






导读:本文是“数据拾光者”专栏的第九十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍当前主流大模型公司的智谱AI的大模型系列产品以及他们最核心的GLM预训练框架。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者

01 智谱AI介绍
智谱AI(北京智谱华章科技有限公司)是一家源自清华大学计算机系技术成果的高科技公司,成立于2019年。公司致力于打造新一代认知智能大模型,专注于做大模型的中国创新。智谱AI的愿景是“未来让机器像人一样思考”,其核心团队由清华大学的科研精英组成,拥有强大的研发能力和创新精神。
智谱AI的核心技术包括自研的GLM(General Language Model)架构预训练框架,以及基于此框架开发的多阶段增强预训练方法。这些技术针对中文问答和对话进行了特别优化,使得智谱AI在中文处理能力上具有显著优势。公司合作研发了中英双语千亿级超大规模预训练模型GLM-130B,并推出了对话模型ChatGLM及其单卡开源版本ChatGLM-6B。
02 智谱AI主要产品
智谱AI研发的大模型产品叫智谱清言,其核心模型是基于GLM预训练框架的双语对话模型,具有多种功能和应用场景。以下是智谱AI主要的大模型产品:
1. ChatGLM 系列模型
(1)技术原理
架构基础:ChatGLM系列模型基于GLM架构,采用Transformer解码器结构,具备高度并行化的计算能力,并能够捕捉长距离的语言依赖关系。
自回归生成:类似于GPT模型,ChatGLM采用自回归的方式进行文本生成,即逐步生成每一个词,直到生成完整的句子。
优化技术:ChatGLM-6B经过约1T标识符的中英双语训练,辅以有监督学习微调(SFT:Supervised Fine-Tuning)、基于人类反馈的强化学习(RLHF:Reinforcement Learning from Human Feedback)等技术,生成的回答符合人类偏好。
多模态能力:支持多模态输入和输出,能够处理文本、图像等多种数据类型。
长上下文处理:支持更长的上下文长度,从2K扩展至32K,能够更好地理解和生成复杂的语言结构。
(2) 使用方法
开源资源:ChatGLM-6B是开源的,支持在单张消费级显卡上进行推理使用。用户可以在GitHub上找到模型文件和相关资源。
本地部署:结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。
(3)实测效果
多语言支持:ChatGLM-6B支持中英双语问答,经过1:1比例的中英语料训练,兼具双语能力。
优化表现:在处理多轮对话时,ChatGLM能够根据对话历史调整生成内容,使得回复更符合上下文语境,表现出强大的多样性和灵活性。
(4)应用场景
智能对话:适用于智能客服、虚拟助手等需要中英双语对话和问答的场景。
内容生成:可以用于生成自然、连贯的对话文本,适用于创意写作、故事生成等任务。
2. GLM-4
GLM-4是智谱AI最新一代的大语言模型,融合了前三代ChatGLM的经验和教训。GLM-4系列包括GLM-4、GLM-4-Air和GLM-4-9B。
ps:ChatGLM和GLM-4的关系有点类似ChatGPT和GPT-4的关系。
(1)技术原理
架构基础:GLM-4是基于Transformer架构的大型语言模型,拥有数十亿个参数。该模型通过大规模语料库的训练,能够理解和生成自然语言文本,实现与人类的交互。
性能提升:GLM-4的整体性能相比上一代提升了60%,逼近GPT-4。它支持更长的上下文(最高128K),具备更强的多模态能力,推理速度更快,支持更高的并发,大大降低了推理成本。
多模态支持:GLM-4不仅支持文本输入,还具备视觉理解能力,能够处理图像和文本的混合输入,进行多模态对话。
(2) 使用方法
开源资源:GLM-4系列中的GLM-4-9B是开源版本,用户可以通过智谱AI的GitHub仓库下载模型文件和相关资源。
本地部署:用户可以在本地部署GLM-4-9B模型,支持在单张消费级显卡上进行推理使用。
API调用:智谱AI提供了API接口,用户可以通过智谱开放平台进行API调用,将GLM-4集成到自己的应用中。
(3)实测效果
多语言支持:GLM-4支持26种语言,能够进行多语言对话,适用于全球用户。
性能表现:在多项权威评测中,GLM-4展现出优异表现。具体来说,GLM-4在MMLU、GSM8K、MATH、BBH、HellaSwag和HumanEval等评测集上的得分分别达到了GPT-4的94%、95%、91%、99%、90%和100%的水平。
长文本处理:GLM-4支持最大128K的上下文长度,单次提示词可以处理的文本可以达到300页。在128K文本长度内,GLM-4模型均可做到几乎100%的精度召回。
(4) 应用场景
- 智能对话:适用于智能客服、虚拟助手等需要中英多语言对话和问答的场景。
- 内容生成:可以用于生成自然、连贯的对话文本,适用于创意写作、故事生成等任务。
- 多模态交互:支持图像和文本的混合输入,适用于需要多模态交互的场景,如智能客服、虚拟助手、创意设计等。
长文本处理:适用于需要处理长文本的场景,如科研、教育、金融等。
(5)优化建议
提示工程:设计合理的提示词可以优化模型的生成效果。
性能优化:使用半精度推理(FP16)、启用批处理加速、合理设置生成参数等方法可以提升模型的推理速度。
3. CogVLM
CogVLM 在智谱清言中的应用主要集中在图像理解与描述、视觉问答、多轮交互对话、视觉定位和图像字幕生成等方面。这些功能使得智谱清言在处理图像和文本的多模态任务中表现出色,提供了接近 GPT-4V的图片理解能力。
(1) 技术原理
视觉优先架构:CogVLM的核心思想是“视觉优先”,在多模态模型中将视觉理解放在更优先的位置。该模型使用了5B参数的视觉编码器和6B参数的视觉专家模块,总共11B参数用于建模图像特征,这甚至多于文本的7B参数量。这种设计使得CogVLM在处理多模态数据时具有更强的特征表示能力和更高的效率。
深度融合:CogVLM通过在GPT语言模型的各个层中添加可训练的视觉专家模块,这些模块包括QKV矩阵和MLP层,实现了图像特征与文本特征在各层的深度融合,确保在此过程中不会降低语言模型的自然语言处理能力。
(2)使用方法
硬件要求:使用CogVLM需要CUDA 11.8及以上环境,推理总显存需要40G以上。推荐使用A40、A6000或A100显卡,也可以使用2卡3090/A30/4090等。
模型文件:可以从ModelScope平台下载所需的模型文件,如cogvlm-chat和vicuna-7b-v1.5。使用矩池云网盘上传这些模型文件,具体步骤如下:
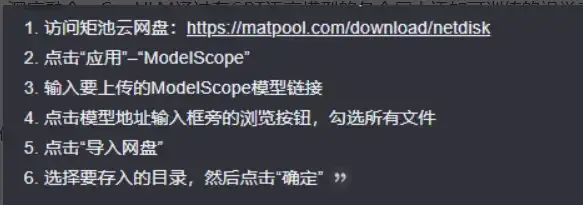
环境配置:在矩池云主机市场选择一个A系列显卡,如A2000,租用并配置环境。选择Pytorch 2.1.1镜像,并在高级选项里自定义一个8501端口,用于部署CogVLM web服务。
(3)实测效果
CogVLM-17B在多模态权威学术榜单上取得了综合成绩第一,在14个数据集上取得了state-of-the-art或第二名的成绩。例如,在图像字幕、视觉问答(VQA)、视觉定位等任务中表现优异。在识别复杂场景中的对象时,CogVLM能够准确识别出4个房子(3个完整可见,1个只有放大才能看到),而GPT-4V仅能识别出其中的3个。
(4)应用场景
- 图像字幕:生成准确的图像描述,适用于内容创作和图像标注。
- 视觉问答:回答与图像相关的问题,适用于智能助手和智能客服。
- 视觉定位:在图像中定位特定对象,适用于智能家居和智能驾驶。
- 文档图像理解:在OCRbench基准上性能提升了32%,在TextVQA基准上性能提升了21.9%,显示出强大的文档图像理解能力。
(5)优化建议
量化技术:采用量化技术压缩模型,使得可以部署在普通消费级GPU上,提高推理效率。
多专家模块:CogVLM2在推理时实际激活的参数量仅约120亿,这得益于其精心设计的多专家模块结构,显著提高了推理效率。
4. CodeGeeX
(1)技术原理
架构基础:CodeGeeX是一个基于Transformer的大规模预训练编程语言模型,采用从左到右的自回归解码器设计。它包含40个Transformer层,每层的自注意力块隐藏层维度为5120,前馈层维度为20480,总参数量达到了130亿。
训练数据:CodeGeeX在超过8500亿Token的20多种编程语言代码语料库上进行了预训练。训练数据包括开源代码数据集The Pile与CodeParrot,以及从GitHub开源仓库中爬取的Python、Java、C++代码。
技术实现:CodeGeeX遵循生成式预训练(GPT)架构,采用多头自注意力机制和MLP层,使用GELU操作的近似(FastGELU),在Ascend 910 AI处理器下效率更高。
(2) 使用方法
CodeGeeX可以通过以下两种方式安装和配置:
- VS Code插件:在VS Code的扩展市场中搜索“CodeGeeX”并安装。需要保证VS Code版本 >= 1.68.0。
- JetBrains IDE插件:支持IntelliJ IDEA、PyCharm、GoLand、CLion等JetBrains全家桶IDE,可以在插件市场搜索“CodeGeeX”安装。
CodeGeeX有以下四种使用模式:
隐匿模式:保持CodeGeeX处于激活状态,当停止输入时,会从当前光标处开始生成。生成完毕后会以灰色显示,按 Tab 即可插入生成结果。
交互模式:按 Ctrl+Enter 激活交互模式,CodeGeeX将生成多个候选,并显示在右侧窗口中。点击候选代码上方的 use code 即可插入。
翻译模式:选择代码,然后按下 Ctrl+Alt+T 激活翻译模式,CodeGeeX会把该代码翻译成匹配当前编辑器语言的代码。点击翻译结果上方的 use code 插入。
提示模式(实验功能):选择需要作为输入的代码,按 Alt/Option+t 触发提示模式,会显示预定义模板列表,选择其中一个模板,即可将代码插入到模板中进行生成。
(3)实测效果
CodeGeeX支持100多种编程语言,包括Python、Java、C++、JavaScript、Go等。CodeGeeX4-ALL-9B在多个权威代码能力评测集,如NaturalCodeBench、BigCodeBench上都取得了极具竞争力的表现,是百亿参数量级以下性能最强的模型。在推理性能和模型效果上得到最佳平衡。CodeGeeX在HumanEval-X代码生成任务上取得47%~60%求解率,较其他开源基线模型有更佳的平均性能。
(4)应用场景
- 软件开发:加速日常编码工作:提高代码编写效率,减少重复工作。辅助解决复杂算法问题:提供思路和实现建议。快速生成样板代码:减少重复工作。
- 学习与教育:帮助编程初学者:理解不同语言的语法和用法。为教师提供教学辅助:生成示例代码和练习题。
- 代码迁移:协助开发者:将项目从一种编程语言迁移到另一种语言。提供不同框架或库之间的代码转换建议。
- 代码审查:自动生成代码注释:提高代码可读性。辅助检查代码质量:提供优化建议。
- 原型开发:快速生成概念验证(PoC)代码:加速产品原型开发。为创意提供快速实现的可能性:促进创新。
(5)优化建议
模型容量与多语言能力:研究如何帮助模型提取编程的本质共性知识,而不是简单地增加参数量来存储多种语言的知识。
少样本学习能力:通过提供少量示例,用户可以启发模型生成所需的程序,而无需进行昂贵的微调。这一特性为CodeGeeX打造定制化编程助手提供了可能性。
除此之外,CodeGeeX的插件对个人用户完全免费,用户无需支付任何费用即可使用其提供的功能。它支持多种主流编程语言,包括Python、Java、C++/C、JavaScript、Go等,并且可以与多种主流的集成开发环境(IDE)集成,如Visual Studio Code、JetBrains IDEs、Visual Studio等。CodeGeeX不仅功能强大,还为用户节省了成本。
5. CogView
(1)技术原理
CogView是一个基于Transformer的文生图模型,采用了自编码器-解码器的结构。模型的主要组成部分包括文本编码器、图像解码器和跨模态嵌入空间。文本编码器负责将输入的文本转换为特征向量,图像解码器则根据这些特征向量生成相应的图像。跨模态嵌入空间用于在文本和图像之间建立联系,使得模型能够理解并生成符合文本描述的图像。
CogView3采用了一种名为“中继扩散”的新颖框架,将高分辨率图像的生成过程分解为多个阶段。具体来说,CogView3的生成过程分为三个阶段:
第一阶段:利用标准扩散过程生成512x512低分辨率的图像。
第二阶段:利用中继扩散过程,执行2倍的超分辨率生成,从512x512输入生成1024x1024的图像。
第三阶段:将生成结果再次基于中继扩散迭代,生成2048x2048高分辨率的图像。
CogView3-Plus在CogView3的基础上引入了最新的DiT(Diffusion Transformer)框架,采用Zero-SNR扩散噪声调度,并引入了文本-图像联合注意力机制。这些改进不仅提升了模型的整体性能,还大幅降低了训练和推理成本。CogView-3Plus使用潜在维度为16的VAE,进一步优化了模型的效率。
(2)使用方法
可以通过如下命令下载模型:
pip install modelscope
modelscope download --model ZhipuAI/CogView3-Plus-3B可以通过如下命令下载代码:
git clone https://github.com/THUDM/CogView3可以通过如下命令搭建环境:
docker run -it --rm --gpus=all -v /datas/work/zzq:/workspace python:3.10.11 bash
cd /workspace/CogView3/CogView3-main/inference
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/diffusers测试推理命令:
python test.py在线部署:
访问智谱AI的开放平台(https://bigmodel.cn/),点击模型详情页的“训练或微调”按钮,创建一个开发环境。
选择“CogView3-Plus-3B-Deploy”的镜像,使用1张A5000或3090的配置(如果需要跑2048x2048的图片可以选择1张H20的配置)。
选择CogView3-Plus-3B的模型文件路径“/llm/ZhipuAI/CogView3-Plus-3B”,完成其他属性的填写或选择,然后直接点击下一步。
确认计费方式,如果是简单体验可以选择按量计费的模型,如果需要使用更长的时间,也可以选择包周或包月的模式。
确定计费方式之后,直接点击提交订单。创建完成之后,等待1分钟左右,开发环境进入运行中的状态,可以通过ssh登录到容器内或者通过notebook的方式把CogView3-Plus-3B服务启动起来。
(3)实测效果
性能表现:CogView3在人工评估中比目前最先进的开源文本到图像扩散模型SDXL高出77.0%,同时只需要SDXL大约1/10的推理时间。
具体示例:CogView3能够根据文本描述生成高分辨率和高清晰度的图像,支持多模态图像理解,具备实时推理能力。
(4) 应用场景
- 艺术创作:生成高质量的图像,适用于创意设计、虚拟现实、游戏开发等领域。
- 广告制作:快速生成符合描述的图像,提高广告创意的效率。
- 电商展示:生成高质量的产品图像,提升用户体验。
- 设计迭代:支持进一步的图像编辑,适用于设计迭代和优化。
(5)优化建议
Zero-SNR扩散噪声调度:有效提高了图像生成质量,同时降低了训练和推理成本。
文本-图像联合注意力机制:进一步提升生成效果,使模型能够更好地理解文本和图像之间的关系。
潜在维度为16的VAE:在保持模型性能的同时,降低了计算复杂度,提高了推理效率。
6. GLM-4-Voice
(1)技术原理
GLM-4-Voice是一个端到端的语音模型,由三个核心部分组成:
- GLM-4-Voice-Tokenizer:通过在Whisper的Encoder部分增加Vector Quantization训练,并在ASR数据上进行有监督训练,将连续的语音输入转化为离散的token。每秒音频转化为12.5个离散token,能够在超低码率下准确保留语义信息,并包含语速、情感等副语言信息。
- GLM-4-Voice-9B:在GLM-4-9B的基础上进行语音模态的预训练和对齐,使其能够理解和生成离散化的语音token。经过数百万小时音频和数千亿token的音频文本交错数据预训练,GLM-4-Voice-9B具备强大的音频理解和建模能力。
- GLM-4-Voice-Decoder:基于CosyVoice的Flow Matching模型结构训练的语音解码器,支持流式推理,将离散化的语音token转化为连续的语音输出。最少只需要10个音频token即可开始生成,有效降低了端到端对话的延迟。
GLM-4-Voice通过端到端建模的方式,直接将输入的语音映射到输出的语音,省去了中间的文本转换步骤。这种端到端的建模方式不仅减少了信息的损失,还提高了语音处理的效率和准确性。更重要的是,它使得模型能够更好地捕捉和表达语音中的情感和语调,从而提供更加自然和富有情感的语音交互体验。
(2)使用方法
GLM-4-Voice的代码仓库已经开源(2.6K star),用户可以在GitHub上免费获取和使用该模型。智谱AI提供了一个可以直接启动的Web Demo,用户可以输入语音或文本,模型会同时给出语音和文字回复。github地址如下:https://github.com/THUDM/GLM-4-Voice.git
(3)实测效果
情感表达:GLM-4-Voice能够模拟不同的情感和语调,如高兴、悲伤、生气、害怕等,让语音回复更加自然。
调节语速:根据用户的指令调整语音的语速,适于不同的对话场景。
实时打断和指令输入:支持用户随时打断语音输出,输入新的指令调整对话内容。
多语言和方言支持:支持中英文及多种中国方言,如粤语、重庆话、北京话等。
低延迟交互:设计流式思考架构,低延迟实现高质量的语音对话。
(4) 应用场景
- 智能助手:在智能手机和智能家居设备中,GLM-4-Voice可以作为智能助手,通过语音交互帮助用户完成各种日常任务,如设置提醒、查询天气、控制家居设备等。
- 客户服务:在客户服务中心,作为虚拟客服,基于自然语言理解和语音合成技术,为用户提供咨询和解决问题的服务。
教育和学习:在教育领域,作为语言学习助手,帮助学生练习发音、听力和口语,提供个性化的学习建议。
娱乐和媒体:在娱乐行业,用在语音合成,为动画、游戏、有声书等提供自然、富有表现力的语音输出。
新闻和播报:用在新闻播报,将文本新闻快速转换为语音,提供给需要语音信息的用户。
(5)优化建议
音频Token化:智谱基于语音识别(ASR)模型以有监督方式训练了音频Tokenizer,能够在极低的码率下准确保留语义信息,并包含语速、情感等副语言信息。
流式思考架构:GLM-4-Voice设计了流式思考架构,输入用户语音后,可以流式交替输出文本和语音两个模态的内容,保证了回复内容的高质量,并具有端到端建模Speech2Speech的能力,同时保证低延迟性。
预训练数据构造:为了攻克模型在语音模态下的智商和合成表现力两个难关,智谱将Speech2Speech任务解耦合为Speech2Text和Text2Speech两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成数据以适配这两种任务形式。
7. AutoGLM
(1)技术原理
AutoGLM通过自然语言指令将任务规划与动作执行解耦,提升智能体的操作能力和灵活性。不仅如此,AutoGLM还可以在真实在线环境中学习和提升智能体的能力,基于自适应学习策略不断自我改进。不仅如此,AutoGLM基于中间界面设计,让任务规划和动作执行能独立优化,提高动作执行的精确度。同时,根据智能体当前的能力水平,AutoGLM动态调整学习任务的难度,最大程度地利用模型潜能。AutoGLM还可以用KL散度控制策略更新和智能体置信度经验回放,减轻模型在迭代训练中的遗忘问题。
(2)使用方法
AutoGLM目前还处于内测阶段,申请入口在智谱清言APP中,直接跟AutoGLM内测申请小助手对话提交申请即可。目前只能在安卓设备上使用,iOS应该很长时间内都不会支持。
AutoGLM在手机端使用流程如下:
打开清言App。
开启AutoGLM模式:在app内找到AutoGLM的入口,开启自动驾驶模式。
下达指令:像和朋友聊天一样,告诉AutoGLM你想要完成的任务,比如“帮我订个外卖”或“查找下周的天气预报”。
用户还可以通过安装“智谱清言”插件体验AutoGLM-Web,这是一个浏览器助手,能够模拟用户访问网页、点击网页,并在网站上自动完成高级检索、总结与内容生成。
(3)实测效果
自然语言交互:用户可以像和朋友聊天一样给AutoGLM发指令,它就能帮用户完成各种手机任务。
任务规划能力:AutoGLM能理解复杂指令,并规划出最佳执行步骤。
自我纠错与适应:在执行任务过程中,如果遇到问题,AutoGLM会尝试解决并继续任务。
高效执行:AutoGLM操作迅速,能节省大量时间和精力。
复杂步骤与循环操作:可以自主执行超过50步无打断操作,还可以实现操作流程复现。
跨App操作:具有更强大的泛化能力和思维链,支持复杂任务跨App操作。
记忆与快捷指令:在用户授权下,AutoGLM能记住过往选择,用户触发特定指令后,AI会自动采取对应行动。
AI主动决策:对于用户的模糊指令,可以主动帮用户做决策。
(4) 应用场景
- 社交媒体管理
:在社交平台上自动执行点赞、评论、分享等操作。
- 在线购物
:在电商平台上搜索商品、比较价格、下单购买、跟踪物流等。
- 旅行预订
:在旅游网站上搜索并预订酒店、机票、火车票等。
- 外卖订购
:在外卖平台上浏览菜单、下单、支付以及追踪订单状态。
- 日常信息查询
:如查询天气、新闻、股票信息等。
(5)优化建议
AutoGLM具备强大的高分辨率视觉处理能力,专门针对高分辨率图像信息处理开发了独特模型架构,不仅在准确性上有所提升,还降低了计算成本。AutoGLM能够适应动态环境,通过实时截屏和状态反馈,不断调整操作策略,确保任务的顺利完成。
8. CogVideoX
(1)技术原理
CogVideoX是一款基于扩散模型的视频生成工具,吸取了Sora和Stable Diffusion 3的优势,不仅使用了3D VAE,还引入了双路DiT架构。具体来说,CogVideoX主要进行了以下几个方面的工作:
使用3D VAE编码视频,有效地压缩视频维度、保证视频的连续性。
引入双路DiT分别对文本和视频进行编码,并用3D attention进行信息交换。
开发了一个视频标注的pipeline,用于对视频给出准确的文本标注。
提出了一种渐进式训练方法和一种均匀采样方法。
由于视频相比图像多了时序信息,所以需要对多出来的时间维度进行处理。先前的视频生成模型都采用2D VAE,这样会导致生成的视频在时间上连续性比较差,并且出现闪烁的情况。3D Causal VAE包括一个编码器、一个解码器以及一个KL约束。在编码的前两个阶段,分别在时间和空间维度上进行2倍下采样,在最后一个阶段只在空间维度上进行下采样。因此最后的下采样倍数是4X8X8,时间维度倍数为4,空间为8倍。
(2) 使用方法
CogVideoX系列中的CogVideoX-2B是首个开源版本,支持以英语输入最长226个tokens的提示词,消耗36GB显存,生成分辨率为720x480的6秒视频。
CogVideoX-2B在FP-16精度下推理仅需18GB显存,微调需要40GB,这使得单张高端显卡即可完成复杂任务。
(3)实测效果
视频生成能力:CogVideoX能够生成长达6秒、每秒8帧、分辨率为720x480的视频,提示词上限为226个token,为创作者提供了广阔的创作空间。
高质量视频输出:支持生成720x480分辨率的视频,确保视频清晰度和观看体验。
多精度推理支持:适配不同硬件条件,支持FP16、BF16、FP32、INT8等多种精度的推理方式。
硬件适配性:能在桌面级显卡如RTX 3060上运行,降低了使用门槛。
(4)应用场景
- 内容创作
:创作者可以利用CogVideoX生成独特的视频内容,降低视频制作的门槛。
- 广告制作
:企业可以提高视频生产效率,降低成本。
- 教育和研究
:教育机构和研究人员可以探索视频生成技术的新领域。
- 社交媒体
:用户可以生成个性化的视频内容,分享到社交媒体平台。
(5)优化建议
数据质量:数据质量是模型训练和推理过程中不可忽视的因素。高质量的数据能够帮助模型更好地学习和生成视频。
调整关键参数:通过调整模型的关键参数,如学习率、批处理大小等,可以显著影响模型的性能。合理调整这些参数,可以提升模型的稳定性和生成速度。
使用高效算法:采用高效的算法,例如使用BF16或FP16精度代替FP32,可以在不牺牲视频质量的前提下,提高模型的运行速度。
模型剪枝和量化:模型剪枝和量化是减少模型大小和提升运行效率的有效手段。通过剪枝去除不必要的权重,以及通过量化减少权重的精度,可以显著降低模型的资源消耗。
9.GLM-Zero
(1)技术原理
智谱AI新上线的GLM-Zero是一个深度推理模型,技术原理介绍如下:
模拟人脑学习机制:GLM-Zero尝试模拟人脑中的反馈和决策系统,推动AI模型向更高层次的智能迈进。这种无意识学习涵盖了自我学习、自我反思和自我批评等方面。
强化学习技术:GLM-Zero基于强化学习技术来训练模型,能让模型通过与环境的交互来学习如何做出决策,以最大化某种累积奖励。
多模态处理:GLM-Zero能处理多种输入模态,包括文字和图片,并输出完整的推理过程,这表明它具备一定的多模态理解能力。
(2)使用方法
对于普通用户来说,可以在「智谱清言」中的「Zero推理模型」智能体免费使用,支持上传文字或图片,模型会输出完整推理过程;对于开发者来说,可以在「智谱开放平台」中,通过API进行调用,将其集成到自己的应用中,提升应用的智能化和自动化水平。
(3)实测效果
金融专业研究题:例如,假设你用保证金购买了500股ABC公司的股票,每股50美元,保证金要求是60%,保证金利率10%(年化)。如果你1年后以每股45美元卖出股票,并且没有收到任何的保证金追加通知,GLM-Zero可以计算出你的投资回报率(ROI)。
(4)项目地址
我们可以通过官网体验,访问智谱清言官网,找到“Zero推理模型”智能体免费体验。还可以通过API调用体验,访问BigModel官网,通过API进行调用。
(5)应用场景
人工智能与AGI发展:GLM-Zero推动了强化学习在AI推理中的应用,适用于人工智能和AGI(通用人工智能)研究,支持模型的深度推理和自我优化。
日常生活与智能助手:用户可以在日常生活中使用GLM-Zero进行快速问题求解,帮助处理各种日常推理任务,如识别、分析图片信息、推理解决生活中的复杂问题等。
GLM-Zero具有强大的数学推理、编程能力、常识问答、多领域适应性和智能生成等功能特性,使其成为一个全能的智能推理工具,广泛适用于教育、科研、技术开发等多个领域。
03 GLM预训练框架介绍
1. 框架简介
质谱AI系列大模型中最关键的是GLM预训练框架,GLM是一个新型的自然语言处理预训练框架,通过自回归空白填充技术(Autoregressive Blank Infilling),实现了对自然语言理解与生成任务的统一处理。自回归空白填充技术通过调整空白块的大小,可以使GLM根据不同的任务需求,灵活地调整模型结构,从而实现对自然语言理解与生成任务的统一处理。
2. 自回归空白填充技术
自回归空白填充技术是GLM的核心,通过在输入序列中插入随机空白块,并让模型根据上下文信息填充这些空白块,从而实现模型对序列的建模。与传统自回归模型不同,GLM在填充空白块时不仅考虑了上下文信息,还考虑了整个序列的信息。这使得GLM在处理序列生成任务时具有更好的稳定性和准确性。
3. 框架优势
GLM框架有以下几个优势:
统一处理多种任务:GLM能够同时处理自然语言理解(NLU)、有条件生成任务(Cond. Gen.)和无条件生成任务,而不需要切换不同的模型架构或目标。
自回归预训练:GLM受益于自回归预训练,特别是在处理变长空白方面,性能优于BERT等自编码模型。
完形填空任务的重要性:完形填空任务(cloze finetuning)对GLM在NLU任务上的表现至关重要。
Span Shuffling和二维位置编码:GLM提出了Span Shuffling和二维位置编码技术,进一步提高了模型的性能。
4. 预训练目标任务
GLM提出了一种基于自回归空白填充目标的通用预训练框架。GLM将NLU任务制定为包含任务描述的填空问题,这些填空问题可以通过自回归生成来回答,同时,通过优化一个自回归的空白填充目标来训练GLM。
5. 实验结果
(1)与BERT对比:在多个自然语言理解任务上,GLM的性能优于BERT。特别是在ReCoRD和WSC任务中,GLM的性能始终优于BERT。
(2)千亿级参数大模型对比:2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B是亚洲唯一入选的大模型。在与OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示GLM-130B在准确性和恶意性指标上与GPT-3 175B (davinci)接近甚至持平,鲁棒性和校准误差在所有千亿规模的基座大模型中表现优异。
6. 应用场景
GLM在多个自然语言处理任务中表现出色,包括但不限于:
自然语言理解(NLU):文本分类、情感分析、分词、句法分析、信息抽取等。
有条件生成任务(Cond. Gen.):翻译任务、问答系统等。
无条件生成任务:直接生成文本内容,如创意写作、故事生成等。
7. 未来研究方向
优化训练过程:进一步优化GLM的训练过程,提高模型的泛化能力和鲁棒性。
多模态和跨语言处理:将GLM扩展到多模态数据处理和跨语言处理中,以更好地满足实际应用的需求。
小结下,GLM预训练框架通过自回归空白填充技术,实现了对自然语言理解和生成任务的统一处理。其在多个自然语言处理任务中表现出色,特别是在处理变长空白和多任务预训练方面具有显著优势。未来,GLM有望在多模态和跨语言处理等领域取得更多突破,为自然语言处理领域的发展做出更大的贡献。
参考资料
1.GLM: General Language Model Pretraining with Autoregressive Blank Infilling
作者:Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, Jie Tang
年份:2022
论文链接:https://arxiv.org/abs/2103.10360
2. GLM-130B: An Open Bilingual Pre-trained Model
作者:Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al.
会议:The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
年份:2023
论文链接:https://arxiv.org/abs/2406.12793
3. CogVLM: Visual Expert for Pretrained Language Models
作者:Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, Jie Tang
年份:2023
论文链接:https://arxiv.org/abs/2311.03079
4. AutoGLM技术报告
作者:清华大学和智谱联合推出
年份:2024
博客链接:https://blog.csdn.net/AI_Conf/article/details/143530615
5. GLM-4系列模型
作者:智谱AI团队
年份:2024
论文链接:https://arxiv.org/abs/2406.12793
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。

















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









