






总体概述:
基于logit值蒸馏的方法
2024年,SDD指出困难样本中存在类间相似情况,提出基于SPP得到21个分块然后对比局部块与全局块的结果差异区分差异化设置loss权重,其效果比Logit Standardization要好;
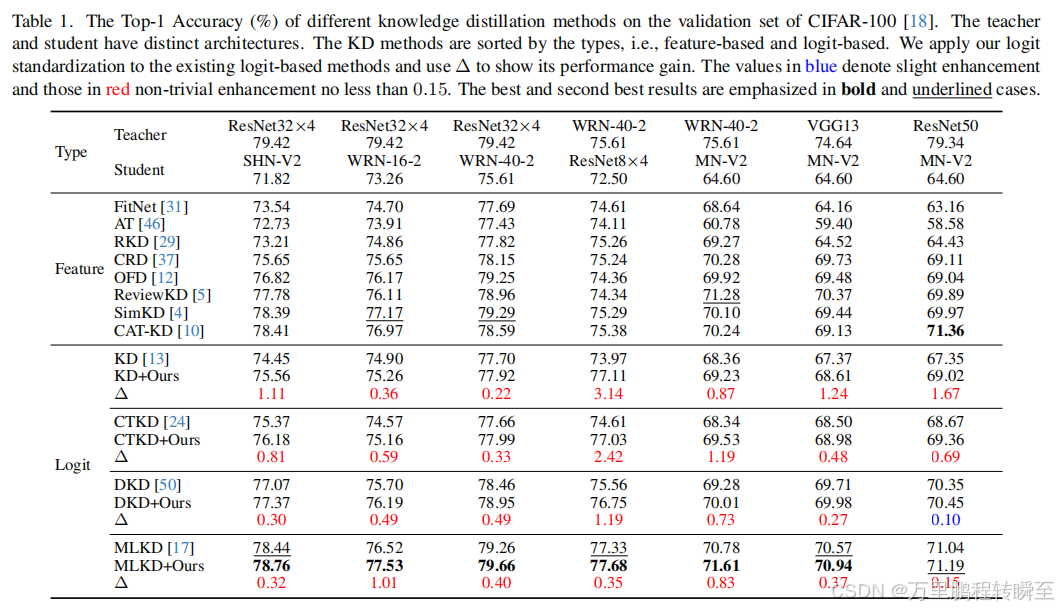
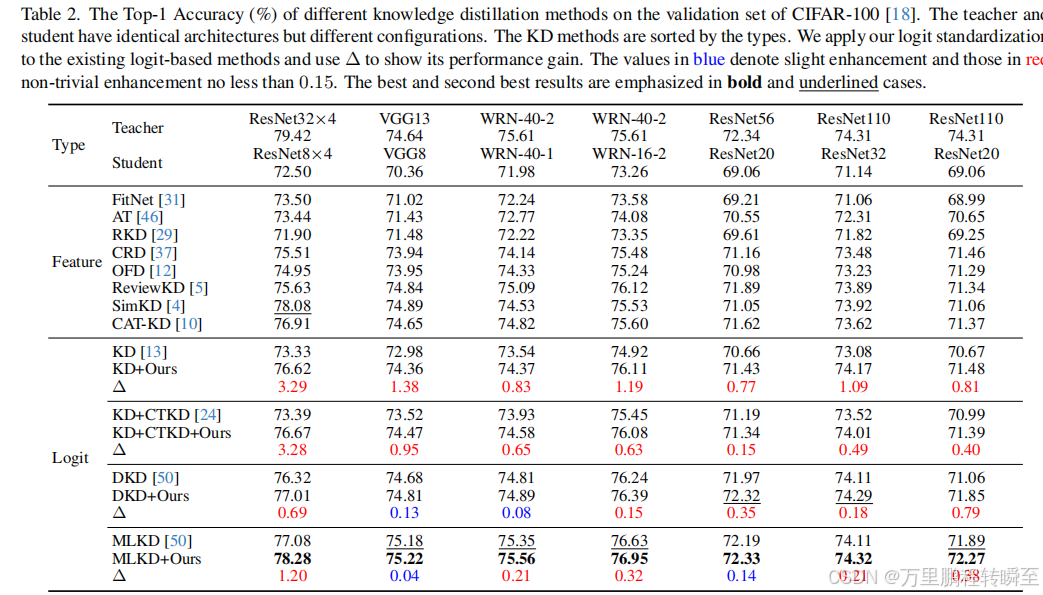
2024年,Logit Standardization提出了直接基于logit值计算KD loss的偏差问题,将标准化添加到KD中,属于对logit值蒸馏方法的改进,并在各种现有的知识蒸馏方法应用Standardization中,取得了有效增益。可以与SDD方法共同补充到各种基于逻辑值的蒸馏方法中。
2023年,OFA-KD 将深度监督的思路应用到了知识蒸馏中不适用于目标检测领域;可以与SDD方法、Logit Standardization方法共同补充到各种基于逻辑值的蒸馏方法中
2022年底,CTKD考虑了知识蒸馏中固定温度值的缺陷,提出一种动态温度的蒸馏方法,属于基于logit值蒸馏的方法;可以与OFA-KD方法、SDD方法、Logit Standardization方法共同补充到各种基于逻辑值的蒸馏方法中
基于feature值蒸馏的方法
2022年,MGD将dropout的操作引入到了KD中,是一种基于feature的蒸馏方法,可以应用到图像分类、目标检测、语义分割,在效果上,MGD>FGD>CWD蒸馏
2022年,FGD指出在目标检测中,教师和学生的特征在不同的领域有很大的差异,特别是在前景和背景上,提出在蒸馏时将前景和背景分开,迫使学生专注于教师的临界像素和通道
2021年,CWD针对在feature中蒸馏时基于mse loss不能使用KL散度来度量差异,提出先将特征图的分布转换为概率分布,然后基于kd散度的理论度量学生特征与教师特征的分布差异
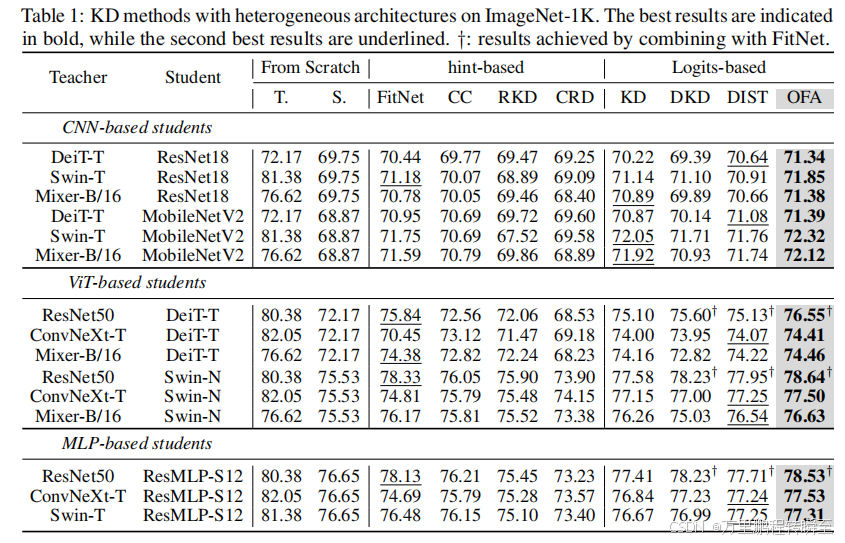
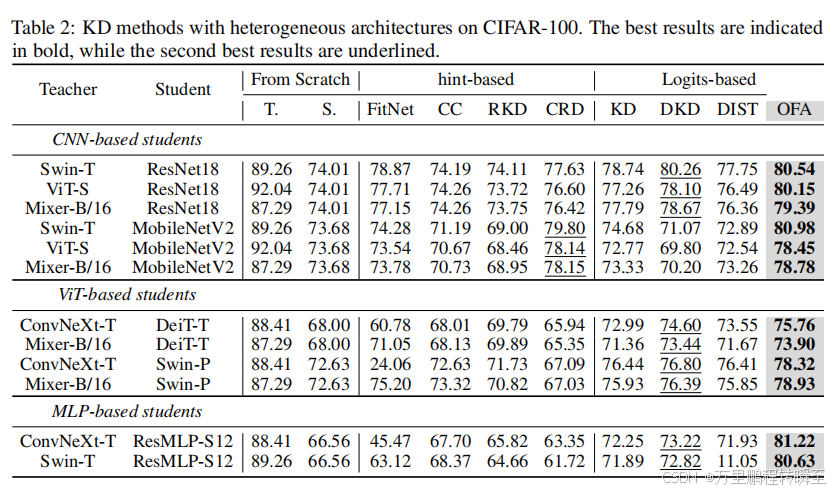
1、One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
论文地址:https://arxiv.org/abs/2310.19444
项目地址:https://github.com/Hao840/OFAKD
发表时间:2023
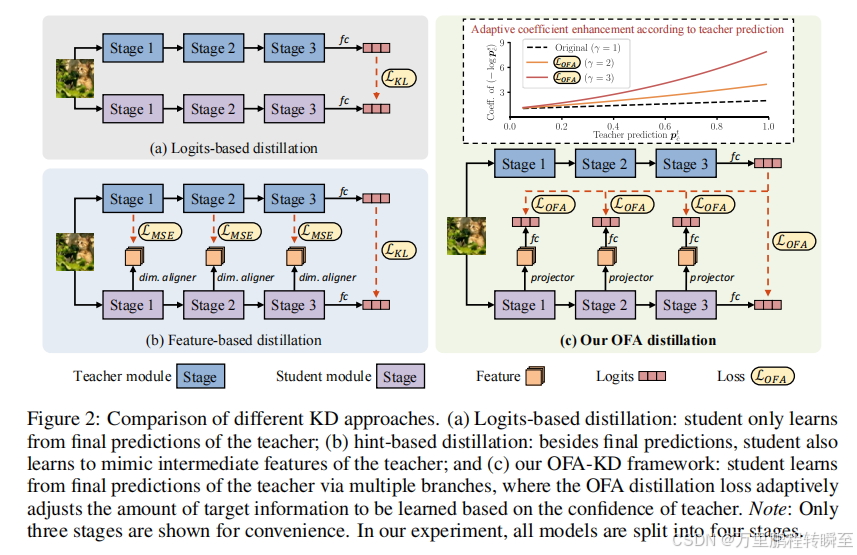
为了解决提取异构模型的挑战,我们提出了一个简单而有效的一对一KD框架,称为OFA-KD,它显著提高了异构体系结构之间的蒸馏性能。具体来说,我们将中间特征投影到一个对齐的潜在空间中,比如概率值空间,其中特定于架构的信息将被丢弃。此外,我们还引入了一种自适应目标增强方案,以防止学生受到不相关信息的干扰。
1.1 算法架构
OFA主要在于特征级的对齐,但区别在于OFA使用教师模型输出的最后一层监督中间多个学生层特征。其本质是将深度监督的概念应用到了知识蒸馏中,每一个中间特征都努力与最终目标对齐。
1.2 实现代码
https://github.com/Hao840/OFAKD/blob/main/distillers/ofa.py
其中有函数ofa_loss,本质就是将交叉熵中的Y_ture替换为为Y_teacher,作者只是将其作用与图像分类任务中,这种设计思路迁移到目标检测中很大概率是无效的,其破坏了多尺度的概念。在语义分割中,深度监督是确认有效的
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.vision_transformer import Block
from ._base import BaseDistiller
from .registry import register_distiller
from .utils import GAP1d, get_module_dict, init_weights, is_cnn_model, PatchMerging, SepConv, set_module_dict, \
TokenFilter, TokenFnContext
def ofa_loss(logits_student, logits_teacher, target_mask, eps, temperature=1.):
pred_student = F.softmax(logits_student / temperature, dim=1)
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
prod = (pred_teacher + target_mask) ** eps
loss = torch.sum(- (prod - target_mask) * torch.log(pred_student), dim=-1)
return loss.mean()
@register_distiller
class OFA(BaseDistiller):
requires_feat = True
def __init__(self, student, teacher, criterion, args, **kwargs):
super(OFA, self).__init__(student, teacher, criterion, args)
if len(self.args.ofa_eps) == 1:
eps = [self.args.ofa_eps[0] for _ in range(len(self.args.ofa_stage) + 1)]
self.args.ofa_eps = eps
assert len(self.args.ofa_stage) + 1 == len(self.args.ofa_eps) # +1 for logits
self.projector = nn.ModuleDict()
is_cnn_student = is_cnn_model(student)
_, feature_dim_t = self.teacher.stage_info(-1)
_, feature_dim_s = self.student.stage_info(-1)
for stage in self.args.ofa_stage:
_, size_s = self.student.stage_info(stage)
if is_cnn_student:
in_chans, _, _ = size_s
if stage != 4:
down_sample_blk_num = 4 - stage
down_sample_blks = []
for i in range(down_sample_blk_num):
if i == down_sample_blk_num - 1:
out_chans = max(feature_dim_s, feature_dim_t)
else:
out_chans = in_chans * 2
down_sample_blks.append(SepConv(in_chans, out_chans))
in_chans *= 2
else:
down_sample_blks = [nn.Conv2d(in_chans, max(feature_dim_s, feature_dim_t), 1, 1, 0)]
projector = nn.Sequential(
*down_sample_blks,
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(max(feature_dim_s, feature_dim_t), args.num_classes) # todo: cifar100
)
else:
patch_num, embed_dim = size_s
token_num = getattr(student, 'num_tokens', 0) # cls tokens
final_patch_grid = 7 # finally there are 49 patches
patch_grid = int(patch_num ** .5)
merge_num = max(int(np.log2(patch_grid / final_patch_grid)), 0)
merger_modules = []
for i in range(merge_num):
if i == 0: # proj to feature_dim_s
merger_modules.append(
PatchMerging(input_resolution=(patch_grid // 2 ** i, patch_grid // 2 ** i),
dim=embed_dim,
out_dim=feature_dim_s,
act_layer=nn.GELU))
else:
merger_modules.append(
PatchMerging(input_resolution=(patch_grid // 2 ** i, patch_grid // 2 ** i),
dim=feature_dim_s,
out_dim=feature_dim_s,
act_layer=nn.GELU if i != merge_num - 1 else nn.Identity))
patch_merger = nn.Sequential(*merger_modules)
blocks = nn.Sequential(
*[Block(dim=feature_dim_s, num_heads=4) for _ in range(max(4 - stage, 1))] # todo: check this
)
if token_num != 0:
get_feature = nn.Sequential(
TokenFilter(token_num, remove_mode=False), # todo: token_num > 1
nn.Flatten()
)
else:
get_feature = GAP1d()
projector = nn.Sequential(
TokenFnContext(token_num, patch_merger),
blocks,
get_feature,
nn.Linear(feature_dim_s, args.num_classes) # todo: cifar100
)
set_module_dict(self.projector, stage, projector)
self.projector.apply(init_weights)
# print(self.projector) # for debug
def forward(self, image, label, *args, **kwargs):
with torch.no_grad():
self.teacher.eval()
logits_teacher = self.teacher(image)
logits_student, feat_student = self.student(image, requires_feat=True)
num_classes = logits_student.size(-1)
if len(label.shape) != 1: # label smoothing
target_mask = F.one_hot(label.argmax(-1), num_classes)
else:
target_mask = F.one_hot(label, num_classes)
ofa_losses = []
for stage, eps in zip(self.args.ofa_stage, self.args.ofa_eps):
idx_s, _ = self.student.stage_info(stage)
feat_s = feat_student[idx_s]
logits_student_head = get_module_dict(self.projector, stage)(feat_s)
ofa_losses.append(
ofa_loss(logits_student_head, logits_teacher, target_mask, eps, self.args.ofa_temperature))
loss_ofa = self.args.ofa_loss_weight * sum(ofa_losses)
loss_gt = self.args.gt_loss_weight * self.criterion(logits_student, label)
loss_kd = self.args.kd_loss_weight * ofa_loss(logits_student, logits_teacher, target_mask,
self.args.ofa_eps[-1], self.args.ofa_temperature)
losses_dict = {
"loss_gt": loss_gt,
"loss_kd": loss_kd,
"loss_ofa": loss_ofa
}
return logits_student, losses_dic
1.3 实现效果
2、Curriculum Temperature for Knowledge Distillation
论文地址:https://arxiv.org/abs/2211.16231
项目地址:https://github.com/zhengli97/CTKD
发表时间:2022年12月24日
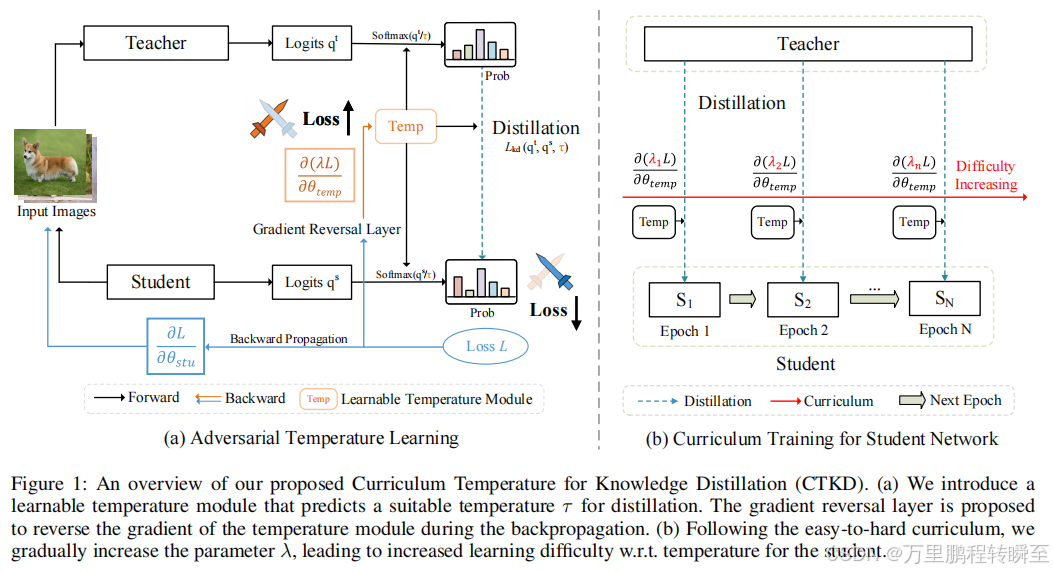
大多数现有的蒸馏方法忽略了温度在损失函数中的灵活作用,并将其固定为一个可以由低效的网格搜索来决定的超参数。一般来说,温度控制着两个分布之间的差异,并可以忠实地确定蒸馏任务的难度水平。保持一个恒定的温度,即一个固定的任务难度水平,对于一个成长中的学生在其渐进式学习阶段通常是不理想的。在本文中,我们提出了一种简单的基于课程的技术,称为知识提炼课程温度(CTKD),它通过一个动态和可学习的温度来控制学生学习生涯中的任务难度水平。具体来说,遵循简单困难的课程,我们逐渐增加蒸馏损失温度升高,使蒸馏难度增加。
如下图所示,不同的模型间蒸馏需要不同的温度值,基于CTKD方式蒸馏的模型可以动态接近最佳温度值。
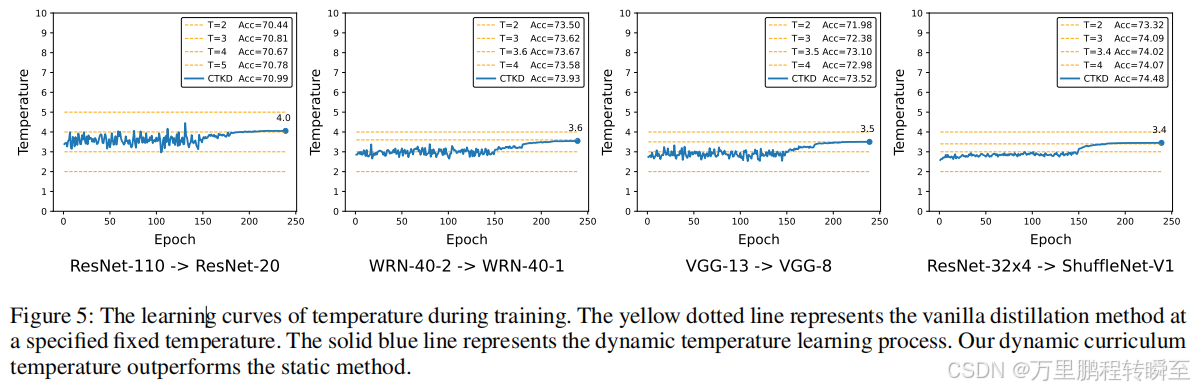
2.1 算法架构
算法的核心在于对温度值的动态调整,针对一个batch中的不同数据,有不同的温度值,以区分对难样本、易样本蒸馏的温度差异。CTKD对基于logit值蒸馏引发的温度值概率进行深入拓展,对于温度值进行动态调整,从而突破原有蒸馏方法的精度上限
具体可以阅读 https://blog.csdn.net/qq_40206371/article/details/129542762 ,了解CTKD的细节。



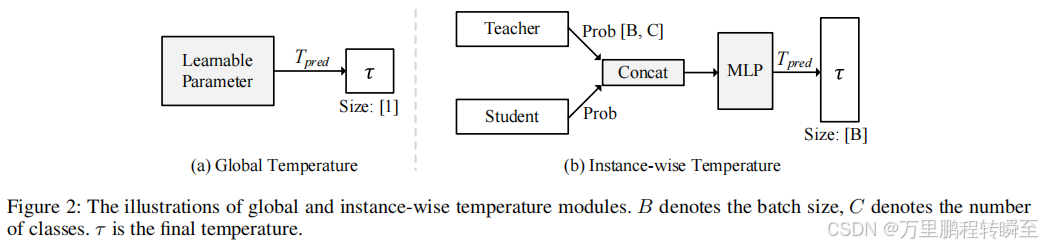
2.2 实现代码
https://github.com/zhengli97/CTKD/blob/master/crd/memory.py
https://github.com/zhengli97/CTKD/blob/master/crd/criterion.py
实现代码嵌套关系比较复杂,暂时难易理解ContrastMemory的实现方式
import torch
from torch import nn
from .memory import ContrastMemory
eps = 1e-7
class CRDLoss(nn.Module):
"""CRD Loss function
includes two symmetric parts:
(a) using teacher as anchor, choose positive and negatives over the student side
(b) using student as anchor, choose positive and negatives over the teacher side
Args:
opt.s_dim: the dimension of student's feature
opt.t_dim: the dimension of teacher's feature
opt.feat_dim: the dimension of the projection space
opt.nce_k: number of negatives paired with each positive
opt.nce_t: the temperature
opt.nce_m: the momentum for updating the memory buffer
opt.n_data: the number of samples in the training set, therefor the memory buffer is: opt.n_data x opt.feat_dim
"""
def __init__(self, opt):
super(CRDLoss, self).__init__()
self.embed_s = Embed(opt.s_dim, opt.feat_dim)
self.embed_t = Embed(opt.t_dim, opt.feat_dim)
self.contrast = ContrastMemory(opt.feat_dim, opt.n_data, opt.nce_k, opt.nce_t, opt.nce_m)
self.criterion_t = ContrastLoss(opt.n_data)
self.criterion_s = ContrastLoss(opt.n_data)
def forward(self, f_s, f_t, idx, contrast_idx=None):
"""
Args:
f_s: the feature of student network, size [batch_size, s_dim]
f_t: the feature of teacher network, size [batch_size, t_dim]
idx: the indices of these positive samples in the dataset, size [batch_size]
contrast_idx: the indices of negative samples, size [batch_size, nce_k]
Returns:
The contrastive loss
"""
f_s = self.embed_s(f_s)
f_t = self.embed_t(f_t)
out_s, out_t = self.contrast(f_s, f_t, idx, contrast_idx)
s_loss = self.criterion_s(out_s)
t_loss = self.criterion_t(out_t)
loss = s_loss + t_loss
return loss
class ContrastLoss(nn.Module):
"""
contrastive loss, corresponding to Eq (18)
"""
def __init__(self, n_data):
super(ContrastLoss, self).__init__()
self.n_data = n_data
def forward(self, x):
bsz = x.shape[0]
m = x.size(1) - 1
# noise distribution
Pn = 1 / float(self.n_data)
# loss for positive pair
P_pos = x.select(1, 0)
log_D1 = torch.div(P_pos, P_pos.add(m * Pn + eps)).log_()
# loss for K negative pair
P_neg = x.narrow(1, 1, m)
log_D0 = torch.div(P_neg.clone().fill_(m * Pn), P_neg.add(m * Pn + eps)).log_()
loss = - (log_D1.sum(0) + log_D0.view(-1, 1).sum(0)) / bsz
return loss
2.3 实现效果
动态温度进行的知识蒸馏,loss值大一些
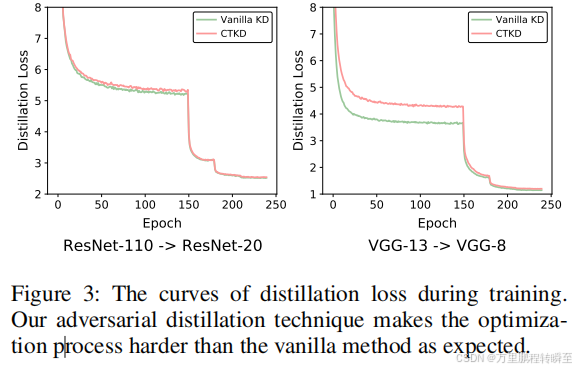
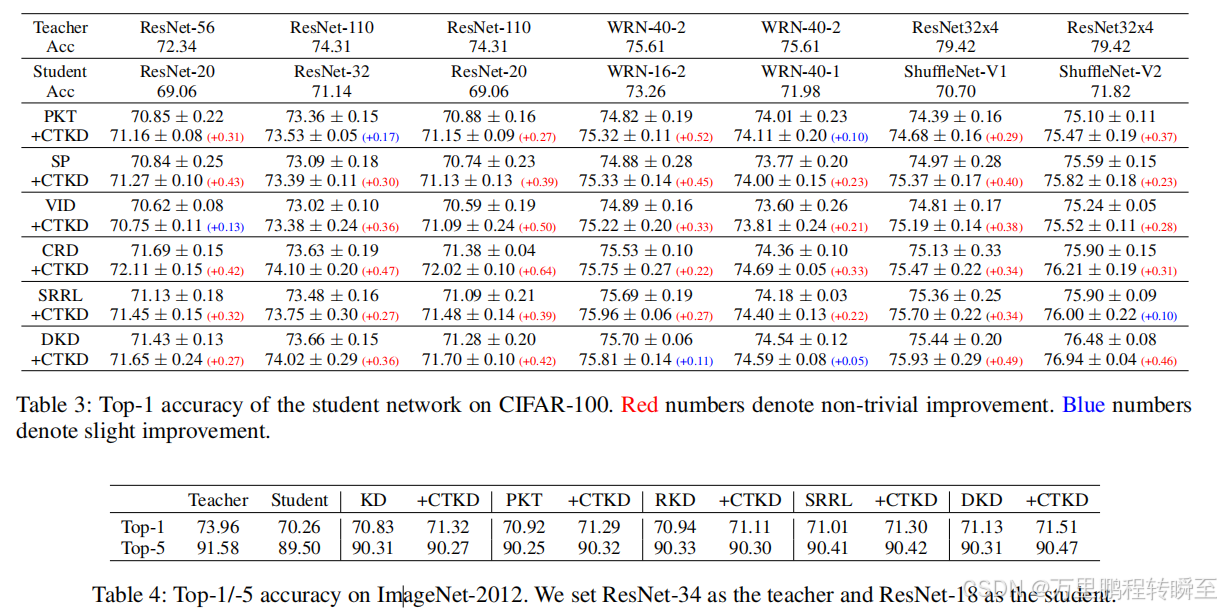
作为一种易于使用的插件技术,CTKD可以无缝地集成到现有的蒸馏工作中。如表3所示,CTKD六种最先进的方法进行了全面的改进。更重要的是,CTKD不会给这些方法产生额外的计算成本,因为它只包含一个轻量级的可学习的温度模块和一个非参数化的GRL。
3、Logit Standardization in Knowledge Distillation
论文地址:https://arxiv.org/abs/2403.01427
项目地址:https://github.com/sunshangquan/logit-standardization-KD
论文解读:https://zhuanlan.zhihu.com/p/688903391
发表时间:2024
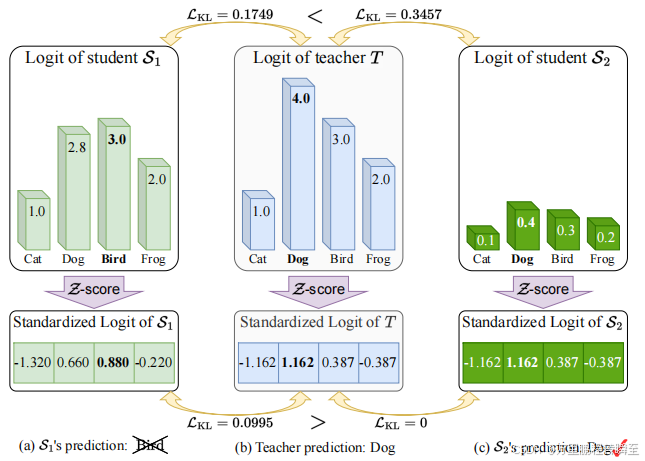
传统知识蒸馏默认学生/教师网络的温度是全局一致的,这种设置迫使学生模仿教师的logit的具体值,而非其关系,论文方法提出logit标准化,解决了这个问题。
3.1 算法架构
算法原理
两个学生,S1和S2,以相同的温度从同一位老师那里学习(为了简单起见,假设为1)。学生S1生成的对数在大小上更接近老师的数,因此损失更低,为0.1749,但它返回了一个错误的预测“鸟”。相比之下,学生S2输出的对数远离老师的对数,产生更大的损失值0.3457,但它返回了“狗”的正确预测。在提出的logit标准化之后,就解决了这个问题。
基于logit值计算的loss,不能正确的引导学生模型接近教师模型的分布,只会强制拉近教师模型与学生模型值的差异。但是在分类任务中,只需要分布一致即可。归一化后计算的KD loss更接近真实情况,当分布相同时,loss值小,分布差异大时loss值大
本质是对loss的引导进行纠正,避免了个别情况下,学生模型学习到位,但loss值大,学生模型学偏了而loss值小的情况
3.2 实现代码
这里只列出标准化在KD loss上的实现代码
https://github.com/sunshangquan/logit-standardization-KD/blob/master/mdistiller/distillers/KD.py
可以发现与原版相比,只是调用了normalize函数,对学生输出与教师输出进行调整。同时基于logit_stand 参数控制对比实验。
import torch
import torch.nn as nn
import torch.nn.functional as F
from ._base import Distiller
def normalize(logit):
mean = logit.mean(dim=-1, keepdims=True)
stdv = logit.std(dim=-1, keepdims=True)
return (logit - mean) / (1e-7 + stdv)
def kd_loss(logits_student_in, logits_teacher_in, temperature, logit_stand):
logits_student = normalize(logits_student_in) if logit_stand else logits_student_in
logits_teacher = normalize(logits_teacher_in) if logit_stand else logits_teacher_in
log_pred_student = F.log_softmax(logits_student / temperature, dim=1)
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
loss_kd = F.kl_div(log_pred_student, pred_teacher, reduction="none").sum(1).mean()
loss_kd *= temperature**2
return loss_kd
class KD(Distiller):
"""Distilling the Knowledge in a Neural Network"""
def __init__(self, student, teacher, cfg):
super(KD, self).__init__(student, teacher)
self.temperature = cfg.KD.TEMPERATURE
self.ce_loss_weight = cfg.KD.LOSS.CE_WEIGHT
self.kd_loss_weight = cfg.KD.LOSS.KD_WEIGHT
self.logit_stand = cfg.EXPERIMENT.LOGIT_STAND
def forward_train(self, image, target, **kwargs):
logits_student, _ = self.student(image)
with torch.no_grad():
logits_teacher, _ = self.teacher(image)
# losses
loss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)
loss_kd = self.kd_loss_weight * kd_loss(
logits_student, logits_teacher, self.temperature, self.logit_stand
)
losses_dict = {
"loss_ce": loss_ce,
"loss_kd": loss_kd,
}
return logits_student, losses_dict
3.3 实现效果
可以看到针对于logit的蒸馏,标准化后再计算蒸馏loss,均可以获得一定的精度提升。但这里表明基于logit的蒸馏方法,精度提升不如基于feature蒸馏方法有效。
4、Scale Decoupled Distillation
论文地址:https://arxiv.org/abs/2403.13512
项目地址:https://github.com/shicaiwei123/SDD-CVPR2024
论文解读:https://zhuanlan.zhihu.com/p/685905353
发表时间:2024
现有的基于logit的方法可能是次优的,因为它们只利用了耦合多个语义知识的全局logit输出。这可能会将模糊的知识转移给学生,并误导学生的学习。SDD将全局logit输出解耦为多个局部logit输出,并为它们建立蒸馏管道。这有助于学生挖掘和继承精细和明确的logit知识。此外,解耦的知识可以进一步分为一致的和互补的logit知识,分别传递语义信息和样本歧义(对比局部特征预测结果与全局特征预测结果差异)。通过增加互补部分的权重,SDD可以引导学生更多地关注模糊样本,提高其辨别能力。
4.1 算法架构
不用全局的logit output,而是用这些局部区域对应的特征计算得到的logit output。局部信息通常会包含更多细节,同时几乎不会在一个局部区域耦合多个类别的信息,所以通过获取多个局部区域的logit output来进行知识蒸馏,就可以unambiguous的信息传递给student。所以,很自然的Scale Decoupling的思想就出来了。
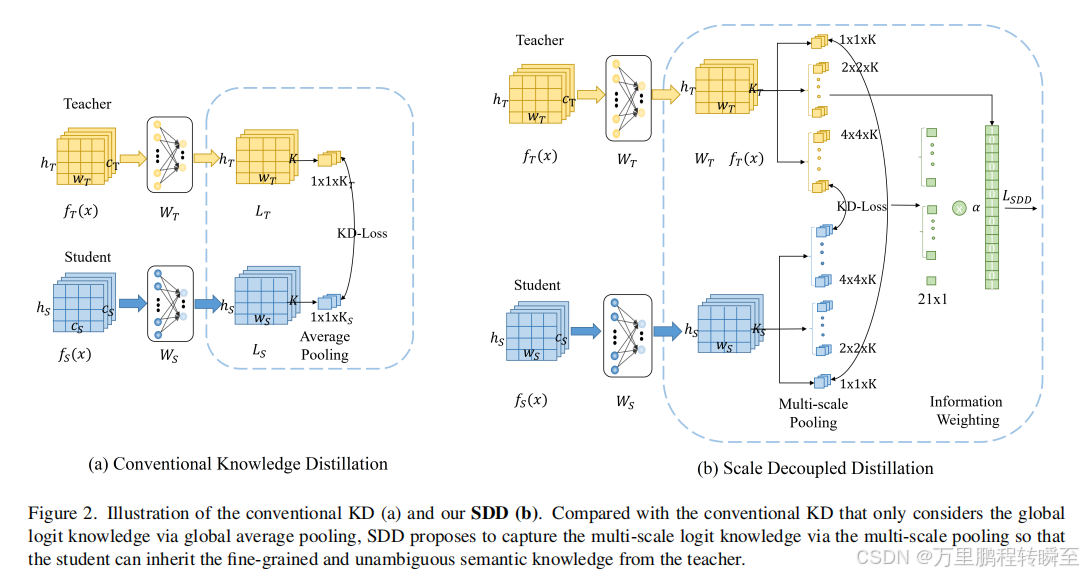
4x4xk为4x4池化,可以得到16个特征图,然后基于共用的预测头,可以得到16个预测结果,基于SSP可以得到21个预测结果。对比局部预测结果与全局预测结果的差异,当存在global是对的,local是错的,说明这个样本有模糊性,保留样本模糊性,避免student对这类样本的过拟合。
模糊样本案例

作者可视化了ImageNet中class 6 (stingray) 的所有的测试样本 在预训练的ResNet34在的预测结果。如左图所示,绝大部分是正确的,但是会有一些错误的结果。错误最多的是class 5,它对应的numbfish,和stingray都属于fish,右边的图也可以看出,二者外形是非常相似的。 其次还有类似于一些右图第二列的错误样本,因为包含了潜水员,被错误分类成了第983类的scuba diver。
这些现象引导我们思考一个,如何在logit distillation中让学生获取更加 accurate 而不是ambiguous的知识。不仅仅是teacher能够准确分类的样本,即使是teacher不能准确分类的样本,student 能否也能获得一些有益的信息。于是,我们提出了我们的Scaled Decoupled Distillation。
4.2 实现代码
https://github.com/shicaiwei123/SDD-CVPR2024/blob/main/mdistiller/distillers/KD.py
可以发现基于sdd_kd_loss计算loss时,需要真实标签选择局部模块的输出(SPP后得到的多个特征图的输出)。其根据类别进一步将解耦的logit输出划分为一致和互补的项。
global和local的预测是一致的情况,local knowledge可以看做是global knowledge的多尺度补充。
预测不一致的时候:
一方面global是错的,local是对的,可以传递正确的知识,另一方面,global是对的,local是错的,说明这个样本有模糊性,错误的预测传递给student,保留样本模糊性,避免student对这类样本的过拟合。
def sdd_kd_loss(out_s_multi, out_t_multi, T, target):
###############################shape convert######################
# from B X C X N to N*B X C. Here N is the number of decoupled region
#####################
out_s_multi = out_s_multi.permute(2, 0, 1)
out_t_multi = out_t_multi.permute(2, 0, 1)
out_t = torch.reshape(out_t_multi, (out_t_multi.shape[0] * out_t_multi.shape[1], out_t_multi.shape[2]))
out_s = torch.reshape(out_s_multi, (out_s_multi.shape[0] * out_s_multi.shape[1], out_s_multi.shape[2]))
target_r = target.repeat(out_t_multi.shape[0])
####################### calculat distillation loss##########################
p_s = F.log_softmax(out_s / T, dim=1)
p_t = F.softmax(out_t / T, dim=1)
loss_kd = F.kl_div(p_s, p_t, reduction='none') * (T ** 2)
nan_index = torch.isnan(loss_kd)
loss_kd[nan_index] = torch.tensor(0.0).cuda()
# only conduct average or sum in the dim of calss and skip the dim of batch
loss_kd = torch.sum(loss_kd, dim=1)
######################find the complementary and consistent local distillation loss#############################
out_t_predict = torch.argmax(out_t, dim=1)
mask_true = out_t_predict == target_r
mask_false = out_t_predict != target_r
# global_prediction = out_t_predict[len(target_r) - len(target):len(target_r)]
global_prediction = out_t_predict[0:len(target)]
global_prediction_true_mask = global_prediction == target
global_prediction_false_mask = global_prediction != target
global_prediction_true_mask_repeat = torch.tensor(global_prediction_true_mask).repeat(out_t_multi.shape[0])
global_prediction_false_mask_repeat = torch.tensor(global_prediction_false_mask).repeat(out_t_multi.shape[0])
# global true local worng
mask_false[global_prediction_false_mask_repeat] = False
mask_false[0:len(target)] = False
gt_lw = mask_false
# global wrong local true
mask_true[global_prediction_true_mask_repeat] = False
# mask_true[len(target_r) - len(target):len(target_r)] = False
mask_true[0:len(target)] = False
gw_lt = mask_true
mask_false = out_t_predict != target_r
mask_true = out_t_predict == target_r
index = torch.zeros_like(loss_kd).float()
# regurilize for similar
# global wrong local wrong
mask_false[global_prediction_true_mask_repeat] = False
gw_lw = mask_false
mask_true[global_prediction_false_mask_repeat] = False
gt_lt = mask_true
# print(torch.sum(gt_lt) + torch.sum(gw_lw) + torch.sum(gt_lw) + torch.sum(gw_lt))
########################################Modify the weight of complementary terms#######################
index[gw_lw] = 1.0
index[gt_lt] = 1.0
index[gw_lt] = 2
index[gt_lw] = 2
loss = torch.sum(loss_kd * index) / target_r.shape[0]
if torch.isnan(loss) or torch.isinf(loss):
print("inf")
loss = torch.zeros(1).float().cuda()
return loss
class SDD_KD(Distiller):
def __init__(self, student, teacher, cfg):
super(SDD_KD, self).__init__(student, teacher)
self.temperature = cfg.KD.TEMPERATURE
self.ce_loss_weight = cfg.KD.LOSS.CE_WEIGHT
self.kd_loss_weight = cfg.KD.LOSS.KD_WEIGHT
self.warmup = cfg.warmup
self.M=cfg.M
def forward_train(self, image, target, **kwargs):
logits_student, patch_s = self.student(image)
with torch.no_grad():
logits_teacher, patch_t = self.teacher(image)
# losses
# *min(kwargs["epoch"] / self.warmup, 1.0)
loss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)
if self.M == '[1]':
# print("M1111111111")
print(logits_student.shape,logits_teacher.shape)
loss_kd =self.kd_loss_weight * kd_loss(
logits_student,
logits_teacher,
self.temperature,
)
else:
loss_kd = self.kd_loss_weight * sdd_kd_loss(
patch_s, patch_t, self.temperature, target
)
losses_dict = {
"loss_ce": loss_ce,
"loss_kd": loss_kd,
}
return logits_student, losses_dict
SDD_KD依赖的patch_t是由SPP模块输出的,SSP的输出与最终的输出共用同一个linear 层实现类别预测。
class ResNet_SDD(nn.Module):
def __init__(self, block, num_blocks, num_classes=10, zero_init_residual=False,M=None):
super(ResNet_SDD, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
self.stage_channels = [256, 512, 1024, 2048]
self.spp = SPP(M=M)
self.class_num = num_classes
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
f0 = out
out, f1_pre = self.layer1(out)
f1 = out
out, f2_pre = self.layer2(out)
f2 = out
out, f3_pre = self.layer3(out)
f3 = out
out, f4_pre = self.layer4(out)
f4 = out
x_spp,x_strength = self.spp(out)
# feature_num = x_spp.shape[-1]
# patch_score = torch.zeros(x_spp.shape[0], self.class_num, feature_num)
# patch_strength = torch.zeros(x_spp.shape[0], feature_num)
x_spp = x_spp.permute((2, 0, 1))
m, b, c = x_spp.shape[0], x_spp.shape[1], x_spp.shape[2]
x_spp = torch.reshape(x_spp, (m * b, c))
patch_score = self.linear(x_spp)
patch_score = torch.reshape(patch_score, (m, b, self.class_num))
patch_score = patch_score.permute((1, 2, 0))
out = self.avgpool(out)
avg = out.reshape(out.size(0), -1)
out = self.linear(avg)
feats = {}
feats["feats"] = [f0, f1, f2, f3, f4]
feats["preact_feats"] = [f0, f1_pre, f2_pre, f3_pre, f4_pre]
feats["pooled_feat"] = avg
return out, patch_score
SSP的实现代码如下所示
import torch.nn as nn
import torch
class SPP(nn.Module):
def __init__(self, M=None):
super(SPP, self).__init__()
self.pooling_4x4 = nn.AdaptiveAvgPool2d((4, 4))
self.pooling_2x2 = nn.AdaptiveAvgPool2d((2, 2))
self.pooling_1x1 = nn.AdaptiveAvgPool2d((1, 1))
self.M = M
print(self.M)
def forward(self, x):
x_4x4 = self.pooling_4x4(x)
x_2x2 = self.pooling_2x2(x_4x4)
x_1x1 = self.pooling_1x1(x_4x4)
x_4x4_flatten = torch.flatten(x_4x4, start_dim=2, end_dim=3) # B X C X feature_num
x_2x2_flatten = torch.flatten(x_2x2, start_dim=2, end_dim=3)
x_1x1_flatten = torch.flatten(x_1x1, start_dim=2, end_dim=3)
if self.M == '[1,2,4]':
x_feature = torch.cat((x_1x1_flatten, x_2x2_flatten, x_4x4_flatten), dim=2)
elif self.M == '[1,2]':
x_feature = torch.cat((x_1x1_flatten, x_2x2_flatten), dim=2)
elif self.M=='[1]':
x_feature = x_1x1_flatten
else:
raise NotImplementedError('ERROR M')
x_strength = x_feature.permute((2, 0, 1))
x_strength = torch.mean(x_strength, dim=2)
return x_feature, x_strength
4.3 实现效果
可以发现SD蒸馏方式作用到各种基于Logit值的蒸馏方法中均取得了增益。以ResNet50蒸馏MobileNetV2为锚点对比,可以发现其增益比Logit Standard方法更加有效,且2中蒸馏方法互补。
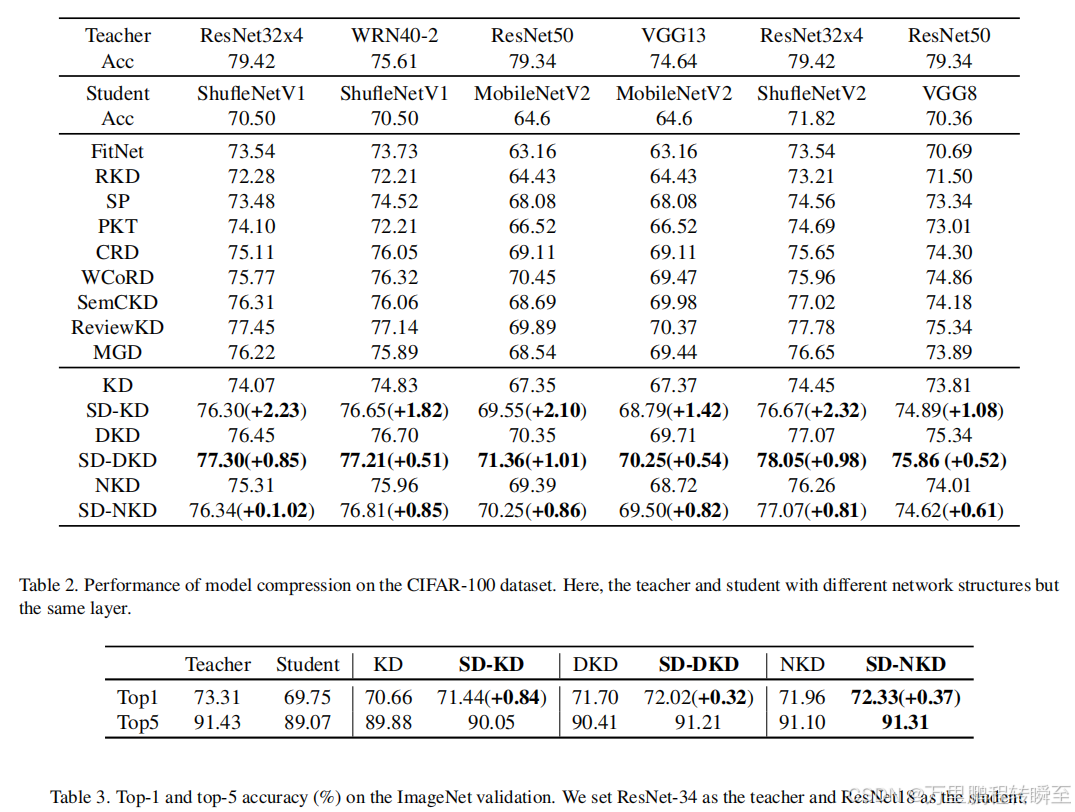
5、Masked Generative Distillation
论文地址:https://arxiv.org/abs/2205.01529
项目地址:https://github.com/yzd-v/MGD
发表时间:2022
MGD随机掩蔽学生特征的像素,并通过一个简单的conv+relu+conv结构,强迫它生成教师的完整特征。MGD是一种真正通用的基于特征的蒸馏方法,可用于图像分类、目标检测、语义分割和实例分割等各种任务。
5.1 算法架构
MGD蒸馏的流程图如下所示,先对特征图进行随机mask,然后映射到教师通道上进行蒸馏。其本质就是将dropout思路进行了变通(只是少了丢弃后,值域的缩放),应用到了知识蒸馏中
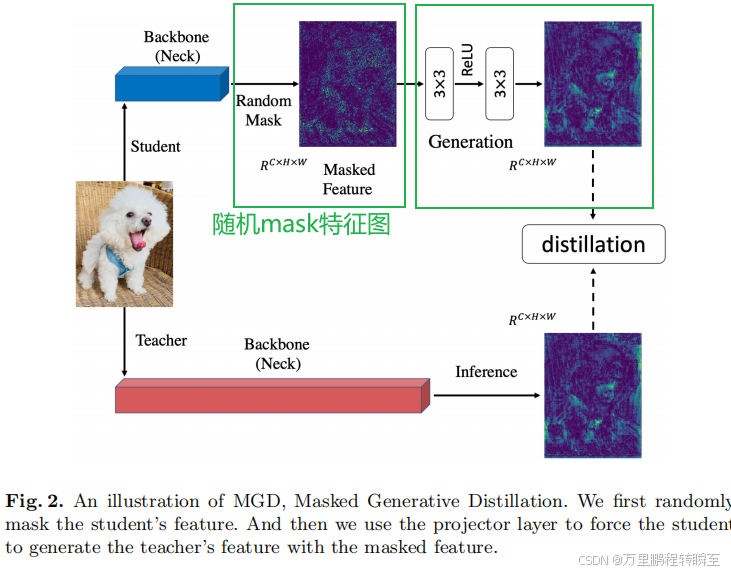
5.2 实现代码
https://github.com/yzd-v/MGD/blob/master/det/mmdet/distillation/losses/mgd.py
这里需要注意两个参数的默认值
alpha_mgd (float, optional): Weight of dis_loss. Defaults to 0.00002 loss权重
lambda_mgd (float, optional): masked ratio. Defaults to 0.65 mask概率
import torch.nn as nn
import torch.nn.functional as F
import torch
from ..builder import DISTILL_LOSSES
@DISTILL_LOSSES.register_module()
class FeatureLoss(nn.Module):
"""PyTorch version of `Masked Generative Distillation`
Args:
student_channels(int): Number of channels in the student's feature map.
teacher_channels(int): Number of channels in the teacher's feature map.
name (str): the loss name of the layer
alpha_mgd (float, optional): Weight of dis_loss. Defaults to 0.00002
lambda_mgd (float, optional): masked ratio. Defaults to 0.65
"""
def __init__(self,
student_channels,
teacher_channels,
name,
alpha_mgd=0.00002,
lambda_mgd=0.65,
):
super(FeatureLoss, self).__init__()
self.alpha_mgd = alpha_mgd
self.lambda_mgd = lambda_mgd
self.name = name
if student_channels != teacher_channels:
self.align = nn.Conv2d(student_channels, teacher_channels, kernel_size=1, stride=1, padding=0)
else:
self.align = None
self.generation = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(teacher_channels, teacher_channels, kernel_size=3, padding=1))
def forward(self,
preds_S,
preds_T):
"""Forward function.
Args:
preds_S(Tensor): Bs*C*H*W, student's feature map
preds_T(Tensor): Bs*C*H*W, teacher's feature map
"""
assert preds_S.shape[-2:] == preds_T.shape[-2:]
if self.align is not None:
preds_S = self.align(preds_S)
loss = self.get_dis_loss(preds_S, preds_T)*self.alpha_mgd
return loss
def get_dis_loss(self, preds_S, preds_T):
loss_mse = nn.MSELoss(reduction='sum')
N, C, H, W = preds_T.shape
device = preds_S.device
mat = torch.rand((N,1,H,W)).to(device)
mat = torch.where(mat>1-self.lambda_mgd, 0, 1).to(device)
masked_fea = torch.mul(preds_S, mat)
new_fea = self.generation(masked_fea)
dis_loss = loss_mse(new_fea, preds_T)/N
return dis_loss
关键函数为get_dis_loss,先随机生成数组,然后基于与lambda_mgd的差异生成mask,并进行特征值的保留,计算mse loss后乘以alpha_mgd作为loss系数。
5.3 实现效果
基于MGD的论文显示,MGD大约可以提升3个点左右的map。同时在效果上,MGD>FGD>CWD蒸馏。
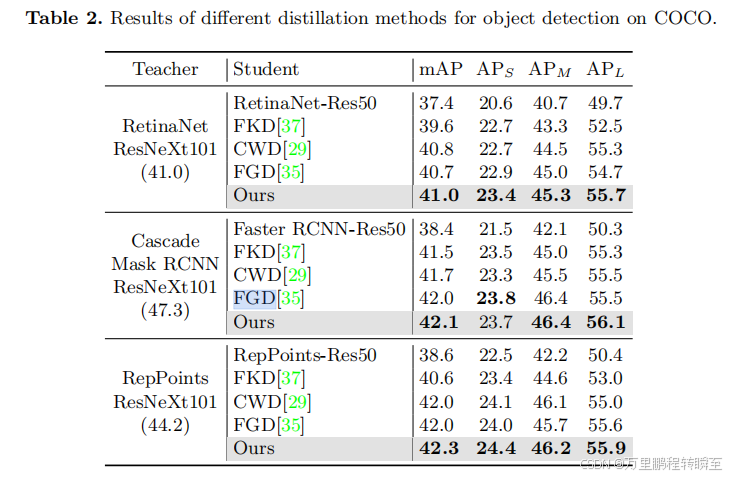
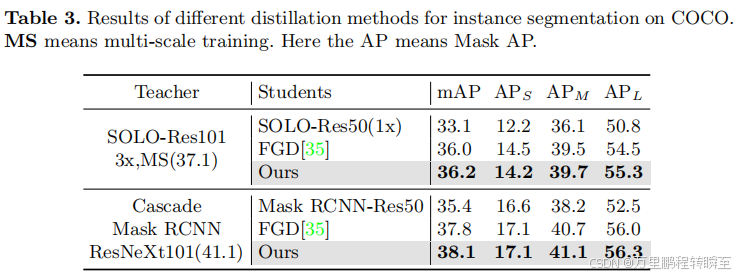
6、Channel-wise Knowledge Distillation for Dense Prediction
论文地址:https://arxiv.org/abs/2011.13256
项目地址:https://github.com/irfanICMLL/TorchDistiller/tree/main
发表时间:2021
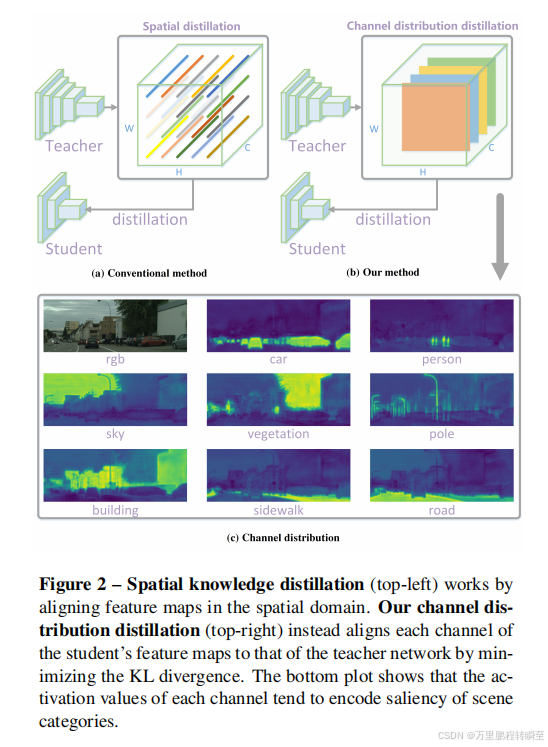
首先将通道的激活转换为概率分布,这样我们就可以使用概率距离度量,如KL散度来测量差异。如图2©所示,不同通道的激活倾向于编码输入图像的场景类别的显著性。此外,一个训练有素的语义分割教师网络显示了每个通道的清晰的类别特定掩码的激活图,这是预期的——如图1右侧所示。在这里,我们提出了一种新的通道式蒸馏范式来指导学生从一个训练有素的教师那里学习知识。
6.1 算法架构
算法结构示意如下所示,本质就是将kd散度作为loss取代了原来的mse loss。先将特征图的分布转换为概率分布,然后基于kd散度的理论度量学生特征与教师特征的分布差异
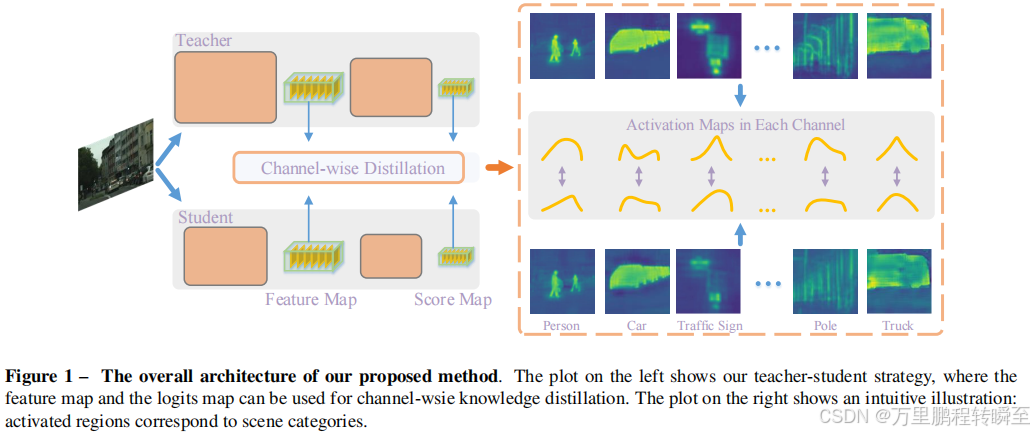
算法公式定义如下所示,与交叉熵相比,先在WH维度进行softmax归一化(总概率和为1)。用Y_tracher替换了Y_true,同时用Y_tracher/Y_student替换了Y_student,

6.2 实现代码
代码地址:https://github.com/huangzongmou/yolov8_Distillation/blob/master/ultralytics/yolo/engine/trainer.py
这里需要注意的是,代码层次实现的是减法,因为log内的除法,移出来就变成减法了。
class CWDLoss(nn.Module):
"""PyTorch version of `Channel-wise Distillation for Semantic Segmentation.
<https://arxiv.org/abs/2011.13256>`_.
"""
def __init__(self, channels_s, channels_t,tau=1.0):
super(CWDLoss, self).__init__()
self.tau = tau
def forward(self, y_s, y_t):
"""Forward computation.
Args:
y_s (list): The student model prediction with
shape (N, C, H, W) in list.
y_t (list): The teacher model prediction with
shape (N, C, H, W) in list.
Return:
torch.Tensor: The calculated loss value of all stages.
"""
assert len(y_s) == len(y_t)
losses = []
for idx, (s, t) in enumerate(zip(y_s, y_t)):
assert s.shape == t.shape
N, C, H, W = s.shape
# normalize in channel diemension
softmax_pred_T = F.softmax(t.view(-1, W * H) / self.tau, dim=1) # [N*C, H*W]
logsoftmax = torch.nn.LogSoftmax(dim=1)
cost = torch.sum(
softmax_pred_T * logsoftmax(t.view(-1, W * H) / self.tau) -
softmax_pred_T * logsoftmax(s.view(-1, W * H) / self.tau)) * (self.tau ** 2)
losses.append(cost / (C * N))
loss = sum(losses)
return loss
6.3 实现效果
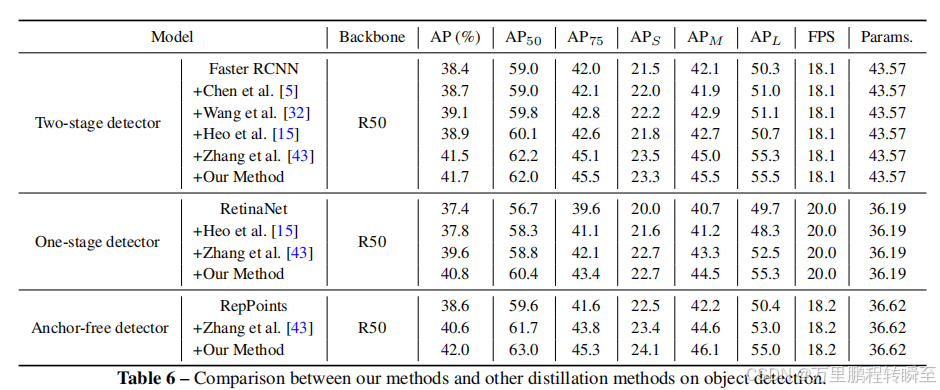
COCO2017效果,可以看到有3.3%的提升,
7、Focal and Global Knowledge Distillation for Detectors
公开时间:2022年3月9号
项目地址:https://github.com/yzd-v/FGD
论文地址:https://arxiv.org/pdf/2111.11837
建议阅读 项目快过:知识蒸馏 | 目标检测 |FGD | Focal and Global Knowledge Distillation for Detectors 获取更为详细的信息
在目标检测中,教师和学生的特征在不同的领域有很大的差异,特别是在前景和背景上。如果我们平均地提取它们,特征图之间的不均匀差异将会对蒸馏产生负面影响。因此,我们提出了聚焦蒸馏和全局蒸馏(FGD)。聚焦蒸馏将前景和背景分开,迫使学生专注于教师的临界像素和通道。全局蒸馏重建了不同像素之间的关系,并将其从教师转移到学生身上,补偿了聚焦蒸馏中全局信息的缺失。
7.1 算法架构
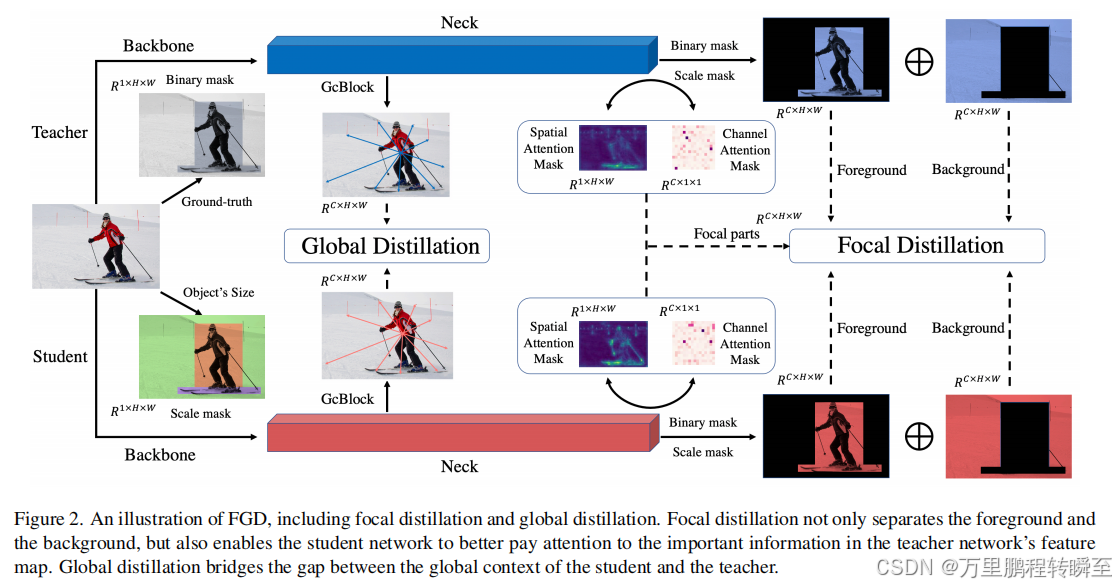
7.2 实现效果
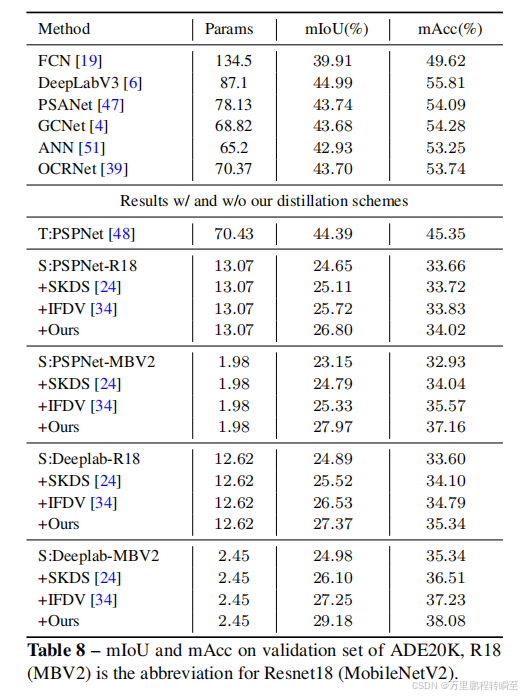
可以看到在coco数据集上有3个点左右的提升,同时基于MGD的论文实现,可以发现FGD是不如MGD有效。同时MGD的实现比较复杂,建议采用MGD的方式进进行蒸馏。
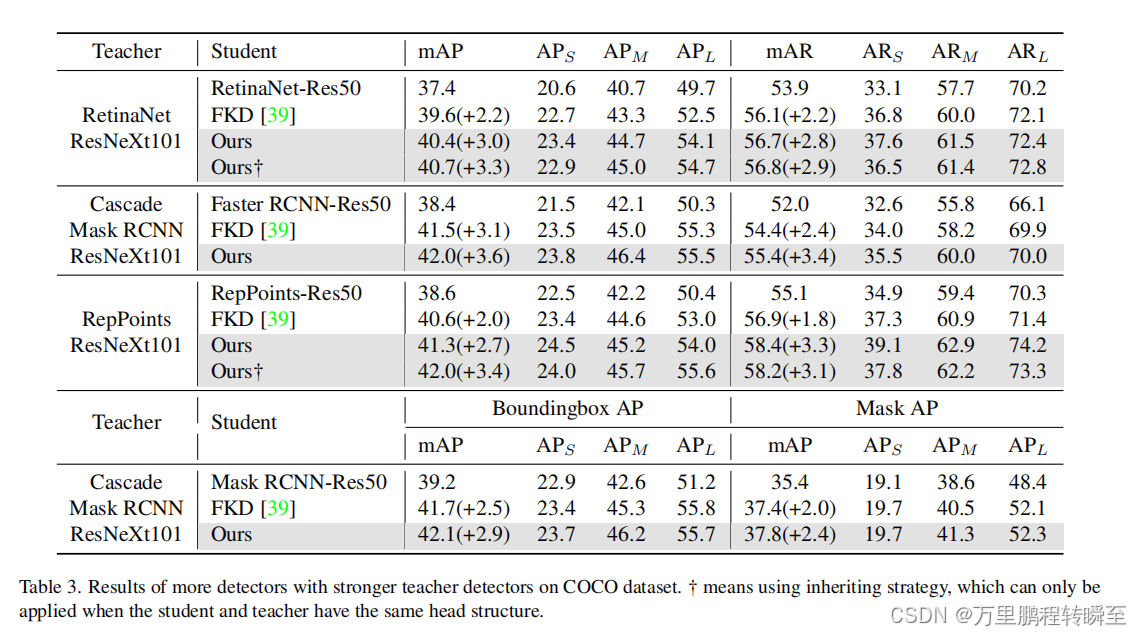


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











