







该示例为参考算法,仅作为在 征程 6 上模型部署的设计参考,非量产算法。
1.简介
激光雷达天然地具有深度信息,摄像头可以提供丰富的语义信息,它们是车载视觉感知系统中两个最关键的传感器。但是,如果激光雷达或者摄像头发生故障,则整个感知框架不能做出任何预测,这在根本上限制了实际自动驾驶场景的部署能力。目前主流的感知架构选择在特征层面进行多传感器融合,即中融合,其中比较有代表性的路线就是 BEV 范式。BEVFusion 就是典型的中融合方法,其存在两个独立流,将来自相机和 LiDAR 的原始输入编码为同一个 BEV 空间。由于是通用的融合框架,相机流和 LiDAR 流的方法都可以自由选择,在 nuScenes 数据集表现出了很强的泛化能力。本文将介绍 BEVFusion 在地平线 J6E/M 平台上的优化部署。
2.性能精度指标
模型参数:
| 模型 | 数据集 | Input shape | LiDAR Stream | Camera Stream | BEV Head | Occ Head |
|---|---|---|---|---|---|---|
| BEVFusion | Nuscenes | 图像输入:6x3x512x960点云输入:1x5x20x40000 | CenterPoint | BEVFormer | BEVFormerDetDecoder | BevformerOccDetDecoder |
性能精度表现:
| 浮点**精度** NDS | 量化精度 NDS | J6E | |
|---|---|---|---|
| Latency/ms | FPS | ||
| 0.6428 | 0.6352 | 135.64 | 30.95 |
3.公版模型介绍
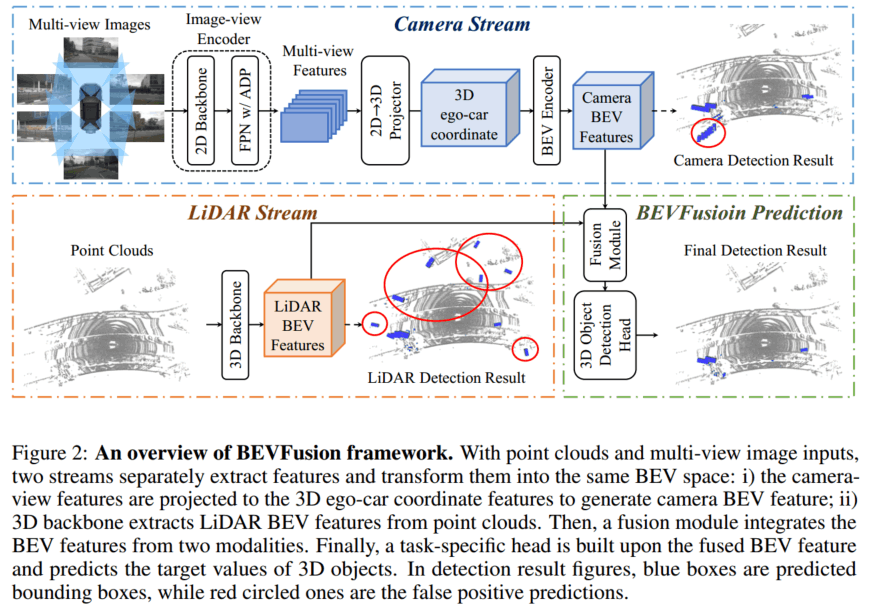
BEVFusion 主要由相机流、激光雷达流、动态融合模块和检测头组成,下面将逐一进行介绍。
3.1 相机流
相机流将多视角图像转到 BEV 空间,由图像编码器、视觉投影模块、BEV 编码器组成。
3.1.1 图像**编码器**
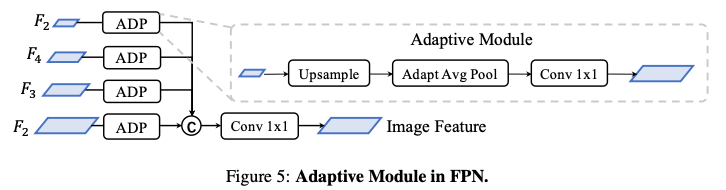
图像编码器旨在将输入图像编码为语义信息丰富的深度特征,它由用于基本特征提取的 2D backbone Dual-Swin-Tiny 和用于多尺度特征提取的 FPN 组成,并采用了一个简单的功能自适应模块 ADP 来完善上采样功能,如下图所示:
3.1.2 视觉投影模块
视觉投影模块采用 LSS 将图像特征转换为 3D 自车坐标,将图像视图作为输入,并通过分类方式密集地预测深度。
然后,根据相机外参和预测的图像深度,获取伪体素。
3.1.3 BEV 编码模块
BEV 编码模块采用空间到通道(S2C)操作将 4D 伪体素特征编码到 3D BEV 空间,从而保留语义信息并降低成本。然后又使用四个 3 × 3 卷积层缩小通道维度,并提取高级语义信息。
3.2 LiDAR 流
LiDAR 流将激光雷达点转换为 BEV 空间,BEVFusion 采用 3 种流行的方法,PointPillars、CenterPoint 和 TransFusion 作为激光雷达流,从而展示模型框架的优秀泛化能力。
3.3 动态融合模块
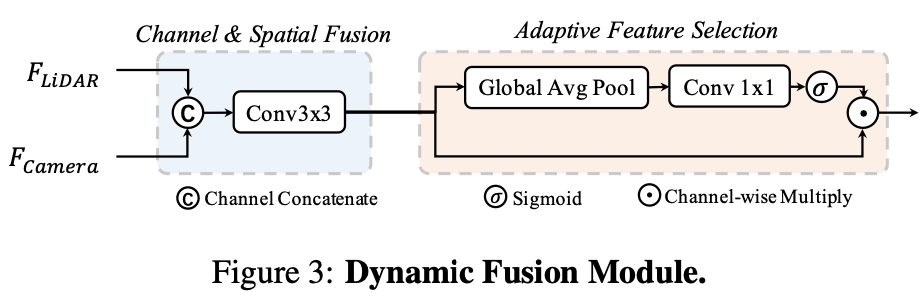
动态融合模块的作用是将 concat 后的相机、 LiDAR 的 BEV 特进行有效融合。受 Squeeze-and-Excitation 机制的启发, BEVFusion 应用一个简单的通道注意力模块来选择重要的融合特征,网络结构图如下所示:
4.地平线部署优化
地平线参考算法使用流程请参考附录《TCJ6007-J6 参考算法使用指南》;对应高效模型设计建议请参考附录《J6 算法平台模型设计建议
4.1 优化点总结
整体情况:
BEVFusion 参考算法采用 BEVFormer 和 centerpoint 分别生成视觉和 LiDAR BEV 特征,然后使用 SE 模型融合 BEV 特征,最后将 BEV 特征解码。
暂时无法在飞书文档外展示此内容
改动点:
相机流使用了地平线深度优化后的 bevformer 参考算法,并将其转换到 LiDAR 坐标系,其相对于公版的优化如下:
使用地平线深度优化后的高效 backbone HENet 提取图像特征;
将 attention 层的 mean 替换为 conv 计算,使性能上获得提升;
公版模型中,在 Encoder 的空间融合模块,会根据 bev_mask 计算有效的 query 和 reference_points,输出 queries_rebatch 和 reference_points_rebatch,作用为减少交互的数据量,提升模型运行性能。对于稀疏的 query 做 crossattn 后再将 query 放回到 bev_feature 中。;
修复了公版模型中时序融合的 bug,并获得了精度上的提升,同时通过对关键层做 int16 的量化精度配置以保障 1%以内的量化精度损失。
LiDAR 流采用了地平线深度优化后的 centerpoint 参考算法,其相对于公版的优化如下:
前处理部分的输入为 5 维点云并做归一化处理,对量化训练更加友好;
PillarFeatutreNet 中的 PFNLayer 使用 Conv2d + BatchNorm2d + ReLU,替换原有的 Linear + BatchNorm1d + ReLU,使该结构可在 BPU 上高效支持,实现了性能提升;
PillarFeatutreNet 中的 PFNLayer 使用 MaxPool2d,替换公版的 torch.max,便于性能的提升;
Scatter 过程使用 horizon_plugin_pytorch 优化实现的 point_pillars_scatter,便于模型推理优化,逻辑与 torch 公版相同;
对于耗时严重的 OP,采用 H、W 维度转换的方式,将较大维数放到 W 维度,比如 1x5x40000x20 转换为 1x5x20x40000;
相对于公版,增加了 OCC 任务头,实现了 LiDAR+Camera+OCC 动静态二网合一;
4.2 性能优化
4.2.1 相机流
公版 BEVFusion 使用流行的 Lift-Splat-Shoot(LSS)并适度调整以提高性能。参考算法直接采用了地平线深度优化后的 BEVFormer 参考算法作为相机流网络,bev 网格的尺寸配置为 128 x128。
改动点 1:
backbone 由公版的 Dual-Swin-Tiny 替换为地平线的高效 backbone HENet,不仅在精度上可与 ResNet50 相媲美,而且在性能上有显著优势。
HENet 是针对 征程 6 平台专门设计的高效 backbone,其采用了纯 CNN 架构,总体可分为四个 stage,每个 stage 会进行 2 倍下采样。以下为总体的结构配置:
depth = [4, 3, 8, 6]
block_cls = ["GroupDWCB", "GroupDWCB 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2868
2868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









