






最强开源模型Qwen3发布!你用上了吗?四种方法教你快速上手Qwen3
导读
本文主要内容
- Qwen3有啥模型?跟其他模型有啥区别?
- Ollama/HuggingFace安装和使用Qwen3的教程
- 硅基流动/无问芯穹,免费调用Qwen3的教程
📢 作为阿里巴巴开源新一代通义千问模型 Qwen3 (简称千问 3),性能全面超越 Deepseek-R1、豆包 1.5pro 等国内领先模型,并登顶全球最强开源模型!
(详见官网报道 https://qwenlm.github.io/zh/blog/qwen3/ )
🚀模型亮点
- Qwen 3 系列的所有模型,都是“混合推理模型”(能直接回答,也能先思考再回答)
- 支持119门语言和方言(Qwen2.5只支持 29 种语言)
- 支持 MCP 协议
啥是混合推理?简单来说,就是同时支持两种思考模式:
- 像DeepSeek-V3 一样:直接回答
- 像DeepSeek-R1一样:先思考,后回答

Qwen3 模型速览

模型家族展示图如下
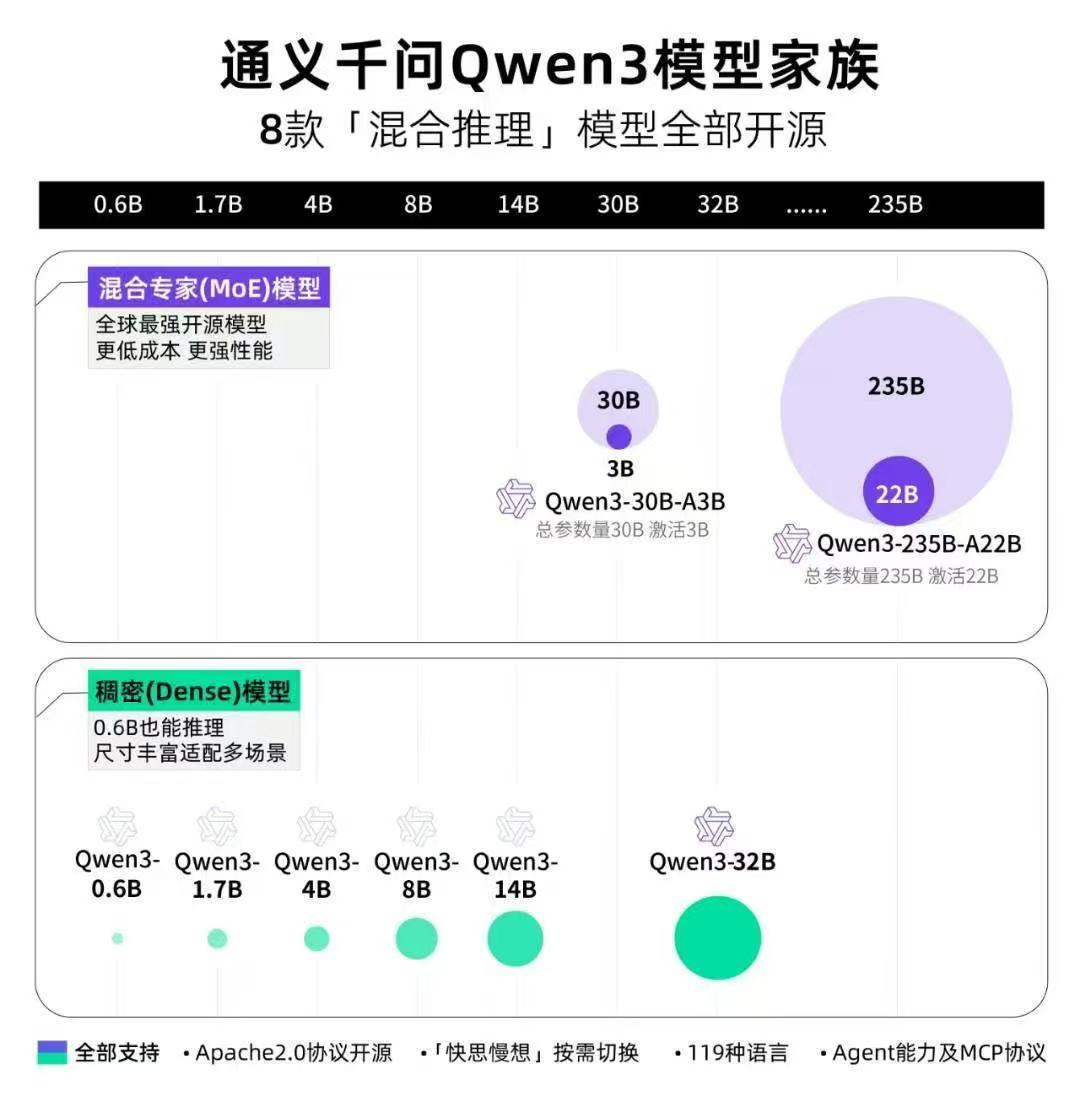

从应用角度看,Qwen3提供了全谱系的选择:
- Qwen3-0.6B:完美适合手机部署
- Qwen3-4B、8B:适合个人PC使用
- Qwen3-14B、32B:适合企业本地化部署
- 更大的模型:适合云端部署使用
🔗 体验链接
通义网页:https://www.tongyi.com/
Qwen Chat:https://chat.qwen.ai
【模型下载】
Ollama:https://ollama.com/library/qwen3:8b
Hugging Face:https://huggingface.co/Qwen
ModelScope:https://www.modelscope.cn/models/Qwen
GitHub:https://github.com/QwenLM
【百炼 API 】
https://bailian.console.aliyun.com/?tab=model#/efm/model_experience_center/text?currentTab=textChat&modelId=qwen3-235b-a22b
📢百炼已经提供Qwen3 API服务,8+2个模型,每个模型100万免费tokens!赶紧领取!
下面是使用Qwen3的四种方法,按需跳转。
Ollama安装Qwen3
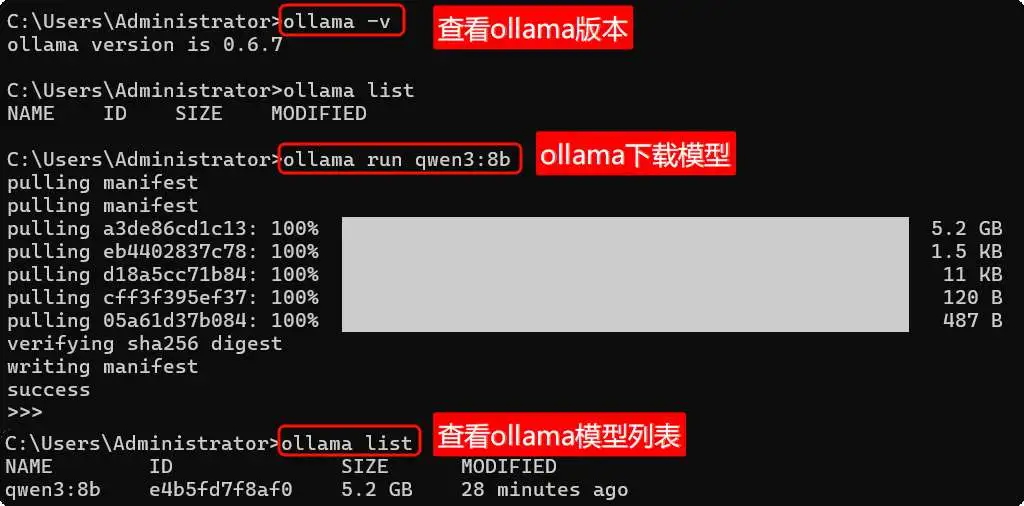
Qwen3发布后,Ollama第一时间支持了本地部署,8B的模型仅需5.2G空间就能运行。这意味着,普通笔记本电脑也能轻松驾驭强大的AI能力,实现随时随地的AI自由!
到Ollama官网 下载安装包
安装命令 ollama run <模型名称>,如
ollama run qwen3:8b
测试对话
在CherryStudio 快速使用 本地的qwen3
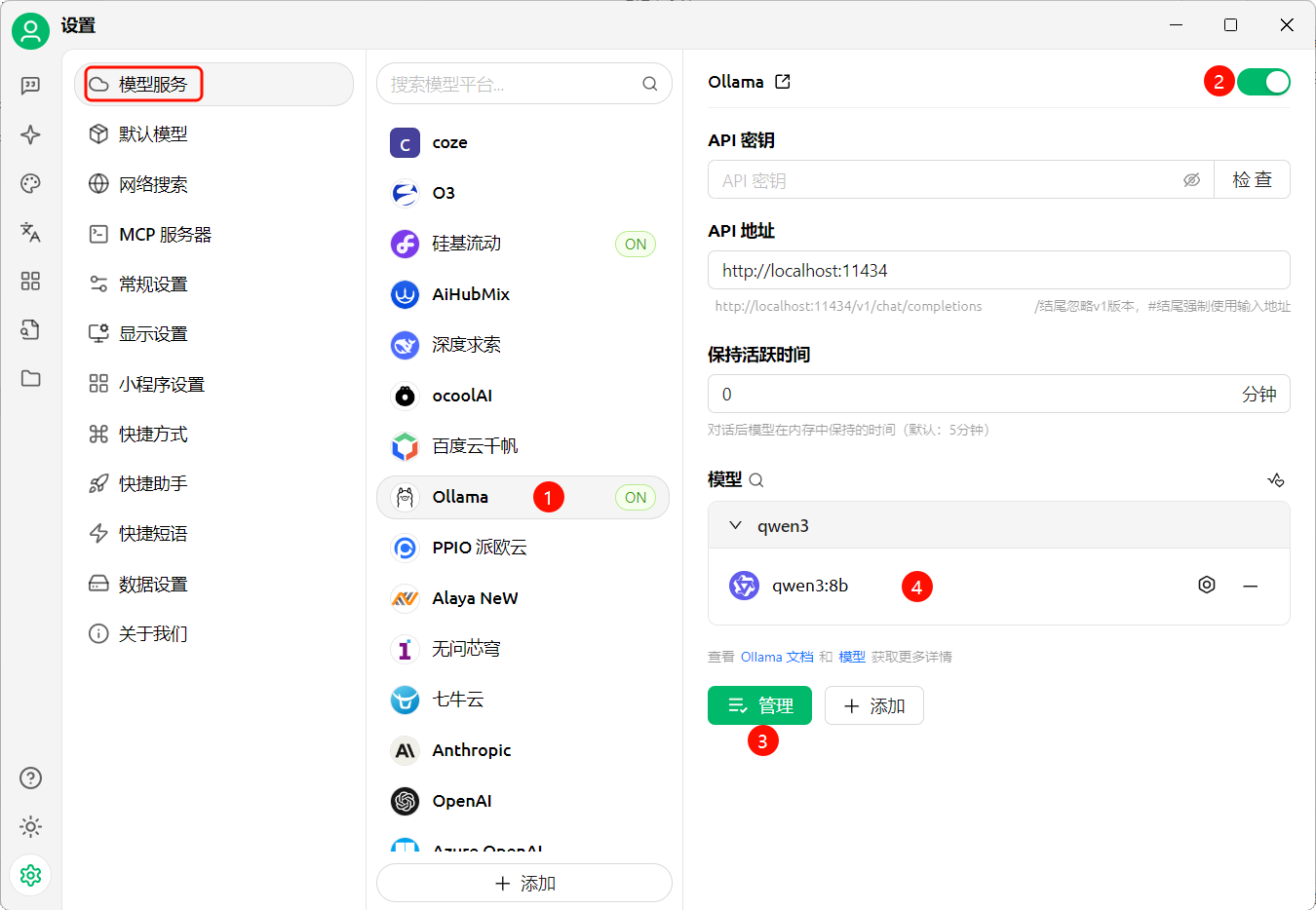
测试对话
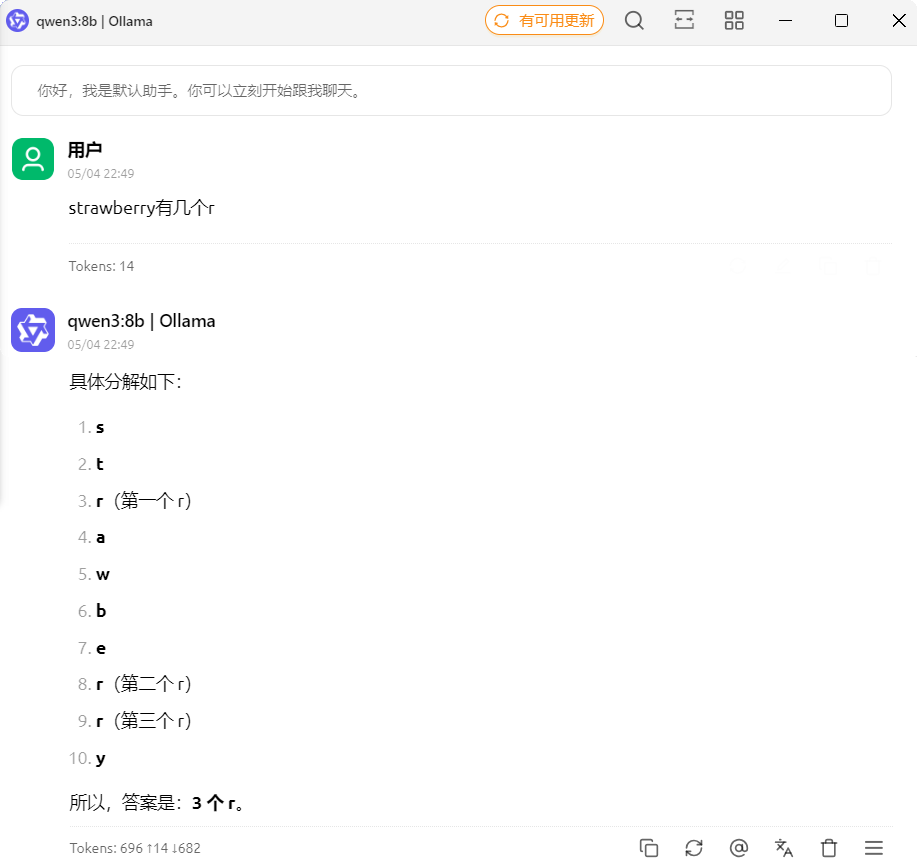
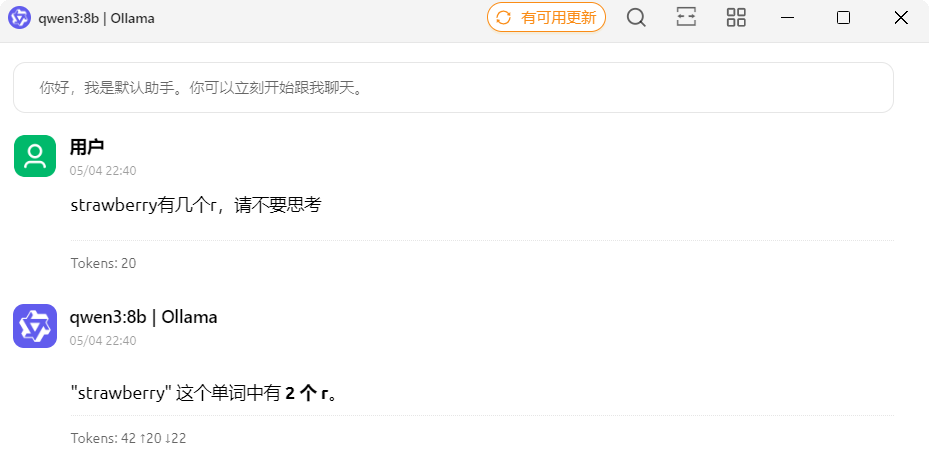
在提示词中输入“请不要思考”,可关闭思考模式!
ollama下载问题
The model you are attempting to pull requires a newer version of Ollama.
解决方案:升级Ollama
HuggingFace安装Qwen3
安装 huggingface 命令
pip install -U huggingface_hub
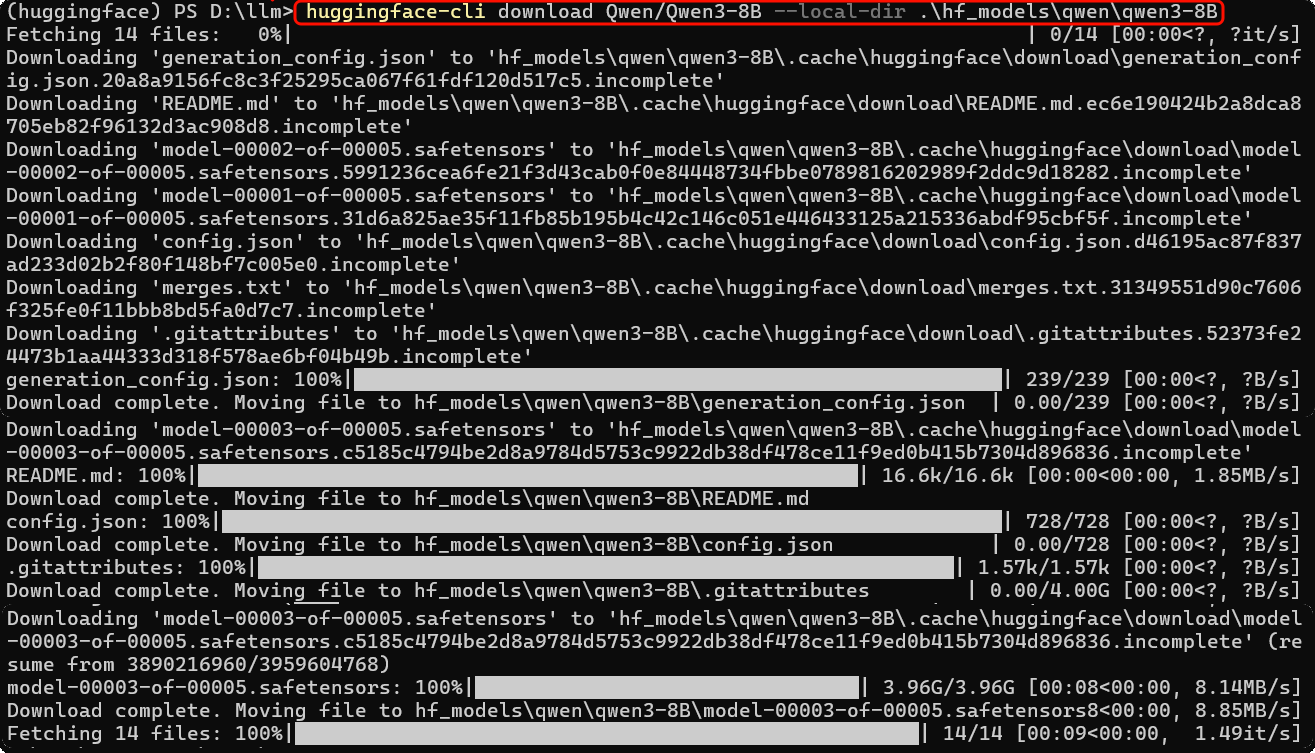
测试对话
先安装python包
pip install transformers accelerate
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
粘贴如下代码
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained("./models/Qwen/Qwen3-8B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"./models/Qwen/Qwen3-8B",
trust_remote_code=True,
device_map="auto" # device_map="cpu" #可明确指定使用 CPU
)
# prepare the model input
prompt = "Strawberry单词中有多少个r?"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt") # 移除 .to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1
)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print("回复:", response)
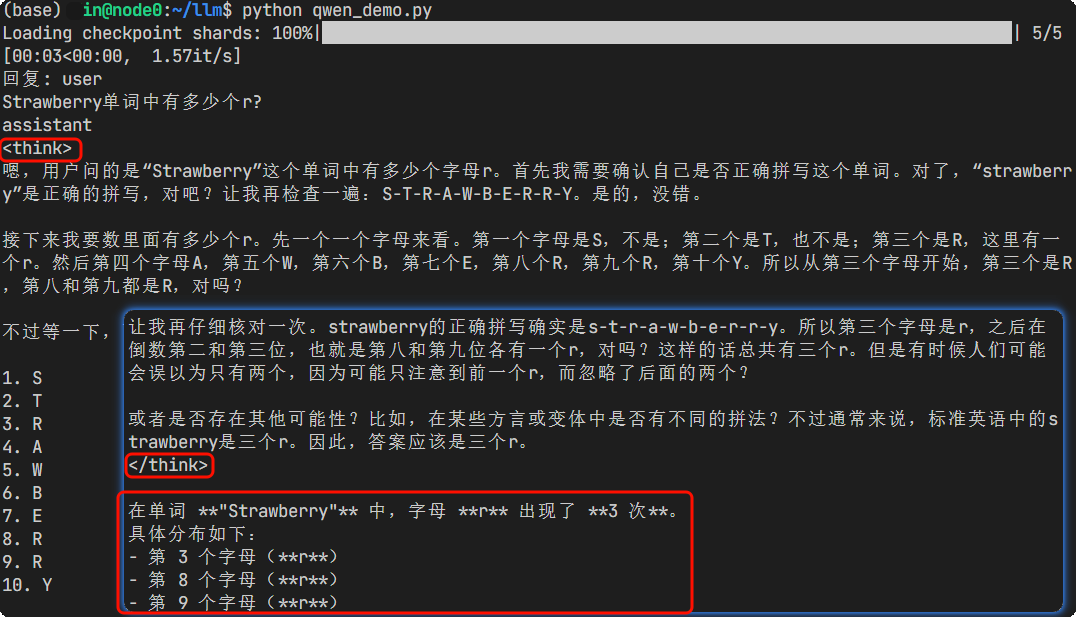

免费调用Qwen3
标准三步走
硅基流动调用Qwen3示例
官网注册链接 https://cloud.siliconflow.cn/i/xJvN9Ecu
手机号码注册,薅 2000 万 Tokens!
import requests
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "Qwen/Qwen3-235B-A22B", # 你选的模型
"messages": [
{
"role": "user", # 你扮演的角色是用户
"content": "把大象装进冰箱分成几步" # 你跟大模型对话的内容
}
]
}
headers = {
"Authorization": "Bearer sk-xxxxxx", # 替换为你的Api-key
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
回复如下
这是一个经典的脑筋急转弯问题,幽默的答案通常是:
分三步
- 打开冰箱门
- 把大象放进去
- 关上冰箱门
无问芯穹调用Qwen3示例
官网注册链接 https://cloud.infini-ai.com/platform/ai
手机号码注册,邀请即可免费在线体验或API调用,薅 无限 Tokens!
import requests
url = "https://cloud.infini-ai.com/maas/v1/chat/completions"
payload = {
"model": "qwen3-235b-a22b",
"messages": [
{
"role": "user",
"content": "9.11 和 9.8 谁大?"
}
]
}
headers = {
"Content-Type": "application/json",
"Accept": "application/json, text/event-stream, */*",
"Authorization": "Bearer sk-xxxxxx"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
回复如下
在比较9.11和9.8的大小时,可以按照以下步骤进行:
- 比较整数部分: 两数的整数部分均为 9,因此需要进一步比较小数部分。
- 统一小数位数: 将9.8补零为 9.80(与9.11同为两位小数),方便逐位对比。
- 比较小数部分: 十分位:9.80的8 > 9.11的1,因此无需继续比较百分位。
结论:9.80 > 9.11。
最终答案: 9.8 更大。
因为虽然9.11的小数部分有两位数字,但小数比较时从高位到低位逐位进行,9.8的十分位(8)大于9.11的十分位(1),所以9.8 > 9.11。
常见误区:
不要误以为小数点后数字位数多或数字本身(如“11”比“8”大)就代表数值更大,小数的大小取决于每一位的数值权重(十分位 > 百分位 > 千分位…)。
以上,是使用Qwen3的四种方法,实践出真知,与君共勉。



















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











