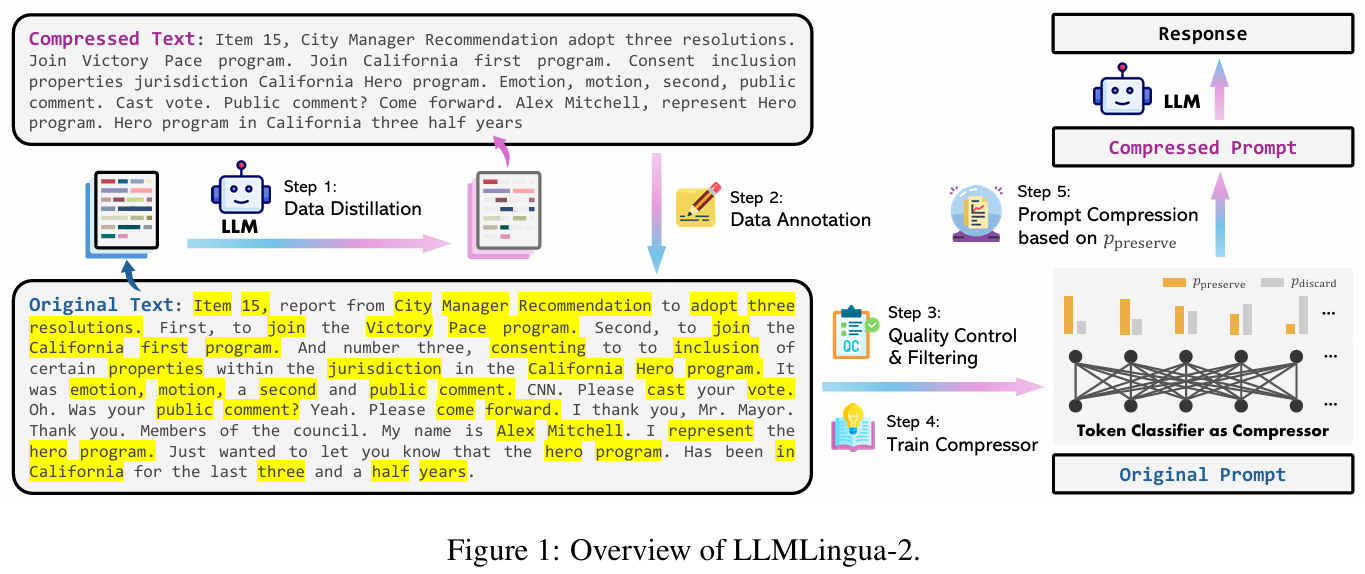
创新点:
-
提出了一种数据蒸馏程序,从大型语言模型(如GPT-4)中提取知识以压缩提示,而不丢失关键信息,并引入了一个新的提取式文本压缩数据集。
-
通过将提示压缩视为一个标记分类任务,作者利用基于Transformer的编码器从完整的双向上下文中捕获所有关键信息。
CVPR 2025 DKDM: Data-Free Knowledge Distillation for Diffusion Models with Any Architecture
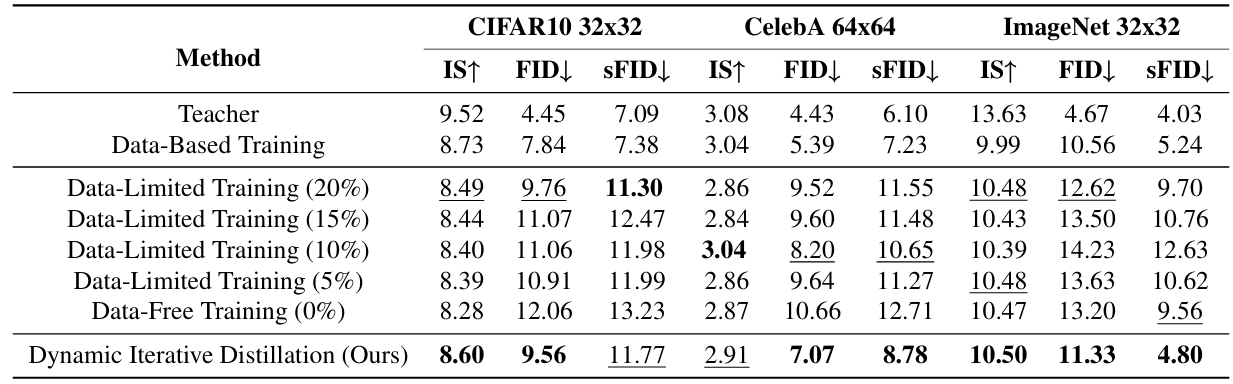
方法:论文提出了一种无数据的知识蒸馏方法(DKDM),通过利用预训练扩散模型生成的噪声样本作为“知识”,来训练新的扩散模型,而无需依赖原始数据集。这种方法不仅减少了数据存储和获取的成本,还提高了训练效率,并在某些情况下超越了传统数据驱动的训练效果。
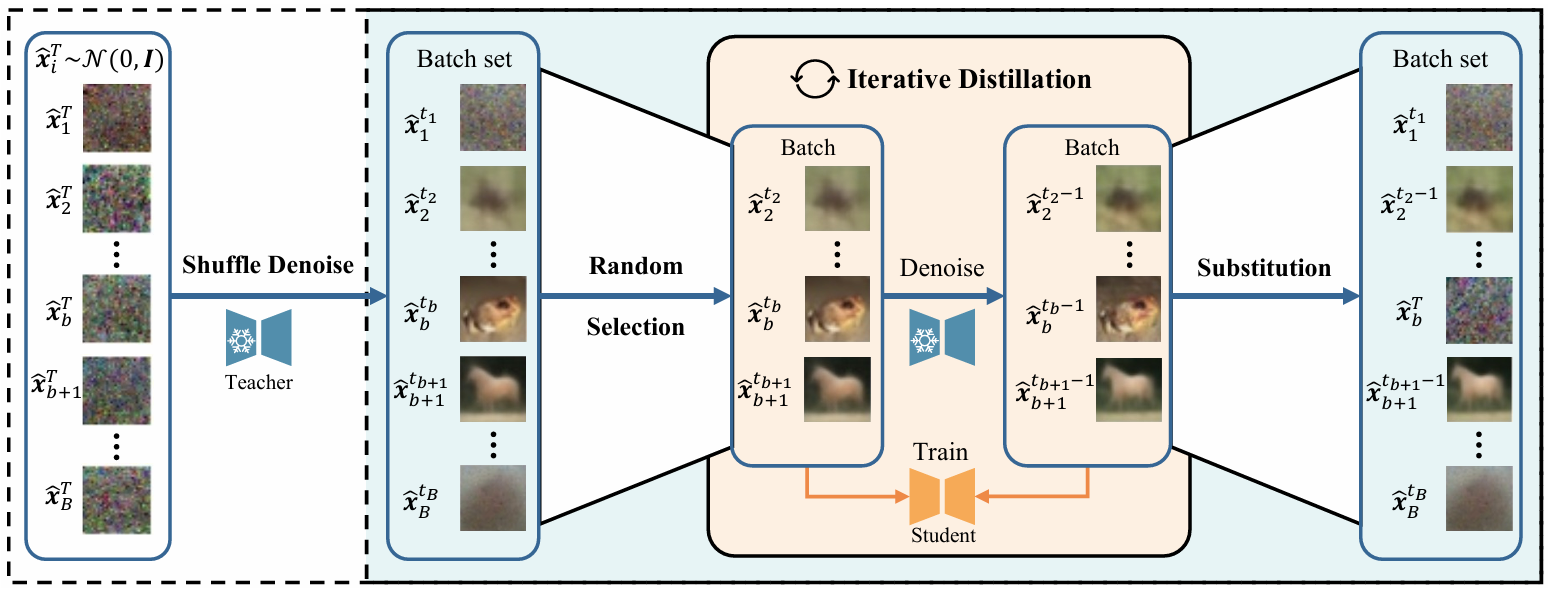
创新点:
-
创新性地利用预训练扩散模型进行新模型的训练,而无需访问原始训练数据集。通过设计DKDM目标和动态迭代蒸馏方法,这种方法确保了学生模型训练过程的有效性和效率。
-
本文的方法能够超越特定模型架构,实现从基于CNN的扩散模型到基于ViT的模型的蒸馏,反之亦然。
Teacher as a lenient expert: teacher-agnostic data-free knowledge distillation
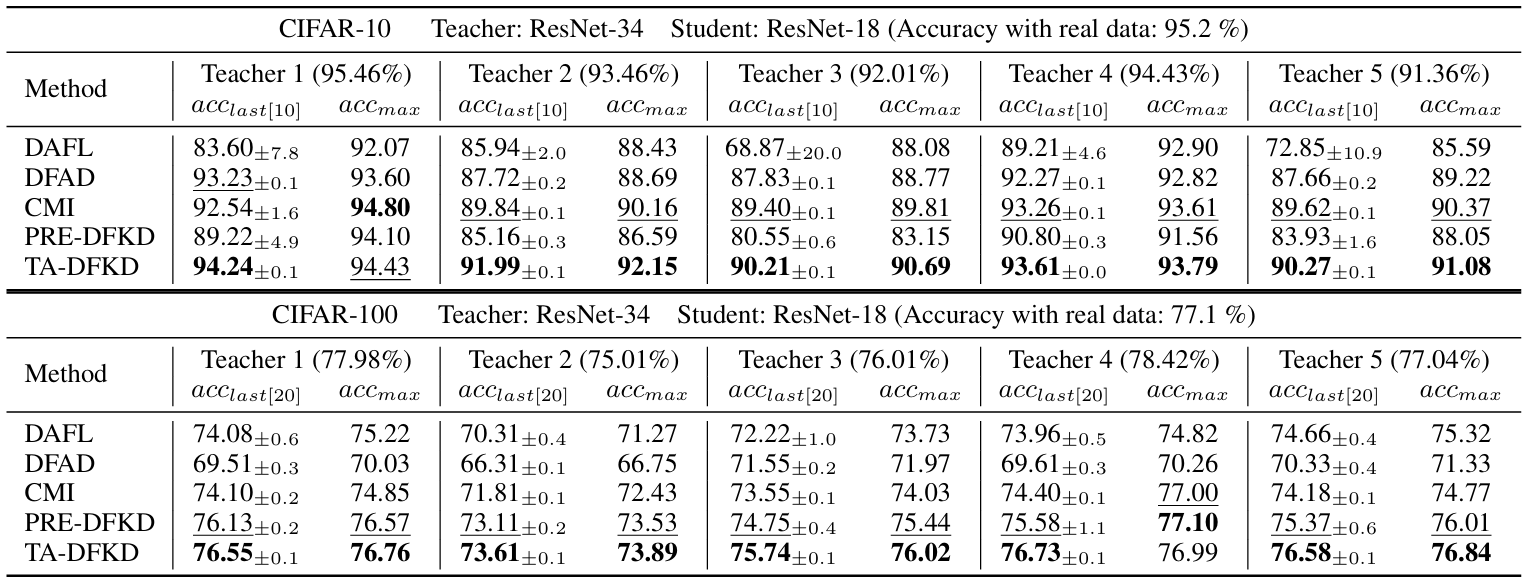
方法:论文提出了一种新的数据蒸馏方法TA-DFKD,通过去除类别先验限制并引入样本筛选机制,生成高质量且多样化的合成数据,从而实现更稳定和鲁棒的知识蒸馏,不依赖于具体教师模型。
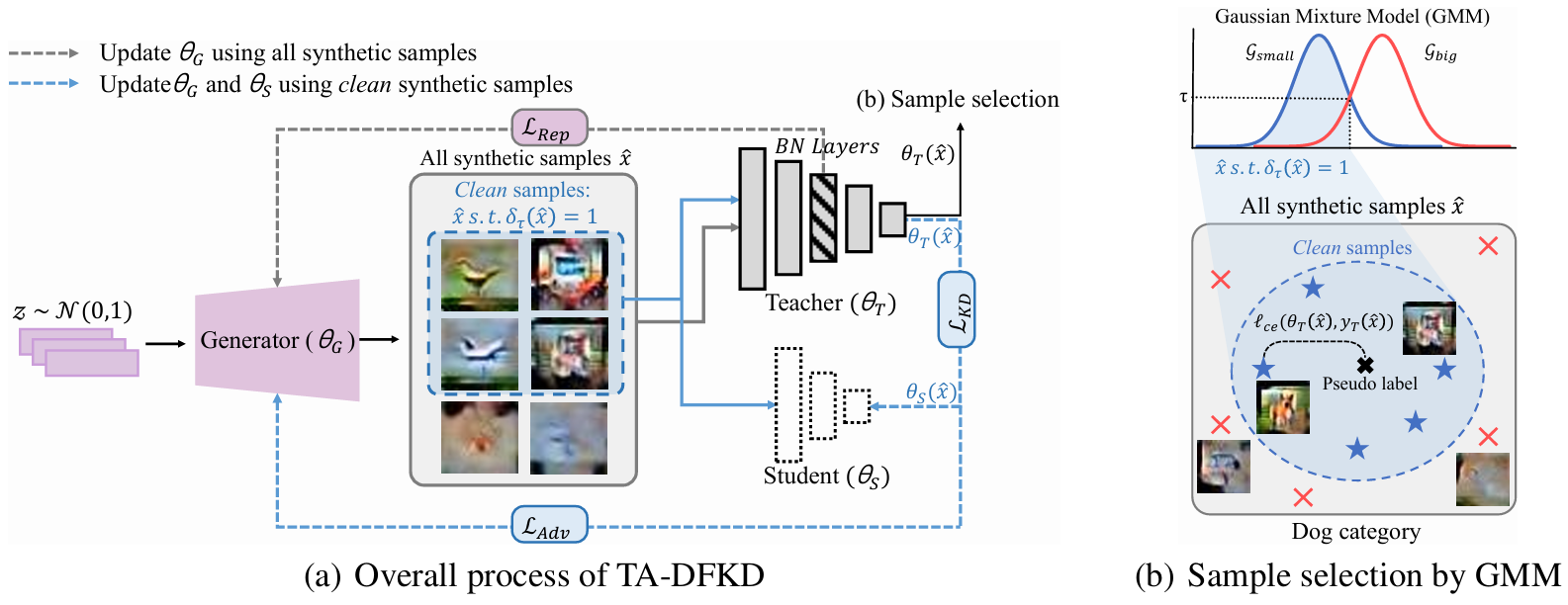
创新点:
-
提出了教师无关的数据无关知识蒸馏方法,旨在实现不依赖于特定教师模型的稳健和稳定的性能。
-
引入了一种教师驱动的样本选择机制,仅选取由教师模型自信验证的干净样本。
-
重新审视了类先验损失的必要性,指出在无类先验限制的情况下,生成器可以自由生成更多样的样本。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“数据蒸馏”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









