






▐ 导读
阿里妈妈AI创意生产工具-万相实验室,已经广泛服务于电商多个业务场景,帮助商家快速制作创意图片,降低成本和提升投放效果。在此之前,公众号已经分享了其背后电商文生图基础模型和可控生成相关工作,随着使用客户的不断增多,以及平台对于规模化制作的诉求,如何加快图像扩散模型的生成速度是急需解决的问题。本文介绍了我们和南京大学王利民教授课题组合作完成的加速扩散模型生成速度上的新工作:SPLAM(基于子路径线性近似的扩散模型加速方法),其主要解决扩散模型在采样过程中通常需要25步推理带来的长耗时问题。SPLAM提出了线性ODE(线性常微分方程)采样方法,对现有的LCM(潜在一致性模型)存在的累积误差较大的问题进行优化。在同等4步推理条件下,SPLAM在COCO30k和COCO5k数据集上分别取得了10.06和20.77的FID分数,在加速模型方法中达到了SOTA水平。同时,相关工作已经应用于万相实验室快速生成任务。SPLAM工作已被 ECCV 2024 接收为 Oral,论文、代码、模型均已开源,欢迎阅读&试用交流~
项目主页:https://subpath-linear-approx-model.github.io/
论文:https://arxiv.org/abs/2404.13903
作者:Chen Xu, Tianhui Song, Weixin Feng, Xubin Li, Tiezheng Ge, Bo Zheng, Limin Wang
代码:https://github.com/MCG-NJU/SPLAM
模型:https://huggingface.co/collections/alimama-creative/slam-662f1dd31d5c8cd0b3acb0e0
1. 背景
扩散模型目前已经成为文本生成图片领域使用最为广泛的模型,其通过逐步去噪步骤来从一张高斯噪声采样生成真实分布中的图片。然而,扩散模型一直存在的一个问题是其运行速度,因为需要多步迭代推理,导致图片生成速度缓慢,计算开销大。针对这个问题,一直以来,也有非常多的工作在探索加速扩散模型的方法。在最初的DDPM中,模型的推理需要和训练时相同的1000步迭代,生成一张图片通常需要数分钟。一系列工作着重研究推理时的采样方法,如DDIM,DPM-Solver等,这些方法通过ODE等技术优化,将采样步数从1000步降低到了20~50步量级,大大提升了图片生成速度。另外一系列的工作着重研究基于现有预训练模型(比如Stable Diffusion),通过蒸馏等方法将步数进一步压缩,实现到了10步以下的采样迭代次数。如LCM(一致性模型),通过将PF-ODE上的采样点映射到原点的思想,实现了2-4步的推理,然而压缩步数也会导致一定程度的图片质量下降。本文分析了一致性优化学习的过程中的难点和导致性能下降的因素,提出了子路径线性近似模型(SPLAM)对问题进行了优化,减小了快速推理过程的累积误差,在生图效果和速度上取得了更好的平衡。
2. 方法
2.1 一致性模型
一致性模型(Consistency Model)[1] 是 OpenAI 的 Song Yang 博士在 ICML2023 提出的扩散模型加速方法,是这个领域中非常重要的一项工作,基于此在Stable Diffusion上开发的LCM模型 [2] 也是在用户社区中热度非常高加速功能插件,我们首先来回顾一下一致性模型的原理。
根据 Song Yang [3] 的理论,一个扩散模型的去噪过程可以建模为一条常微分方程ODE路径,称为概率流Probability-Flow ODE (PF-ODE):
而一致性模型的想法其实也非常简单,就是将ODE路径上每一个点都映射到原点,而原点来源于真实图片的分布,从而做到一步生成,如图所示:
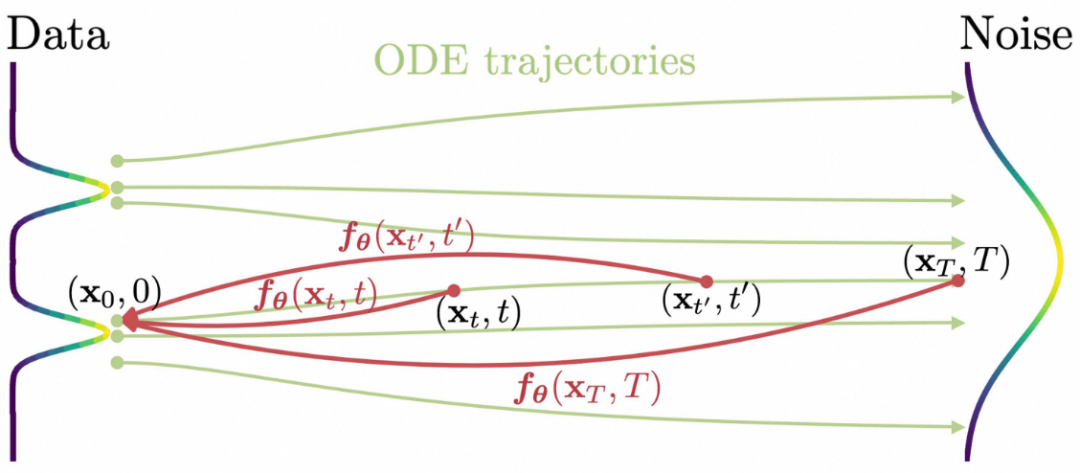
具体地,我们希望学习一个函数,对于一条ODE上的采样点。在训练中,从逐步采样到通常时间开销过大,所以CM采取了一个训练技巧,在每一步训练迭代中通过缩小相邻两个点间的映射误差,来逐渐最终达到一致性。然而这也带来了问题,逐步的收敛导致了较大的累积误差:
使得在生图时的图片的细节丢失较多,生图质量较差。我们的方法也是针对这个问题,通过在每个子路径上通过随机线性插值采样,来进行连续的渐进式的误差估计,做到累计误差更小的去噪映射。
2.2 SPLAM
2.2.1 问题分析
对于上面提到的一步生成模型,我们通常把映射函数参数化为:.
根据EDM中的理论,我们可以设计一个 canonical denoiser function ,而其去噪目标就为:
这时会存在一个问题,这个目标其实比较难以优化,原因在于随着时间步的增加,会逐渐趋向于零,这会使得训练不稳定有可能塌缩。一致性模型其实一定程度上缓解了这个问题,当我们假设模型理想地收敛,即 ,这个性质能够对于上式进行一个预估:
然后我们把的表达式代入,得到一个基于的误差估计:
。
因为额外有了系数,所以上面所提到的问题被一定程度的缓解。
现在我们再来具体分析一下这个优化目标,我们可以把它解耦为两项:
1),这一项衡量了由于漂移和扩散过程导致的从到的增量距离。
2),这一项衡量了前一时间步的去噪贡献,这些贡献会连续地传播到后续时间步。
这时,我们我们就可以把这个优化目标重写为一个子路径(Sub-Path)的优化目标:
在这个目标式中,这项是导致累积误差的关键,我们也着重对于这项进行优化。
2.2.2 Sub-Path Linear Approximation Model
基于此,我们提出了我们的加速方法子路径线性近似模型(Sub-Path Linear Approximation Model,SPLAM),如图所示。
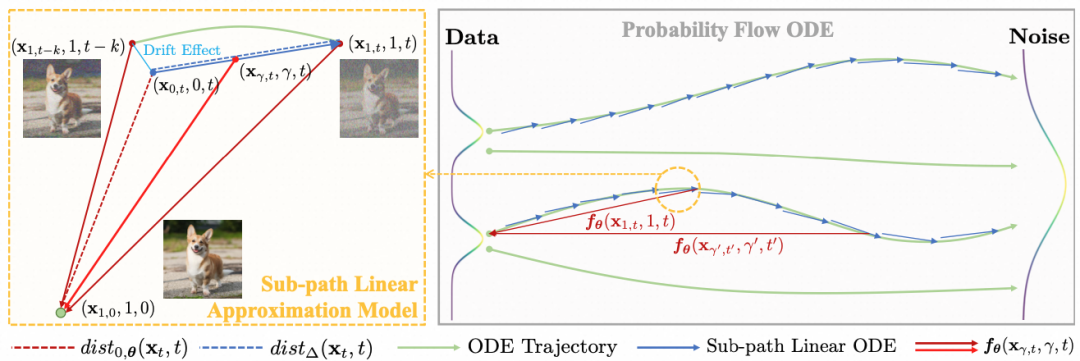
首先,我们提出了子路径线性ODE(Sub-Path Linear ODE,SL-ODE),来近似原始PF-ODE上的子段,由此来进行对于的递进式估计。具体来说,对于原始路径上的一段,基于我们对两个端点进行插值形成线性路径,在这个线性路径上的采样点可以表示为:
因为符合由PF-ODE控制的分布,我们的线性变换有效地定义了一个对于的线性ODE:
即为SL-ODE。注意到这里对于端点多了一项漂移系数,这项系数的引入具体可参考我们论文中的详细推导。据此,我们也有了对应的Denoiser和生成表达式:
将这个式子代入上面的子路径优化目标,便得到了我们SPLAM的最终优化目标:
这个目标对于原本较难优化的项提供了一种递进式的拟合,这也使得我们我们的训练可以使用更大的推理步长。
由此,我们也以预训练好的Stable Diffusion模型作为PF-ODE,来建立我们的SL-ODE,并提出了基于SLPAM目标的蒸馏方法(Sub-Path Linear Approxmiation Distillation,SPLAD)。
我们依然沿用CM中的生成函数的参数表达式,除了额外增加了一个维度:
与CM的优化方法结合,SPLAD最小化的目标为:
其中为使用的教师模型作为 ODE Solver。具体训练流程如下算法所示:

在推理时,我们只需设置即可实现一步出图:,同样地,我们也采用和CM同样的多步推理策略来实现更好的生成质量。
3. 实验结果
3.1 定量指标
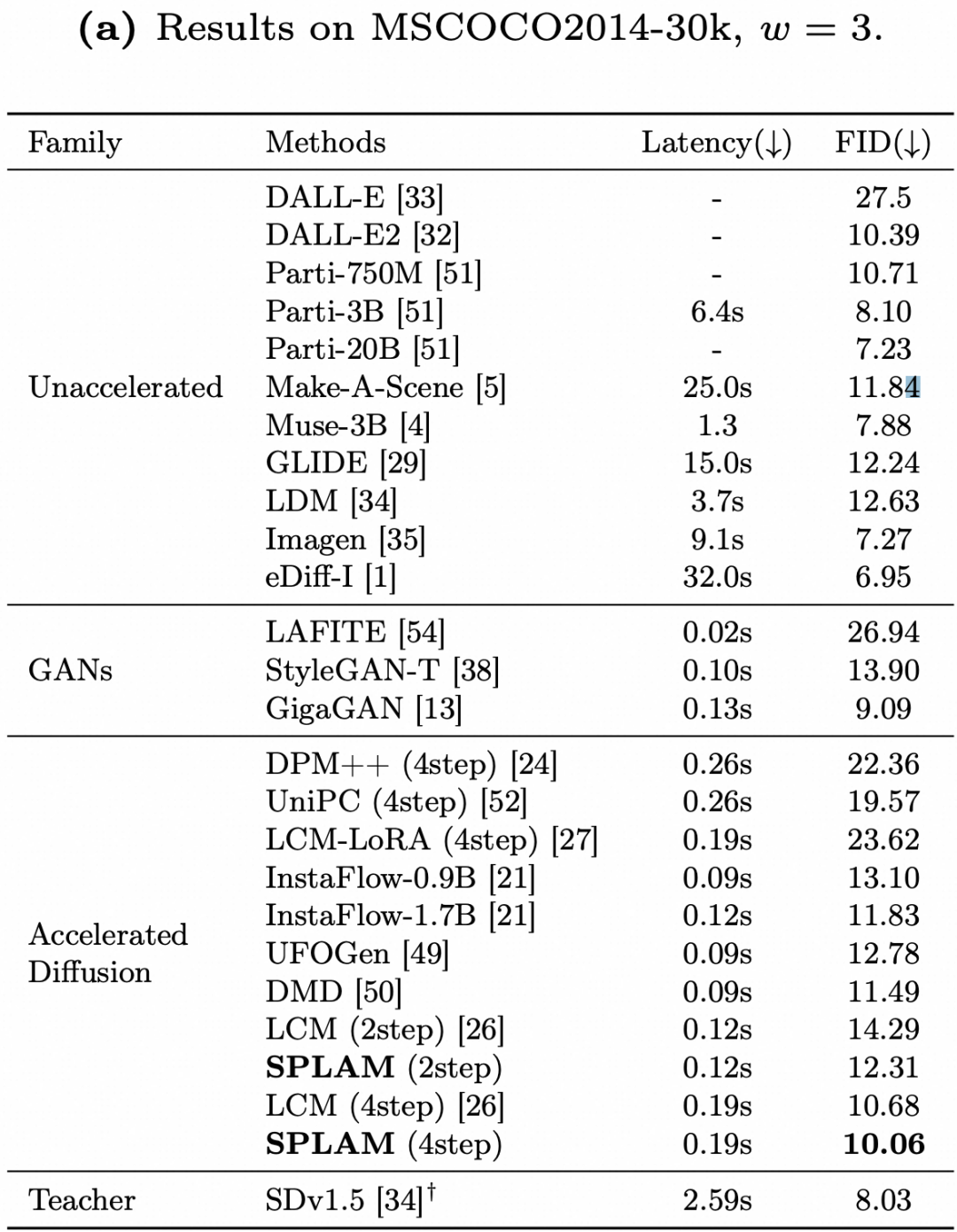
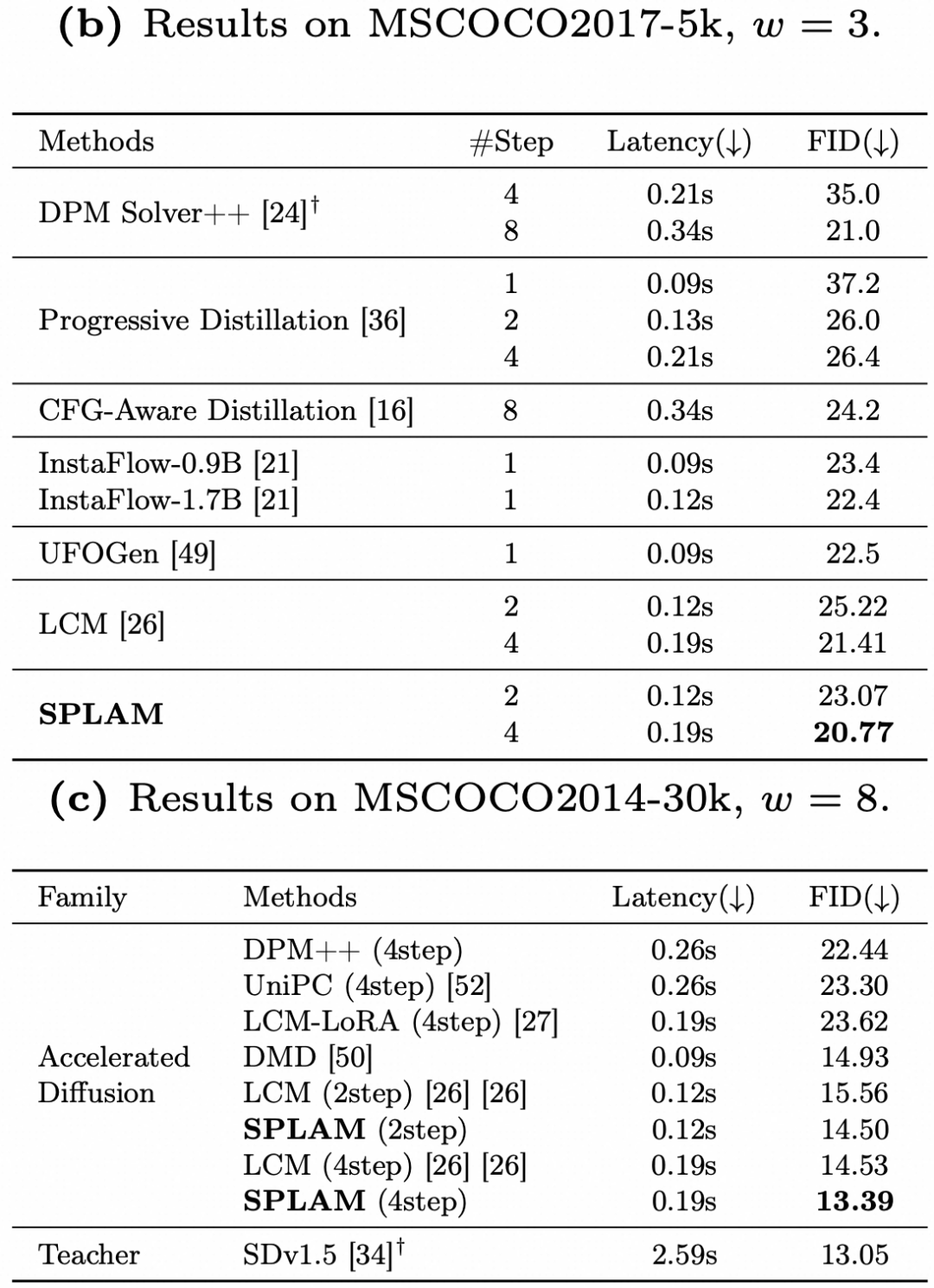
在常用的学术指标基准 COCO FID 上,SPLAM相比于LCM和其它加速方法取得了更好的效果,FID更低表示生图效果和真实图片的分布更加接近。所有模型均基于SD1.5基础模型。
3.2 定性可视化
我们在基于SD1.5微调的模型DreamShaper上训练了SPLAM-DreamShaper,并与LCM-Dreamshaper进行了对比,效果如下图所示。可以看到,SPLAM从色彩、美观度、真实感上都优于LCM。


同时,SPLAM算法也可以用于其它基础模型,基于SD2.1的训练效果见下图。可以明显地看出,SPLAM由于优化了更小的累积误差,画面更加清晰丰富。更多的可视化例子可见我们的论文。

4. 应用
基于SPLAM算法,万相实验室推出了灵感推荐功能,用户选择商品后,灵感推荐功能会在5秒内快速生成一批预览素材。商家可以直接下载对应素材或者进一步进行细节优化。从系统生成次数和下载次数上看,灵感推荐大幅降低了客户等待结果的时间,有效提升用户体验。
5. 总结
本文介绍了我们对于扩散模型的加速方法SPLAM,通过子路径线性近似策略来优化一致性学习过程中的累积误差,相同去噪步数下,提升了图片生成质量。朴素的核心思想是对于原始一致性训练过程中相邻两点的映射误差较难以优化的问题,我们引入额外的一个维度,通过建立线性插值进行连续的渐进式的误差估计。在该子路径上进行优化使得 SPLAM 的学习更加平滑,能够做到累计误差更小的去噪映射,从而提升更少步数生图的图片质量。该算法已经应用在阿里妈妈万相实验室的灵感推荐功能上,实现3~5s生图提升用户体验。代码及模型已开源(项目主页:https://subpath-linear-approx-model.github.io/),欢迎体验。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱 AIGC 时代!感兴趣的同学欢迎投递简历加入我们。
✉️ 简历投递邮箱:
alimama_tech@service.alibaba.com
▐ 参考文献
[1] Score-Based Generative Modeling through Stochastic Differential Equations. https://arxiv.org/abs/2011.13456
[2] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference. https://arxiv.org/abs/2310.04378
[3] Consistency Models. https://arxiv.org/abs/2303.01469
END

也许你还想看
丨ACM MM’23 | 4篇论文解析阿里妈妈广告创意算法最新进展
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨CVPR 2023 | 基于无监督域自适应方法的海报布局生成
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









