







目录
向量自回归模型(VAR)是一种用于分析多个时间序列变量之间相互关系的统计模型。在 STATA 中,我们可以通过一系列的操作来实现 VAR 模型的建立、分析和解读。以下将为您详细介绍 VAR 模型在 STATA 中的具体操作步骤,并结合一个实际案例进行展示。
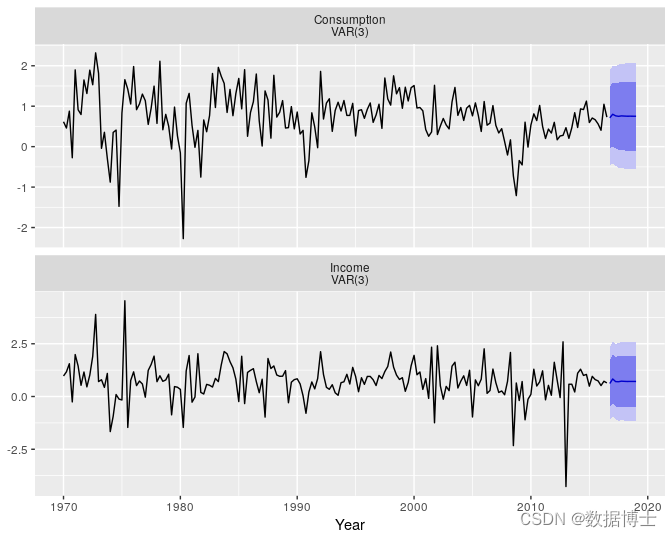
一、数据准备
在进行任何统计分析之前,数据的准备工作至关重要。首先,您需要确保已经成功地将所需的数据集导入到 STATA 中。这可以通过多种方式实现,如使用 import 命令从外部文件(如 Excel、CSV 等)导入数据,或者直接在 STATA 中手动输入数据。
假设我们有两个时间序列变量 gdp 和 inflation ,分别代表国内生产总值和通货膨胀率。在导入数据后,需要对变量进行适当的命名和处理。确保变量的数据类型正确,并且不存在缺失值或异常值。如果存在缺失值,您可能需要根据具体情况选择合适的处理方法,如删除包含缺失值的观测值、使用均值或中位数进行填充等。
二、平稳性检验
时间序列数据的平稳性是建立 VAR 模型的一个重要前提。如果数据不平稳,可能会导致错误的模型估计和无效的推断。在 STATA 中,常用的平稳性检验方法是单位根检验,其中 ADF(Augmented Dickey-Fuller)检验是一种广泛应用的方法。
对于变量 gdp ,我们可以使用以下代码进行 ADF 检验:
dfuller gdp
对于变量 inflation ,执行类似的操作:
dfuller inflation
假设 gdp 的检验结果如下:
Dickey-Fuller test for gdp
Lag order: 4
=============================================
Test Statistic p-value
---------------------------------------------
ADF test statistic -1.25 0.56
============ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









