







实体识别(信息抽取)
2. 信息抽取的基础:分词和词性标注
2.6基于统计的分词方法
基于统计的方法需要标注训练语料训练模型,可分为生成式统计分词和判别式统计分词
2.6.1 生成式方法
- 生成式方法优缺点
- 优点:在训练语料规模足够大和覆盖领域足够多的情况下,可以获得较高的切分正确率
- 缺点:训练语料的规模和覆盖领域不好把握。模型实现复杂、计算量较大。
2.6.2 判别式方法
-
原理:在有限样本条件下建立对于预测结果的判别函数,直接对预测结果进行判别。由字构词的分词理念,将分词问题转化为判别式分类问题。
-
典型算法:Maxent SVM CRF Perceptron
-
分词流程:
- 把分词问题转化为确定居中每个字在词中位置问题
- 每个字在词中可能的位置可以分为以下四种:词首(B),词中(M),词尾(E),独字(S)。
-
分词结果展示
- 分词结果:毛/B新/M年/E2/B0/M0/M0/M年/E毕/B业/E于/S东/B北/M大/M学/E
-
最大熵模型
-
最大熵理论:
- 在无外力作用下,事物总是朝着最混乱的方向发展
- 事物是约束和自由的统一体
- 事物总是在约束下争取最大的自由权,这其实也是自然界的根本原则
- 在已知条件下,熵最大的事物,最可能接近它的真实状态
-
基于最大熵原理的模型选择
- 任务:研究某个随机事件,根据已知信息,预测其未来行为。
- 方法:当无法获得随机事件的真实分布时,构造统计模型对随机事件进行模拟。
- 难点:满足已知信息要求的模型可能有很多个,用哪个模型来预测最合适呢?
- 原则熵最大的模型
- Jaynes证明:对随机事件的所有相容的预测中,熵最大的预测出现的概率占绝对优势
- Tribus证明:正态分布、伽玛分布、指数分布等,都是最大熵原理的特殊情况。

-
最大熵模型:天气预报
假设要用今天的天气预测明天的天气。- 天气 ∈ \in ∈{晴、阴、雨}
- 风向 ∈ \in ∈{无、南、北}
- 已知今天的天气和风向,要预测明天的天气
-
样本数据如下所示:

-
问题定义:

-
建模
- 建立天气预报模型:给出所有可能的条件下结论的概率 P ( β ∣ α ) , α ∈ A , β ∈ B P(\beta | \alpha),\alpha \in A,\beta \in B P(β∣α),α∈A,β∈B
- 为简化问题,通常用联合概率模型取代上述的条件概率模型 P ( α , β ) P(\alpha,\beta) P(α,β)
- 二者关系: P ( β ∣ α ) = P ( α , β ) / P ( α ) P(\beta | \alpha) = P(\alpha, \beta)/P(\alpha) P(β∣α)=P(α,β)/P(α)
- 由于条件和结论都是离散量,理论上,所有的可能性是可以穷举的,因此只要给出所有可能性的概率即可。

-
上述模型需要满足以下两个条件:
- 模型的概率分布应尽可能与样本一致

- 模型的熵最大
- 模型的概率分布应尽可能与样本一致
-
优化目标:
- X熵最大:可以表示为:

- 实际上,A(预测的条件)的可能性数量可能极其巨大,穷举所有可能性是不现实的,如何对任意的条件和结论给出其概率?以及如何表示X的分布于已知样本的分布一致这个问题?
- X熵最大:可以表示为:
-
引入特征
- 实际问题中,由于条件 α \alpha α和结果 β \beta β取值多样化,为模型表示方便,通常将条件和结果表示为一些二制特征
- 特征
f
1
,
f
2
,
.
.
.
,
f
n
f_1,f_2,...,f_n
f1,f2,...,fn定义如下:
f i : ε − > 0 , 1 , ε = A ( 预 测 条 件 ) × B ( 结 论 ) f_i : \varepsilon ->{0, 1}, \varepsilon = A(预测条件) \times B(结论) fi:ε−>0,1,ε=A(预测条件)×B(结论) - 这样每个时间都可以表示为一个由特征值{0,1}组成的n维向量,不再直接用条件和结论来描述。
-
引入约束
- “模型分布与样本分布一致”可以描述为:
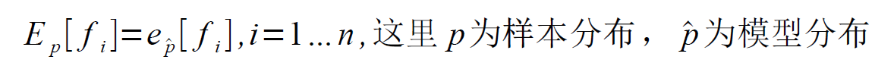
这个公式含义为:对于任何一个特征,模型和样本应该具有相同的均值(即,根据样本数据统计各种出现的次数)。由于特征取值只有{0,1},因此这个公式实质上可以理解为:模型中任何一个特征为1的概率与样本应相同。
- “模型分布与样本分布一致”可以描述为:
-
为天气预报引入以下简单特征:

-
用简单特征表示样本:样本表示

-
用简单特征表示样本:建模目标(模型能预测所有的可能,并给出概率)

-
利用上述简单特诊个,采用最大熵原理为天气预报建模,得到的模型是:

而这个模型并不是我们想要的模型,我们需要得到的是类似于下面这样的模型:- 模型中“昨天天气为晴”的情况下今天各种天气的概率与样本一致
-
符合特征(组合特征)
- 为了使得到的模型满足我们所期望的约束条件,可以重新定义特征:

- 按照这种方式定义特征,那么所有的特征都反映了某种预测条件和结果之间的依赖关系,这样得到的模型才是我们所期望的模型

- 为了使得到的模型满足我们所期望的约束条件,可以重新定义特征:
-
模型应用
- 假设我们已经得到一个满足上述约束条件且熵最大的模型,如何预测天气?
- 给定预测条件 α \alpha α(今天天气和今天风向),需要预测明天天气 β ∈ \beta \in β∈{晴、阴、雨},我们只要根据模型分别将 ( α , 晴 ) / ( α , 阴 ) / ( α , 雨 ) (\alpha,晴)/(\alpha,阴)/(\alpha,雨) (α,晴)/(α,阴)/(α,雨)转化为特征值,然后根据模型计算出相应的概率,取概率最大者即可。
-
最优化:学习过程
- 根据前面的定义,最大熵模型的参数估计可以表示为一个约束条件下的极值问题



- 根据前面的定义,最大熵模型的参数估计可以表示为一个约束条件下的极值问题
-
判别式方法优缺点
- 优点:分词精度高,新词识别率较高
- 缺点:训练速度慢,性能与特征紧密相连,需要人工标注训练语料。
-
当前分词技术存在的主要问题
- 训练语料规模小:分词模型过于依赖训练样本,而标注大规模训练样本费时费力,由此导致分词系统对新词的识别能力差,往往在与训练样本差异较大的测试集上性能大幅度下降
- 训练语料领域少:现有的训练样本主要在新闻领域,而实际应用千差万别。
- 对实体和专有名词的识别性能较低。
3. 命名实体识别
-
命名实体的定义
- 狭义的讲,命名实体指现实世界中具体或抽象的实体。如人、机构、地点等,通常用唯一的标识符(专有名称)表示。
- 广义地讲,命名实体还可以包含时间、日期、数量表达式(100)、金钱(一亿人民币)等。
-
命名实体识别的任务
- 一般而言,主要是识别出待处理文本中七类(人名、机构名、地名、时间、日期、货币和百分比)命名实体
- 两个子任务:实体边界识别和确定实体识别
- 实体识别的任务中,人名、地名、机构名的用字灵活,识别的难度较大
-
人名识别
- 英文人名识别已有很好的研究,其本身具有一些明显的特征,切分造成的错误很少。
- 中文识别存在比较多难点:
- 名字用字范围广,分布松散,规律不很明显
- 姓氏和名字都可以单独使用用于特指某一人(eg.王二小,小王,二小)
- 许多姓氏用字和名字用字可以作为普通用字或词被使用。
- 缺乏可利用的启发标记(人名与上下文组合成词)(eg.祝贺老总百战百胜)
- 中国人名一般由姓、名、前缀(老王)、后缀(王总)部分组合而成。
- 中国人名各组成部分用字比较有规律:姓氏中使用频度最高的前400个姓氏覆盖率达到99%,名字中用字使用频度最高的前400个字的覆盖率达到90%
- 人名各组成部分的组合规律:姓+名,姓,名,前缀+姓,姓+后缀,姓+姓+名
- 人名的上下文构成规律:身份词
- 前:工人、教师、影星
- 后:先生、同志
- 前后:女士、教授、经理、小姐、总理
-
中文地名的识别
- 难点:地名数量大,缺乏明确、规范的定义;真实语料中地名出现情况复杂(地名简称、地名 用词与其它普通词冲突、地名是其它专用名词的一部分、地名长度不一)
-
中文机构名识别
- 难点:机构名中含有大量的人名、地名、企业字号等专有名称;用词广泛;机构名长度极其不固定;机构名很不稳定。
-
命名实体识别的方法:
- 有词典切分/无词典切分:在分词的过程中使用词典的方法是有词典切分,反之是无词典切分,有词典切分的方法一般是基于规则的,无词典切分的方法一般是基于统计的
- 基于规则的方法/基于统计的方法:基于规则的方法不需要标注训练语料,能直接根据词典和规则进行分词,基于统计的方法需要标注训练语料训练模型。基于统计的方法可以分为生成式统计命名实体识别和判别式命名实体识别。
-
基于字典的命名实体识别方法
- 按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
- 典型方法:正向、反向最大匹配法,最短路径法。(与之前的分词方法类似)
-
基于统计的命名实体识别方法
- 生成式方法
- 原理:首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理
- 典型算法:HMM,PCFG(概率上下文无关文法)等
- 判别式方法
- 原理:由字构词的命名实体识别理念,将NER(命名实体识别)问题转化为判别式分类问题(序列标注问题)
- 典型算法:Maxent,SVM,CRF,CNN,RNN,LSTM+CRF
- 生成式方法
-
条件随机场(CRF)
- 定义:条件随机场(Conditional Random Field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。
- 特点:假设输出随机变量构成马尔可夫随机场
- 应用:可以应用于不同类型的标注问题,例如:单个目标的标注、序列结构的标注、图结构的标注
- 自然语言处理的很多任务可以转化为序列结构的标注问题。
- 条件随机场的三个基本问题:概率计算问题、解码问题、学习问题。
-
概率无向图模型
- 图是由节点及连接节点的边组成的集合。结点和边分别记作v和e,结点和边的集合分别记作V和E,图记作G=(V,E)
- 概率图模型是由图表示的概率分布:设有联合概率分布P(Y),Y是一组随机变量。由图G=(V,E)表示概率分布P(Y),即在图G中,一个结点v表示一个随机变量 Y v Y_v Yv,边e表示随机变量之间的概率依赖关系。
- 概率图模型可分为概率有向图模型(例如隐马尔可夫模型)和概率无向图模型(例如条件随机场模型)。
-
概率无向图模型:成对马尔可夫性
- 任意没有直接相连的一对结点,在给定O的条件下互相独立
- 设u和v是无向图G中任意两个没有连接的结点,结点u和v分别对应随机变量
Y
u
和
Y
v
Y_u和Y_v
Yu和Yv。其它所有结点为O,对应的随机变量组是
Y
o
Y_o
Yo,成对马尔可夫性是指给定随机组
Y
o
Y_o
Yo的条件下是
Y
u
和
Y
v
Y_u和Y_v
Yu和Yv条件独立的

-
局部马尔可夫性
- 任意一个结点与所有不与他直接相连的结点,在给定的条件下相互独立。

- 任意一个结点与所有不与他直接相连的结点,在给定的条件下相互独立。
-
全局马尔可夫性
- 被结点集合O分开的任意两个结点集合A和B,在给定O的条件下相互独立

- 被结点集合O分开的任意两个结点集合A和B,在给定O的条件下相互独立
-
马尔可夫随机场
- 如果概率无向图模型的联合概率分布P(Y)满足三种马尔可夫性(成对、局部、全局),就称此联合概率分布为马尔可夫随机场。
- 对给定的马尔可夫随机场模型,希望将整体的联合概率写成若干子联合概率的乘积的形式,也就是将联合概率进行因子分解。
-
因子分解
- 团(clique):无向图G中任何两个结点均为有边连接的结点子集称为团
- 最大团:若C是无向图G的一个团,并且不能再加任何一个c的结点使其成为一个更大的团,则称此C为最大团
- 示例:

- 将马尔可夫随机场模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为马尔可夫随机场模型的因子分解。
- 给定马尔可夫随机场模型,设其无向图为G,C为G上的最大团,
Y
c
Y_c
Yc表示C对应的随机变量,那么马尔可夫随机场模型的联合概率分布P(Y)可写作图中所有最大团C上的函数
Ψ
c
(
Y
c
)
\Psi_c(Y_c)
Ψc(Yc)的乘积形式,即:

- Z是归一化因子:

-
条件随机场
- 定义:设X与Y是随机变量,P(X|Y)是在给定X的条件下Y的条件概率分布。若随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场,则称条件概率分布P(X|Y)为条件随机场。

其中w~v表示在图G中与结点v有边连接的所有结点w, w ≠ v w \not= v w=v表示结点v意外的所有结点。
- 定义:设X与Y是随机变量,P(X|Y)是在给定X的条件下Y的条件概率分布。若随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场,则称条件概率分布P(X|Y)为条件随机场。
-
线性链条件随机场

- 图示:

在标注问题中,X表示输入观察序列,Y表示对应的输出标记序列或状态序列。
这块涉及到蛮多繁琐的公式推导,后面慢慢再补充吧。
- 图示:
4. 开放域实体识别
-
开放类别实体抽取:
- 不限定实体类别
- 不限定目标文本
- 任务:给定某一类别的实体实例,从网页中抽取同一类别其他实体实例
例如,<中国、美国、俄罗斯>作为输入,称为“种子”,找出其他国家<日本、德国、韩国、英国、法国。。。>
-
开放类别实体抽取:主要方法
- 基本思路:种子词与目标词在网页中具有相同或者类似的上下文
- 种子词——>模板
- 模板——>更多同类实体
- 处理实例扩展问题的主流框架
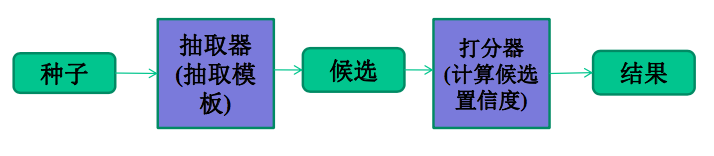
- 利用不同数据源(例如查询日志、网页文档、知识库文档等)的不同特点,设计方法。
- 基本思路:种子词与目标词在网页中具有相同或者类似的上下文
-
Query Log问题
- 通过分析种子实例在查询日志中的上下文学得模板,再利用模板找到同类别的实例
- 构造候选与种子上下文向量,计算相似度。

-
Web Page问题
- 动机
- 处理列表型网页
- 在列表中,种子与目标实体具有相同的网页结构

- 系统框架

- 爬取模块(Fetcher):把种子送到搜索引擎,把返回的前100个网页抓取下来作为语料
- 抽取模块(Extractor):针对单个网页学习模板,再使用模板抽取候选实例
- 排序模块(Ranker):利用种子、网页、模板、候选构造一个图,综合考虑网页和模板的质量,使用Random Walk算法为候选打分并排序。
- 动机
-
融合多个数据源的方法(Pennacchiotti EMNLP 2009)
- 针对不同数据源,选取不同特征分别进行实例扩展,对结果进行融合
- 针对不同数据源选取不同的模板和特征
- 使用不同特征计算候选的置信度
- 结果融合
















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











