






Qwen3是阿里巴巴开源的国内首个混合推理大模型,支持"思考模式"与"非思考模式"无缝切换。
旗舰模型Qwen3-235B-A22B采用混合专家(MoE)架构,总参数量235B,专家模型数量128个,活跃参数量22B,活跃专家模型8个,在代码、数学、通用能力等基准测试中,与业界顶级模型表现相当,展现出极强的竞争力,性能略微超越DeepSeek R1,属于开源界的顶级模型。
一、模型矩阵
| 名称 | 类型 | 上下文 长度 | 神经层数 | 阿里云推荐 显存配置 | 华为推荐 显存配置 | 主要特点 |
| Qwen3-235B-A22B | MOE | 128K | 94 | 8*96GB | 8卡64GB 2台Atlas800I A2 | 旗舰模型,编码、数学、通用能力媲美DeepSeek-R1、Grok-3,高效推理 |
| Qwen3-30B-A3B | MOE | 128K | 48 | 4*96GB | 8卡32GB 1 台Atlas800I A2 | 小型MoE,性能超Qwen2.5-32B,推理成本低,适合本地部署 |
| Qwen3-32B | Dense | 128K | 64 | 1*96GB | 8卡32GB 1 台Atlas800I A2 | 高性能密集模型,适合复杂任务,推理能力匹敌Qwen2.5-72B,适合企业级部署 |
| Qwen3-14B | Dense | 128K | 40 | 1*48GB | Atlas 300I Duo | 中等规模,平衡性能与资源占用,适合企业级应用 |
| Qwen3-8B | Dense | 128K | 36 | 1*24GB | Atlas 300I Duo | 轻量高效,适用于电脑或汽车端的对话系统、语音助手场景 |
| Qwen3-4B | Dense | 32K | 36 | 1*24GB | Atlas 300I Duo | 小型模型,推理速度快,适用于移动端部署 |
| Qwen3-1.7B | Dense | 32K | 28 | 1*24GB | Atlas 300I Duo | 超轻量,适合移动设备 |
| Qwen3-0.6B | Dense | 32K | 28 | 1*24GB | Atlas 300I Duo | 最小规模,极低资源需求,适用于低功耗场景,例如本地测试、科学研究 |
二、基准测试
旗舰模型 Qwen3-235B-A22B与其他顶级模型(如DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro)相比,在编码、数学、通用能力等各项基准测试中,成绩相当亮眼,表现出极强的竞争力。
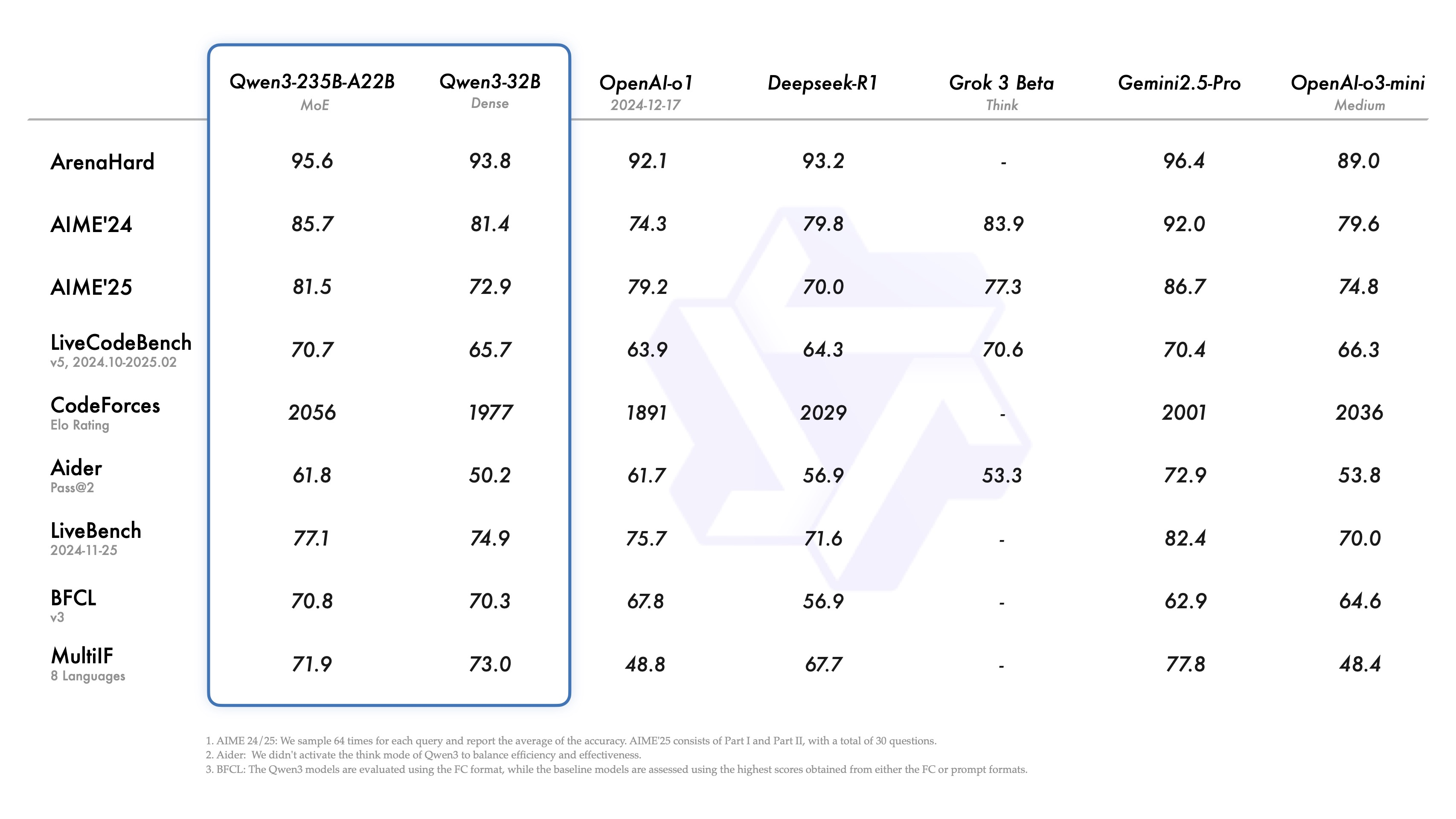
在评估模型人类偏好对齐的ArenaHard测评中,以95.6分超越了OpenAI-o1及DeepSeek-R1。
在奥数水平的AIME25评测中,斩获81.5分,刷新开源记录。
在考察代码能力LiveCodeBench评测中,Qwen3突破70分,表现优越Grok3。
此外,小尺寸模型同样表现亮眼,Qwen3-4B在数学、代码能力上“以小博大”,和比自身大10倍模型水平相当。
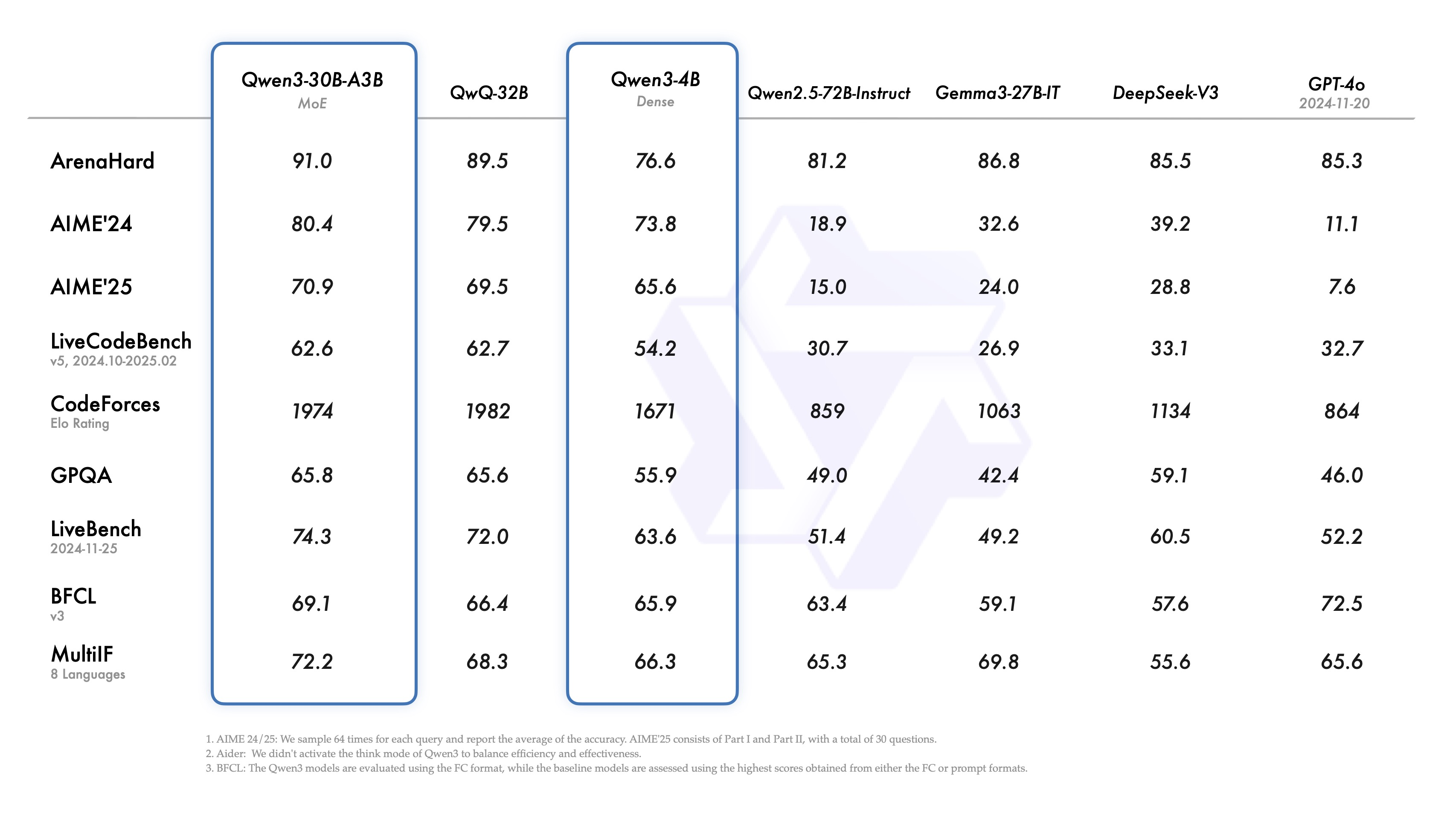
各评测项说明:
| 评测名称 | 说明 | 解读重点 |
| ArenaHard | 综合对话能力的人工对比评测,偏重 " 困难场景 " | 高分代表对话生成自然、逻辑性强 |
| AIME'24 / '25 | 数学竞赛题,测试数学推理、数列、几何等能力 | GPT-4o 分数很低,因其在该基准测试中未开启 " 思考模式 ",Qwen3 表现更实际 |
| LiveCodeBench | 代码生成任务,结合实时代码执行验证正确性 | Qwen3-4B 表现接近 GPT-4o,说明小模型已具备强代码能力 |
| CodeForces(Elo Rating) | 类似编程竞赛 Elo 排名,越高越强 | Qwen3-4B > GPT-4o,意味着它在 " 解题速度 + 准确性 " 上优于 GPT-4o |
| GPQA | 高质量问答集(类似学术类 QA),考察多跳推理 | Qwen 系列保持优势,说明对知识与推理兼顾 |
| LiveBench | 实时对话任务评测,包括多轮上下文与事实性要求 | GPT-4o 得分较低(52.2),说明未必在所有任务中都最优 |
| BFCL | 指令遵循与对话连贯性测试,Qwen 使用 FC 格式评估 | GPT-4o 表现最强,Qwen3-4B 略弱但接近 |
| MultiIF(8 Languages) | 多语言指令跟随能力评估 | Qwen3-4B 具有较好多语泛化,优于 GPT-4o(特别在非英语场景) |
三、模型亮点
1、国内首个混合推理模型
思考模式和非思考模式无缝切换,可以根据不同的任务需要选择不同的模式,无需跟往常一样同时部署推理模型和对话模型,一个模型即可搞定所有工作。
思考模式:该模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
非思考模式:该模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
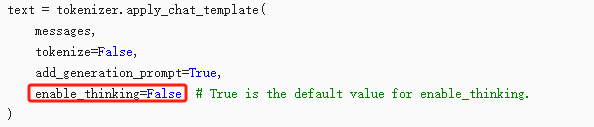
思考模式与非思考模式切换通过enable_thinking参数控制,禁用思考模式,将enable_thinking设置为false,默认为思考模式。
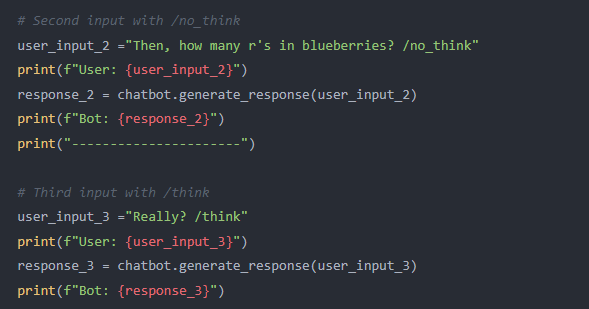
当启用思考模式时,也可以使用软切换机制来动态控制模型的行为。操作起来非常简单,只需要在用户提示词或系统消息中添加 /think 和 /no_think ,即可在不同轮次的交互中实现推理或者简单对话。
2、支持119种语言和方言
| 语系 | 语种&方言 |
|---|---|
| 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、罗马尼亚语、达里语、南非荷兰语、马其顿语僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| 汉藏语系 | 中文(简体中文、繁体中文、粤语)、缅甸语 |
| 亚非语系 | 阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 |
| 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) |
| 德拉威语 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| 突厥语系 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| 壮侗语系 | 泰语、老挝语 |
| 乌拉尔语系 | 芬兰语、爱沙尼亚语、匈牙利语 |
| 南亚语系 | 越南语、高棉语 |
| 其他 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
3、训练数据量翻倍,基础更扎实

4、原生支持MCP,Agent新业态
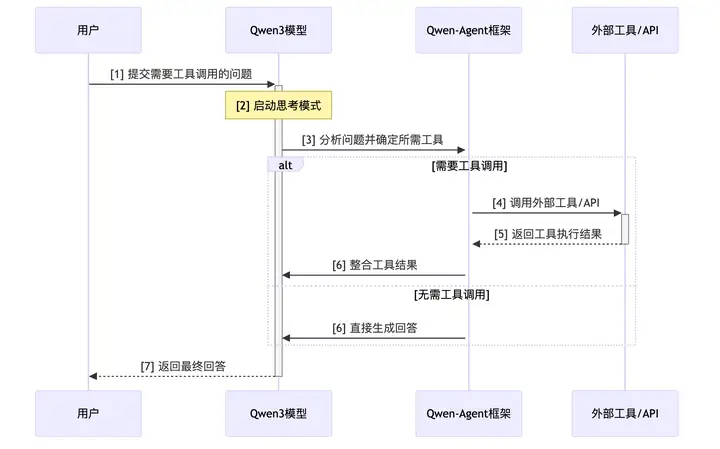
Qwen3原生支持模型上下文协议(MCP),并提供强大的函数调用能力,可通过Qwen-Agent框架实现复杂的工具调用和任务执行。
5、多模态融合能力
Qwen3 集成视觉(Qwen3-VL)、音频(Qwen3-Audio)模块,支持图像描述、语音转录及跨模态生成等任务,能够处理多种类型的任务,为用户带来更丰富的应用场景和交互方式。
- Qwen3-VL:图像描述准确率91.2%(GPT-4V为85.7%),支持医学影像分析,可识别CT片中0.3mm的肺部结节。
- Qwen3-Audio:语音识别错误率较Qwen2.5下降40%,支持方言转录,粤语识别准确率达98.6%。
- Qwen3-math:数学竞赛题解准确率89.3%,超越人类平均水平,可自动生成奥数题分步解析。
6、高效推理与硬件适配
Qwen3 兼容 vLLM、SGLang 与 llama.cpp,新增 Flash Attention2 支持,推理速度在 A100 GPU 上提升约 20%,且全面支持鲲鹏、昇腾等国产算力芯片,在政务金融场景实测效率提升显著。
四、总结
1、开源界顶级模型,整体表现略好于R1,但是相比R1不算有太大突破。
2、混合思维方式,同时支持思考、非思考两种模式,能同时满足智能客服、代码助手等场景,节约一套硬件资源。
3、原生支持MCP+Agent,能更好与应用场景集成,执行复杂任务。
4、代码能力突出,适用于构建代码助手。
5、原生多模态能力,能适配更多应用场景。但是当前多模态能力集中于图文、语音, 视频流实时推理和3D建模生成尚未完全开放,需加速技术迭代。

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









