







目录
一、简介
双重差分法(DID)是一种经济学中常用的计量方法,用于评估某一事件或政策的影响。通过比较实验组和对照组在事件发生前后的变化,DID能够有效地分离出事件或政策的影响。本案例将详细阐述如何使用双重差分法进行实证分析,并展示具体的STATA操作代码。

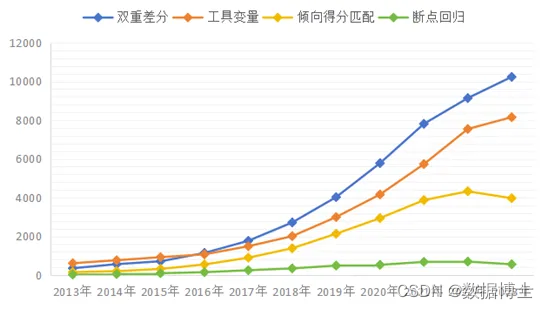
在中国知网以“双重差分”“倍差法”“DID”按篇名、主题、关键词、摘要、小标题检索,2017年后使用双重差分方法的论文数量急剧上升,超越了工具变量法(instrumental variable)、倾向得分匹配法(PSM)、断点回归设计(regression discontinuity design)等社会科学领域实证研究常用方法。据有关不完全统计,从2020年开始,国内外核心、权威期刊约有20%的实证论文采用了DID方法。
二、数据准备
数据收集:
假设我们要评估一项新的就业培训政策对失业人员再就业的影响。我们收集了实施该政策的地区(实验组)和未实施该政策的地区(对照组)的相关数据。数据包括个人的年龄、性别、教育水平、失业时长以及是否再就业等信息。
数据清洗:
在数据分析之前,需要对数据进行清洗,以确保数据的准确性和完整性。这包括检查数据的一致性、处理缺失值和异常值等。
* 检查数据的一致性
describe
* 处理缺失值
drop if missing(age) | missing(gender) | missing(education) | missing(unemployment_duration) | missing(reemployment)
* 处理异常值(例如,删除失业时长小于0的记录)
drop if unemployment_duration < 0变量定义:
定义所需的变量,包括被解释变量(是否再就业)、解释变量(政策实施虚拟变量和时间虚拟变量)以及控制变量(年龄、性别、教育水平和失业时长)。
* 定义变量
gen policy = (treatment == 1 & year >= policy_year) // 政策实施虚拟变量
gen time = (year >= policy_year) // 时间虚拟变量三、模型构建
基于双重差分法,我们构建以下回归模型:
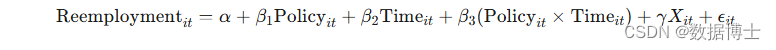
其中,Reemployment𝑖𝑡是个体 𝑖在时间 𝑡是否再就业的二进制变量;Policy𝑖𝑡是政策实施虚拟变量;Time𝑖𝑡是时间虚拟变量;Xit
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









