






▐ 摘要
在深度推荐模型中,ID类特征的表示学习是至关重要的。其中,每一个特征值将会被映射成一个特征向量。对于同一个特征域的不同特征值,传统的特征表示学习方法会固定对应特征向量的维度大小。这样设置统一维度的模式对于表示学习以及对应向量存储而言,都是次优的。尽管,现有方法尝试从基于规则或网络搜索的角度去解决这个问题,这些方法需要额外的人工知识或者不易训练,且对于特征向量的热启动也不友好。因此,在本文中,我们提出一种新颖并且高效的特征维度选择方法。具体而言,我们在每一个表示层后面,设计了一个自适应孪生掩码层(AMTL)来去除每一个特征向量中不需要的维度。这样一种掩码的方式能够灵活的应用在各个模型中,很好的支持了模型特征向量的热启动。大量实验结果表明,所提方法在模型精度上相比于其他方法取得了最好的效果,且同时节省了60%存储开销。目前,该工作已被 CIKM 2021 接收。
论文下载:
https://arxiv.org/pdf/2108.11513.pdf
▐ 1. 背景
近年来,基于深度学习的推荐模型(DLRMs)被广泛的应用在各个 web 级系统中[1-4]。在 DLRMs 中,最重要的一个模块就是 embedding layer 。其将每一个ID类特征值映射到 embedding 空间,来对该特征进行表征学习。具体来讲,给定一个特征域,对应的词典大小为(即特征值的 unique 数),embedding layer 将每一个特征值通过 embedding 矩阵映射成一个 embedding 向量[1,2],其中为预定义的 embeddig 向量的维度。
然而,这样一种对同一特征域的所有特征值赋予相同 embedding 维度的 embedding 学习方法存在着两大问题:
效果: 在很多应用中,同一特征域的不同特征值的出现频率大不相同。比如高频特征,我们需要给予更多的 embedding 维度使其能够表达更丰富的信息。同时对于低频特征,太大的 embedding 维度,反而会有过拟合的风险。因此对于所有特征值赋予固定的统一的 embedding 维度会低估 embedding 学习的能力。模型的效果处于一个次优状态。
存储: 存储这样一个固定 embedding 维度的矩阵会带来巨大的存储开销[5,6,7]。需要一个更加灵活的 embedding 维度调整策略来减少存储开销。
现有的学习不固定 embedding 维度的方法,大体可以分为两类:
基于规则的方法 [8]: 该方法采用人工规则的方式,根据特征的不同频率给予不同的 embedding 维度(如图1(b)所示)。这样一种方法最大的问题是强依赖于人工经验,并且设置的 embedding 维度较为粗糙,往往效果不佳。
基于神经网络搜索(NAS)的方法[9,10,11,12]: 该方法预先设置候选维度,然后通过 NAS 的搜索为每一个特征值寻找一个合适的特征维度(如图1(c)所示)。这类方法需要精心设计搜索空间和训练特征,并且搜索空间经常被局限于离散的 embedding 维度候选集。
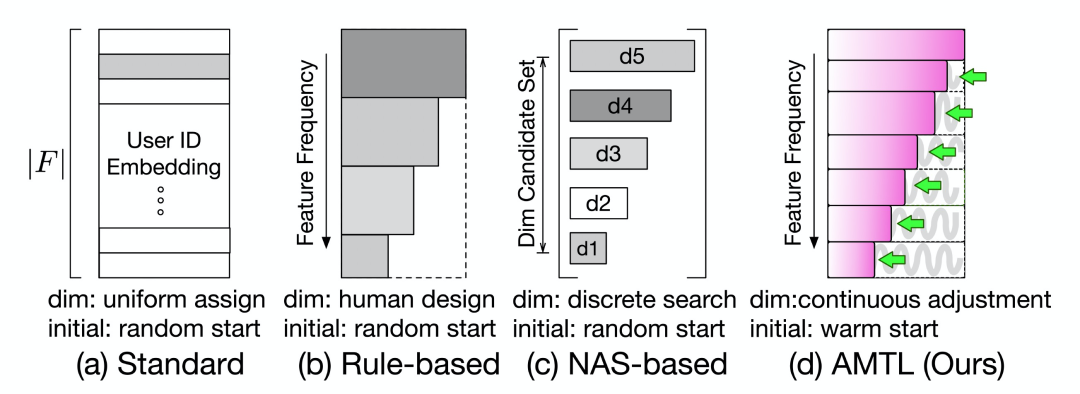
此外,上述两类方法均只能从头开始训练,不支持热启动。然而在现实的应用中,线上往往已经服务着一个训练了很久的深度学习模型。对应的 embedding 矩阵已经被训练的相对充分。如果能够利用该 embedding 矩阵蕴含的信息,就可以很好的热启动不固定维度的 embedding 学习。然而,现有的方法都不能够很好的支持这样一种热启动的模式。
在本文中,我们提出一种新颖并且高效的为每一个特征值选择合适的 embedding 维度的方法。其核心想法是在 embedding layer 之后增加一个 Adaptively-Masked Twins-based Layer (AMTL)。这样一个 layer 可以自适应的学习出一个掩码(mask)向量来去除掉对应 embedding 中不需要的维度。经过掩码后的embedding向量可以被看成是一个拥有自适应维度的 embedding,然后被送到下一层进行前向计算。这样一种方法可以带来三个好处:
embedding 的学习是高效的。因为 embedding 的维度可以在一个连续的整数空间进行选择,并且不需要额外的人工知识以及特定的搜索空间设计。
模型的存储是高效的。因为 embedding 的维度被自适应的调整。
embedding 的初始化是高效的。对于 embedding 的热启动十分友好。
▐ 2. 方法
在这一章,我们将介绍所提的模型。
2.1 基本想法
首先,我们回顾一下最经典的 embedding layer,其可以被表达为:
其中是特征的one-hot向量, 是embedding矩阵。 是 的embedding向量。
接下来,我们定义特征值的掩码向量为,该向量需要满足:
其中是一个可学习的整数参数,受特征的频率影响。
然后,为了能够调整不同特征值的 embedding 维度,最基本的思想是用掩码向量去mask ,
其中 表示对应位置的元素乘. 由于在中下标大于的值都为0,mask后的可以看成是一个 embedding 维度自适应调整的向量,其中中前值被保留。
下面简单介绍下,是如何节省 embedding 存储以及自适应维度的 embedding 是如何使用的。
节省存储。当存储时,我们可以只存没有 mask 的前个值,然后从存储中取出 embedding 的时候,可以直接在向量后面补0来复原。
自适应维度的 embedding 使用。不像现有的方法[8-12]需要额外设计一个模块使得不同的 embedding 重新映射成统一的维度来适配接下来统一长度的 MLP 层,所提方法的通过补0拥有相同的维度,可以直接输入到 MLP 层。
2.2 自适应孪生掩码层
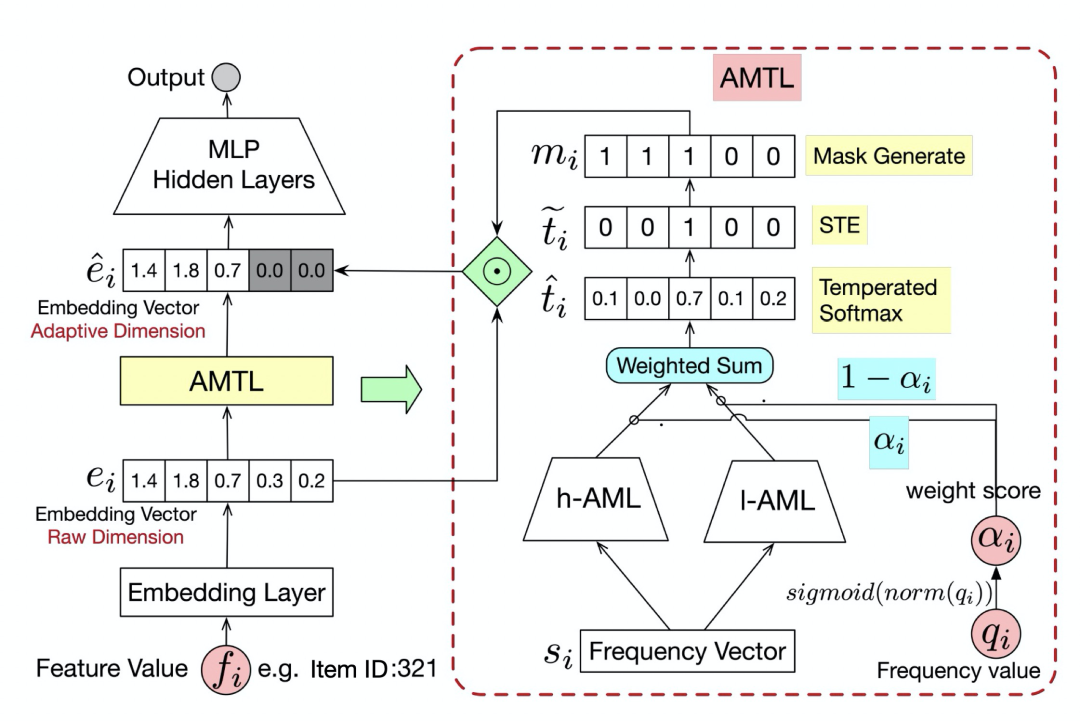
自适应孪生掩码(AMTL)层是用来为每个特征生成掩码向量。整体的结构见图2.
2.2.1 输入和输出
在这一节,我们介绍 AMTL 的输入和输出:
输入:由于需要能够随着特征的频率的改变而改变。因此为了使得 AMTL 能够拥有特征频率的信息,我们将特征的频率信息(比如一个特征在历史中出现的次数,出现频率的排名等等)作为输入(记为)。
输出:AMTL 的输出是一个 one-hot 向量(叫做选择向量)来表示 。
2.2.2 结构
我们设计了一个孪生网络结构(即两个分支子网络)来生成。每一个分支网络叫做自适应掩码层(AML)。需要注意的是这两个分支网络的参数是不共享的。具体而言,每一个 AML 都是一个MLP
其中为特征频率向量, 和 是第层的网络参数, 是激活函数, 为 AML 的最后一层的输出。
设计成孪生网络的主要目的是:如果仅采用一个分支,那么整个网络参数的更新,由于输入数据不平衡原因,将会被高频的特征所主导。具体来讲,由于高频特征在样本中出现次数更多,那么 AML 的大部分输入特征都是高频特征,这样一来,AML 的网络参数将极大的会被高频特征影响,导致AML可能会盲目的倾向于选择大维度。因此,我们提出了一个孪生网络来解决这个问题,其中 h-AML 和 l-AML 分别被用来刻画高频和低频特征。这样以来 l-AML 的网络参数可以不受高频特征影响,给出公正的特征维度选择决断。
Weighted Sum. 然而,一个最大的问题是,我们很难去卡一个阈值来事先定义哪些是高频特征哪些是低频特征。因此,我们提出了一个软选择的策略。具体而言,我们定义为特征值在历史中出现的次数,然后将分别输入到 h-AML 和 l-AML 中去,得到两个网络的输出 和 。最后将这两个输出进行加权求和,即:
其中是和相关的权重,是一个归一化函数将变成一个正态分布来使得在左右分布。不然的话,没有,所有的将会都趋近于1. 通过加权求和,对于高频样本,会有一个较大的,对应的 将会由 主导,这时在梯度传播的时候,会主要更新 h-AML 的网络参数,反之亦然。这样以来,AMTL 能够自适应的调节 h-AML 和 l-AML 的梯度更新来解决样本不平衡问题。
然后我们对使用 softmax 函数
其中, 为特征选择不同维度的概率,比如为选择维度的概率。然后选择向量可以被表达为:
对应的掩码向量可以通过来生成:
其中为预定义的掩码矩阵, 当时, 反之 。
掩码后的 embedding 向量可以通过 来获取。需要注意的是,对于不同的特征域,需要不同的 AMTL 来进行特征维度选择。
2.2.3 Relaxation 策略
然而,由于生成中需要 argmax 操作,这样一个操作使得 AMTL 的学习变得不可微,无法直接使用梯度下降的策略。为了解决这样一个问题,我们利用 temperated softmax [13,14,15]来平滑, 具体来说, 的第个值可以被近似为:
其中是 temperature 超参。当时,近似就无限接近于精确解。由于 是一个连续的向量,没有引入不可微的过程,因此可以使用梯度下降算法来训练。因此,我们并不直接去求解离散的向量,而是用 来近似。
然而,这样的操作会使得训练和推断之间存在信息差。具体来讲,我们使用的是 作为训练,然后在推断阶段,使用的是离散向量。为了解决这样一种差异,受 Straight-Through Estimator (STE) [16]启发,我们重构为
其中 stop_gradient 使用来阻断梯度传播的。由于前向计算的过程不受 stop_gradient 影响,在该阶段(与推断时,所用向量一致)。在反向传播是,通过 stop_gradient 来避免不可微过程的梯度更新。
▐ 3. 实验
3.1 实验设置
数据集
MovieLens
IJCAI-AAC
Taobao
Baseline
Standard:传统的固定维度的embedding(FBE)
基于规则的:MDE [8]
基于NAS的:AutoEmb [11]
3.2 CTR预估任务
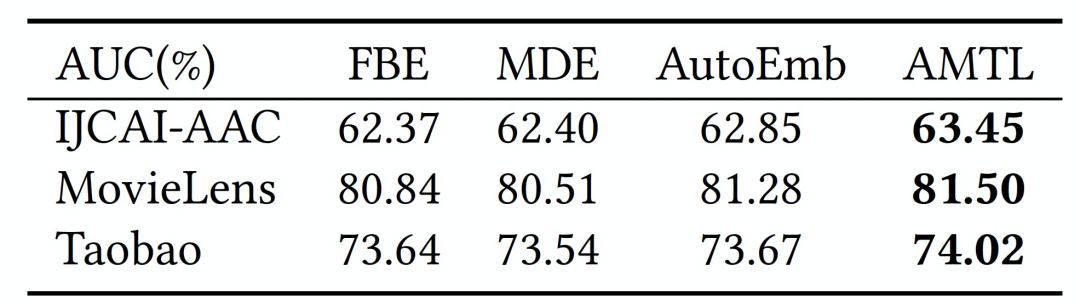
我们通过 CTR 预估任务来比较不同方法的效果。如表1所示,不论是和传统的FBE方法,还是维度选择的 MDE 和 AutoEmb 方法相比,AMTL 在所有数据集均取得更好的效果。
3.3 存储开销比较
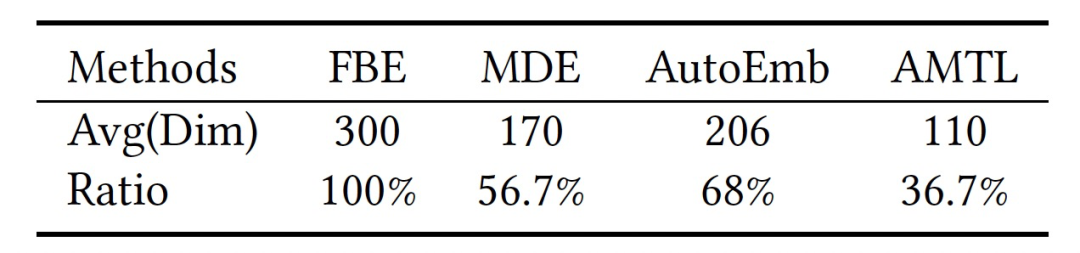
在这里,我们比较不同方法的 embedding 存储开销。由于 embedding 存储开销与 embedding 的维度成正比,在这里,简单起见,我们比较了,不同方法下,特征 User ID 的平均维度。如表2所示,可以看到由于 AMTL 采用了更加灵活的特征维度选择方式,其最能节省存储开销。相比于 FBE,节省约60%。
3.4 Embedding热启动评估
这里,我们评估 AMTL 在 embedding 热启动上的优越性。具体讲,在 DLRM 中有两类参数,一个是 MLP 层的参数,一个是 embedding 层的参数。在热启动的设置中,由于 MDE 和 AutoEmb 都不支持 embedding 的热启动,所以我们仅用线上服务模型的 MLP 的参数来初始化 MDE 和 AutoEmb 的 MLP 层。对于 AMTL 和 FBE 而言,其 MLP 层和 embedding 层均可用线上模型初始化。热启动后的 CTR 效果如表3所示,可以看到,由于能够自然的支持 embedding 的热启动,AMTL 取得了极大的提升。这样一种性质,为 AMTL 在实际应用提供了极大的便利。

3.5 Embedding维度评估
我们可视化了不同频率特征的embedding维度选择的平均大小,如图3(a)所示,到分别表示不同频率的特征集,下标越大,频率越大。可以看到,高频特征值倾向于选择高维度,低频特征选择低维度。表明,AMTL能够为不同频率的特征值选择合适的维度。

3.6 消融实验
孪生结构的评估:我们分别比较 AMTL 和 AML 的效果。如表4所示,AMTL 能够取得更好的效果。同时我们也可视化了 AML 的维度选择,如表图3(b)所示,由于样本不平衡问题,低频特征盲目的选择了高维度。
STE有效性评估:我们设置了一个不采用STE的模型,记为 AMTL-nSTE 。通过比较 AMTL 和 AMTL-nSTE 来评估 STE 的有效性。如表4所示,采用了 STE 的 AMTL 取得了更好的效果。

3.7 时间开销比较
我们比较了不同模型之间的时间开销,如表5所示,AMTL 的方法相比于 FBE,在时间开销上略有增加。不过,需要指出的是,在推断阶段,我们可以直接存储 mask 后的 embedding 向量,而不需要再过 AMTL 层,以此来节省时间。

结语
AMTL 是我们团队在 embedding 优化上,从维度角度出发的一篇工作。同时也是继 FCN-GNN[17] 之后,在模型瘦身上的又一次探索。我们后续在此方向继续发力,也期待与从事相同领域的同学交流探讨。
Reference
[1] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
[2] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
[3] Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Fieldaware factorization machines for CTR prediction. In Proceedings of the 10th ACM conference on recommender systems. 43–50.
[4] Feng Li, Zhenrui Chen, Pengjie Wang, Yi Ren, Di Zhang, and Xiaoyu Zhu. 2019. Graph Intention Network for Click-through Rate Prediction in Sponsored Search. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 961–964.
[5] Hao-Jun Michael Shi, Dheevatsa Mudigere, Maxim Naumov, and Jiyan Yang. 2020. Compositional embeddings using complementary partitions for memory-efficient recommendation systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 165–175.
[6] Caojin Zhang, Yicun Liu, Yuanpu Xie, Sofia Ira Ktena, Alykhan Tejani, Akshay Gupta, Pranay Kumar Myana, Deepak Dilipkumar, Suvadip Paul, Ikuhiro Ihara, et al. 2020. Model Size Reduction Using Frequency Based Double Hashing for Recommender Systems. In Fourteenth ACM Conference on Recommender Systems. 521–526.
[7] Xiangyu Zhao, Haochen Liu, Hui Liu, Jiliang Tang, Weiwei Guo, Jun Shi, Sida Wang, Huiji Gao, and Bo Long. 2020. Memory-efficient Embedding for Recommendations. arXiv preprint arXiv:2006.14827 (2020).
[8] Antonio Ginart, Maxim Naumov, Dheevatsa Mudigere, Jiyan Yang, and James Zou. 2019. Mixed dimension embeddings with application to memory-efficient recommendation systems. arXiv preprint arXiv:1909.11810 (2019).
[9] Manas R Joglekar, Cong Li, Mei Chen, Taibai Xu, Xiaoming Wang, Jay K Adams, Pranav Khaitan, Jiahui Liu, and Quoc V Le. 2020. Neural input search for large scale recommendation models. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2387–2397.
[10] Haochen Liu, Xiangyu Zhao, Chong Wang, Xiaobing Liu, and Jiliang Tang. 2020. Automated Embedding Size Search in Deep Recommender Systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2307–2316.
[11] Xiangyu Zhao, Chong Wang, Ming Chen, Xudong Zheng, Xiaobing Liu, and Jiliang Tang. 2020. AutoEmb: Automated Embedding Dimensionality Search in Streaming Recommendations. arXiv preprint arXiv:2002.11252 (2020).
[12] Xiangyu Zhao, Haochen Liu, Hui Liu, Jiliang Tang, Weiwei Guo, Jun Shi, Sida Wang, Huiji Gao, and Bo Long. 2020. Memory-efficient Embedding for Recommendations. arXiv preprint arXiv:2006.14827 (2020).
[13] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
[14] Eric Jang, Shixiang Gu, and Ben Poole. 2016. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144 (2016).
[15] Chris J Maddison, Andriy Mnih, and Yee Whye Teh. 2016. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:1611.00712 (2016).
[16] Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013).
[17] Li F, Yan B, Long Q, et al. Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction[J]. SIGIR 2021.
END

欢迎关注「阿里妈妈技术」,了解更多~

疯狂暗示↓↓↓↓↓↓↓
















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









