



Masked Image Modeling: A Survey
原文链接:Masked Image Modeling: A Survey
摘要
在这项工作中,我们调查了最近关于掩码图像建模(MIM)的研究,这种方法在计算机视觉中成为一种强大的自我监督学习技术。MIM 任务涉及屏蔽一些信息,例如像素、补丁甚至潜在表示,并训练模型(通常是自动编码器)以使用输入可见部分中可用的上下文来预测缺失的信息。我们确定并正式确定了如何将 MIM 作为借口任务实施的两类方法,一种基于重建,另一类基于对比学习。然后,我们构建了一个分类法并回顾了近年来最突出的论文。我们用通过应用分层聚类算法获得的树状图来补充手动构建的分类法。我们通过手动检查生成的树状图进一步识别相关集群。我们的综述还包括 MIM 研究中常用的数据集。我们在最流行的数据集上汇总了各种掩蔽图像建模方法的性能结果,以促进竞争方法的比较。最后,我们确定了研究差距并提出了未来工作的几个有趣的方向。
关键词:掩码图像建模,掩码自动编码器,自监督学习
1 引言
数据在训练大型深度神经网络中一直发挥着至关重要的作用。从人工注释者团队那里获得精选的标记数据集不仅需要付出巨大的努力和费力的过程,而且还意味着一笔巨大的费用。因此,已经探索了各种自我监督学习策略,其中模型使用不同的目标进行预训练,不需要人工标签。自我监督学习可以帮助模型学习丰富的特征再现,甚至超越监督替代方案(He et al., 2022)。然后,在微调阶段,针对特定的下游任务进一步优化模型。例如,在大多数图像分类任务中,一种常见的方法是在 ImageNet 数据集上训练网络(邓等人,2009 年;Russakovsky et al., 2015),然后更改新任务的分类头,并在相关数据集上训练结果模型。
自监督学习是预训练深度学习模型的一种常用方法。它涉及在不注释数据的情况下创建监督设置,而是使用固有结构 NeurIPS 2023(损坏或模糊),然后使用基于卷积层的架构重建。的数据。由于其潜力,近年来,自我监督的预训练算法已迅速被视觉领域采用。Doersch 等人(2015 年)以及 Noroozi 和 Favaro (2016 年)在这个方向上的早期工作受到拼图想法的启发,他们提议将图像分成块并估计每个块的位置。Wang 和 Gupta (2015) 提出了另一种预训练策略,其目标是使视频中第一帧和最后一帧之间的距离小于初始帧与另一个视频的随机帧之间的距离。Pathak et al. (2017) 根据视频中物体的运动创建了一个分割图,然后使用人工分割图作为基本实况,应用分割任务进行预保留。其他突出的借口任务是给灰度图像着色(Zhang等人,2016 年)或旋转输入图像并估计它旋转的角度(Gidaris 等人,2018 年)。
随着 Transformers 双向编码器表示 (BERT) 的引入,通过屏蔽部分输入然后预测屏蔽信息来预训练模型的想法获得了关注(Devlin et al., 2019),这在自然语言处理领域带来了重大进步。主要优点是可以使用大量未标记和非结构化的文本数据。值得注意的是,这种借口策略较早地被应用于视觉问题,由 Vincent 等人(2010 年)和 Pathak 等人(2016 年)提出,其中原始输入信号被改变。后来的工作甚至采用了编码器-解码器模型来修复输入图像中缺失的区域。尽管如此,正如 He 等人(2022 年)所介绍的那样,与最近的蒙面图像建模 (MIM) 文献存在一些差异,因为上述论文将问题界定为一项去噪任务。
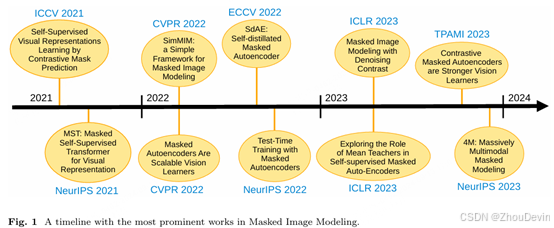
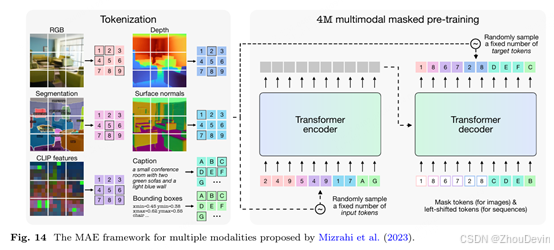
在图1中,我们展示了蒙版图像建模中最突出的工作时间表。在ICCV 2021上,Zhao et al.(2021)提出了一种自我监督学习方法,该方法在图像的掩蔽补丁和其他区域之间应用对比损失。在NeurIPS 2021上,Li等人(2021年)提出了一个同时采用重建和转换目标的师生框架。在CVPR 2022上,He et al.(2022)和Xie et al.(2022)引入了一个预训练框架,该框架涉及掩盖大部分输入,并使用基于视觉转换器(ViT)架构的自动编码器对其进行重建(Dosovitskiy et al., 2021)。他们同时进行的研究代表了以下研究的基础。继Li et al.(2021)之后,Chen et al.(2022)正式提出了一种涉及两个目标的预训练方法,但遵循掩码自动编码器(MAE)框架。除了使用MAE进行预训练外,Gandelsman等人(2022年)还演示了如何在推理时使用MAE,从而提高下游任务的性能。在ICLR 2023上,Yi等人(2023年)将MIM与去噪对比学习相结合,以实现更好的功能学习,而Lee等人(2023年)分析了2师生MIM框架,并在最新的技术中展示了这一点。Li等人的工作将教师的权重更新为学生的指数移动平均值的优势。Huang et al.(2023)是在MAE框架中整合重建和对比目标的另一个重要垫脚石。在NeurIPS 2023上,Mizrahi等人(2023年)提出了一种方法,该方法将掩码预训练方法应用于多种输入视觉模态以及文本。
在最新神经网络更复杂的架构以及它们需要大量注释数据的背景下,预训练此类模型已开始成为先决条件。掩蔽图像建模代表一项借口任务,包括掩盖来自输入的一些信息(原始信号或从中获得的一些特征),然后估计一个输出,该输出应该与输入保持不变相同,甚至预测原始输入。这种预训练策略很快就流行起来,特别是因为该机制很容易用著名的trans former架构实现,因此它出现在许多领域和任务中。因此,研究如此大量的研究论文并找到必要的信息是非常困难和耗时的。我们的工作旨在减少这一挑战并促进进一步的研究或工业努力。首先,我们提出了一个所有掩码图像建模方法都遵循的通用框架,并确定了两种不同类型的方法:一种涉及输入重建,另一种采用对比物镜。此外,我们仔细全面地回顾了最近的论文,并从这些研究中提取了主要思想和贡献。此外,我们根据多个标准手动将审查的研究组织成分类法,并辅以通过分层聚类获得的树状图。
鉴于掩蔽图像建模的日益突出以及有关该主题的研究出版物的相应增加,已经进行了几项研究,其目标与我们相似:促进文献综述过程。其中,Li et al.(2023)对掩码建模的调查是一个显着的贡献,我们的论文与许多共同点,例如预训练期间采用的一般框架、手动分类法的一些标准,甚至一些提交的论文。尽管如此,我们的调查侧重于视力和如何应用MIM在最新的技术中。李等人的工作调查了广泛的领域,同时每个领域包括有限数量的论文。此外,我们对图像领域的调查范围更加集中,使我们能够审查更多的视觉论文以进行更彻底的研究。因此,我们认为我们的工作更具包容性,尤其是在计算机视觉领域。与Li et al.(2023)相比,我们通过手动和自动聚类来组织论文,提供了对调查论文进行分类的补充方法。
为了突出我们调查的目的,我们将我们的贡献总结如下:
• 我们重点介绍了如何将蒙版图像建模作为借口任务的两类方法。
• 我们回顾了近年来最突出的论文,并构建了一个有助于研究相关文献的分类法。
• 我们对摘要应用分层聚类算法,并通过手动检查生成的树状图来识别相关聚类。
• 我们审查了常用的数据集,并将各种掩蔽图像建模方法的结果集中在一个地方,以促进竞争方法的比较。
• 我们确定了研究差距,并提出了掩蔽图像建模领域未来工作的几个有趣方向
2 通用框架
蒙版图像建模是一种无监督的技术方法,通常在预训练阶段应用。它涉及掩盖一些信息,无论是来自输入还是来自潜在表示,然后估计原始数据,就好像数据不会被隐藏一样。尽管已经提出了许多掩蔽图像建模技术,但研究主要集中在两个主要方案上,要么重建掩蔽信号,要么比较两个潜在表示,一个用于未改变的输入信号,一个用于掩蔽输入。在少数情况下,探索了不同的方法,但它们都是建立在相似的基础上的。因此,在以下小节中,我们旨在给出上述前两种方案的一般表述
2.1 重建
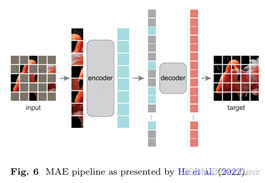
我们确定的第一个方案围绕着在模型前向传递期间的任何阶段屏蔽一些信息,然后使用解码器重建缺失数据的想法。He et al.(2022)和Xie et al.(2022)在同时进行的工作中引入了这种预训练技术。这两件作品都由一个基于ViT架构的编码器组成(Dosovit skiy et al., 2021),其中很大一部分输入标记(通过线性投影图像的非重叠补丁产生)将被遮罩。在编码阶段之后,掩码标记被特殊标记替换,解码器用于重建它们。在He et al.(2022)提出的掩码自动编码器(MAE)中,解码器比编码器轻,这导致了非对称度量架构。损失函数仅应用于与掩码令牌对应的输出。当应用于下游任务时,解码器被丢弃,只有编码器被用作主干,因为它具有强大的功能表示能力。我们在图2中说明了重建框架。
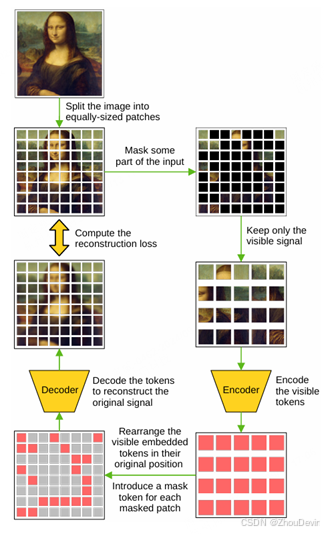
图2 基于重建的MIM管道。输入图像被分割成块。一些生成的Patch被遮罩,其余的Patch通过编码器传递。接下来,对应于掩码和可见补丁的潜在向量通过解码器。最后,计算输出patchs和原始输入patchs之间的重建损失。这个自我监督管道的全部目的是通过学习重建被掩盖的补丁来生成一个强大的潜在代表。最好用彩色观看。
我们在算法1中正式提出了基于重建的训练策略。该算法的第一步是将输入图像分割成不重叠的块,从而产生一个包含相同大小(即h×w像素)的块的集合P。第二步应用掩码操作,该操作可能因方法而异。掩码操作指示应保留哪些补丁,应掩码哪些补丁。这可见补丁和掩码补丁的索引分别存储在Iv和Im中。在接下来的步骤中,通常会丢弃被掩盖的补丁,只有可见的补丁由视觉投影层(VPφ)处理,然后是提取潜在表示的编码器(Eθ)。在解码步骤之前,先前屏蔽的patch被可学习的表示(M)替换,它位于编码器的潜在空间中。这些转换对应于算法1中的步骤3-7。
使用通过将掩蔽表示与编码器中的表示连接起来形成的序列,解码器(Dφ)重建补丁,如算法1的步骤8所示。最后,在算法1的步骤9-13中,通过更新编码器、解码器、投影层和可学习的掩码表示来优化距离函数。
2.2 对比
第二种泛型方案通过比较同一输入的两种不同的潜在表示来表示。一个潜在表示对应于未更改或弱增强的输入图像,而另一个对应于同一输入图像的遮罩和强增强版本。该方法基于对比学习框架,如图3所示。有两种常见的架构配置。一种配置使用具有共享权重的编码器,如(Wu et al., 2023;Zhang et al., 2023)。另一种配置将编码器用于掩蔽输入,将编码器的指数移动平均线(EMA)版本用于原始输入,如(Lee et al., 2023)。
通用的基于对比的MIM框架在算法2中正式化。该框架的目的是获得类似的嵌入,与应用的掩码无关。该算法的步骤1和2通过以不同的强度增强输入图像来生成两个版本的输入图像。经过掩码的版本是强增强的,而另一个版本是弱增强的(甚至可以保持不变)。在步骤3-4中,每个图像被划分为不重叠的补丁,在步骤5中,蒙版仅应用于强增强的图像。未被遮罩的图像由投影层和编码器进行处理(步骤7),而被遮罩的图像在编码之前,image将其省略的补丁替换为可学习的向量(步骤8-11)。值得注意的是,算法2使用相同的编码器处理两个输入图像,这可以被视为两个权重共享的编码器。渐变传播仅限于蒙版图像的处理。另一种方法(Lee等人,2023年)是在步骤9和11中使用基于EMA的编码器处理未遮罩的图像。该算法的第12步计算对比损失,其中负斑块来自同一图像内的不同ent位置。此外,在实践中,底片也可以来自其他图像。最后,算法的最后步骤(13-15)更新了编码器、投影层和可学习表示M的权重。尽管对比学习方法在技术上与基于重建的方案不同,但Zhang et al.(2022)证明,就学习的潜在表征而言,对比方法与基于重建的框架密切相关
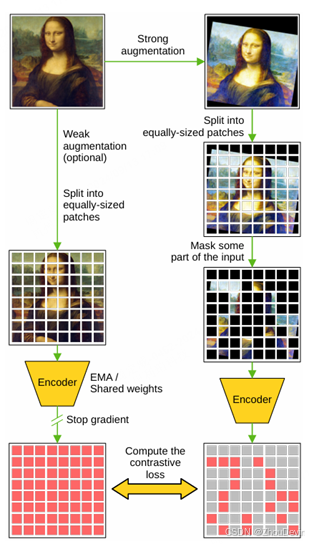
图3 基于对比的MIM管道。此框架中使用了两个版本的输入图像,一个是未更改的(或弱增强),另一个是强烈增强和遮罩的。图像由两个编码器处理,一个教师编码器(左)和学生编码器(右)。教师编码器要么与学生编码器相同,要么是学生编码器的指数移动平均线(EMA)。训练基于应用于补丁的潜在表示的对比损失。渐变仅通过student编码器传播。最好用彩色观看。
3 分类学和概述
在图4中,我们提出了最有前途的MIM论文的手动生成的分类法,并根据它们的主要贡献对它们进行了组织分类。在构建分类法时,我们考虑了与以下相关的六个主要研究方向:掩蔽策略、掩蔽信号的类型、神经结构、目标函数、下游的类型任务和理论结果。尽管如此,由于许多论文都集中在上述多个方面,我们将各自的作品分为代表撰写贡献的不同类别。现在我们继续介绍上述论文,根据我们的分类法分为几个小节。
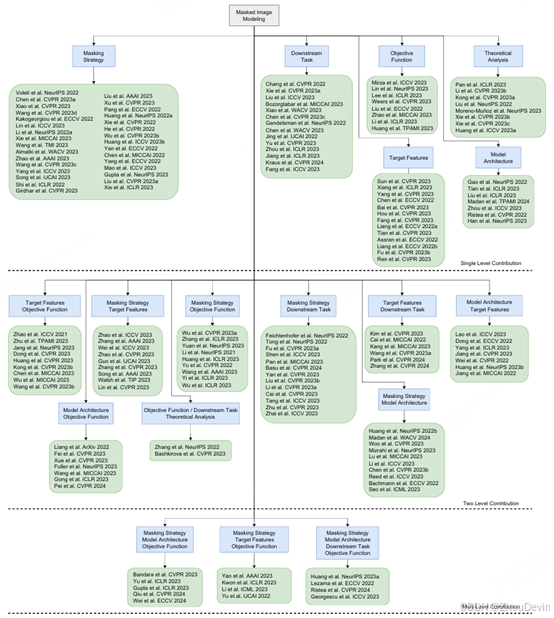
图 4 根据各自论文研究的研究方向,将蒙版图像建模论文多级分类为不同类别
3.1 掩码策略
早期的掩蔽策略基于选择大量随机补丁并对其进行掩蔽。最近,已经提出了许多替代掩码策略来改进MIM。一种建议是通过不同的机制来指导掩蔽,从利用图像统计(Xu et al., 2023)到使用额外的简单网络(Bandara et al., 2023)甚至自我注意模块(Chen et al., 2023;Yang et al., 2023)。
Xie et al.(2022)介绍了SimMIM,这是一个自我监督的预训练框架,用于侦察随机掩码图像的像素值。该方法的概述如图5所示。该模型是一个简单的编码器(ViT),它接收图像作为输入,其中掩码补丁被可学习的标记替换。此外,该研究通过广泛的消融研究促使选择随机掩蔽和原始像素作为目标特征。
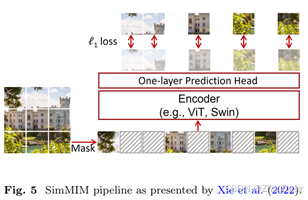
Ta 等人(2022年)提出了掩码自动编码器(MAE)框架,其中主要贡献是从编码器的输入中排除掩码令牌,并使用非常高的掩码率(75%)。与其他工作(如SimMIM)相比,这些变化意味着更有效的框架(Xie等人,2022年)。然而,作为一个负面影响,拥有一个只在可见令牌上运行的编码器会使该框架默认与分层视觉转换器(Liu et al., 2021)架构不兼容,后者通常比标准ViT表现得更好。MAE管道如图6所示。
Pang et al.(2022)将蒙面预训练策略应用于3D点云。该方法将点分组为面片,并遮罩其中一些面片。然后,它仅嵌入和编码未屏蔽的补丁。接下来,可见的补丁与掩码标记连接并通过解码器传递,目的是侦察struct后者。作者指出,提前传递屏蔽补丁会泄露空间信息,从而简化了任务。
Yan et al.(2022)将训练前掩蔽策略应用于研究较少的全景深度完成任务。由RGB图像和关联的稀疏深度图组成的对被联合遮罩。然后,两者都通过引导的卷积网络(Tang et al., 2020)生成稀疏深度图,并且仅针对掩蔽深度计算重建损失。在密集深度图预测下游任务上进行实验,所提出的方法称为M3PT,显示出比以前最先进的技术更好的定性和定量结果。
Kako georgiou等人(2022年)没有实施掩蔽政策,而是提出了一个学习掩蔽策略的框架。教师网络看到完整的图像,生成一个掩码,用于对学生进行预训练。目标是为掩码标记重建教师的特征表示,以及用于生成掩码的类标记 [CLS]。教师的参数使用学生权重的指数移动平均值进行更新。实验证明了该方法优于其他掩蔽策略。为了提高任何基于特征学习的知识调整框架的性能,Yang et al.(2022)提出了一个辅助任务。学生的潜在特征图的所有权被屏蔽,投影层会尝试恢复被屏蔽的特征图并将其与教师的特征图匹配。这为各种计算机视觉任务带来了更高的性能。
SemMAE(Li et al., 2022)在掩蔽之前部署了一个额外的阶段。这个阶段称为语义部分学习,负责学习与图像中有意义的语义成分相对应的注意力图。此阶段的训练是通过将ViT编码器提供的类令牌嵌入到零件嵌入叮当中来执行的。生成的embeddings与同一编码器提供的patch embeddings一起用于Attention层。最后,获得的注意力图由解码器处理,以侦察原始图像的结构。在第二阶段,注意力图用于零件分割。遮罩从遮罩每个部分中的修补到随机遮罩整个部分不等。
Voleti等人(2022年)引入了蒙面条件视频扩散(MCVD)。MCVD利用不同的帧掩码策略来训练用于无条件视频合成sis和视频插值的视频扩散模型。在训练时,该方法随机且独立地选择来掩盖给定视频的未来帧或过去帧。这种简单的策略允许扩散模型在推理过程中执行四个不同的任务:未来和过去的帧预测、无条件生成和帧插值。
Huang et al.(2022)在GAN的训练管道中添加了掩蔽图像建模。掩码基于两种方法。第一个称为移位空间掩码,构成图像的随机掩码。第二种称为平衡光谱掩码,随机掩盖在光谱空间中分解的图像的一些光谱带。作者观察到,这两种策略是正交的,有助于对抗性训练变得更加稳定。
Tong et al.(2022)的工作率先将掩码自动编码器(VideoMAE)应用于视频数据,将图像处理中使用的MAE原理应用于时间域。在这种方法中,帧序列以大约90% 的掩码率进行掩码。战略性地选择这个非常高的比率是为了有效地最大限度地减少紧密间隔的帧之间发生的信息泄漏问题。Wang et al.(2023)扩展了这项工作并引入了VideoMAEv2,它代表了一种放大原始VideoMAE的方法。
Chen et al.(2022)提出了一种用于视觉和语言医疗数据的蒙面autoen编码器预训练方案。该模型由两个编码器组成:一个基于ViT的图像,一个基于BERT的文本。然后,用交叉注意力模块联合处理两种模态的嵌入,以融合信息。最后,每个输入都使用sepa速率解码器进行重建:用于图像的transformer模型和用于文本的简单多层前馈网络。当语言解码器接收多模态模块最后一层的输出时,视觉解码器使用中间潜在表示。另一个重要方面是,不同的Importing类型使用不同的掩码比率。
从视频和语音数据密切相关的观点出发,Shi et al.(2022)为这两种模式提出了一个联合掩蔽预训练框架。首先,使用ResNet将每种数据类型编码为中间潜在表示,使用ResNet表示图像,使用线性层表示音频样本。在每个时间步长,通过将来自两种模式的帧替换为来自同一序列的任意采样帧来掩盖它们。然后,这些被连接起来,并通过基于transformer的编码器将信息融合在一起。受Hsu et al.(2021)的启发,目标是预测每帧属于哪个聚类,通过将离散潜在变量算法应用于从音频序列中提取的特征来重复计算聚类。
Xiao et al.(2023)引入了一种对模型进行f ine-tune的方法,目的是在分布内(ID)和分布外(OOD)性能之间实现更平衡的权衡。作者认为,在特定数据集上微调模型往往会提高它们在ID数据上的性能,但这会降低它们在OOD数据上的性能。因此,他们提出了一种方法,包括掩盖图像中的某些补丁并将其替换为另一个图像中的内容。然后,在预训练模型的超级视觉下,使用这个修改后的图像来训练模型,以识别被掩盖的图像特征。
Chen et al.(2023)观察到,现有的图像去噪方法经常过度拟合训练期间看到的噪声类型。他们的方法侧重于通过利用蒙版图像mod eling来提高此类模型的泛化能力。为此,所提出的方法掩盖了从输入图像中随机选择的像素和跨性别者架构的自我注意层中的标记。令牌掩码的使用当数据受到各种类型的噪声影响时,自我注意层有效地模拟了在推理过程中观察到的令牌中的不可靠性。此模拟有助于为数据质量可能不一致的真实场景准备模型。
.Wang et al.(2023)根据正在训练的模型提供的反馈开发了一种掩蔽策略。该策略计算每个补丁的侦察结构损失,然后有选择地掩盖更难重建的补丁,如它们较高的损失值所示。这种方法可确保模型在训练期间专注于数据中最困难的方面。
Xu et al.(2023)表明,当某些点被排除在遮罩之外时,遮罩图像建模在3D场景中更有效,即所谓的信息点。保持这些点不变将有助于在遮罩过程后保留场景的几何结构。Wu et al.(2023)提出了DropMAE,这是MAE在视频中的适用形式。
Wu et al.(2023)的主要观察是,为了学习时空特征而掩盖和重建视频补丁是不够的。提出的解决方案是丢弃空间注意力标记,以引导模型查看时间信息。
由Girdhar等人(2023年)引入的OmniMAE类似于经典的MAE框架,但在这种情况下,该模型同时使用视频和图像数据进行训练。
MixMAE(Liu et al., 2023)预训练方法整合了MAE(He et al., 2022)和SimMIM(Xie et al., 2022)的元素。此方法从训练数据集中选择两个不同的图像,并从每个图像中提取随机标记。然后,这些令牌被合并以形成一个新的混合映像。此合成图像由编码器进行处理。此外,采用了解码器,旨在重建原始的两个图像,从中衍生出混合图像。在解码阶段,提供给解码器的输入是未混合的,与混合图像中缺失的标记相对应的补丁用掩码标记填充。
Lin et al.(2023)提出了SMAUG,它是视频语言预训练的有效框架,超越了以前的方法。在其预训练过程中,SMAUG采用了一种策略,即掩盖显著的部分的帧补丁和文本标记,相应的报告)使用单独的方式进行编码,从而同时实现蒙版视频建模和蒙版语言建模。
Huang et al.(2023)认为,要在视频中成功应用MAE,在不同时间上始终如一地掩盖视频片段至关重要。如果没有这种一致性,就存在时间信息泄露的风险,使学习任务过于简单。为了应对这一挑战,他们推出了一种新颖的解决方案,利用低光学飞行技术来生成时间相干的掩膜体积。然后利用这些卷选择性地对可见令牌进行采样,确保屏蔽过程保持时间完整性并有效防止信息泄露。
Yang et al.(2023)引入了掩蔽关系模型,以改善医学图像的自我监督预训练。这种遮罩策略使用自注意力机制来识别输入图像中的强目标区域,并通过遮罩给定图块中最重要的图块来打破这种关系。同样,在图像和基因组特征之间应用了交叉注意力,旨在捕捉这两种模式之间的对应关系。
Mao et al.(2023)将MAE方法扩展到颞部骨骼序列。这项研究没有选择直接重建骨骼序列的简单方法,而是使用掩蔽的骨骼序列作为输入,构建了嵌入在序列中的时间运动。此外,它使用相同的动作来引导骨架的遮罩。
Song et al.(2023)提出了一种基于自我监督的基于掩蔽的方法,用于多智能体重新强化学习(RL)设置。对于给定的时间戳,将获取所有代理的观察结果。它们的一部分被屏蔽并替换为前一个时间戳的值,最终在潜在空间中进行编码。然后,使用重构模型从掩蔽序列中生成原始智能体的特征表示。作者断言,由此产生的特征空间受到刺激,以更多地了解代理之间的交互,同时具有更强的时间感知能力。
Xie等人(2023年)在MIM预训练期间没有对医学图像使用随机遮蔽策略,而是引入了MedIM,这是一种根据放射学报告指导遮蔽的方法。首先,两个输入(医学图像和相应的报告)使用单独的编码器进行编码。然后,根据原始单词分类,将文本嵌入向量拆分为两个子集:MeSH和Sentence tokens。文本嵌入的每个子集以及视觉嵌入dings用于生成一个隐藏不同信息的掩码。损失在两个生成的解码掩码嵌入(具有单独的头)和原始图像之间添加了侦察结构错误。
Wang et al.(2023)提出了一种应用于超像素(具有相似特性的连续像素组)的遮蔽策略,展示了其在皮肤病变的医学图像分割方面的能力。然而,在掩盖了超像素的主张之后,遵循相同的MIM方法:基于可见的超像素重建被掩盖的超像素。最初,采用基本策略(Achanta et al., 2012)来生成和屏蔽超像素,然后,以自我监督的方式优化策略,使用新策略进一步对模型进行预训练。
鉴于包含牙科全景X光片的数据稀缺,Almalki和Latecki(2023)采用了掩蔽图像建模策略(SimMIM或UM-MAE)来预训练SwinViT,以改善其对大型训练数据集的需求。然后,采用预训练的SwinViT的编码器,并将其用作检测和图像分割下游任务的支柱。
为了检测恶意网络流量,Zhao et al.(2023)引入了一个transformer模型,通过采用MAE解决了数据不足问题。在预训练期间,原始流量被处理成一个紧凑的2D矩阵,该矩阵由5个数据包级别组成,将其划分为补丁并屏蔽其中一些补丁。然后,转换器对可见标记进行编码,并尝试使用解码器重建矩阵。然而,在微调步骤中,从早期的预训练编码器创建两个不同的编码器,每个编码器都有不同的注意力层(与前一阶段的全局注意力相比)。一方面,编码器仅对同一数据包级别内的令牌进行操作。另一方面,另一个编码器在来自所有数据包级别的补丁之间执行注意。
Liu et al.(2023)提出了一种针对MAE的指导性掩码策略,而不是随机策略。所有图像都会定期通过编码器及其潜在特征表示来自最后一个attention层的 [CLS] 令牌只接受被掩盖的补丁。提取目标是为了计算所有补丁的重要性映射。使用此功能,对掩码的补丁进行采样(获得更突出的补丁的机会更高),然后通过重建进行估计,同时将最不重要的补丁的片段完全放在一边(即不提供给编码器)。
Gupta等人(2023年)扩展了MAE帧工作,以学习视频剪辑帧之间的时间特征表示。两个帧是随机采样的,前面的帧被分割成补丁,而后面的帧既被分割又被遮罩。然后使用Siamese编码器对这两个图像进行单独编码。生成的嵌入通过具有交叉注意力的解码器(由未来帧的可见标记嵌入和掩码标记组成的查询)传递,以便重建未来帧。
Xie et al.(2023)建议在频域中应用掩码,而不是在像素或补丁级别进行掩蔽。图像使用快速傅里叶变换进行转换,然后屏蔽低频或高频,并映射回像素空间。使用编码器-解码器模型,估计原始图像并将其转换为频域。目标是识别被屏蔽的频率
3.2 目标特征
早期流行的框架要么包括重建原始图像的补丁(He et al., 2022;Xie等人,2022年)或比较高级潜在特征(Chen et al.,2022年)。随后的工作采用了更适合下游任务的不同重建目标(Fang等人,2023年;Hou et al., 2023),或证明可以学习更丰富的特征表示(Bai et al., 2023)。最后,MIM已被用于图像像素以外的输入信号,其中一些研究涉及估计不同的特征类型而不是原始输入信号,例如点云的统计数据(Tian et al., 2023)。
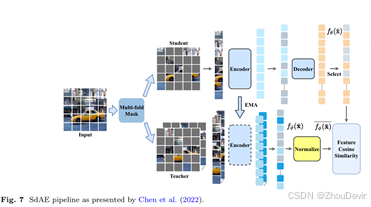
Chen et al.(2022)认为,重建图像像素空间并不会强迫网络工作学习数据的理想表示。因此,他们引入了一个自蒸馏框架,如图7所示,其中学生分支遵循原始的MAE流,而教师网络(不是通过梯度下降更新,而是从学生的权重更新)仅采用蒙版补丁。目标是匹配两个网络之间的高级功能。
Liang et al.(2022)提出了3D网格的掩码图像建模预训练。受ViT的启发,他们首先将面孔(每张面孔由一个10D向量表示)分组到一个补丁中。然后,他们采用变压器架构,使用每个补丁中心的3D位置来计算位置嵌入丁。该算法遵循MAE:以高掩码率随机屏蔽补丁,可见补丁通过编码器,然后将产生的潜在嵌入与掩码标记(与掩码补丁相关联)连接起来,然后进行解码。目标不仅是重建被掩盖的补丁(通过预测vertices的坐标),而且还重建补丁的面(10D表示)。
受MAE的启发,Assran等人(2022年)提出了一个涉及连体网络的自我监督掩码训练前策略。给定一个源图像并对其应用转换,将生成两个不同的视图(锚点和目标)。然后,仅屏蔽锚点的标记化补丁,并使用Siamese网络(遵循ViT架构),对两个视图进行编码。将潜在表示与一组可学习的原型进行比较,以生成分布,最终目标是获得匹配的分布(锚点和目标的预测)。虽然锚点的模型使用梯度下降法进行更新,但目标的网络参数是根据锚点网络的权重计算为指数移动平均值。作者证明,该方法大大提高了小镜头场景中的性能。
给定一个标记的(源)和一个未标记的(tar get)3D点云数据集,Liang et al.(2022)的目标是通过在编码器中嵌入有关常见特征的信息,将知识从后者转移到前者。该模型在两个数据集上同时训练,但目标不同。一方面,源数据集在特定任务的监督设置中进行训练。另一方面,目标数据集中的点在任意区域中被随机屏蔽,目标是估计它们的基数(邻域中的点数)、位置和NOR恶意向量。因此,该模型受益于未标记的数据。
Sun et al.(2023)提出了一种基于掩码的视频再现学习方法,该方法重建轨迹特征而不是静态信息(如帧)。这些目标特征经过精心设计,用于捕获长期运动变化(对象形状和位置)。
Yang et al.(2023)结合了图像-文本交互学习(CLIP)(Radford et al., 2021)和MIM。与结合这两种方法的朴素方法相比,它们的主要贡献在于使用语言空间作为重建目标的目标空间。这是由直觉驱动的,即语言特征充当视觉信号的丰富语义表示。
Bai et al.(2023)介绍了一种使用MAE框架进行知识蒸馏的有效方法。他们的方法重建了被掩盖的补丁,同时训练学生模型复制教师的早期(低级)特征图。效率源于利用MAE框架和对教师网络的部分评估,因为它只需要早期特征图来培训学生。这大大降低了计算成本和训练时间。
Mask3D(Hou et al., 2023)通过将3D先验集成到训练管道中,增强了ViT主干的2D特征表示(Doso vitskiy et al., 2021)。Mask3D在自监督框架内利用RGB-D数据,其中彩色图像和相应的密集深度图都通过双编码器进行屏蔽和处理。这些编码器将数据投影到更高维的空间中,便于解码器准确重建密集的深度图。这种方法丰富了ViT处理空间深度以及传统2D数据的能力。
EVA(Fang et al., 2023)是一种ViT模型,经过训练,可以重建以掩蔽图像标记为条件的CLIP特征。Fang et al.(2023)表明,这种自我监督任务适用于大规模表示学习。EVA模型使用数千万个样本扩展到10亿个参数,展示了其处理大量数据集和复杂学习任务的潜力。
受MIM的启发,任等人(2023年)提出了一种提高ViT性能的新方法。原始图像中的许多补丁被随机排列,并掩盖其位置编码。除了下游任务的原始损失外,还采用了另一个尝试预测掩码位置编码的目标。
GeoMAE(Tian et al., 2023)是MAE框架对点云的改编。这种方法改变了通常的重建目标,取而代之的是质心预测、正态估计和曲率预测。这一变化表明,下游任务(如对象检测、分割和多对象跟踪)有了显著改进。
.Fu et al.(2023)对视频语言预训练的最佳目标特征进行了实证分析。他们发现,使用Swin-B(Liu et al., 2021)变压器提取的空间聚焦图像特征会产生最佳结果。当在ally上进行实验时,加法几乎为零,他们的研究结合了视频语言预训练中采用的常用任务,例如蒙面视频建模、蒙面语言建模和视频文本匹配。
对于他们的视频压缩方法,Xiang等人(2023年)采用了一种基于transformer的熵,该熵使用掩码图像建模进行了预训练。当前帧中的一些标记被随机屏蔽,模型会尝试估计它们的概率质量函数。有关最后解码帧的更多先前信息以键和值的形式提供。在推理时,预测作为迭代过程完成。
3.3 目标函数
MIM的主要目标功能是重建来自输入信号的掩码信息片段。因此,任何在这方面做出贡献的论文,无论是通过改进重建过程还是采取不同的方法,都被归入基于重建的框架类别。受基于重建的技术的启发,最近出现了另一种方法,它应用了对比目标函数。此外,MIM被集成到在利用分布外未标记数据方面显示出巨大潜力的方法中(Yu等人,2022年;Zhang et al., 2024),甚至在使模型适应测试数据分布方面(Gandelsman et al., 2022;Mirza et al., 2023)。
受MAE的启发,Liu et al.(2022)提出了一个类似的3D点云预训练框架,但用判别代替了重建任务。一小部分点未被屏蔽,随后被编码。然后,对蒙面的子集进行采样(真实),以及来自空间的一些随机3D点(假),解码器的目标是区分两者。编码的未掩码点用于解码器的交叉注意力块。对各种下游任务进行了实验,其中该方法显示出相当大的性能改进。
Weers等人(2023年)研究了将MAE和CLIP结合在单个框架中的有效性。结论是,在小型数据集(数千万个样本)上进行训练时,这种组合会带来一些好处,但这种好处较小或当实验在更大的数据集(10亿个样本)上进行时,接近于零。
Mirza等人(2023年)在测试阶段引入了MAE自我监督学习框架的应用,然后使用细化的权重执行预测。该方法在点云分类的背景下进行了评估,展示了在影响3D点云的各种标准扰动中增强的性能。研究结果表明,在测试时使用MAE更新模型权重可以显著提高点云分类任务的鲁棒性和准确性。
Zhao et al.(2023)引入了一个基于掩蔽的辅助目标,用于训练腹腔镜图像的语义分割模型。由于标记数据的稀缺性,作者建议使用标记的代理源数据集(带有模拟图像)和未标记的目标数据集(带有真实图像)来传递知识。前一个数据集用于计算student模型进行分割的监督损失。来自第二个数据集的每张图像都掩盖了其较高的频率(首先应用傅里叶变换,然后应用逆变换),并使用学生模型预测其分割图。将结果输出与教师模型给出的完整图像预测(即学生的指数移动平均线)进行比较,目标是最小化两者之间的距离。
为了提高具有零样本分类能力的模型(如CLIP)的性能,Li et al.(2023)提出了一个由三个任务组成的框架,其中两个基于MIM。除了掩码补丁的重建损失外,另一个目标是最小化掩码标记的结果嵌入与共享投影空间中前置 [CLS] 标记的嵌入之间的差异。
Lee et al.(2023)正式引入了自蒸馏掩码自动编码器框架。输入图像被划分为多个块,其中一些块是随机遮罩的。两个编码器-解码器网络(教师和学生)用于重建原始图像。采用新目标来最小化教师和学生预测之间的距离。当学生使用梯度下降法进行训练时,教师的权重计算为学生权重的指数移动平均值。
Lin和Jabri(2023)在强化学习设置中集成了一个掩蔽的自动编码器模型,以获得爆炸的奖励模型。自动编码器的训练方法是屏蔽轨迹中的某些状态,然后估计它们。给定一个采样轨迹,对于每次tamp,都会保留固定数量的先前状态并对其进行编码。然后,一些生成的嵌入被屏蔽,而其余的则通过解码器传递以预测缺失的状态。最后,勘探奖励由预测误差给出。
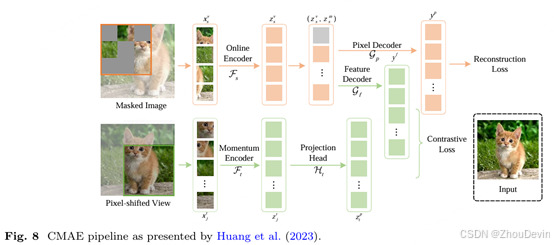
在他们的工作中,Huang et al.(2023)将重建和对比方法合二为一。如图8所示,他们通过使用两个分支来实现这一点,每个策略一个:第一个分支在每一步都更新编码器和像素解码器,而第二个分支使用另一个编码器,该编码器更新为来自另一个编码器的指数移动平均线,以及具有相同输出向量空间的投影层和特征解码器。从输入图像创建两个具有不同a shift的视图,一个通过第一个分支(以及被遮罩),而另一个被馈送到第二个分支(未更改)。第一个分支遵循原始MAE框架,以重建为目标。第二个分支在第二个视图的投影嵌入特征(使用后一个编码器)和第一个视图的解码嵌入特征(即来自前一个编码器)之间应用对比损失。
3.4 下游任务
鉴于MIM的有希望的结果及其减少对少量数据的负面影响的能力,预训练策略被热切地应用于许多视觉任务和相关领域,从图像分类(Zhang et al., 2022;江等人,2023年)和图像生成(Bashkirova等人,2023年;Chang et al., 2022)到3D点云(Shen et al., 2023)、图形(Jing et al., 2022),甚至医疗数据(Bozorgtabar et al., 2023;Chen et al., 2023;Zhou et al., 2023)。
MaskGIT(Chang et al., 2022)训练了一个通用转换器来重建随机掩盖的图像块。在推理时,它首先预测所有补丁,并在其余补丁再次被屏蔽和重新生成时为下一次迭代保留最一致的补丁。该过程将继续进行几次迭代。总体而言,管道实际上有两个阶段,第一个阶段使用VQ编码器将补丁编码为视觉标记,第二个阶段(解码器)接收掩码标记以进行重建。
Feichtenhofer et al.(2022)建议使用MAEonvideos。视频被分割成大小相等的片段,这些片段在任何维度(即包括时间)上都不会重叠,并且仅由两个时间步长组成。正如作者所假设和证明的那样,由于解码时存在冗余数据,因此使用了高掩码率(约占整个输入视频的90%,不知道任何轴)。位置(即高度和宽度)和时间(即时间)嵌入被添加到输入标记中。编码器和解码器的架构都基于ViT。该方法遵循相同的logic作为MAE:仅对可见的token进行编码,然后解码完整的set token。
Gandelsman等人(2022年)将MAE应用于测试时训练。使用权重被冻结的预训练MAE,将由ViT表示的分类头附加到编码器上,并在监督数据集上进行f ined-tune。在推理时,每个样本最初用于分多个步骤训练重建目标的网络工作,从而修改生成的编码潜在表示,而头部不变,然后对输入进行分类。每次预测后,编码器和解码器始终使用其原始权重重置。性能的提高是以牺牲推理速度为代价的。
通过将神经网络架构的搜索公式化为图形,可以训练和评估模型以估计其性能。Jing et al.(2022)应用了一种预训练策略,通过屏蔽顶点,然后重建图形(采用编码器-解码器模型)。然后,对编码器进行微调以预测架构的性能。这导致更高的泛化程度,同时需要的数据也更少。
MAGVIT(Yu et al., 2023)训练了一个基于transformer的模型,用于条件视频生成,处理帧预测、插值和中央外绘等任务。该模型通过选择任务并从预处理的视频创建条件令牌来处理视频。条件令牌与掩码令牌和原始令牌一起构成了用于训练模型的输入,该模型通过三个目标进行了优化:优化条件令牌、预测掩码令牌和重建原始令牌。推理是自回归进行的,逐渐降低掩蔽率。
像素分辨率的掩码自动编码器引导分割(MAESTER)(Xie, et al., 2023)是一种用于细胞图像分离的掩码图像建模方法。MAESTER将掩蔽的自动编码器整合到视觉转换器的训练管道中,以学习与亚细胞结构分割任务(即纹理)相关的标记表示,并通过对学习到的表示进行聚类,在推理时执行分割。
.Chen et al.(2023)使用掩蔽图像建模从fMRI输入中学习潜在空间。在这个阶段之后,作者使用学习到的潜在表征来调节一个扩散模型,该模型能够生成初始视觉刺激的可视化。
Fang et al.(2023)探讨了预先训练的Vision Transformer(ViT)在对象检测环境中对蒙版图像建模任务的有效性。
几何增强掩蔽图像建模(GeoMIM)(Liu et al., 2023)解决了使用多视角相机进行3D检测的问题。此方法涉及通过利用来自多个摄像头的掩码输入来预训练学生网络视图。目标是让学生网络利用基于预先训练的基于LiDAR的模型的指导,μ̂A平均重建重建鸟瞰特征之间的巨大差异。这种策略弥合了多视角摄像头输入和LiDAR精度之间的差距,增强了学生网络准确解释和重建3D环境的能力。
Bozorgtabar等人(2023)利用MAE来检测胸部X光片中的异常。他们管道的第一阶段(如图9所示)包括最初预训练一个蒙面的autoen编码器。然后将分类头连接到编码器(其权重被冻结)以对正常和异常样品进行分类,后者是人工创建的。在第二阶段,使用上一阶段的模型对unla beled数据进行分类,并保留置信度高的示例。最后一步是使用预先训练的自动编码器的两个不同副本,每个类一个,并分别训练它们完成掩码重建任务。在推理时,两个autoen编码器都会生成多个重建,异常预测由两个模块的平均重建图像之间存在很大差异。第二阶段的步骤如图10所示。
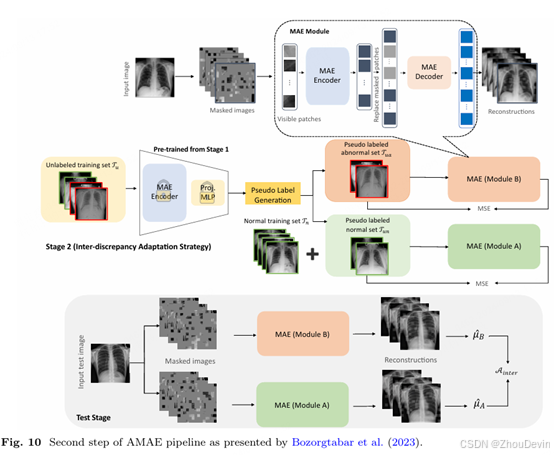
为了提高计算机视觉模型在医疗领域的性能,Xiao et al.(2023)使用视觉转换器对胸部X射线进行多标签分类。通过在掩蔽建模任务上对模型进行预训练,克服了训练ViT所需的大量数据。此外,作者证明了与基于CNN的架构相比,他们的方法具有卓越的性能。
与Xiao等人(2023年)类似,Chen等人(2023年)展示了在3D医学图像上进行遮罩图像建模的好处。他们采用了两个策略(原始MAE和SimMIM)和各种掩码超参数,展示了两种不同分割任务的改进结果。
Zhou et al.(2023)通过使用相关的放射学报告,将掩蔽建模作为医学射线照相任务的预训练策略。当图像的采样率降低一半,并且对未遮罩的色块进行编码时,文本报表被标记化、随机屏蔽,然后通过查找表嵌入。将生成的视觉嵌入的全局平均年龄池添加到未屏蔽的文本嵌入中,并对所有文本进行解码以获得完整的报告。图像令牌也通过另一个解码器馈送,以便以原始分辨率重建X射线照相。
为了在预训练过程中将掩蔽图像建模与对比学习相结合,江et al.(2023)建议将前者应用于初始层,而后者应用于最后一层。这是以迭代方式实现的,首先对重建任务进行预训练,冻结相应的层,然后进行对比任务的训练。
Kraus等人(2023年)采用了显微镜图像的MAE预训练策略。他们的目标是学习数据细胞形态的丰富特征表示。扩展实验证明了预测生物关系的出色结果。
3.5 理论分析
除了应用的贡献外,一些工作还采用了另一种方法:他们对MIM的各个方面进行了理论化,并更深入地研究了其有趣的damentals。该类别的论文涉及整体理解等方面(Kong et al., 2023;Pan et al., 2023)、MIMstrategies之间的联系(Zhang et al., 2022),或目前存在的缺陷以及如何克服它们(Huang et al., 2023;Xie等人,2023年)。
Liu et al.(2022)评估了自我监督学习(SSL)的性能,方法是确定训练后的模型是否代表了足够的信息来获得数据分布,给定有关家庭分布的其他信息。为此评估选择的SSL任务是掩码预测任务。
Li et al.(2023)探讨了MIM对分布外(OOD)检测的有效性。他们的结果表明,MIM在多种设置中提高了性能,例如单类、多类或接近分布的OOD。
Kong et al.(2023)将基础数据生成过程表述为分层潜在可变过程。作者发现了数据生成过程的潜在变量与掩码参数(掩码ratio和patch size)的MAP的MAP和Patch size)。这些关系允许MAE恢复不同语义级别的变量。作者通过几个实验验证了他们的理论发现,其中主要结果表明,非常大的掩码比率与低比率具有相似的效果,即学习低级信息的效果。
Xie et al.(2023)研究了蒙版图像建模的数据缩放能力。他们的实验使用各种大小的数据集,范围从100.000个样本到1400万个样本。作者根据两种掩蔽图像建模方法验证了他们的观察结果,即SimMIM(Xieet al., 2022)和MAE(He et al., 2022)。他们研究的结论指出,MIM仍然需要数据扩展以有效地促进模型扩展。该研究还指出,在非过拟合sce narios中,简单地增加唯一样本的数量并不一定能提高性能。
Xie et al.(2023)探讨了深度模型通过MIM与传统监督训练学习的表征差异。他们观察到,MIM鼓励模型关注所有层的局部模式,而supervised训练仅在初始层强调这些模式。此外,与监督方法相比,MIM导致注意力头之间的多样性更大,这表明模型内的特征识别更加细微。
Pan et al.(2023)对重建掩蔽输入背后的机械原理、这种预训练策略的好处以及为什么它会学习有价值的特征表示进行了理论分析。主要的发现是特征判别是在预训练期间学习的,因此,当应用于下游任务时,这些特征会进一步增强,这比随机初始化的权重有很大的优势。
Moreno-Muñoz等人(2023年)提出了蒙版图像建模的潜在机械原理的贝叶斯理论观点。他们假设掩蔽的预训练,以及隐含的重建误差最小化,可以等同于最大化边际似然,在语言和视觉模型上证明了这一命题。
Huang et al.(2023)研究了用MIM预训练的变压器的对抗鲁棒性。他们的第一个观察结果是,与其他方法相比,MAE的稳健性较低。此外,他们发现稳健性与重建目标有关。对于LSSMCTB块(SSMCTB)进行异常检测。SSMCTB是SSPCAB的扩展,通过示例进行训练,该模型经过训练以再现图像的像素,因此容易受到对抗性攻击,因为它的重点是中高频特征。为了改善这个问题,作者提出了一种基于频域上优化的视觉提示的测试时解决方案。然后,通过基于原型的提示选择将这些提示包含在输入图像中。
此外,他们发现稳健性与重建目标有关。例如,经过训练以再现图像像素的模型容易受到对抗性攻击,因为它的重点是中高频特征。为了改善这个问题,作者提出了一种基于频域上优化的视觉提示的测试时解决方案。然后,通过基于原型的提示选择将这些提示包含在输入图像中。
3.6 模型架构
虽然整个MIM研究采用的架构是一致的(基于transformer的编码器和浅层解码器),但有一些重要的贡献通过架构修改进一步提高了预训练任务的性能(Liu et al., 2023)。一些尝试试图将自己与通常的基于ViT的模型区分开来,要么使用CNN(Tian et al., 2023;Woo等人,2023年)或将MIM集成到卷积运算中(Madan等人,2024年;Ristea et al., 2022)。
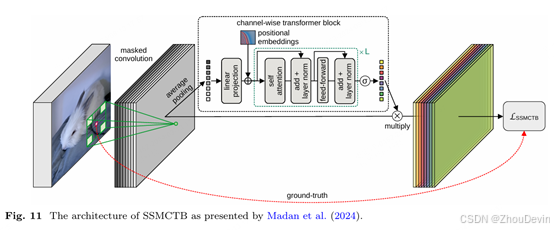
Ristea et al.(2022)提出了自监督预测卷积注意力块(SSPCAB),这是一种由掩蔽卷积层和挤压激励(SE)模块组成的新型块。掩蔽卷积层的滤波器在感受野的角落区域包含可学习的参数,掩蔽区域位于中心。这个新颖的块使用自我监督的重建损失进行训练,并被集成到异常检测网络工作中。后来,Madan等人(2024)引入了自监督掩码卷积转换器block(SSMCTB)进行异常检测。SSMCTB是SSPCAB的扩展,通过自我监督重建损失进行训练,并包含一个掩蔽卷积层。与Ris tea等人(2022年)相比,Madan等人(2024年)采用了通道式变压器模块而不是SE模块,如图11所示。
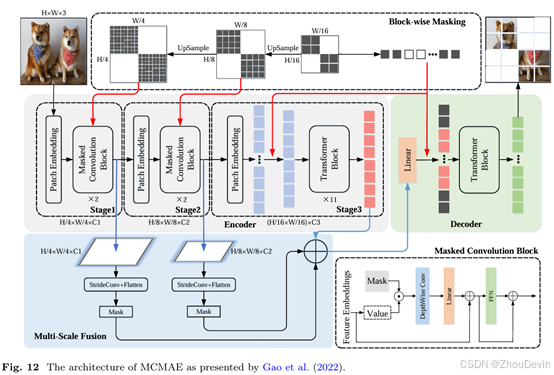
在利用具有卷积层的自动编码器的掩码预训练策略的激励下,Gao等人(2022年)提出了一种将它们结合起来的架构,如图12所示。编码器由三个阶段组成:前两个阶段是卷积阶段,最后一个阶段是基于transformer的阶段。首先,对掩码进行采样以确定哪些标记可见。然后,以前两个阶段的分辨率对掩码进行上采样,以便被掩码卷积块使用。来自前两个阶段的信息被添加到第三个阶段的结果标记中,然后,它们被线性投影。最后,所有标记(预测和掩码)都被解码到原始像素空间中。作者指出,这种方法的优势体现在编码器学习的多尺度特征上。
SparseMAE (zhou et al., 2023) 为小型变压器面临的没有从 MAE 预训练中受益的问题提供了一种新颖的解决方案。它通过同时训练一个全尺寸变压器和一个较小的稀疏网络来实现这一点,该网络驻留在整个变压器内部。这个较小的网络的任务是重建输入图像的遮罩补丁。独特的是,SparseMAE 独立管理两组权重,一组用于稀疏网络,另一组用于包含的较大转换器。尽管存在这种分离,但两个网络都旨在实现相同的目标:准确重建图像的遮罩补丁。经过预训练,只使用稀疏网络进行微调。
受到启发TokenMoE(Riquelmeetal.,2021),Liuetal.(2023)proposed a pre-training方法,该方法对所有下游任务更加健壮。第一步是获取预先训练的MAE的特征表示并对它们进行聚类(获取质心)。该模型的架构适应于包含多个专家(即变压器层中的一组头),每个专家都与一个集群相关联。令牌通过图像分配到的expert进行路由。当应用于downstream任务时,该方法仅选择数据集中最常用的专家进行微调。
在他们的工作中,Tianetal。(2023)采用CNNs进行maskedimagemodeling。AsintheMAE帧工作时,输入在非重叠补丁中被分割,其中一些被屏蔽了。编码器由稀疏卷积层组成,从而沿特征图保持掩码模式完整。用于重建原始图像的解码器由接收前一层的上采样块以及编码器的功能处于同一水平。遮罩区域将替换为遮罩嵌入。Han et al.(2023)提议将RevCol(Caietal.,2023)集成到MAE框架中,除了自下而上的列外,RevCol还扩展到包括自上而下的列,因此类似于编码器-解码器。网络包含可逆连接,帮助模型学习解开的表示。这样,解码器在微调过程中不再被丢弃,因为它包含显着信息
3.7 目标特征和目标函数
几项研究对目标特征和目标函数都有贡献。目标特征的获取方式多种多样,主要是通过使用深度编码器(例如CLIPor DINO)特征(Dongetal.,2023;Wuetal.,2023年)。目标函数修改围绕着整合重建和对比损失。
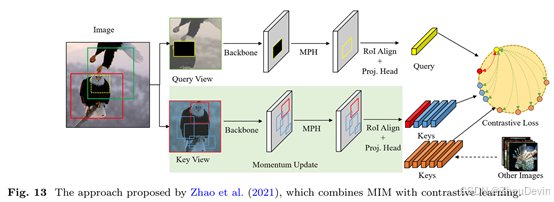
MaskCo(Zhaoetal., 2021)是一个区域级的对比学习框架。它首先增强图像以创建同一图像的两个不同视图,其中一个视图被部分遮罩。然后使用对比学习对模型进行训练,以将蒙版区域的特征与未蒙版视图中相应区域的特征对齐,如图13所示。
.Zhu et al.(2022)提议将附加的掩蔽对比物镜集成到专用于视频游戏的RL管道中。对视频剪辑中的序列进行采样,然后使用基于CNN的网络对每一帧进行编码。然后,除了主RL策略网络之外,还添加了一个辅助分支,该分支采用student和teacher(student的指数移动平均值)框架。前者接收掩码输入特征,而后者则接收完整的潜在表示。目标是最大化两个生成的嵌入之间的相似性。
Wang et al.(2023)表明,在以前的掩蔽图像建模方法中,底层很难学习补丁间关系。为了缓解这个问题,作者引入了LocalMIM。他们通过使用基于本地补丁损失的加权和的损失函数来解决这个问题。他们的管道还包括一个多尺度重建任务,其中模型使用不同的特征描述符进行监督。
MaskCLIP(Dong et al., 2023)将掩蔽图像建模和图像和文本之间的CLIP对比损失结合在一个框架中。与原版CLIP相比,MaskCLIP在重建蒙版图像时有一个额外的损失,并且这两个损失共享相同的视觉编码器。
Huang et al.(2023)提出了一个两阶段的分散框架。在第一阶段,学生网络提取了教师与任务无关的知识,作者选择了MIM作为此目标的代理任务。因此,学生学会将其可见和蒙版的图块表示与教师的图块对齐。在第二阶段,进行经典的面向任务的知识蒸馏。
Kong和Zhang(2023)通过对比学习的视角重新解释了MIM。他们发现了一种公式,表明经典的N’IIN’I方法相当于Siamese网络的设置,其中一个网络重建掩码令牌,而其对应网络则专注于未掩码的令牌。目标是紧密协调这些模型的输出。
为了在医学领域的MIMpre-training期间学习更好的视觉表示,Chen等人(2023年)利用了一种额外的模态(文本)。使用了两种不同的编码器(每种模态一个),但是,文本编码器也被馈送到平均的全局视觉嵌入。他们的方法包括两个重建目标,一个用于图像,一个用于文本,每个目标都有自己的解码器。此外,作者在完全可见的编码文本和所有图像嵌入(掩码和未掩码标记)的解码表示(使用额外的解码器)之间采用了第三个对比目标。
.Wu et al.(2023)提出了一种改进的全玻片图像(WSI)MAE框架。去除背景后,图像被分成块(其中一些被遮罩),对于每个块,使用DINO计算特征向量(Caron等人,2021年)。按照Zheng et al.(2022)的说法,采用了可训练的锚向量,然后用于计算特征和锚向量之间的距离和极角。所有这些仅为可见补丁计算的表示都经过编码,附加掩码标记,最后解码以重建所有WSI表示。编码器和解码器的patch和anchor之间的交叉注意单元是双向的。
Jang et al.(2023)通过优化潜在编码空间,改进了多模态数据的MAE预训练策略。还对未掩蔽的Tokens的一些相邻Token进行采样,以计算重建损失并使用生成的梯度来产生更明确的潜在表示。这进一步用于计算最终的重建损失。此外,采用额外的对比损失来最大化任务的两个结果潜在再现的相似性,同时最小化不同任务的相似性。
3.8 模型架构和目标函数
许多论文对模型架构和目标函数都有贡献。虽然前者是大多数作品的主要焦点,但后者的贡献代表了建筑修改的延伸。
Fei et al.(2023)通过集成对抗训练的鉴别器来增强标准MAE管道。值得注意的是,这个与MAE编码器共享参数的鉴别器经过训练可以区分合成补丁和真实补丁。这种增强是对现有管道的补充,典型的重建损失仍然存在于训练过程中。
Xue et al.(2023)没有遵循MIM中的标准方法进行重建,而是提出了一种独特的损失函数,它将从可见标记中提取的特征与教师模型在不同建筑层次上提取的特征对齐。为了促进这种对齐,本研究引入了一个名为Dynamic Alignment的新模块。此模块经过专门设计,可确保两组功能之间的兼容性,从而实现更有效的功能对齐。
受处理视觉和文本模态的掩码自动编码器的启发,Fuller等人(2023年)为光学和雷达输入调整了掩码预训练框架。两种模态在对齐、标记化和随机屏蔽后,使用单个编码器进行编码,然后由多模态编码器联合处理。对生成的嵌入进行解码以重建两个输入图像。采用各个编码器的平均嵌入之间的对比损失来匹配来自同一时间戳的传感器测量值,同时最大化不同时间戳的测量值之间的差异。
在他们的工作中,Wang等人(2023年)展示了MAE如何提高3D医疗图像分割的性能。输入体积(3D扫描)被分成相等的子体积,这些子体积被随机屏蔽。然后,获得不同的视图(正面、水平或纵向),并进一步应用任意旋转。在预训练期间,除了每个视图的主要重建目标外,还使用了另外三个损失:旋转角度估计、对比损失以及两个不同重建视图之间的额外MSE损失(归一化后)。编码器的架构基于SwinTrans former。一个cross-attention模块,负责两个视图之间的特征,在解码器的第一级之前集成。
在Gong et al.(2023)的工作中,音频频谱图和图像被标记化。未屏蔽的令牌使用单独的编码器进行编码,同时还添加了相应的模态嵌入。然后,通过一个通用编码器执行三个单独的前向传递:每个模态嵌入一个,以及两者的串联。对级联的token以及掩码的token进行解码,并应用重建损失。此外,在每种模态的平均池化编码之间应用对比损失。
Liang et al.(2024)证明,额外的辅助监督分类任务有助于MAEpre训练框架。除了主要的重建损失外,作者还集成了另一个分支,该分支仅将可见编码标记的子集作为输入,对它们应用平均全局池化操作,最后通过多层感知器预测该类。在f ine-tuning部分,使用所有Token。
Pei et al.(2024)的贡献是双重的。首先,他们通过在两个被掩盖相同的连续帧之间应用一致性损失来集成视频的MAE预训练,然后使用两个不同的网络(一个是另一个的指数移动平均值)进行编码和解码。其次,他们提出了一个类似的框架,但使用稀疏卷积层而不是ViT架构,从而降低了计算成本
3.9 掩码策略和目标特征
几项研究影响了掩蔽策略和目标特征。一般来说,这两个贡献是共同提出的,因为改变目标特征涉及对新输入信号的不同屏蔽策略。
Zhao et al.(2023)提出了一种学习对对象跟踪有用的表示的方法。该方法基于MAE,但作者使用两个输入,一个是搜索区域,另一个是模板。MAE经过训练,可以按原样对搜索区域进行侦察结构,并在搜索区域中找到的位置重新创建模板。
Zhang et al.(2023)提出了I2P-MAE,这是一种旨在通过重建掩蔽点云来学习更好的3D特征的方法。该方法利用2D预训练模型在遮罩时保持重要点标记可见。此外,2D模型用于获取应用于解码器之后可见标记的语义重建损失的目标表示。
Lin et al.(2023)将自我监督知识蒸馏和掩蔽图像建模结合到一个框架中。在建议的管道中,教师网络处理来自与student网络相同的类的图像。学生网络处理蒙版图像,并接受训练以最大限度地提高其班级令牌与教师的班级令牌之间的相似性。此外,学生还接受了培训,以提炼教师最相似的标记的知识。
Zhao et al.(2023)的研究将MAE管道集成到用于域自适应对象检测的师生环境中。在这种设置中,学生网络具有双重关注点:它使用教师网络生成的标签来学习检测任务,同时,它对目标图像中缺失的多尺度特征进行侦察结构。这种重建方面至关重要,尤其是在教师提供的伪标签可用性有限的情况下,因为它显著提高了模型对目标领域的适应性,确保更稳健和准确的对象检测性能。
Wei et al.(2023)评估了使用图像生成作为自我监督的预训练任务的有效性,发现当应用于扩散模型框架时,它在下游识别任务中只能产生边际改进。作为对这一观察的回应,作者提出了一种新的策略,将MAE与扩散模型相结合,用于自我监督的预训练,特别关注修复任务。这种方法展示了有竞争力的性能,与图像识别中最先进的方法密切相关,从而为提高训练前的有效性提供了一个引人注目的替代方案。
.Zhang et al.(2023)由于缺乏监督数据,以及训练和测试数据之间的领域差异,在3D分割中使用了掩码重建策略。在训练过程中,给定一对由2D图像和3D点云组成的对,来自一种模态的补丁被屏蔽,模型尝试使用另一种模态来估计它们。采用掩码率较低的CNN主干。有两个不同的ent数据集(源标记和目标未标记),MIM在两个数据集上执行,而监督任务仅在前者上执行。
受MAE框架的启发,Song等人(2023年)提议通过将MIM作为额外的并发任务来提升用于对象跟踪的ViT模型的性能(给定模板图像中的对象,在搜索图像中找到相同的对象)。两个输入图像都是串联的,并通过编码器传递。除了主任务头之外,还使用了另外两个解码器。在屏蔽了大部分嵌入后,两组(每组对应于一张图像)分别通过一个解码器馈送以重建两个帧。另一个解码器仅接收搜索图像的标记嵌入作为输入,并重建模板图像。
Guo et al.(2023)提出了一种利用相应的2D视觉表示来制作3D点云的预训练方法。3D点及其2D投影是联合编码的。生成的编码被随机屏蔽并通过两阶段解码器传递。首先,有一个共享的解码器,然后每个表示继续通过一个单独的模块来重建两种输入模式。
受MAE的启发,Walsh等人(2023年)修改了MAE框架,以便在应用于小镜头场景中的分类下游任务时提高性能。作者建议在冻结主干的潜在表示空间中操作,而不是重建原始像素空间。图像的两个子集,称为首先嵌入support和query,则采用所有输入类型的lat编码器,never’s inter的嵌入被屏蔽。然后,对支持嵌入进行编码,与掩码标记连接,并进行解码以估计相应的查询嵌入,MSE是计算出的重建损失。在使用大型标记数据集进行预训练后,该方法在较小的数据集(每个类包含几个示例)上进一步训练,以便了解有关每个类的全局信息
3.10 掩码策略和模型架构
许多研究都影响了掩蔽策略和采用的架构。架构贡献包括将MIM与不同模型集成或针对特定场景的调整。这些变化导致了必须调整的不同掩码策略。本节中相当多的论文具有多模态输入(Mizrahi et al., 2023;Chen et al., 2023;Lu et al., 2023;Bachmann et al., 2022)。
Huang et al.(2022)介绍了需要在Hierarchical Vision Transformer架构上完成的一系列更改,以便与MAE框架兼容,其中掩码标记在输入序列中被忽略。直接应用时有2个问题,一个是非重叠窗口的窗口注意力,另一个是卷积和池化铺设器。对于第一个问题,作者的解决方案是使用新颖的最优分组算法对来自不均匀窗口的标记进行分组,然后应用掩码注意。对于第二个问题,他们选择使用稀疏卷积。
Woo et al.(2023)实现了卷积网络的MAE框架。其中一项更改是根据编码器的深度特征图创建掩码,并将其大小调整为输入图像的分辨率。第二个变化也是在编码器上,他们使用了稀疏卷积层来保持掩码带来的时间性能提升。
Mizrahi等人(2023年)提出了一种可以与多种模态一起使用的MAE框架。给定一组模态,每个模态都被标记化为通用的表示形式。不是使用所有标记,而是只对每种模态中的两个子集进行采样:一个是编码的,另一个是被屏蔽然后重建的。采用所有input类型的通用编码器,但是,将模态嵌入添加到标记中。在解码器的交叉注意力层期间,对应于一种模态的嵌入被屏蔽,同时处理来自编码器的所有结果标记。除了在下游任务上恶魔策略的良好结果外,该方法还显示出有前途的跨模态生成能力。
.Lu等人(2023年)结合了两个信息来源(苏木精和伊红以及免疫组织化学染色图像)来检测乳腺癌,采用MAE作为他们方法的基础。两张图像都被分成补丁,其中一些将被随机遮罩,其余的可见补丁通过基于ViT的模型一起馈送。生成的嵌入与可学习的掩码嵌入一起,由两个自我注意模块(每种模态一个特定模块)和一个交叉注意力模块(馈送所有嵌入)进一步进行。最后,两个独立的解码器重建原始图像,每个解码器都接收特定于模态的嵌入以及模态间嵌入。
Li et al.(2023)提出了一种新的视频基础模型两阶段预训练框架。初始阶段的重点是训练模型,以将从蒙版帧中提取的特征与从未蒙版帧上的图像基础模型派生的特征对齐。在随后的阶段,作者引入了文本编码器和跨模态解码器,以进一步训练模型进行视频文本匹配和蒙版语言修改,同时保持第一阶段采用的训练目标。
PiMAE Chen et al.(2023)是一个基于MAE的自监督框架,它学习代表的怨恨,以捕捉点云和图像之间的交互。总体而言,该方法基于每种模式的通常重建目标。然而,与MAE相比,在这种情况下的掩蔽策略旨在成为两种模式之间的互补。在架构变化方面,编码器和解码器在两种模态之间包含一些公共块,但它们也有模态特定的层。
Scale-MAE Reed et al.(2023)介绍了一种适用于比例依赖领域的预训练方法,特别是在这种情况下,他们在遥感数据上进行了测试。该方法类似于MAE框架,但有一些关键点变化。首先,添加到标记嵌入中的位置编码取决于图像中覆盖的Earth区域。其次,作者将解码器更改为使用三阶段架构。第一阶段是基于transformer的block。第二阶段是上采样合成反卷积层。最后一个阶段称为重建阶段,包含用于重建高频和低频特征的Laplacian块。
为了利用来自多种输入数据类型的信息来学习更丰富的特征表示,Bachmann等人(2022年)提议预训练具有多种模态的网络。他们的自我监督方法涉及三种类型的数据:RGB图像、深度和语义分离图。遵循ViT的架构,模态被拆分为补丁并投影到令牌中(每个模态都有单独的层)。然后,来自每种模式的大部分标记被屏蔽。最后,其余的(未屏蔽的)被编码(使用通用编码器),与屏蔽的token连接,然后使用每种类型的单独解码器来重建相应的ing输入。在由交叉注意力层组成的解码器的第一阶段,与相应模态关联的标记作为查询给出,而给出的键和值来自所有标记。对所有三种类型的下游任务进行实验,预训练策略显示出有竞争力的结果。
Seo et al.(2023)为使MAE预训练策略适应他们的情况做出了多项贡献。首先,将ViT架构的线性投影层替换为CNN层;但是,仍会添加Positional、ViewPoint和Timestep Embed Ding。其次,他们对具有多个视点的图像序列进行操作,从而提出了一种新颖的遮罩策略:一方面在每个视频帧中完全遮罩一个视点,另一方面,对完整的帧进行遮罩其潜在特征图。为了方便重建任务,编码器被输入来自不同视点以及相邻帧的标记。这个预训练框架允许作者训练一个用于视觉机器人操作的世界模型。
Madan等人(2024年)引入了一个可学习的掩蔽模块,可促进MAE框架内的课程学习。最初,新模块创建易于重建的掩码,训练目标随着时间的推移而改变,采用对抗性角色,逐步创建更具挑战性的掩码供MAE重建。训练掩码的这种动态调整增强了MAE处理日益复杂的重建任务的能力,从而提高了其学习效率和稳健性。
3.11 掩码策略和目标函数
大量工作为掩码策略和目标函数做出了贡献。这些工作首先采用了一种新颖的掩盖策略,该策略擅长隐藏突出信息(Li et al., 2021;Zhang et al., 2023;Yuan等人,2023年),或调整掩码,给定不同的输入类型(Yu等人,2022年;Wang et al., 2023)。此外,目标函数被改变为更适合恢复原始输入源。
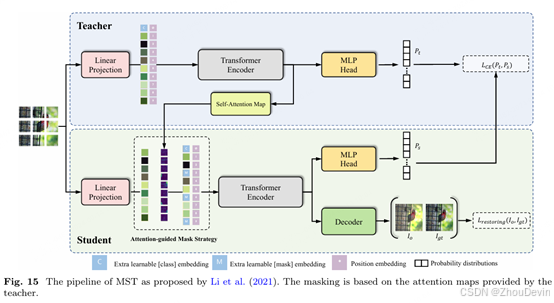
掩蔽的自我监督转换器(MST)(Li et al., 2021)根据来自教师网络的注意力图确定的低响应来选择补丁进行掩蔽,教师网络是学生网络的EMA。这些选定的补丁将替换为特殊标记。MST的训练包括双目标方法:用于重建掩蔽输入的侦察结构损失,以及旨在同步教师和学生网络的交叉熵损失,尤其是在班级区分方面。图15描述了该管道的详细概述。
Yu et al.(2022)提出了一种受BERT启发的方法,从点云数据中预训练变压器。首先,将点划分为子云,并应用PointNet来提取点嵌入。利用得到的嵌入向量,作者训练了一个离散的变分自动编码器(dVAE),其中编码器是一个分词器,将连续的嵌入映射到离散的分词中。在此阶段之后,执行transformer预训练,其中模型接收掩码序列的点嵌入并学习输出离散标记。掩码令牌将替换为可学习令牌。
蒙面场景对比(Wu et al., 2023)是一个利用对比学习的3D表示学习框架。该框架通过一系列数据增强技术生成输入对,并应用完整掩码。然后在未掩蔽和掩蔽补丁的特征之间采用对比学习目标。此外,该框架还纳入了重建损失以提高学习效能。
.Yuan et al.(2023)为人类感知任务量身定制了MIM预训练策略。他们首先检测人体部位并掩盖与这些部位相对应的斑块,目的是从可见的标记中重建被掩盖的标记。除此之外,他们还生成了输入图像的另一个掩码视图(对其他人体部分进行采样),目的是对齐两个视图的全局表示(通过在 [CLS] 标记上应用对比损失)。
Wang et al.(2023)将MAE集成到他们的自监督视频哈希方法中。首先使用CNN对视频剪辑进行下采样,然后为每帧提取一个标记。对两个不同的令牌帧子集进行采样,然后将每个子集输入编码器并进行哈希处理。屏蔽一些哈希嵌入后,使用解码器重建原始帧标记。还使用对比损失来最大化两个子集之间平均哈希嵌入的相似性。
.Zhang et al.(2023)通过对比性预训练框架对师生MIM进行了一些改进。第一个添加是一个排名组件,它将补丁分为两个:包含重要信息的补丁和无意义的补丁。前一个子集传递给学生,而后者传递给教师,两者都被屏蔽并让其余部分可见。第一个目标是重建学生的蒙面补丁,因为它们由于包含更多的上下文信息而更难预测。第二个损失用于通过最大模拟 [CLS] 标记的嵌入之间的相似性来对齐两个子集的全局编码表示。虽然两个模型使用相同的编码器,但梯度不会流经教师。
采用不同的屏蔽SSL方法,Huang等人(2023年)提出了一种方法,其目标是对下游任务更加稳健。在输入图像上,应用了两组不同的增强,并且每个视图都经过编码。然后,投影层将编码的表示转换为多元高斯分布。最后,应用一系列可学习的掩码,并且对于所有掩码,计算两个掩码概率嵌入之间的差异,目的是最小化这种差异。
Yi et al.(2023)提出了一个结合了MIM和对比学习的训练前框架。将不同的增强子集(更激进的子集和较轻的子集)应用于输入图像以创建两个视图,后者掩盖了其部分标记。然后,使用两个vision transformer模型(其中未遮罩图像的模型是另一个模型的EMA)对标记化的补丁进行编码。对比损失仅在相应的损坏补丁之间应用。
Wu et al.(2023)通过向输入图像中的所有像素添加高斯噪声,对MAE模型进行了轻微修改。鉴于此,除了掩蔽区域的重构损失外,目标进一步扩展到解码所有去噪的补丁。实验证明了这种方法优于原始框架
3.12 掩码策略和下游任务
一些研究对掩蔽策略和它们所应用的下游任务都至关重要。这些论文首先将 MIM 应用于新任务,但由于所研究任务的性质不同,掩蔽策略也进行了调整。
Fu et al.(2023)介绍了TVC(文本引导视频完成)任务:模型需要根据帧的子集生成视频,同时尊重一些文本指令。根据帧的子集,该任务需要预测(未来)、倒带(过去)或填充(在两个时刻之间)。作者提出了一种基于掩码帧的训练策略,该策略解决了所有三个可能的TVC子任务。
Zhu和Liu(2023)认为,单独的MIM不足以完成地理指标匹配等下游任务。因此,他们提出了配对MIM,它重建成对的蒙版图像,而不是单个蒙版图像。他们的研究表明,这种预训练任务对于几何匹配更有效,因为此类任务需要两张图像之间的相关性。
LEMaRT(Liu et al., 2023)作为下游任务应用于图像校准时,是一种有效的预训练框架。在这种方法中,被遮罩的补丁被替换为从原始图像的pertured版本中获取的补丁。该研究还调查了创建蒙版的最佳策略是什么,得出的结论是随机蒙版最适合图像协调。
Li et al.(2023)提出了一个代表怨恨学习和图像生成的框架。应用的预训练方法类似于MAE He et al.(2022),但令牌由VQ-GAN分词器给出,掩码率是可变的。
Cai et al.(2023)使用蒙面自动编码器从面部视频中学习丰富、通用、可转移和稳健的面部表征。掩码pri对特定标记(包含眼睛、鼻子、嘴巴和头发的标记)进行修饰。然后在下游任务上测试学习到的表示,例如面部属性识别、面部表情识别、DeepFake检测和嘴唇同步。
Yan等人(2023年)推出的饱和掩模自动编码器(SMAE)是一种用于小镜头HDR成像的两阶段方法。第一阶段侧重于表示学习,这是通过掩蔽图像建模形成的。在此阶段,该方法使用曝光调整从原始帧创建两个额外的图像。接下来,在将这三张图像传递给模型之前,以高遮罩率随机遮罩所有图像。
为了提高WSI分类的性能,Tang et al.(2023)研究了几种掩码策略,以创建一种可用于多实例学习的硬挖掘方法。他们观察到,掩蔽的最佳候选者是突出的补丁。为了在训练过程中识别这种类型的补丁,作者提出了一个管道,其中教师网络提供的注意力分数作为补丁显著性的指标。
Zhai et al.(2023)证明,MAE可以作为一种基于排练的方法用于课堂增量学习。MAE的效率只需要几个补丁,允许存储来自先前任务的更多示例。此外,作者还设计了一个双分支MAE架构,以确保更高质量的重构,其中一个分支负责在图像中插入细节。
Shen et al.(2023)介绍了一种专为点云视频设计的新型自我监督预训练技术,采用了一种涉及遮蔽点管的独特方法。这种方法的重点是训练模型准确地侦察这些蒙蔽的管子的结构。同时,它参与了时间基数不同任务的训练。这种双重训练策略增强了模型理解点云视频中固有的空间结构和时间动态的能力。
磁共振扫描在k空间中生成,然后在图像域中使用逆傅里叶变换进行转换。为了获得高质量和保真度的图像,需要对k-space进行完全采样,但这在大多数情况下是不现实的。为此,Pan等人(2023年)提议利用MAE框架,在沿第一维的k空间(以3D表示:高度、宽度和时间)中屏蔽数据。通过l1损失重新构建缺失的标记,采用的ViT模型学习了丰富的特征表示,能够在推理时估计来自k空间的未采样数据。使用三个基于顺序transformer的解码器(每对维度一个)进一步细化估计的k空间,并在每个解码器之后采用高动态范围损失。
Basu等人(2024)解决了在静态图像中检测胆囊癌的缺点,建议使用视频序列代替。他们采用MAE作为借口任务,但提出了一种改进的掩蔽策略,该策略能够更一致地隐藏恶性区域,从而更好地了解疾病的表现。掩码策略涉及一个区域选择网络,该网络为每个令牌生成一个概率,然后使用该概率对可见令牌进行采样。
3.13 目标特征和下游任务
许多论文在目标下游任务方面取得了重大进展,这也意味着对目标特征的贡献。这些工作大多属于医学领域(Zhang et al., 2024;Cai et al., 2022;Kang等人,2023年),并选择目标特征以更具代表性的输入数据。该类别的其他论文使用视频作为输入信号(Wang et al., 2023)。
Cai et al.(2022)提出了一种使用MIM预训练模型的方法,该方法能够处理2D和3D眼科图像。作者开发了一个名为Unified Patch Embedding的新模块,它由两个分支组成,每个分支对应每种数据类型。该模块将输入分成相等的补丁,然后屏蔽它们的大部分内容。然后,一个通用编码器计算可见patchs的潜在表示。最后,使用了两个解码器:一个用于侦察构造补丁,另一个用于估计其梯度映射(由水平和垂直边缘映射组成)。实验表明,该方法在眼科图像分类中产生了最先进的性能。
MAGVLT(Kim et al., 2023)是一种非自回归的生成视觉语言跨性别者,联合训练用于图像到文本、文本到图像和图像文本到图像。训练目标是3个掩码预测损失,每个任务1个
王等人。(2023)介绍了Masked Video DistiIIation(MVD),一种自监督视频表示学习的新方法,如图16所示。这种方法有两个阶段。第一部分将蒙版图像模型和蒙版视频模型作为教师进行训练。第二部分用老师学到的表示作为目标向量来训练学生。掩蔽也用于后一阶段。
为了提高MAE在超声成像领域的性能增益,Kang等人。(2023)在预训练阶段引入了一项额外任务。由于此类图像中的高信噪比,它们最初是模糊的,因此重建了隐藏的斑块,而可见的斑块则被去模糊。因此,与原始MAE相比,所有补丁都通过编码器。甲状腺超声图像分类下游任务的实验取得了领先的成果。轨迹预测任务严重受到数据分布变化的影响。为此,Park等人。(2024)提出了基于MAE框架的在线训练策略(即测试时间自适应)。除了对先前收集的状态进行回归IOSS之外,所输入输入的重建仅表示一个辅助任务。作者推测,与仅使用初级目标函数相比,该方法有助于更深入地进行有效优化。
由于包含医学扫描的带注释数据集的稀缺性,Zhang等人。(2024)引入了一种新颖的无监督域适应基于MAE的框架。所执行的重建任务应用于由两次体积扫描创建的两个输入信号。本地S11b体积和全局下采样扫描。与MAE不同,作者采用了卷积架构 .最后,当应用于分割下游任务时,该方法使用师生框架:教师(n EMA的学生)生成目标域图像的伪标签分割掩模,然后,使用生成的对以及来自源dornain的样本对学生进行训练。
3.14 模型架构和目标特征
有几篇论文在模型架构和目标特征方面都具有影响力。这些作品提出的修改是紧密耦合的。一方面,提出了目标特征,为了适应它,采用了架构上的改变(Wei et al., 2022;Jiang et al., 2023;Huang et al., 2023)。另一方面,其他工作正在扩展原始框架(Dong et al., 2022;Lao et al., 2023),甚至引入基于MIM的新的预训练框架(Jiang et al., 2022;Yang et al., 2023)。
Dong et al.(2022)对原来的MAE预训练提出了一些修改。他们使用了两种解码器:一种用于图像重建(原始任务),一种用于特征表示估计。后者尝试预测屏蔽补丁的特征表示,来自MAE编码器的EMA副本的基本事实。对于这两个解码器,有关来自编码器的可见补丁的一些信息被注入交叉注意层:前者接收低级上下文,而后者则被赋予高级特征。
.Wei et al.(2022)使用掩蔽区域的HOG特征作为目标值。掩码补丁被可学习的令牌取代,架构基于单个编码器,后跟一个用于预测HOG特征的线性头。
Jiang et al.(2022)介绍了一个复杂的自我监督自我蒸馏预训练框架,展示了它在3D医学图像分割下游任务上的能力。第一步是生成同一3D图像的两个视图,将它们分割成大小相等的补丁,然后对它们进行domly遮罩。使用了两个编码器网络,teacher和student,前者更新为指数移动平均线,后者的momen tum为后者。当学生仅处理一个视图的遮罩补丁时,教师将完全编码相同的未损坏视图,以及另一个视图的遮罩补丁。然后使用三个独立的单线性层从每个嵌入的补丁密集重建图像,估计掩蔽的补丁并生成图像的全局嵌入。因此,计算了三个损失:学生的预测掩码标记与教师编码的相应标记之间的重建损失,全局教师和学生对两个掩码视图的嵌入之间的交叉熵,以及学生预测的视图的重建损失。
掩蔽形状预测(MSP)(Jiang et al., 2023)使用几何形状作为掩蔽点的预测目标。此目标包括显式形状上下文和深层形状特征。此外,MSP的架构修改了交叉注意力和自注意力层,以避免因在令牌嵌入中包含掩蔽部分位置而可能导致的掩蔽形状泄漏。这些修改旨在限制掩膜点之间的交互。
Lao et al.(2023)提出了一种基于掩码自动编码器框架的适用于对象检测的知识提炼技术。学生网络接收到蒙版图像,并学习恢复教师网络提供的缺失的多尺度特征。学生和教师网络基于卷积层。因此,在学生的设计中,作者使用了掩码卷积来避免掩码补丁的变化。
Yang et al.(2023)提出了一个掩码预训练框架,解决了训练和测试数据分布的差异,主要思想是重建来自其他领域的图像。该框架由一个编码器和多个解码器(每个域一个)组成。首先,从输入图像中获取样式混合图像。样式混合图像的补丁被遮罩,可见标记通过编码器和所有解码器传递,以估计所有样式的输入图像。重建损失首先用于与input对应的预测样式。框架的第二阶段涉及获取其他估计的图像,主要屏蔽他们的补丁,然后将它们通过自动编码器(使用输入样式的解码器)来估计输入图像。第二个目标是从所有其他输入重建输入样式。
观察到掩蔽预训练对深度ViT模型的最后一层产生负面影响,Huang等人(2023年)提出了掩蔽图像残差学习(MIRL)。该框架包括沿深度将ViT划分为偶数个阶段。为每个阶段添加一个解码器,该解码器由相应的中间嵌入ding以及掩码标记提供。上半部分的解码器重建了输入图像的主要成分,而其余的解码器则估计残差,即目标和预测之间的差异
3.15 目标函数、下游任务和理论分析
两项研究对目标函数和下游任务有影响,同时也进行了理论分析。这些工作首先对不同的MIM方面进行深入分析,然后提供解决方案以改进它们。
Zhang et al.(2022)揭示了对MAE范式的几个理论见解。最初,它揭示了MAE框架和对比学习原则之间的联系,揭示了MAE中的重建损失与对比学习中发现的对齐损失相似。进一步的探索为MAE模型的下游功效提供了理论保证。对比学习之间的联系也意味着存在特征列失误,这是对比学习中的一个常见挑战,其中仅对齐正样本会降低模型的有效性。研究人员引入了均匀性增强的MAE作为特征折叠问题的解决方案。这种适应修改了损失目标以集成一种新的损失函数,该函数专门用于减少未屏蔽视图之间的特征相似性,从而保持特征多样性并增强模型鲁棒性。
MaskSketch(Bashkirova et al., 2023)是一种使用掩蔽生成转换器从草图生成图像的方法。一般来说,一个被掩蔽的generative transformer通过在连续迭代中接受新token来合成新样本,接受的token是高于某个阈值的token。在这种情况下,作者修改了这个阈值,以取决于素描的自注意力图和正在生成的图像之间计算的差异。因此,主要观察结果是,蒙面跨性别者提供的自我注意力图是域不变的,为草图和自然图像保留了相似的结构。
3.16 掩码策略、模型架构和目标函数
一些工作为掩码策略、模型架构和目标函数的进步做出了贡献。这些论文中有一半引入了一种新的掩蔽策略,并继续在其基础上开发的改进(Bandara等人,2023年;Yu et al., 2023)。另一半是关于最初转换输入数据,然后引入所有修改以将MIM应用于新的输入源(Gupta等人,2023年;Qiu et al., 2024)。
自适应掩码(AdaMAE)(Bandara et al., 2023)提出了一种由附加神经网络执行的MAE自适应掩码策略,该策略为包含时空信息(又名前景)的补丁分配了更大的掩码概率。新的神经网络给出了执行采样的概率向量。因此,它不能用重建损失进行训练。这个问题的解决方案是使用一个基于重建的附加损失函数,其中这些项用自适应网络给出的概率向量进行加权。
Yu et al.(2023)提出了一种专门为带有文本的图像设计的掩码预训练方法。包含文本的随机补丁将被屏蔽,然后通过基于CNN的模型传递以提取特征表示。特征图被tok enized然后馈送到变压器中。遵循特征金字塔网络(FPN)架构(Lin et al., 2017),对生成的嵌入进行上采样,并与来自多个层次的特征图相结合。第一个目标是预先判断掩码单词,而第二个目标是重建损坏的像素(在预测的单词标记的帮助下)。ROI对齐单元用于将特征图与掩蔽区域相关联。
为了对视频的ViT进行预训练,Gupta等人(2023年)提议首先将输入视频转换为VQ-VAE的潜在空间。然后,将每个帧转换为一组标记,并屏蔽整个视频序列中不同高比例的标记。模型的注意力单元被修改,以便每个标记只能访问同一帧中的周围标记,或者访问所有维度(即包括时间)上的标记的一个小的相邻区域。目标是通过最小化其负对数似然来估计掩码标记。
在他们的工作中,Qiu et al.(2024)引入了一个通用框架,以使用transformer学习各种计算机视觉任务。他们将每个任务(例如检测和分割)的输入和输出构建为一个序列,并使用带有双向注意力掩码的编码器解码器变压器。为了捕获任务的丰富上下文,他们通过重建标记序列来采用MAE预训练。
.Wei et al.(2024)分析了以前潜在空间MIM应用的缺点(Yi et al., 2023),展示了传统的重建损失如何限制多样化的潜在学习。为了解决这个问题,作者引入了一个补丁判别目标,以增加预测和相应目标潜在之间的相似性。此外,Wei et al.(2024)通过改变掩蔽策略egy解决了补丁相关性问题。他们使用了高掩码率(90%)、相邻补丁之间的间隙以及可见和目标补丁集的相似性限制。此外,最后一个贡献是改进的解码器架构,适用于潜在表示预测,并结合了自我注意、交叉注意力层和来自可见补丁的视觉提示。
3.17 掩码策略、目标特征和目标函数
几篇对掩码策略、目标特征以及目标功能有影响的论文。对掩蔽策略的贡献是多种多样的:整合新的目标特征(Yu等人,2022年;Li et al., 2022),根据指导改进掩蔽政策(Yao et al., 2023),甚至利用多模式数据(Kwon et al., 2023)。由于采用了特征,这些工作的目标函数被修改了。
在小样本学习的背景下,Yu et al.(2022)使用掩码自动编码器来重建潜在嵌入而不是原始图像。此外,每个实例都充当一个补丁,因此,输入由来自同一类的更多图像组成。对input进行编码后,它的大部分被屏蔽,解码器尝试重建被屏蔽的嵌入表示(给定一些识别变量)。以这种方式,主干网络(即编码器)学习了更多的判别性特征,并且具有更好的小样本性能。
Yao et al.(2023)提议使用MAE重建掩蔽输入图像的正常估计,并将其与原始图像进行比较,以检测异常。模型的预训练遵循原始MAE,仅优化了连续补丁块的掩码策略。由于目的是重建异常区域,因此在推理过程中,采用了建议掩码单元,估计包含异常的图像块的可能位置,以便对其进行掩盖。该单元由一个特征提取模型组成,该模型获取输入图像块和一些原型法线图像的潜在表示(每个法线类中一个示例),以及用于计算似然性的归一化流模型。
Kwon et al.(2023)专注于为视觉和文本数据实施掩码预训练策略。主要思想是屏蔽一种模态并使用另一种输入类型重建缺失的数据。首先,每个模态都使用自己的编码器进行编码,并由其特定的交叉注意力编码器(也与其他模态嵌入一起馈送)进一步处理。最后,使用图像的转换器或文本的线性分类层对掩码标记进行解码。除了重建目标外,还采用了另外两个损失来对齐模态的嵌入。
在他们的工作中,Li et al.(2022)介绍了一种适用于标准卷积神经网络的预训练方法。作者首先从图像中删除补丁,并将它们替换为像素的平均值。与以前的方法不同,与先前擦除的补丁相对应的掩码令牌是在网络的中间铺设器中引入的。除了重建目标之外,还增加了另一个损失,它考虑了原始图像和重建图像的离散傅里叶变换之间的差异。额外损失的作用是在中间级别而不是较低级别增强由于补丁之间的交互而学习的表示。
3.18 掩码策略、模型架构、下游任务和目标函数
许多论文对四个方向做出了贡献,范围很广:掩码策略、模型架构、下游任务和目标函数。第一篇论文涉及整合另一种学习范式(强化学习)(Lezama et al., 2022),而其余论文涉及多模态数据(Huang et al., 2023;Ristea et al., 2024;Georgescu等人,2023年)。
.Lezama et al.(2022)提出了一种Token Critic算法,通过预测需要采样或不采样哪些标记来指导非自回归图像生成模型的合成。为了训练模型,采用了以下过程:标记化图像(通过矢量量化自动编码器)被随机屏蔽。然后,使用基于transformer的泛型模型对其进行重建,而评论家必须区分采样的标记和原始标记。通过这种方式,完全被遮罩的标记化图像逐渐被揭开,使用Token Critic选择要采样的标记,最终生成新的合成图像。
Huang et al.(2023)通过将MIM的所有突出目标集成到一个两阶段框架中,利用MAE对音频-视频模型进行预训练。第一阶段包括重建原始输入,而第二阶段采用师生蒸馏方案,后者的目标是重建前者的预测。教师接收完全可见的输入,而学生则接受蒙面模式。在这两个训练阶段,生成、编码相同模态的两个不同掩码视图,并计算两个对比损失:相同模态的嵌入之间以及跨模态。然后,联合编码器融合两种模态嵌入,最后用单独的解码器进行解码。
Ristea et al.(2024)开发了一种专为视频异常检测量身定制的轻量级MAE。这个MAEmodel利用从运动渐变中得出的权重来强调重建损失中的前景对象。此外,他们通过引入合成异常来增强训练程序,同时使用正常帧作为重建损失的目标。训练的后期阶段涉及学生解码器,它学习模仿主(教师)解码器的输出,进一步完善检测过程。
Georgescu et al.(2023)通过利用视听数据增强了自我监督表示学习。他们在掩蔽的自动编码框架中提出了各种预训练架构和目标,以提高音像下游分类任务的性能。该框架还支持多个单模态下游任务,使用单个视听预训练模型。
4 自动聚类
为了补充手动分类法,我们通过在TF-IDF向量上执行分层聚类算法来生成树状图,该算法是通过连接调查论文的标题和摘要来计算的。我们采用TF-IDF向量来减少停用词的影响,增加内容词的重要性。分层聚类基于Ward关联,旨在最小化总聚类内方差。每个TF-IDF向量都从其自己的单个集群开始。在每个步骤中,合并时导致总聚类内方差增加最小的两个聚类被合并。重复合并过程,直到所有TF-IDF向量都合并成一个簇,从而生成树状图。我们选择了Ward连锁,而不利于其他替代方案,以确保生成的集群更加同质。我们在图17中说明了得到的树状图。通过分析树状图,我们确定了几个相关的集群,如图17所示。
第一个观察到的集群类别与输入数据类型有关:时间数据、3D数据或3D点云、视频、音频,甚至多峰。其他已识别的集群由使用MAE框架的领域或应用于的下游任务表示:医学成像、异常检测、小镜头场景中的图像分类、对象检测和语义分割。聚类算法还能够捕获更复杂的概念:测试时的训练、多视图掩码重建以及域或分布外适应。最值得注意的线索之一可能是由采用基于相对目标的师生MAE框架的论文形成的。另一类由采用扩散模型的方法组成。最后,一个与输入掩码策略相关的集群与我们的手动分类重叠。
与手动分类法相比,我们认为自动生成的聚类为论文提供了独特但同样有用的分类。


















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









