







Prompt Engineering(PE)就像是炼丹师的魔法配方,好的PE能够激发大模型的创造力能力,给人灵光一现的惊喜。下面我们就从OpenAI和它的死对头Anthropic给出的官方PE指南出发,了解好的PE应当遵循的基本原则,然后再介绍目前非常流行且有效的“CO-STAR框架”,最后再针对性地给出9个适合不同场景的9个PE框架。
文章较长,建议收藏后阅读~
一、OpenAI官方指南
策略1: 给 GPT 明确的指示 (Write clear instructions)
说明:清晰地告诉 GPT 你需要什么。如果你提出的需求不明确, GPT 就会〖猜测〗你要什么。而减少模型的〖猜测〗,有助于得到更满意的结果。
- 输入要包含尽可能详尽的细节 / Include details in your query to get more relevant answers
- 让模型扮演特定角色 / Ask the model to adopt a persona
- 利用分隔符把不同部分区分开 / Use delimiters to clearly indicate distinct parts of the input
- 告诉 GPT 完成任务的具体步骤 / Specify the steps required to complete a task
- 多提供几个示例 / Provide examples
- 告诉 GPT 需要的答案长度 / Specify the desired length of the output
策略2:给 GPT 提供阅读材料 (Provide reference text)
说明:语言模型经常信口开河,尤其遇到冷门话题,以及需要引用或者读取链接的时候。这时给 GPT 提供阅读材料,让它参考作答,就靠谱多了。
- 要求 GPT 按照提供的阅读材料作答 / Instruct the model to answer using a reference text
- 要求 GPT 在回答时,给出阅读材料里的原文信息 / Instruct the model to answer with citations from a reference text
策略3:把复杂任务拆解为简单的子任务 (Split complex tasks into simpler subtasks)
说明:借鉴软件工程的经验,把大任务拆解为一连串的小任务 (工作流),更容易完成 & 正确率更高。
- 使用意图分类,找到最确切的提示词 / Use intent classification to identify the most relevant instructions for a user query
- 如果对话拖得太长,过程中经常做一下总结,防止话题跑偏 / For dialogue applications that require very long conversations, summarize or filter previous dialogue
- 长文档要一段一段地处理,最后再进行整合 / Summarize long documents piecewise and construct a full summary recursively
策略4:给予 GPT 思考时间 (Give GPTs time to "think")
说明:给道数学题〖17 X 28 = ?〗 你得算一会儿再给出正确答案。 GPT 同理,需要时间慢慢地思考和推理,这样给出的答案也更加靠谱。
- 与其让 GPT 匆匆给出结论,不如让它先推理一遍解题过程 / Instruct the model to work out its own solution before rushing to a conclusion
- 把不想让用户看到的内容隐藏起来 / Use inner monologue or a sequence of queries to hide the model's reasoning process
- 最后问 GPT 之前的回答是否有遗漏 / Ask the model if it missed anything on previous passes
策略5:借助外部工具 (Use external tools)
说明:用其他工具的输出来补模型的不足。如果借助外部工具,可以更可靠或高效地完成任务,就别让 GPT 硬撑。
- 使用基于 embedding 的搜索来实现高效的知识检索 / Use embeddings-based search to implement efficient knowledge retrieval
- 需要做精确计算的场景:写代码完成,或者调用 API / Use code execution to perform more accurate calculations or call external APIs
- 使用 Function-Call (函数调用) / Give the model access to specific functions
策略6:进行系统化的测试 (Test changes systematically)
说明:量化模型的输出质量,有助于提升模型性能。完成这个过程,可以参考机器学习领域的有监督学习过程。
评估模型输出的时候,需要你提供一个优质答案作为参考标准 / Evaluate model outputs with reference to gold.standard answers

二、Anthropic官方指南
策略1:提示词要清晰明确 (Be clear & direct)
说明:在与 Claude 互动过程中,输入清晰直接的提示词,对于获得最佳响应至关重要。
- Claude 最喜欢直截了当的提示词。如果输入的提示词比较复杂,建议将其分步和编号。
- 判断提示词是否清晰明确的〖黄金法则〗:把 Claude 当成一位聪明勤奋的新员工,试想 ta 能否按照你的提示词,准确地行动并最终产生你期望的结果。
策略2:给 Claude 举例 (Use examples)
说明:提示词包含几个精心设计的例子,可以显著提高 Claude 回答的准确性、一致性和质量。这一技巧通常也被称作 few-shot prompting / one-shot prompting。
- 举例是提升 Claude 性能、引导产生符合期望的输出的最有效工具。如果你的输出需要包含更多的细节、更加结构化、或者遵守特定格式,那么〖举例〗这个技巧尤其有效。
- 通常,提供的示例越多,Claude 回答就越可靠,但代价是响应时间、计算资源等随之增多。
- 确保给 Claude 提供常见的边缘情况示例。
策略3:角色扮演 (Give Claude a role)
说明:在提示词中给 Claude 设定指定一个角色 (比如数学家),能引导提升其准确性和性能。这一技巧也常被称作 role prompting。
- 为了帮助 Claude 理解它在特定对话中扮演的角色,你需要提供额外的上下文。
- Claude响应体现在两个方面:① 调整输出内容 (行为/语气等) 以符合角色特征,② 在某些情况下(如数学问题)显著提高回答的准确性。
策略4:使用 XML 标签 (Use XML tags)
说明:Claude 大模型已经针对 XML 标签进行了专门训练,因此特别推荐使用 XML 标签来强化提示词的结构。
- XML 标签 <> </> 可以帮助 Claude 理解提示词的结构,类似于章节标题帮助人类理解文本结构。
- 将提示词的关键部分 (如例子、输入数据等) 用 XML 标签区隔开,可以帮助 Claude 更好地理解上下文,输出也能更准确。
- 当提示词比较长,或者结构比较复杂时,这个技巧尤其有效。
策略5:任务拆解 (Chain prompts)
说明:把复杂任务拆解成多个步骤,并将子任务构建成串行的工作流,确保过程中的每一步 & 最终输出是准确的。
- 任务完成后,你可以给 Claude 提供一套评分标准或评价准则,让 Claude 自己判断之前回答的质量。
- 让Claude根据评分标准的最高要求,重新生成或者修正之前的回答
策略6:逐步思考 (Let Claude think)
说明:面对复杂问题时,让 Claude 在回答之前先想清楚具体的步骤,再根据步骤生成最终的答案。这一技巧也被称作 chain of thought (CoT) prompting [思维链]。
策略7:预填充引导 Claude回答 (Prefill Claude's response)
说明:在提示词中设定 Assistant 内容,可以控制输出格式,并帮助 Claude 在角色扮演场景中保持角色特性。
- 这是 Claude 独特能力,允许在提示词中设定〖Assistant〗部分的详细内容,来精准引导和控制回答。
- 尤其在 Claude 输出表现不理想的情况下,几个预填充的句子可以显著提升响应质量。
策略8:控制输出格式 (Control output format - JSON mode)
说明:提供清晰的指令 [技巧1]、给 Claude 举例 [技巧2]、预填充 [技巧3],这些都可以引导 Claude 生成结果符合你期望的结构/风格。
策略9:请求Claude重写 (Ask Claude for rewrites)
说明:即使提示设计得很好,Claude 回答也可能不够准确或完全不符合预期。这种情况下,可以利用 Claude 自我修订能力,通过重写来改善生成质量。
- 需要提供更清晰的指令 & 详细的评分标准。
策略10:长上下文窗口技巧 (Long context window tips)
说明:长上下文增加了大模型处理复杂任务的能力。例如,一份长文档,之前需要将其切割并分别处理,现在可以完整输入给大模型,既有助于 Claude 全面理解上下文,又使得生成结果准确度更有保障。
- 当处理长文档时,使用XML标签将各部分分隔开,以便 Claude 能够清晰地区分输入的内容。
- 先输入长文档或其他附加材料,再输入详细的操作指令,可以显著提升输出品质。
- 基于输入的长文档/长文本回答某个问题时,先让 Claude 找到原文中的对应信息,再回答提出的问题。
- 基于输入长文档/长文本生成多项选择题时,提示词中包括同一文本的参考示例 (问题+选项+答案),可以显著提高生成质量。
三、CO-STAR框架
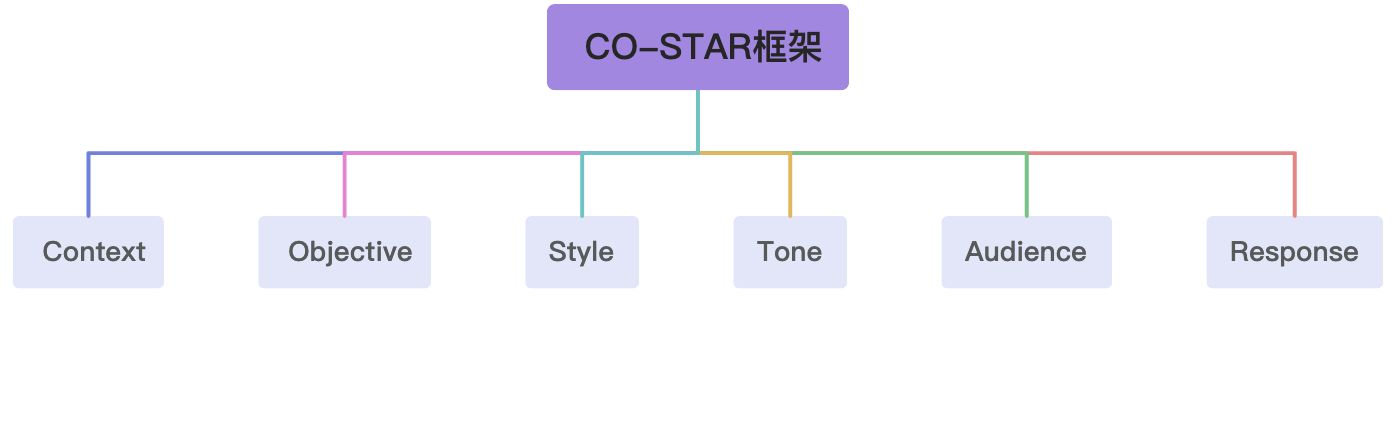
1、CO-STAR介绍
(C)上下文:提供任务的上下文信息
这有助于LLM了解正在讨论的具体情景,确保其答复具有相关性。
(O)目标:确定你希望LLM执行的任务是什么
明确你的目标有助于LLM把回答的重点放在实现这一具体目标上。
(S)风格:指明你希望LLM使用的写作风格
这可以是某个名人的写作风格,也可以是某个行业的某个专家,如商业分析专家或首席执行官。这将引导LLM以符合你需求的方式和用词做出回复。
(T)语气:确定回复的态度
这可确保LLM的回复与所需的情感或情绪背景产生共鸣。例如,正式的、幽默的、善解人意的等。
(A)受众:确定回复的对象
根据受众(如某一领域的专家、初学者、儿童等)量身定制LLM的回复,确保其在所需的语境中是恰当的、可以理解的。
(R)回复:提供回复格式
这可确保LLM按照下游任务所需的准确格式输出。例如,列表、JSON、专业报告等。大多数LLM应用程序都会以编程方式LLM回复进行下游操作,对于这些应用程序来说,JSON输出格式是最理想的。
2、CO-STAR示例
假设你是一名社交媒体经理,你需要帮助起草一篇Facebook帖子来宣传公司的新产品。
没有CO-STAR的提示工程是这样的:
在Facebook上写一篇文章,为我公司的新产品做广告。我的公司名为Alpha,产品名为Beta,是一种新型超快速吹风机。
下面是GPT-4的输出结果:
介绍Alpha公司革命性的Beta吹风机!
- 告别冗长乏味的吹发过程!阿尔法隆重推出贝塔型吹风机,这是我们在护发技术方面的最新创新。
- 超快吹干:得益于先进、强劲的电机,Beta可以将你的吹干时间缩短一半。让你更快做好准备,有更多时间做自己喜欢的事情!
这种输出方式虽然够用,但却非常普通,缺乏必要的细微差别和有针对性的吸引力,无法引起公司受众的共鸣。
下面是一个使用CO-STAR模板的示例,它提醒你将任务的其他方面融入你的提示中,特别是之前的快速提示中缺少的「风格」、「语气」和「受众」方面:
#上下文#
我想为我公司的新产品做广告。我的公司名叫Alpha,产品名叫Beta,是一种新型超快吹风机。
#目标#
为我创建一个Facebook帖子,目的是让人们点击产品链接购买它。
#风格#
效仿戴森等宣传类似产品的成功公司的写作风格。
#语气#
有说服力的。
#受众#
我公司在Facebook上的受众通常是老一代人。请针对这部分受众通常对美发产品的要求,量身定制你的帖子。
#回复#
Facebook上的帖子,简明扼要而又富有感染力。
通过应用CO-STAR,GPT-4的回复变得更有针对性、更有效:
用Alpha Beta拥抱轻松优雅--智慧一代的超快吹风机。
使用Alpha Beta,重新找回简单有效的护发乐趣。我们的最新创新产品不仅仅是一款吹风机,它还是一个承诺,为那些热爱生活的人提供快速、轻柔、可靠的头发造型。
- 简单直观:告别复杂的小工具。Alpha Beta为舒适和简便而设计,非常适合那些看中直接、无忧技术的人。
- 省心技术:我们知道你的时间非常宝贵。因此,Alpha Beta可以大大缩短吹干时间,让你有更多时间享受生活的乐趣。使用Alpha Beta,让每一天都成为美好的一天。体验精致与简约的完美融合。
CO-STAR框架指导你有条不紊地向LLM提供有关任务的所有关键信息,确保根据你的需求提供量身定制的优化回复。
四、其他9个PE框架

1、E.R.A
E.R.A 框架代表的意思如下:
Expectation:告诉 LLM 你期望的结果是什么。
Role:根据你的期望,在上下文中指定 LLM 需要扮演的角色或者身份,以这个角色或者身份来回答你的问题。
Action:有了期望和角色之后,就需要告诉 LLM 它需要做什么。
示例
Expectation: 我想要过上健康的饮食生活。
Role: 你是一名资深营养师,你能够在健康饮食方面提供独到的见解。
Action: 请你根据健康且可持续的饮食搭配原则,在保证营养摄入充分的前提下,为我提供一份为期一个月的营养食谱,你要保证至少五天之内没有重复。
2、A.P.E
A.P.E 框架代表的意思如下:
Action:把你需要让 LLM 做的事情指派给它。
Purpose:根据你指派的任务,提出你让它做这个任务的目的。
Expectation:写明你最终想要的、期望的结果,根据你的目的和你指派给 LLM 的任务,你期望 LLM 最终输出给你的内容是什么。
示例
Action: 请为我设计一个为期一个月的营养食谱,确保在保证营养摄入充分的前提下,至少五天内没有重复。
Purpose: 我希望通过这份食谱,能够过上健康且可持续的饮食生活。这不仅能够满足我对营养的需求,还能够帮助我培养良好的饮食习惯,提高生活质量和健康水平。
Expectation: 我期待得到一份详细的、多样化的营养食谱,其中包含早餐、午餐、晚餐和健康零食等各个方面的建议。食谱中的食物应当富含各种营养素,包括蛋白质、碳水化合物、脂肪、维生素和矿物质,以及足够的膳食纤维。同时,食谱中的食物应当易于购买和准备,符合实际生活中的需求和限制。
3、T.A.G
Task:一句话清晰准确的描述你想让它做什么。
Action:根据你的目标任务,提供给 LLM 你需要的步骤或者流程或者必须包含的元素。
Goal:最终目标,向 LLM 解释你最终需要的产出物。
示例
Task: 设计一个为期一个月的营养食谱,确保五天内没有重复。
Action:
- 确定每日的饮食结构,包括早餐、午餐、晚餐和健康零食。
- 根据健康饮食原则,选择各种食材,确保食谱中包含足够的蛋白质、碳水化合物、脂肪、维生素和矿物质。
- 确保食谱中的食物种类多样化,涵盖不同的风味和口感。
- 考虑食物的购买和准备方便性,尽量选择易于获取并且容易烹饪的食材。
Goal: 营养食谱需要详细并且多样化,应当满足健康饮食的原则,提供充足的营养素,并考虑到食材的易获取和烹饪方便性。
4、C.A.R.E
Context:向 LLM 提供上下文和背景信息。
Action:告诉 LLM,在你设定的背景和上下文中,你需要它做什么事情或者哪些事情,一定要具体。
Result:向 LLM 解释你的期望的输出内容。
Example:加上一个详细的示例描述,可以让 LLM 给出更准确的内容。
示例
Context: 我想要改善我的饮食习惯,过上健康的生活。但是我工作繁忙,经常吃外卖和零食,所以,我希望通过一份营养食谱来指导我每天的饮食选择,让我能够吃的更健康。
Action: 你需要为我设计一个为期一个月的营养食谱,每天包括早餐、午餐、晚餐和健康零食,确保五天内没有重复。食谱中应包含简单易做的菜肴,同时,你需要考虑到我工作繁忙的情况,你所提供的食材应易于购买和准备。
Result: 这份食谱应该尽可能的详细和多样化,其中需要包括每天的食谱安排以及所需食材清单。食谱应满足营养均衡的原则,提供足够的蛋白质、碳水化合物、脂肪、维生素和矿物质,还要考虑到方便性和实用性。最后,我需要你以表格的形式将这份清单提供给我。
Example: 以周一为例,早餐可以是煮粥配蔬菜水饺,午餐是麻婆豆腐配米饭,晚餐是清蒸鱼配炒时蔬,健康零食可以是水果拼盘或者坚果。食材清单会列出所需的材料和食物准备方法:比如蔬菜水饺有哪些食材,是怎么做的,怎么保存,麻婆豆腐是怎么做的,如何保存等等,这样,我才能够方便购买并准备食物。
5、R.A.C.E
Role:让 LLM 在上下文中扮演指定的角色或者身份。
Action:详细描述你需要让它做的事情。
Context:提供相关的上下文明细和背景信息。
Expectation:写明你最终想要的、期望的结果,根据你指定的角色或者身份,结合上下文,你期望 LLM 最终输出给你的内容是什么。
示例
Role: 你是一名专业的营养师,负责为繁忙的上班一族设计健康的饮食计划。
Action: 我现在需要你为我设计一个为期一个月的营养食谱,包括早餐、午餐、晚餐和健康零食,确保五天内没有重复。
Context: 我希望通过改善饮食习惯来过上健康的生活,但由于工作繁忙,经常依赖外卖和零食。我希望有一份详细的饮食计划,能够指导我每天的饮食选择,让我更加健康。
Expectation: 我期望得到一份详细的、多样化的营养食谱,其中包括每天的食谱安排和所需食材清单。食谱应满足营养均衡的原则,提供足够的营养素,食材和菜肴应简单易做,便于购买和准备。最终的输出物应以表格的形式呈现,包括食谱安排、所需食材、食物准备方法和保存建议,以便我能够轻松地执行并坚持这份健康饮食计划。
6、R.I.S.E
Role:让 LLM 在上下文中扮演指定的角色或者身份。
Input:为 LLM 提供相应的相关资料和数据,让 LLM 能够有输入信息,为后面做回答做好准备。
Steps:让 LLM 提供详细的步骤分析和回答,即我在以前文章中提到的思维链提示 (CoT):。
Expectation:写明你最终想要的、期望的结果以及期望 LLM 最终输出给你的内容是什么。
示例
Role: 我需要你扮演一名专业的营养师,为我设计一个为期一个月的营养食谱。
Input: 我的工作繁忙,经常依赖外卖和零食,但我希望通过改善饮食习惯来过上健康的生活。
Steps: 你必须逐步向我解释你是如何设计这一份食谱的,分别都遵循了什么科学原理,什么原则等,我需要保证你提供的食谱是健康的。
Expectation: 我希望得到一份详细的、多样化的营养食谱,其中包括每天的食谱安排和所需食材清单。食谱应满足营养均衡的原则,提供足够的营养素。同时,考虑到我的工作繁忙情况,食材和菜肴应简单易做,便于购买和准备。最终的输出物应以表格的形式呈现,包括食谱安排、所需食材、食物准备方法和保存建议,以便我能够轻松地执行并坚持这份健康饮食计划。
7、R.O.S.E.S
Role:让 LLM 在上下文中扮演指定的角色或者身份。
Objective:这里也可以理解为 Purpose,即目标,向 LLM 准确描述你的目标。
Scenario:提供问题场景,背景信息,上下文等。
Expected Solution:表达你最终想要的、期望的结果以及期望 LLM 最终输出给你的解决方案是什么。
Steps:让 LLM 提供详细的步骤分析和回答,同样的,也可以理解为思维链提示 (CoT)。
示例
Role: 请你扮演一名专业的营养师,为我设计一个为期一个月的营养食谱。
Objective: 我希望得到一个健康的饮食计划,能够帮助我改善不健康的饮食习惯,提升生活质量。
Scenario: 我的工作非常繁忙,常常没有时间准备健康的饮食,导致我经常依赖外卖和零食。我意识到这种饮食习惯对我的健康不利,因此我希望能够通过一个长期可持续的营养食谱来改善我的饮食习惯,让我能够过上更健康的生活。
Expected Solution: 我希望得到一份详细的、多样化的营养食谱,包括每天的食谱安排和所需食材清单。食谱应该遵循营养均衡的原则,提供足够的蛋白质、碳水化合物、脂肪、维生素和矿物质。同时,考虑到我的工作繁忙情况,食材和菜肴应简单易做,便于购买和准备。最终的输出物应以表格的形式呈现,包括食谱安排、所需食材、食物准备方法和保存建议,以便我能够轻松地执行并坚持这份健康饮食计划。
Steps: 你必须逐步向我解释你是如何设计这一份食谱的,分别都遵循了什么科学原理,什么原则等,我需要保证你提供的食谱是健康的。
8、T.R.A.C.E
Task:向 LLM 详细说明你想要它做的事情。
Request:结合这个任务,描述你需要让它给你什么回答。
Action:同时,告诉 LLM 它需要做什么。
Context:提供详细的上下文信息。
Example:提供详细的示例描述,可以让 LLM 给出更准确的回答。
示例
Task: 我需要你设计一个为期一个月的营养食谱,每天包括早餐、午餐、晚餐和健康零食,确保五天内没有重复。
Request: 我需要你提供一份详细的、多样化的营养食谱,其中包括每天的食谱安排和所需食材清单。并以表格形式回答给我。
Action: 请根据我的工作繁忙情况和对健康饮食的追求,设计一份营养均衡的食谱。确保食材和菜肴简单易做,并且容易购买和准备。
Context: 我的工作很忙,经常依赖外卖和零食,但我意识到这种饮食习惯对我的健康不利。因此,我希望通过一个为期一个月的营养食谱来改善我的饮食习惯,让我能够过上更健康的生活。
Example: 以周一为例,早餐可以是煮粥配蔬菜水饺,午餐是麻婆豆腐配米饭,晚餐是清蒸鱼配炒时蔬,健康零食可以是水果拼盘或者坚果。食材清单会列出所需的材料和食物准备方法:比如蔬菜水饺有哪些食材,是怎么做的,怎么保存,麻婆豆腐是怎么做的,如何保存等等,这样,我才能够方便购买并准备食物。
9、C.O.A.S.T
Context:向 LLM 提供上下文和背景信息。
Objective:即目标,向 LLM 准确描述你的目标。
Actions:告诉 LLM 它需要做哪些事情。
Scenario:提供场景信息。
Task:告诉 LLM 它的最终任务以及你需要它给你什么回答。
示例
Context: 我的工作生活节奏快,经常吃外卖和速食,我知道这很不健康,所以,我希望改善这种情况,过上更健康的生活。
Objective: 我希望得到一个为期一个月的营养食谱,能够帮助我改善饮食习惯,提供健康的饮食选择。
Actions:
- 分析我的饮食习惯和健康需求。
- 设计一个为期一个月的营养食谱,包括每天的早餐、午餐、晚餐和健康零食,确保五天内没有重复。
- 选择简单易做、营养丰富的食材和菜肴。
- 提供食谱中所需食材的清单和食物准备方法。
Scenario: 我每天的工作非常繁忙,经常没有时间准备健康的饮食,导致依赖外卖和速食。但我意识到这种饮食习惯对我的健康不利,因此希望能够通过一个为期一个月的营养食谱来改善饮食,让我能够过上更健康的生活。
Task: 我需要你为我设计一个为期一个月的营养食谱,包括每天的早餐、午餐、晚餐和健康零食。食谱中的食材和菜肴应该简单易做、营养丰富,确保五天内没有重复。最终的输出物应以表格的形式呈现,包括食谱安排、所需食材和食物准备方法,以便我能够轻松地执行并坚持这份健康饮食计划。
Reference
1. OpenAI官方指南
【推广时间】
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台,目前注册送20元测试金,可以畅享7小时4090算力,预装了主流的大模型和环境的镜像,开箱即用,非常方便。



















 4753
4753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











