







实体识别(信息抽取)
1. 信息抽取概述
- 信息抽取定义:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。(Grishman,1997)
- 信息抽取的主要任务:实体识别与抽取、实体消歧、关系抽取、事件抽取
2. 信息抽取的基础:分词和词性标注
2.1中文分词
- 中文以字为基本书写单位,词语之间没有明显的区分标记
- 中文分词就是要由机器在中文文本中词与词之间加上标记。
- 和中文分词相比,英语切分问题相对容易。
2.2词性标注
- Part-of-speech(POS) tagging(词性标注):消除词性兼类歧义,即确定当前上下文每个词是名词、动词、形容词或其他词性的过程。
eg:名词和动词的兼类:爱好,把握,报道。
2.3中文分词的难点:
- 汉语中,字、词、词素和词组的界限模糊:吃饭、吃鱼、吃羊肉、吃羊肉串
- 歧义切分字段处理:
1.交集型歧义:对于汉字串ABC,AB,BC同时成词:研究生物,从小学起等
2.组合型歧义:对于汉字串AB,A、B、AB同时成词:门/把/手/弄/坏/了。门/把手/弄/坏/了。
3.真歧义:歧义字段在不同的语境中确实有多种切分形式:乒乓球拍/卖/完了。乒乓球/拍卖/完了。 - 未登录词(未登录词即没有被收录在分词词表中但必须切分出来的词)识别:
1.实体名词和专有名词:eg.中国人名,中国地名,翻译人名,翻译地名,机构名,商标字号。
2.专业术语和新词语:专业术语、缩略语、新词语。
2.4中文分词结果的评价:
- 封闭测试和开放测试
开方测试指的是测试样本不属于训练样本集合,否则称为封闭测试;
封闭测试相当于考试试题都出自于学习过的书本,实际上,通过机械记忆小样本的封闭测试取得100%的精度不存在问题。 - 专项测试和总体测试
专项测试是对特定领域或者特定类型的样本进行测试,反之成为总体测试。
总体测试能反映分词系统的综合效果,专项测试可以反映分词系统针对某个特定领域或者特定类型文本的效果。 - 评价指标:
真确率:测试结果中正确切分或标注的个数占系统所有输出结果的比例。P
召回率:测试结果中正确结果的个数占标准答案总数的比例。R
F值:正确率与召回率的综合值。
F 1 = 2 × P × R P + R F1 = \frac{2 \times P \times R}{P + R} F1=P+R2×P×R

2.5基于字典的分词方法
-
方法概述:按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
-
典型方法:
1.正向最大匹配法
2.反向最大匹配法
3.最短路径法(最少分词法) -
eg.
句子:中医治白癜风 词典:中、医、治、中医、医治、白癜风
正向最大匹配法:中医/治/白癜风
反向最大匹配法:中/医治/白癜风
最短路径法:
独立自主/和平/等/互利/的/原则
独立自主/和/平等互利/的/原则 -
正向最大匹配(Forward Maximum Matching, FMM)
1.令i=0,当前指针 P i P_i Pi指向输入字串的初始位置,执行下面的操作:
2.计算当前指针 P i P_i Pi到字串末端的字数(即未被切分字串的长度)n,如果n=1,转第4步,结束算法。否则,令m=字典中最长单词的字数,如果 n < m n<m n<m,令m=n;
3.从当前 P i P_i Pi起取m个汉字作为词 w i w_i wi,判断:
(1)如果 w i w_i wi确实是词典中的词,则在 w i w_i wi后添加一个切分标志,转(3);
(2)如果 w i w_i wi不是词典中的词且 w i w_i wi的长度大于1,将 w i w_i wi从右端去掉一个字,转(1)步;否则( w i w_i wi的长度等于1),则在 w i w_i wi后添加一个切分标志,将 w i w_i wi作为单字词添加到词典中,执行(3);
(3)根据 w i w_i wi的长度修改指针 P i P_i Pi的位置,如果 P i P_i Pi指向字串末端,转第4步,否则, i = i + 1 i = i + 1 i=i+1,返回(2);
4.输出切分结果,结束分词程序 -
最短路径法
1.相邻节点 V k − 1 , V k V_{k-1}, V_k Vk−1,Vk之间建立有向边 < V k − 1 , V k > <V_{k-1}, V_k> <Vk−1,Vk>,边对应的词默认为 C k ( k = 1 , 2 , . . . , n ) C_k (k = 1, 2, ..., n) Ck(k=1,2,...,n)。
2.如果 w = C i C i + 1 . . . C j ( 0 < i < j < = n ) w = C_i C_{i+1}... C_{j} (0<i<j<=n) w=CiCi+1...Cj(0<i<j<=n)是一个词,则节点 V i − 1 , V j V_{i-1},V_j Vi−1,Vj之间建立有向边 < V i − 1 , V j > <V_{i-1}, V_j> <Vi−1,Vj>,边对应的词为w。

3.重复步骤2,直到没有新路径(词序列)产生。
4.从产生的所有路径中,选择路径最短的(词数最少的)作为最终分词结果。
2.6基于统计的分词方法
基于统计的方法需要标注训练语料训练模型,可分为生成式统计分词和判别式统计分词
2.6.1 生成式方法
原理:首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理。
马尔可夫模型
存在一类重要的随机过程(马尔可夫过程):如果一个系统有N个状态
S
1
,
S
2
,
.
.
.
,
S
N
S_1, S_2, ..., S_N
S1,S2,...,SN,随着时间的推移,该系统从某一个状态转移到另一状态。如果用
q
t
q_t
qt表示系统在时间t的状态变量,那么t时刻的状态取值为
S
j
(
1
<
=
j
<
=
N
)
S_j (1<=j<=N)
Sj(1<=j<=N)的概率取决于前t-1个时刻的状态,该状态的概率为:
P
(
q
t
=
S
j
∣
q
t
−
1
=
S
i
,
q
t
−
2
=
S
k
,
.
.
.
)
P(q_t = S_j | q_{t-1} = S_i, q_{t-2} = S_k, ...)
P(qt=Sj∣qt−1=Si,qt−2=Sk,...)
-
假设1:一阶马尔可夫假设
如果在特定情况下,系统在时间t的状态只与其在时间t-1的状态相关,则该系统构成一个离散的一阶马尔可夫链。
P ( q t = S j ∣ q t − 1 = S i , q t − 2 = S k , . . . ) = P ( q t = S j ∣ q t − 1 = S i ) P(q_t = S_j | q_{t-1} = S_i, q_{t-2} = S_k, ...) = P(q_t = S_j | q_{t-1} = S_i) P(qt=Sj∣qt−1=Si,qt−2=Sk,...)=P(qt=Sj∣qt−1=Si) -
假设2:不动性假设
如果只考虑上述公式独立于时间t的随机过程,状态与时间无关,那么:
P ( q t = S j ∣ q t − 1 = S i ) = a i j , 1 < = i , j < = N P(q_t = S_j | q_{t-1} = S_i) = a_{ij}, \quad\quad 1<=i,j<=N P(qt=Sj∣qt−1=Si)=aij,1<=i,j<=N
a i j > = 0 ∑ j = 1 N a i j = 1 a_{ij}>=0 \quad\quad\quad \sum_{j=1}^N a_{ij} = 1 aij>=0j=1∑Naij=1 -
马尔可夫模型状态表示:马尔可夫链可以表示成状态图(转移弧上有概率的非确定的有限状态自动机)
- 零概率的转移弧省略
- 每个节点上所有发生弧的概率之和等于1

-
马尔可夫模型状态序列的概率
状态序列 S 1 , . . . , S T S_1, ..., S_T S1,...,ST的概率:
P ( S 1 , . . . , S T ) = P ( S 1 ) P ( S 2 ∣ S 1 ) P ( S 3 ∣ S 1 , S 2 ) . . . P ( S T ∣ S 1 , . . . , S T − 1 ) P(S_1, ..., S_T) = P(S_1)P(S_2 | S_1)P(S_3 | S_1, S_2) ... P(S_T | S_1, ..., S_{T-1}) P(S1,...,ST)=P(S1)P(S2∣S1)P(S3∣S1,S2)...P(ST∣S1,...,ST−1)
一 阶 马 尔 可 夫 假 设 = P ( S 1 ) P ( S 2 ∣ S 1 ) P ( S 3 ∣ S 2 ) . . . P ( S T ∣ S T − 1 ) 一阶马尔可夫假设 = P(S_1)P(S_2 | S_1)P(S_3 | S_2) ... P(S_T | S_{T-1}) 一阶马尔可夫假设=P(S1)P(S2∣S1)P(S3∣S2)...P(ST∣ST−1)
不 动 性 假 设 = π S 1 ∏ t = 1 T − 1 a S t S t + 1 不动性假设 = \pi_{S_1}\prod_{t=1}^{T-1} a_{S_t S_{t+1}} 不动性假设=πS1∏t=1T−1aStSt+1其中, π = P ( q 1 = S i ) \pi = P(q_1 = S_i) π=P(q1=Si)为初始状态的概率。

隐马尔可夫模型 -
隐马尔可夫模型是关于时序的概率模型,是一个双重随机过程。其描述由一个隐藏的马尔可夫链随机生成不可观察的状态随机序列,再由各个状态生成一个观察,从而产生随机观察序列的过程,序列的每一个位置又可以看作是一个时刻。
-
wiki定义:隐马尔可夫模型是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
-
示例:
房间里有N个盒子,每个盒子中有M种不同颜色的球。一实验员进入房间根据某一概率分布选择一个盒子,然后根据盒子中不同颜色球的概率分布随机取出一个球,并向房间外的人报告该球的颜色。
对房间外的人:可观察的过程是不同颜色球的序列,而盒子的序列是不可观察的。
每只盒子对应HMM中的一个状态;球的颜色对应于HMM中状态的输出。

-
图解

-
HMM的组成
- 状态集合:模型中的状态数为N(盒子的数量)
- 观察集合:从每一个状态可能输出的不同的符号数M(不同颜色球的数目)
- 状态转移概率矩阵:
A
=
a
i
j
A = a_{ij}
A=aij(
a
i
j
a_{ij}
aij为实验员从一个盒子(状态
S
i
S_{i}
Si)转向另一个盒子(状态
S
j
S_{j}
Sj)取球的概率)。其中:
A = [ a i j ] N × N A = [a_{ij}]_{N \times N} A=[aij]N×N
a i j = P ( q t + 1 = S j ∣ q t = S i ) i = 1 , 2 , . . . , N ; j = 1 , 2 , . . . , N a_{ij} = P(q_{t+1} = S_j | q_t = S_i) \quad\quad i = 1,2,...,N; j = 1,2,...,N aij=P(qt+1=Sj∣qt=Si)i=1,2,...,N;j=1,2,...,N
a i j > = 0 ∑ j = 1 N a i j = 1 a_{ij}>=0 \quad\quad \sum_{j=1}^N a_{ij} = 1 aij>=0j=1∑Naij=1 - 观察概率矩阵B,处于状态
S
i
S_i
Si的条件下生成观察
v
k
v_k
vk的概率:
B = [ b j ( k ) ] N × N B = [b_j(k)]_{N \times N} B=[bj(k)]N×N
b j ( k ) = P ( o t = v k ∣ q t = S j ) k = 1 , 2 , . . . , M ; j = 1 , 2 , . . . , N b_j(k) = P(o_t = v_k | q_t = S_j) \quad\quad k = 1,2,...,M; j = 1,2,...,N bj(k)=P(ot=vk∣qt=Sj)k=1,2,...,M;j=1,2,...,N
b j ( k ) > = 0 ∑ k = 1 M b j ( k ) = 1 b_j(k) >= 0 \quad\quad \sum_{k=1}^{M} b_j(k) = 1 bj(k)>=0k=1∑Mbj(k)=1 - 初始状态的概率分布
π
\pi
π:
π i = P ( q 1 = S i ) , i = 1 , 2 , . . . , N \pi_i = P(q_1 = S_i), \quad\quad i = 1,2,...,N πi=P(q1=Si),i=1,2,...,N
π i > = 0 , ∑ i = 1 N π i = 1 \pi_i >= 0, \quad\quad \sum_{i=1}^{N} \pi_i = 1 πi>=0,i=1∑Nπi=1
-
假设
- 参数集合
为了方便,一般将HMM记为: μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)或者 μ = ( S , O , A , B , π ) \mu = (S, O, A, B, \pi) μ=(S,O,A,B,π) - 基本假设
一阶马尔可夫性假设:隐马尔可夫链t的状态只和t-1状态有关

观察独立性假设:观察值和当前时刻状态有关:

- 参数集合
-
生成观察序列
- 给定模型
μ
=
(
A
,
B
,
π
)
\mu = (A, B, \pi)
μ=(A,B,π),生成观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT
(1)令t=1
(2)按照初始状态分布 π \pi π产生状态 q 1 = S i q_1 = S_i q1=Si
(3)按照状态 S t S_t St的观察概率 b i ( k ) b_i(k) bi(k)分布生成 o t o_t ot
(4)按照状态 S t S_t St的状态转移概率 a i j {a_{ij}} aij分布产生状态 q t + 1 = S j q_{t+1} = S_j qt+1=Sj
(5)令t = t+1;如果t<T,转步骤(3);否则,终止
- 给定模型
μ
=
(
A
,
B
,
π
)
\mu = (A, B, \pi)
μ=(A,B,π),生成观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT
-
三个问题:
- 概率计算问题:在给定模型 μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)和观察序列 O = O 1 O 2 . . . O T O = O_1 O_2 ... O_T O=O1O2...OT的情况下,怎样快速计算概率 P ( O ∣ μ ) P(O | \mu) P(O∣μ)?
- 预测问题:在给定模型 μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)和观察序列 O = O 1 O 2 . . . O T O = O_1 O_2 ... O_T O=O1O2...OT的情况下,如何选择在一定意义下“最优”的状态序列 Q = q 1 q 2 . . . q T Q = q_1 q_2 ... q_T Q=q1q2...qT,使得该状态序列“最好地解释”观察序列 O = O 1 O 2 . . . O T O = O_1 O_2 ... O_T O=O1O2...OT?
- 学习问题:给定一个观察序列 O = O 1 O 2 . . . O T O = O_1 O_2 ... O_T O=O1O2...OT,如何根据最大似然估计求模型的参考值?即如何调节模型 μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)的参数,使得 P ( O ∣ μ ) P(O | \mu) P(O∣μ)最大?
-
1. 概率计算问题
对于给定的状态序列 Q = q 1 q 2 . . . q T Q = q_1 q_2 ... q_T Q=q1q2...qT,求 P ( O ∣ μ ) P(O | \mu) P(O∣μ)?

在公式里,我们需要遍历所有满足条件的Q,即遍历所有路径。
一阶马尔可夫假设:
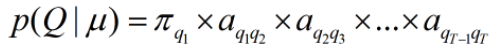
观察独立假设:
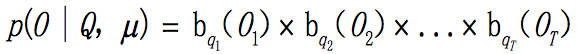

可以看出,如果模型 μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)有N个不同的状态,时间长度为T,那么有 N T N^T NT个可能的状态序列,搜索路径成指数级组合爆炸。
可以通过动态规划,利用地推算法提高计算效率 -
概率计算问题——前向算法


-
前向算法计算过程:
- 初始化:
α 1 ( i ) = π i b i ( O 1 ) , 1 < = i < = N \alpha_1(i) = \pi_i b_i(O_1), \quad 1<=i<=N α1(i)=πibi(O1),1<=i<=N - 循环计算:
α t + 1 ( j ) = [ ∑ i = 1 N α t ( i ) α i j ] × b j ( O t + 1 ) , 1 < = t < = T − 1 \alpha_{t+1}(j) = [\sum_{i=1}^{N} \alpha_t(i)\alpha_{ij}] \times b_j(O_{t+1}), \quad 1<=t<=T-1 αt+1(j)=[∑i=1Nαt(i)αij]×bj(Ot+1),1<=t<=T−1 - 结束,输出:
P ( O ∣ μ ) = ∑ i = 1 N α T ( i ) P(O | \mu) = \sum_{i=1}^{N}\alpha_T(i) P(O∣μ)=∑i=1NαT(i)
- 初始化:
-
算法的时间复杂性:

递推计算中,每一次计算可以直接饮用前一个时刻的计算结果,避免了重复计算。
-
-
示例
共有3个盒子,每个盒子里分别有红、白两种球,对应的状态转移概率矩阵、观察概率矩阵和初始状态概率分布如下所示:

(1)计算前向向量的初值:
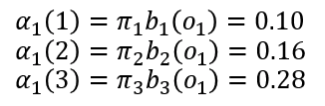
(2)递推计算:

(3)终止:
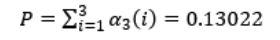
-
概率计算问题——后向算法



-
后向算法——算法描述
- 初始化:
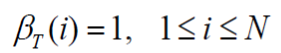
- 循环计算:
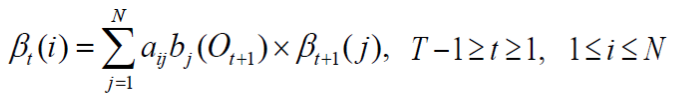
- 结束:
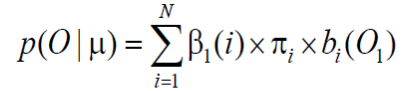
- 时间复杂度:
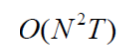
- 初始化:
-
2. 隐马尔可夫模型——预测问题
- 预测问题:在给定模型
μ
=
(
A
,
B
,
π
)
\mu = (A, B, \pi)
μ=(A,B,π)和观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT的情况下,如何选择在一定意义下“最优”的状态序列
Q
=
q
1
q
2
.
.
.
q
T
Q = q_1 q_2 ... q_T
Q=q1q2...qT,使得该状态序列“最好地解释”观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT?

- 关于“最优”,有两种解释。
- 一种解释:状态序列中的每个状态都单独地具有概率,针对每个时刻t都找到具有最大概率的状态,顺序连接每个时刻具有最大概率的状态,进而得到最优状态序列。(该解释可能存在的问题是:每一个状态单独最优不一定使整体的状态序列最优,额能两个最优的状态之间的转移概率为0。)
- 另一种解释:不单独考虑每个时刻的状态,而是考虑到达t时刻的状态序列的概率,从不同的状态序列中找到具有最大概率的状态序列,呢绒得到最优状态序列。
- 预测问题:在给定模型
μ
=
(
A
,
B
,
π
)
\mu = (A, B, \pi)
μ=(A,B,π)和观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT的情况下,如何选择在一定意义下“最优”的状态序列
Q
=
q
1
q
2
.
.
.
q
T
Q = q_1 q_2 ... q_T
Q=q1q2...qT,使得该状态序列“最好地解释”观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1 O_2 ... O_T
O=O1O2...OT?
-
针对第二种解释,可使用Viterbi 算法:动态搜索最优状态序列

-
Viterbi算法


-
示例:




-
3. 隐马尔科夫模型——学习问题
- 学习问题:给定一个观察序列 O = O 1 O 2 . . . O T O = O_1 O_2 ... O_T O=O1O2...OT,如何根据最大似然估计求模型的参考值?即如何调节模型 μ = ( A , B , π ) \mu = (A, B, \pi) μ=(A,B,π)的参数,使得 P ( O ∣ μ ) P(O | \mu) P(O∣μ)最大?
-
有监督学习的方法:假设训练数据是包括观测序列O和对应的状态序列Q,则可以利用最大似然估计来计算模型的参数。


-
无监督学习方法
- 假设训练数据中只包括观测序列O,没有对应的状态序列Q,此时只能利用期望值最大化算法(Expectation-Maximizatiion,EM)
- 基本思想:初始化时随机地给模型的参数赋值(遵循限制规则,如:从某一状态处罚的转移概率总和为1,得到模型
μ
0
\mu_0
μ0),然后可以从
μ
0
\mu_0
μ0得到从某一状态转移到另一状态的期望次数,然后以期望次数代替公式中的次数,得到模型参数的新估计,由此得到新的模型
μ
1
\mu_1
μ1,从
μ
1
\mu_1
μ1又可得到模型中隐变量的期望值,由此重新估计模型参数。循环这一过程,收敛于最大似然估计值。

-
无监督学习方法
- 定义:给定模型
μ
\mu
μ和观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1O_2...O_T
O=O1O2...OT,那么,在时间t位于状态
S
i
S_i
Si,时间t+1位于状态
S
j
S_j
Sj的概率:



- 定义:给定模型
μ
\mu
μ和观察序列
O
=
O
1
O
2
.
.
.
O
T
O = O_1O_2...O_T
O=O1O2...OT,那么,在时间t位于状态
S
i
S_i
Si,时间t+1位于状态
S
j
S_j
Sj的概率:
-
Baum-Welch算法(前向后向算法)描述:
- 初始化:随机地给
π
i
,
a
i
j
,
b
j
(
k
)
\pi_i, a_{ij}, b_j(k)
πi,aij,bj(k)赋值

由此得到模型 μ 0 \mu_0 μ0,令i = 0. - 执行EM算法:

- 初始化:随机地给
π
i
,
a
i
j
,
b
j
(
k
)
\pi_i, a_{ij}, b_j(k)
πi,aij,bj(k)赋值
-
生成式方法的优缺点:
- 优点:
















 9310
9310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











