






分享一篇大连理工软院的发表于TPAMI的2025最新红外与可见光融合的综述
请多多关注,定期分享好文解析!
论文最下面给出了我个人总结的,综述中出现的优质参考文献的链接!!!需要学习的一定要收藏这一篇文章,一篇就够用了!需要解析哪篇文章的可以评论!!
论文链接:https://ieeexplore.ieee.org/document/10812907
目录
1.核心目标与原理 (Complementary Information):
2.应用价值 (Synergy & Robust Perception):
3.关键挑战 (Challenges in Practical Applications):
1. 免配准方法 (Registration-free Approaches):
2. 通用融合框架 (General Fusion Approach):
4. 架构总结 (Architectures Summary):
5. 损失函数总结 (Loss Function Summary):
6. 对偶判别器 GAN (Dual Discrimination GANs):
7. 基于 Transformer 的方法 (Transformer-based Approaches):
8. 面向应用的融合 (Application-oriented Fusion):
编辑B. 评估指标 (Evaluation Metric)
B. 未对齐图像融合 (Registration-based Image Fusion)
C. 用于目标检测的图像融合 (Image Fusion for Object Detection)
D. 用于语义分割的图像融合 (Image Fusion for Semantic Segmentation)
E. 计算复杂度分析 (Computational Complexity Analysis)
一. 摘要
1.1 摘要翻译
红外-可见光图像融合(IVIF)是计算机视觉领域的一项基本且关键任务。其目标是将红外和可见光谱的独特特性整合成一个整体表示。自2018年以来,越来越多的多样化IVIF方法进入了深度学习时代,涵盖了广泛的网络结构和损失函数,以提升视觉增强效果。随着研究的深入和实际需求的增长,一些复杂问题,如数据兼容性、感知精度和效率,无法被忽视。遗憾的是,缺乏最近的综述文章来全面介绍和组织这一不断扩展的知识领域。鉴于当前的快速发展,本文旨在填补这一空白,提供一份全面的综述,涵盖广泛的方面。首先,我们引入了一个多维框架,以阐明当前流行的基于学习的IVIF方法,涵盖从基本视觉增强策略到数据兼容性、任务适应性以及进一步扩展的主题。随后,我们深入分析这些新方法,提供详细的查找表以澄清其核心思想。最后,我们从定量和定性角度总结了性能比较,涵盖配准、融合和后续高级任务。除了深入探讨这些基于学习的融合方法的技术细节外,我们还探索了潜在的未来方向和需要社区进一步探索的开放问题。如需更多信息和详细的数据汇编,请参阅我们的 GitHub 仓库:https://github.com/RollingPlain/IVIF ZOO。
二. 介绍
2.1 介绍翻译
光谱由多个光谱项组成,可以简洁地定义为光在不同频率或波长上的表示。广义上,光谱涵盖了整个电磁波范围,从无线电波到伽马射线。然而,在日常生活中,我们最为熟悉的是可见光谱,它包括人眼可感知的颜色,如红、橙、黄、绿、蓝、靛、紫。但可见光谱仅占整个光谱的极小部分。在可见光之外,还存在许多其他光谱类型,包括紫外线、红外线、微波和X射线,每种光谱都有其独特的特性和应用[1],[2]。图1展示了对应不同波长的图像,从10⁻¹²米(伽马射线)到10³米(广播频段)。随着人工智能的快速发展,智能系统在现实世界、复杂甚至极端场景下有效运行的感知需求日益增加。然而,单一光谱类型的固有局限性往往无法全面、可靠、精确地描述这些场景。因此,多光谱图像融合技术应运而生,旨在合成和优化来自不同传感器捕获同一环境的多样化图像数据[3],[4]。其中,红外和可见光图像作为下一代智能系统的主要数据源,在实现高可靠性感知任务中发挥着不可替代的作用。红外光谱位于可见光谱红色端的外部,具有比红光更长的波长。红外辐射的一个显著特征是其能被物体吸收并重新发射,使其成为温度或热量的宝贵指标。因此,红外传感器常用于夜视、热成像和某些特殊医疗应用[6]。虽然两种光谱在不利条件下都有局限性,但多光谱图像在环境适应性(如烟雾、障碍物、低光照)和独特视觉特征(如分辨率、对比度、纹理细节)方面提供了显著的互补性。为了充分利用红外和可见光谱的互补性,整合两者以发挥其综合优势至关重要。一种直接方法是将红外和可见光图像直接输入神经网络,进行决策级融合以完成各种任务。然而,这种方法忽略了生成融合图像的优势,融合图像可以增强信息表示,降低噪声,同时满足观察需求,并更好地支持广泛的实际应用,如遥感、军事监控和自动驾驶等[7]。自2018年以来,基于学习的红外与可见光图像融合(IVIF)方法因深度学习技术的强大非线性拟合能力而取得了显著发展。与传统方法相比,这些基于学习的方法在视觉质量、鲁棒性和计算效率方面表现出色,因此吸引了越来越多的关注。这些方法在各种基准测试中往往达到最先进性能,从早期的仅用于视觉增强的图像融合方法到近期的数据兼容性/任务适应性方法。本文全面概述了通过深度学习融合红外和可见光图像的最新进展,特别强调了面向实际应用的提案。尽管文献中存在关于红外与可见光图像融合的综述[8],[9],但我们的工作独树一帜。我们的重点在于多维度洞察(数据、融合和任务)的IVIF技术,与大多数之前的工作不同,后者主要旨在综述传统或基于学习的IVIF方法。我们的综述采用了更通用的视角,审视设计适用于实际应用的深度网络所需的各种关键因素。重要的是,我们强调了初步数据兼容性和后续任务的关键作用,这两者在将IVIF应用于实际场景时至关重要。因此,本综述是首次以多维度方式提供对近期进展的洞察性和系统性分析的努力。本工作旨在激发社区内的新研究,充当进一步探索和发展的催化剂。本研究的主要贡献有以下四点:
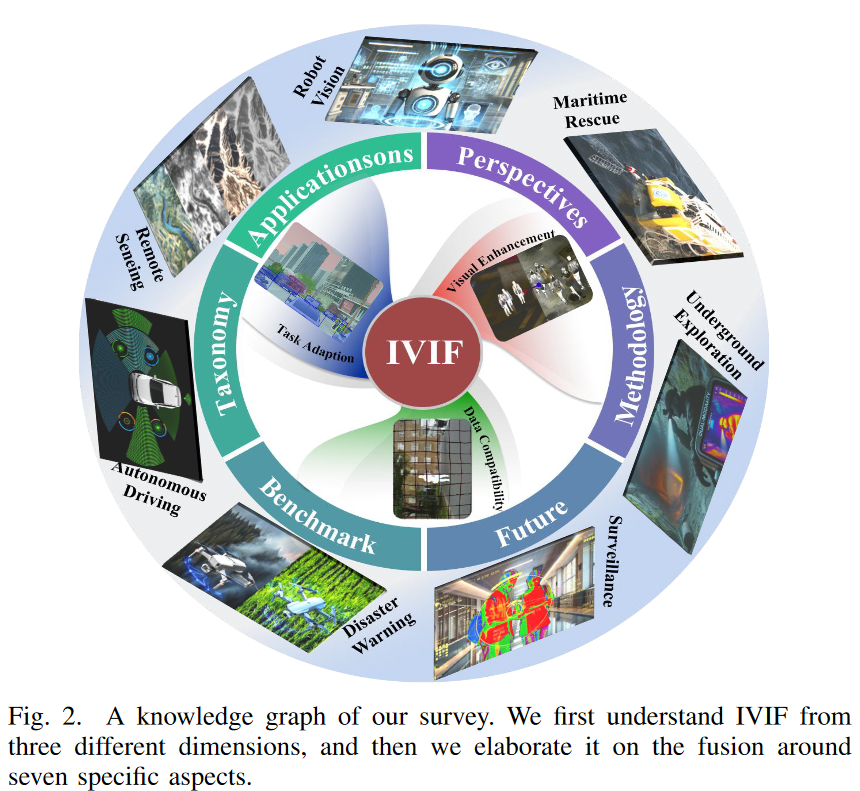
- 据我们所知,本综述论文在以多维度视角(数据、融合和任务)统一理解和组织基于学习的红外与可见光图像融合方法方面是前所未有的。我们回顾了180多种基于学习的方法。论文整体结构概览如图2所示。
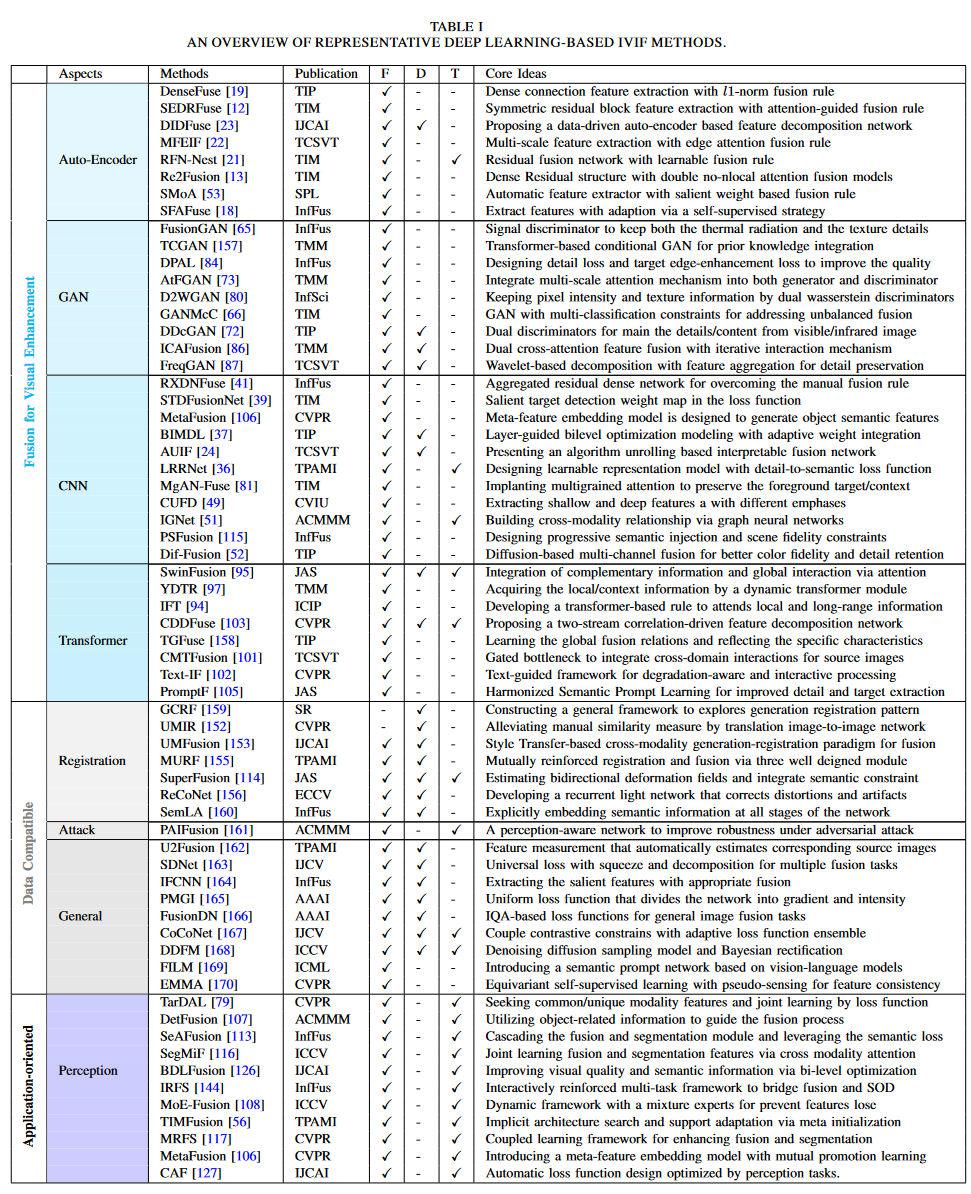
- 我们深入讨论了每个视角,涉及最近使用的架构和损失函数。我们还总结了表I,讨论代表性方法的核心思想,从而为后续研究该领域的学者提供了极大便利。
- 为阐明面向应用的红外与可见光图像融合方法,我们以层次化和结构化的方式系统概述了近期技术和数据集的进展。值得注意的是,我们首次比较了初步配准和后续任务(如目标检测和语义分割)的融合性能。
- 我们讨论了挑战和开放问题,识别新兴趋势和潜在方向,为社区提供洞察性指导。
A. 范围
图像融合是一项基础图像增强技术,涵盖多个分支,包括但不限于红外与可见光图像融合。在单一篇幅内详细回顾这些相关技术是不现实的。本工作中,我们主要聚焦于基于学习的红外与可见光图像融合,精选介绍相关领域的代表性方法。本文主要关注过去六年取得的重要进展,特别关注顶级会议和期刊发表的工作。除了阐明基于学习的红外与可见光图像融合方法的技术细节外,本综述还概述了分类法、常用数据集、潜在挑战和研究方向。
B. 组织
本文组织如下。第II节简要介绍了红外与可见光图像融合任务,重点在于其应用。第III节提出了一个新的分类法,将现有方法分为三个维度。此外,该节深入探讨了网络架构和相关损失函数的基本组成部分。这一全面概述有助于初学者掌握基础知识,并帮助资深研究者更结构化、更深刻地理解该领域。第IV节列举了该领域广泛接受的基准和评估指标。第V节展示了我们方法的全面评估,详细介绍了配准、融合和其他后续下游任务的定性和定量结果。第VI节指出了未来研究的潜在方向。文章在第VII节以总结结束。
2.2 介绍解析
1. 多光谱图像融合的背景与重要性
- 光谱定义:
- 光谱表示光在不同波长或频率上的分布,涵盖电磁波全范围(从无线电波到伽马射线)。
- 可见光谱:仅占很小部分(约400-700nm),包括人眼可感知的颜色(红、橙、黄、绿、蓝、靛、紫)。
- 其他光谱:
- 红外(700nm-1mm):捕捉热辐射,适合夜视、热成像。
- 紫外(10-400nm):用于材料分析、医疗。
- 微波、X射线:分别用于通信、成像等。
- IVIF 的核心目标:
- 整合红外(显著性强,热目标突出)和可见光(纹理丰富,细节清晰)的特性,生成综合表示。
- 应用:
- 自动驾驶:夜间行人检测。
- 遥感:地貌分析。
- 军事监控:全天候目标跟踪。
- 医疗:热成像诊断。
- 必要性:单一光谱(如可见光在夜间失效,红外缺乏纹理)无法满足复杂场景需求,IVIF 是解决这一局限的关键技术。
2. 多光谱融合的挑战与 IVIF 的独特地位
- 单一光谱的局限性:
- 红外:分辨率低,缺乏颜色和纹理,易受噪声影响。
- 可见光:受光照、烟雾、遮挡影响,夜间效果差。
- 挑战:单一光谱无法提供全面、可靠的场景描述,尤其在极端条件(如低光照、雾天)。
- 多光谱融合的意义:
- 通过整合不同传感器的数据,生成更鲁棒、丰富的信息表示。
- 红外-可见光融合(IVIF):
- 互补性:
- 环境适应性:红外在烟雾、低光照下表现优异;可见光在白天提供高分辨率。
- 视觉特征:红外突出目标(热源),可见光提供纹理、对比度。
- 关键性:IVIF 是多光谱融合的核心分支,因其数据易获取(红外相机、可见光相机普及)且应用广泛。
- 互补性:
3. IVIF 的技术演进与深度学习
- 传统方法:
- 基于多尺度分解(如小波变换)、稀疏表示或加权平均。
- 局限:依赖手工特征,泛化性差,视觉质量有限。
- 深度学习时代(2018年以后):
- 驱动因素:深度学习的非线性拟合能力,显著提升融合质量。
- 代表性进展:
- 早期(视觉增强):如 DenseFuse(2018),基于编码-解码器,提升目标和纹理保留。
- 近期(数据兼容性/任务适应性):如 PIAFusion(光照感知)、NestFuse(多尺度),支持配准、检测、分割等。
- 优势:
- 视觉质量:融合图像更自然,细节更丰富。
- 鲁棒性:适应复杂场景(如夜间、雾天)。
- 效率:端到端训练,减少手动调参。
4. IVIF 的技术细节
- 网络架构:
- CNN:如 U-Net、ResNet,适合特征提取和融合。
- GAN:生成自然图像,优化视觉质量。
- Transformer:捕捉全局依赖,适合跨模态交互。
- MoE:动态选择融合策略,提升自适应性。
- 损失函数:
- 像素级:
、
、SSIM,优化像素一致性。
- 感知级:VGG 特征损失,增强语义自然性。
- 对抗级:GAN 损失,提升视觉真实性。
- 任务级:检测或分割损失,优化下游性能。
- 像素级:
- 数据兼容性:
- 配准:端到端深度配准(如 FlowNet)或传统特征点匹配。
- 分辨率统一:插值、超分辨率网络(如 SRGAN)。
- 任务适应性:
- 检测:融合图像提升夜间 mAP。
- 分割:融合图像提高 mIoU。
- 夜视增强:生成适合人眼观察的图像。
三. 任务
3.1 任务翻译
对于由不同传感器捕获的一对红外与可见光图像,红外与可见光图像融合(IVIF)的目标是生成一个比任何单一图像包含更互补、更全面的信息的单一图像。可见光图像是传感器利用从各种场景和物体反射的光线生成的,有效地呈现了环境的详细纹理信息。然而,这些图像很容易受到环境光照、亮度以及恶劣天气条件等因素的影响。相比之下,红外传感器通过探测热辐射来成像,这突出了物体的整体轮廓,但可能导致特征模糊、对比度低以及纹理信息减少。为了利用这两种技术的优势,可以结合红外与可见光成像来提取全面的信息,从而增强场景理解。这种协同作用使得现实中的实际应用(例如智能系统)即使在动态和恶劣条件为特征的环境中也能保持鲁棒的视觉感知。
当将 IVIF 应用于实际应用时,应仔细考虑两个关键因素。(i) 大多数现有方法需要像素级配准的红外与可见光图像对进行融合。然而,由于红外与可见光传感器在视点、像素分布和分辨率方面存在显著差异,获取精确配准的数据极具挑战性。(ii) 部分方法侧重于寻求视觉增强,而忽略了提升后续高级视觉任务(例如,目标检测、深度估计和语义分割)的性能。因此,生成的融合图像难以直接应用于具有感知需求的智能系统中。
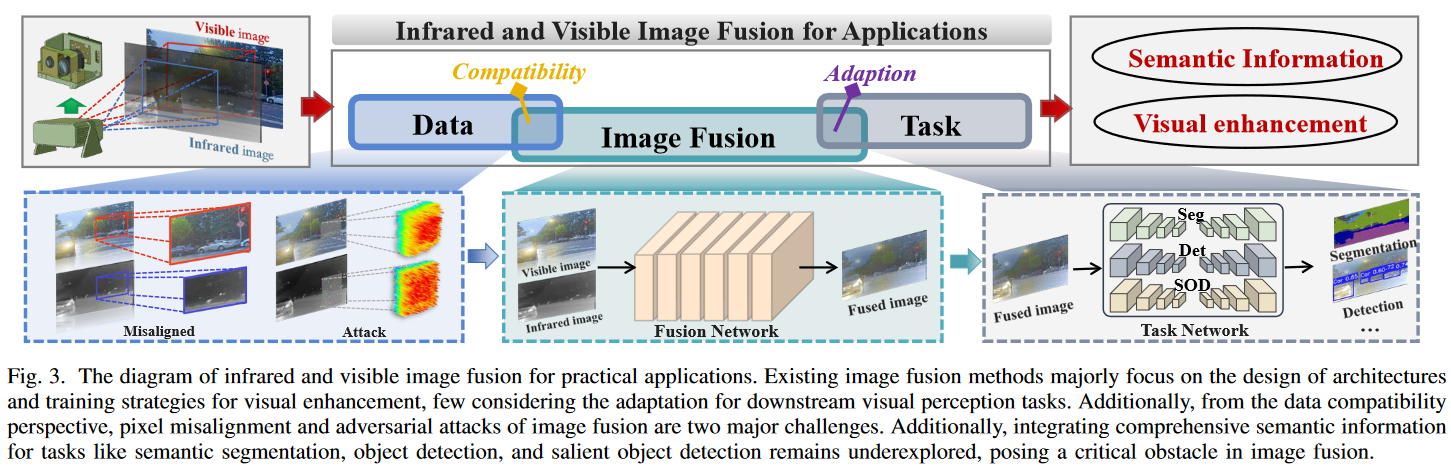 图 3 给出了用于实际应用的 IVIF 完整流程。总之,IVIF 的总体目标是生成一个既能实现视觉增强,又能提升环境感知性能的融合图像。
图 3 给出了用于实际应用的 IVIF 完整流程。总之,IVIF 的总体目标是生成一个既能实现视觉增强,又能提升环境感知性能的融合图像。
3.2 任务解析
1.核心目标与原理 (Complementary Information):
- 基本概念: IVIF 属于多模态图像融合领域,其根本出发点是不同类型的传感器捕捉现实世界信息的互补性。
- 可见光图像 (Visible): 依赖反射光成像,与人眼感知类似。其优势在于高分辨率、丰富的纹理细节和色彩信息,能很好地表现场景的结构和细节。但其致命弱点是严重依赖光照条件,在夜晚、强光/阴影、雾霾、烟尘等恶劣环境下性能急剧下降。
- 红外图像 (Infrared, 通常指热红外): 依赖物体自身发射的热辐射成像。其优势在于全天候工作能力(不受光照影响)、穿透烟雾能力以及突出热目标(如人、车辆发动机)的能力。其劣势在于分辨率通常较低、缺乏纹理细节和色彩信息、对比度可能不高,有时难以区分材质相同但温度相近的不同物体。
- 融合目标: IVIF 的核心目标就是设计算法,将可见光图像的纹理细节与红外图像的热目标信息/轮廓信息有效结合,生成一张信息更丰富、对环境描述更全面的图像,克服单一传感器的局限性。
2.应用价值 (Synergy & Robust Perception):
- 提升场景理解: 融合图像提供了更完整的信息,有助于后续的分析和决策。
- 增强鲁棒性: 这是 IVIF 最重要的价值之一。在例如自动驾驶、智能监控、军事侦察、搜索救援等应用中,系统需要在各种光照和天气条件下(白天、黑夜、雨雪、雾霾)都能稳定工作。IVIF 通过结合两种模态的优势,显著提高了视觉系统在这些动态和恶劣条件下的感知可靠性。例如,夜间驾驶时,融合图像可以同时显示道路的纹理(来自可见光,如有微光)和行人/动物的热信号(来自红外)。
3.关键挑战 (Challenges in Practical Applications):
- (i) 图像配准 (Registration): 这是 IVIF 领域一个长期存在的经典难题。
- 原因: 红外和可见光传感器通常物理位置不同(导致视差)、内部参数不同(焦距、光学畸变)、成像原理不同(导致几何和辐射度量差异)、分辨率可能不同。这些因素导致原始获取的图像在空间上是不对齐的。
- 难点: 大多数传统的或基于学习的融合算法都假设输入图像是像素级精确对齐的。然而,实现这种精确对齐非常困难,配准误差会严重影响融合效果,甚至引入错误信息(如重影、模糊)。开发对配准误差不敏感或能处理未配准图像的融合方法是一个重要的研究方向。
- (ii) 融合目标与下游任务的协同 (Fusion for High-Level Tasks): 这是近年来 IVIF 研究的一个重要趋势。
- 传统问题: 很多早期的 IVIF 方法主要追求视觉效果上的增强,即生成的图像看起来更清晰、对比度更高、信息更丰富(对人眼友好)。评价指标也多集中在信息熵、空间频率、标准差等图像质量指标上。
- 实际需求: 在智能系统中(如自动驾驶车辆、检测机器人),融合图像最终是服务于下游的高级视觉任务,如目标检测、语义分割、深度估计等。
- 矛盾: 仅仅追求视觉效果的融合方法,其生成的图像不一定有利于这些下游任务。例如,某些融合方法可能为了视觉效果而平滑掉一些对目标检测器很重要的边缘信息,或者引入一些伪影干扰分割算法。
- 研究趋势: 因此,越来越多的研究开始关注任务驱动的融合,即融合算法的设计直接以提升下游任务(如目标检测精度、分割 IoU)为目标,或者将融合模块与下游任务模块进行端到端的联合训练。这种方法更能满足实际应用的需求。
4.总体目标 (Total Goal):
- 理想的 IVIF 技术应该能够实现双重目标:既要生成视觉上自然、清晰、信息丰富的图像(Visual Enhancement),也要使其有利于后续的智能分析任务,提升系统的整体环境感知性能/准确率 (Boost Environment Perception Rate/Performance)。这要求融合算法在信息提取、整合和表示方面做得更好,避免信息损失和伪影引入。
四. 文献综述
4.1 文献综述翻译
A. 以视觉增强为目的的融合
-
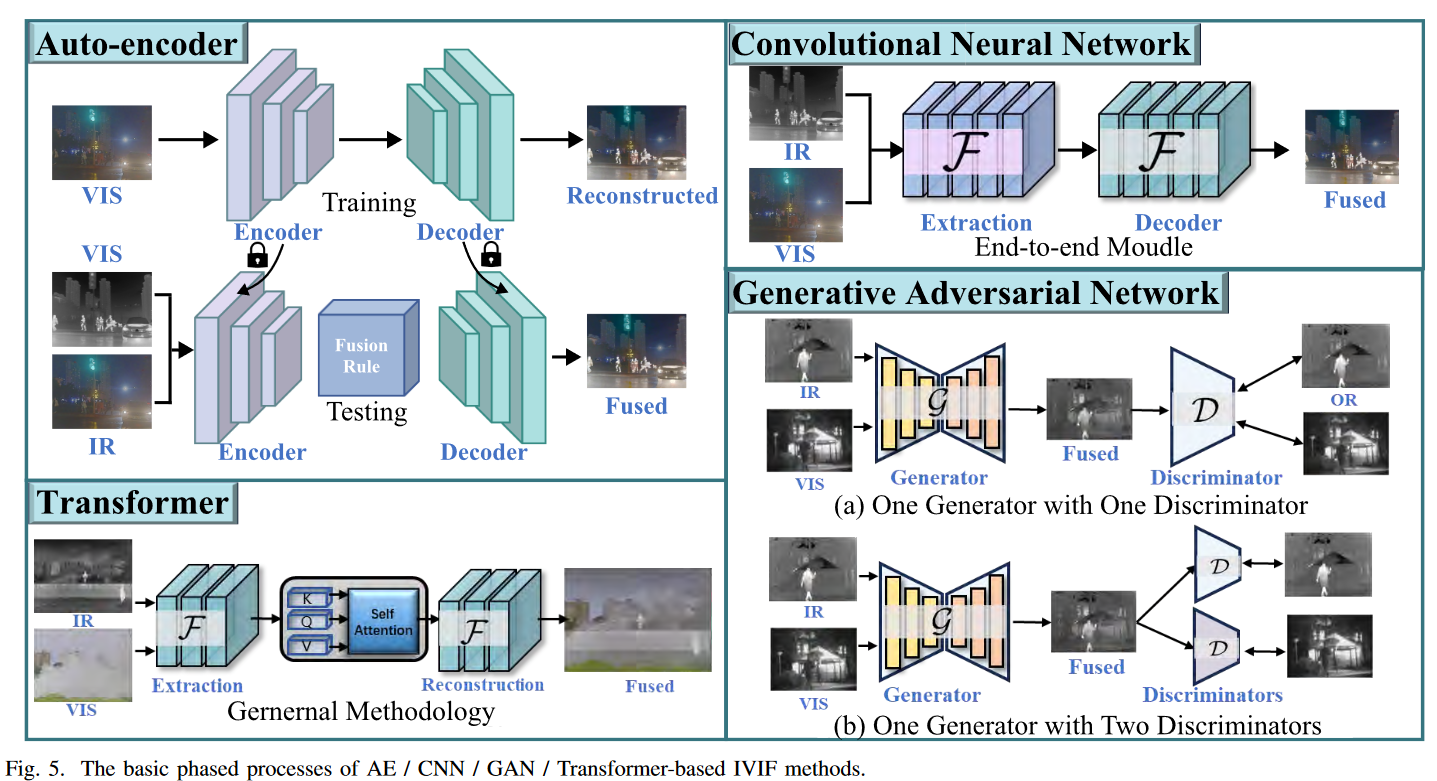
基于自编码器 (AE) 的方法: 基于自编码器 (AE) 的方法 [10]–[18] 包含两个步骤。首先,使用可见光和/或红外图像预训练一个自编码器。其次,使用训练好的编码器进行特征提取,并使用训练好的解码器进行图像重建。编码器和解码器之间的融合通常根据手动设计的融合规则执行,或者通过使用可见光-红外图像对进行第二阶段训练来学习,如图 5 所示。现有的 AE 方法可以分为两类:i) 融合规则和数据整合方面的增强,旨在改进多模态特征合成。ii) 网络架构方面的创新,包括引入新层和修改连接方式。
- 融合规则: DenseFuse [19] 作为融合策略方法的先驱,引入了两种核心方法:一种用于组合编码器生成的特征图的加法策略,以及一种使用 softmax 选择显著特征的基于 l1 范数的策略。这两种策略产生了优于传统方法的结果。为了进一步增强特征整合并强调关键信息,Li 等人 [20] 创新地将嵌套连接网络与空间/通道注意力模型相结合用于红外-可见光图像融合。它通过注意力模型突出了空间和通道的重要性,增强了多尺度深度特征融合,并在客观和主观评估中超越了其他方法。
- 网络架构: RFN-Nest [21] 以其新颖的网络架构脱颖而出,引入了一个残差融合网络 (RFN),旨在增强基于深度特征的图像融合,特别关注网络设计的复杂性以保留复杂细节。针对红外-可见光图像融合的复杂性,Liu 等人 [22] 通过其创新的网络结构推动了该领域的发展,该结构结合了多尺度特征学习和边缘引导的注意力机制,优化了架构以增强细节清晰度同时减少噪声。在网络创新领域,Zhao 等人 [23] 采用具有特殊设计的自编码器来有效分离和整合背景与细节特征,强调了通过策略性网络修改实现彻底的特征融合。扩展对网络驱动解决方案的关注,Zhao 等人 [24] 利用算法展开将传统优化重新概念化为一个结构化的网络过程,该过程经过精心设计以分离和融合不同频率信息,突显了通过策略性架构进步改善融合结果。
-
基于 CNN 的方法: 在基于 CNN 的图像融合算法 [25]–[35] 中,过程通常涉及三个主要步骤:特征提取、融合和图像重建,如图 5 所示。此类算法的关键优势在于它们能够从数据中自主学习复杂和高级的特征。在基于 CNN 的图像融合方法领域,三种创新方法脱颖而出:i) 受优化启发的 CNN 方法利用迭代整合和可学习模块来提高融合效率。ii) 修改损失函数对 IVIF 任务中的无监督学习结果起着关键性的定义作用。iii) 架构进步侧重于优化网络设计,其中 NAS 作为一种用于结构优化的专门方法。
- 受优化启发: 基于模态特征的自然先验,提出了受优化模型启发的学习模型用于红外与可见光图像融合 [24], [36], [37]。这些方法通常将网络引入迭代过程,受优化目标引导,或用可学习模块替换数值运算。Li 等人 [36] 引入了 LRRNet,将低秩表示 (Low-Rank Representation) 应用于网络设计,从而增强了可解释性。Liu 等人 [37] 提出了一种基于双层优化的融合方法,专注于图像分解。Zhao 等人 [24] 采用算法展开进行图像融合,针对跨模态的低频/高频信息。
- 损失函数: 损失函数是关键的目标,对于 IVIF 这种无监督图像处理任务,其设置至关重要。PIAFusion [38] 采用了一种创新的光照感知损失,由一个评估场景光照的子网络引导,显著改善了各种光照条件下的图像融合。扩展上下文感知处理,STDFusionNet [39] 使用由显著目标掩码增强的损失函数,优先将关键的红外特征与可见光纹理整合,极大地改善了特征整合和图像清晰度。
- 结构: 早期关注网络结构的工作集中于利用和微调如残差网络 [28], [40]–[43]、密集网络 [41], [44]–[50] 和 U-Net 等架构,此处不再详述。这里介绍的专注于设计网络结构的方法,大多融入了新颖的技术方法来升级融合算法。IGNet [51] 创新地结合了 CNN 和图神经网络 (GNN) 进行红外-可见光图像融合。它首先进行基于 CNN 的多尺度特征提取,然后采用图交互模块将这些特征转换为图结构,以实现有效的跨模态融合。此外,其在 GCNs 中的领导节点策略增强了信息传播,从而更有效地保留了纹理细节。Yue 等人引入了 Dif-Fusion [52],利用扩散模型构建多通道分布,能够直接生成具有高色彩保真度的彩色融合图像。特别地,神经架构搜索 (NAS) 近年来在图像融合领域取得了广泛发展,它可以自动发现所需的架构,避免了大量的手工架构工程和专门调整。在超网构建方面,提出了基于自编码器范式的 SMoA [53],基于两个模态特定的编码器充分表示典型特征。为了解决目标模糊和细节丢失问题,Liu 等人 [54] 开发了一种分层聚合融合方法,旨在实现全面的目标和细节表示。此外,Liu 等人 [55] 提出了一种硬件延迟感知方法来构建轻量级网络,减少了计算需求并有助于实际部署。最近,提出了一种具有充分融合收敛性的隐式搜索策略 [56],与现有方法 [57], [58] 相比显示出卓越的性能。
-
基于 GAN 的方法: 生成对抗网络 (GAN) [59] 已证明其在无标签监督下建模数据分布的有效性。这种无监督方法天然适用于 IVIF 任务,其中 GAN 已成为一种主要方法论。现有方法可分为两类,如图 5 所示:i) 单判别器 [60]–[70] 利用原始 GAN 来约束融合图像使其与某一模态相似。ii) 双判别器 [29], [71]–[83] 利用两个判别器来平衡典型的模态信息。
- 单判别器: Ma 等人首先提出了 FusionGAN 方法 [65],包含一个旨在保留红外强度和纹理细节的生成器,以及一个保证可见光图像中纹理细节的判别器。随后,同一团队 [84] 通过两个损失函数进一步改进了 FusionGAN。提出了细节损失和边缘损失来约束 FusionGAN 中红外目标的边界。大量方法专注于设计最优的生成器以产生视觉上吸引人的结果。例如,Fu 等人 [85] 应用密集连接块构建生成器以保留融合图像的纹理细节。Ma 等人提出了 GANMcC [66],引入了一种更平衡的训练方式,带有对可见光和红外图像的多分类任务。其生成器包含两个子模块,包括用于提取纹理细节的梯度路径和用于强度信息的对比度路径。
- 双判别器: Xu 等人提出了 DDcGAN [71],利用两个判别器来强制(融合图像)与不同模态的相似性。Ma 等人通过将 U-Net 生成器替换为密集连接块来扩展了 DDcGAN [72]。遵循这种范式,设计了许多具有一个生成器和两个判别器的方法。Li 等人提出了 AttentionFGAN [73],将多尺度注意力机制引入到生成器和判别器的构建中。通过注意力损失的监督,该方法可以保留源图像中注意力区域的信息。Zhou 等人提出了 SDDGAN [74],设计了信息量判别来估计信息的丰富度。Gao 等人 [76] 使用密集连接和多尺度融合构建生成器,并提出了内容和模态的重构损失。Rao 等人 [77] 提出了注意力和转换模块来构成生成器,以滤除噪声并提高恶劣条件下的质量。Wang 等人 [86] 在 ICAFusion 中利用对偶判别器,通过将融合结果的分布与源图像匹配来确保平衡融合,同时交互式注意力模块增强了特征提取和重构。此外,他们开发了 FreqGAN [87],整合了对偶频率约束判别器,可以动态调整每个频带的权重。单判别器的主要缺点是大多数方法仅提供单一模态的监督,使得融合图像要么类似于可见光模态,要么类似于红外模态(即模态不平衡),这导致互补特征(即红外图像的像素强度和可见光图像的纹理细节)无法同时保留。因此,引入了针对不同模态的对偶判别器来解决这个问题。然而,对偶判别器的主要障碍是引导模态特定的判别器提取多样的模态特征,包括来自热辐射的显著目标和来自可见光模态的丰富纹理细节。
- 基于 Transformer 的方法: 受益于基于自注意力机制的强大表示能力和长距离依赖建模能力,研究人员正在探索将这种机制用于红外-可见光图像融合 [88]–[93]。基于 Transformer 的融合方法大多利用组合的 CNN-Transformer 网络,聚合 CNN 块来提取浅层特征,并利用 Transformer 块来构建长距离依赖关系。VS 等人 [94] 开创性地将 Transformer 用于图像融合,引入了多尺度自编码器和空间 Transformer 融合策略来聚合局部和全局特征信息。Ma 等人 [95] 提出了 SwinFusion,利用 Swin Transformer [96] 构建了两种注意力模块。提出了自注意力和交叉注意力机制来整合特定模态内部以及跨域之间的长距离依赖。Tang 等人提出了 Y 型 Transformer YDTR [97],通过 CNN 和 Transformer 的组合构建编码和解码分支,并级联了视觉 Transformer 块 [98]。此外,Tang 等人 [99] 提出了局部-全局并行架构,由局部特征提取和全局特征提取模块组成,以更好地用局部互补特征描述局部互补特征。最近,提出了 DATfusion [100],通过双重注意力和 Transformer 块的交互实现图像融合,这在保留重要特征和全局信息方面起着至关重要的作用。{CMTFusion [101] 引入了跨模态 Transformer,通过移除空间和通道冗余来有效保留互补信息,并使用门控瓶颈增强跨域交互以改进特征融合。Yi 等人 [102] 应用基于 Transformer 的模型 Text-IF 进行文本引导的融合,通过利用文本语义编码器和语义交互融合解码器来解决(融合)退化问题并实现交互式结果。Zhao 等人 [103] 引入了 CDDFuse,一个用于 IVIF 的双分支 Transformer-CNN 框架,它使用分解来提取跨模态特征,并利用来自 Restormer [104] 的混合模块进行无损信息传输。Liu 等人 [105] 利用视觉-语言模型中基于提示的学习来指导图像融合,通过语义提示增强目标识别和融合质量。} 基于 Transformer 的方法有效捕捉长距离依赖关系(这对于理解跨模态关系至关重要),同时自注意力有助于在图像融合中保留全局上下文。然而,这些方法需要高计算资源和大量内存,使得在现实世界中部署具有挑战性。
B. 面向应用的
多模态红外与可见光图像融合因其广泛的现实世界应用(例如,自动驾驶和机器人操作)而受到极大关注。在所有任务中,目标检测和语义分割已变得尤为核心,因为它们是与融合相关应用连接最紧密的任务,如图 6 所示。已经提出了许多方法和数据集来应对这些挑战,使它们成为关键的研究热点和未来研究方向。在本部分中,我们将深入探讨专门为这两项任务开发的方法,并详细探讨它们的最新进展,同时介绍该领域内其他相关任务。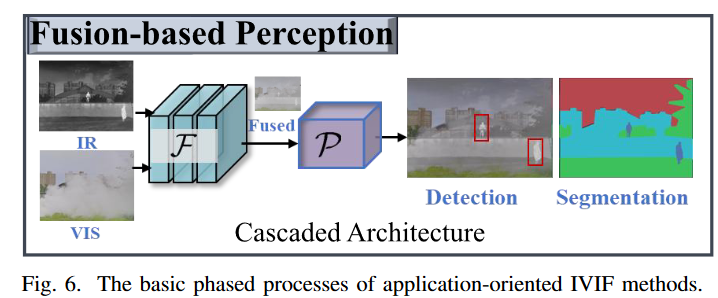
-
目标检测: 对于目标检测,Liu 等人开创性地探索了图像融合与目标检测的结合,称为 TarDAL [79],并发布了最大的多模态目标检测数据集 M3FD。TarDAL 提出了一个双层优化公式来建模这两个任务之间的内在关系,并将该优化展开为一个目标感知的双层学习网络。Zhao 等人 [106] 引入了元特征嵌入来实现目标检测与图像融合之间的兼容性。Sun 等人提出了令人印象深刻的 DetFusion [107],利用检测驱动的信息通过共享注意力机制来指导融合的优化。目标感知损失在从目标位置学习像素级信息方面也起着关键作用。Cao 等人提出了 MoE-Fusion [108],整合了局部-全局专家混合体来动态提取各自模态的有效特征。这种针对局部信息和全局对比度的动态特征学习证明了其在目标检测上的有效性。Zhao 等人提出了 MetaFusion [106],它利用来自目标检测的元特征嵌入来对齐语义和融合特征,从而实现有效的联合学习。与基于融合的方法相反,一些方法专注于使用红外和可见光图像进行目标检测,而不产生融合图像。这些方法通过利用注意力机制的跨模态交互、光谱特征的迭代细化、检测结果的概率集成以及对齐模态间特征来增强检测,以提高精度 [109]–[112]。
-
语义分割: 对于语义分割,SeAFusion [113] 将图像融合与分割任务级联,引入语义损失,通过基于循环的训练来增强融合的信息丰富度。Tang 等人提出了 SuperFusion [114],一个用于多模态图像配准、融合和语义感知的通用框架。PSFusion [115] 在特征层面引入了渐进式语义注入,考虑了融合的语义需求。它还表明,在计算资源较少的情况下,图像级融合为感知任务提供了与特征融合相当的性能。最近,Liu 等人提出了 SegMiF [116],它利用双任务相关性来增强分割和融合性能,引入了分层交互式注意力进行细粒度任务映射,并收集了这些任务最大的全时段基准数据集。Zhang 等人提出了 MRFS [117],一个耦合学习框架,通过相互增强来整合图像融合和分割,实现了增强的视觉质量和更准确的分割结果。除了其他基于融合的分割方法外,双流红外-可见光语义分割也受到关注。这些方法通常在编码器或解码器阶段融合模态特定的特征。基于编码器的融合方法早期聚合特征,如 [118]–[121] 中的工作所示,而基于解码器的融合在重构期间结合特征,如 [122]–[125] 中所展示。总的来说,这些双流方法补充了更广泛的基于融合的语义分割技术领域。最近,桥接图像融合和语义感知的统一解决方案已成为一个有吸引力的话题。Liu 等人 [126] 引入了统一的双层动态学习范式,以保证图像融合既具有视觉吸引力的结果,又能服务于下游感知任务。Liu 等人 [127] 使用检测和分割任务来指导损失函数的自动化搜索过程,解放了人力,并能够在 CAF 框架中构建用于感知任务的融合方法。提出了 TIMFusion [56] 通过隐式架构搜索来发现硬件敏感网络,通过前置元初始化实现对不同任务的快速适应,同时增强视觉质量并支持各种语义感知任务。
-
其他感知任务: 红外和可见光模态不仅对融合任务有用,还在各种其他感知应用中发挥关键作用,例如目标跟踪、人群计数、显著目标检测和深度估计。
- 目标跟踪 [128]–[136]: 利用 RGB-T 模态的像素级、特征级和决策级融合来增强跟踪的鲁棒性和可靠性。
- 人群计数 [137]–[143]: 受益于多模态特征融合以改进密度估计和人群预测。
- 显著目标检测 [144]–[148]: 利用双流框架和融合模块来结合 RGB-T 数据的互补线索,以实现更精确的目标描绘。
- 深度估计 [54], [101], [149]–[151]: 通过光谱转移和风格迁移方法得到增强,以处理变化的照明条件并改善跨模态匹配。
C. 数据兼容性
-
免配准方法: 尽管大量为精确对齐的多模态图像量身定制的融合方法已经涌现,但为未精确对齐的多模态图像设计的融合方法才刚刚开始引起关注。现有的针对未精确对齐多模态图像的融合方法可以分为两类:i) 生成伪标签,将多模态配准转换为单模态配准,称为基于风格迁移的方法。ii) 构建模态无关的特征空间,将多模态图像特征映射到共享空间,并利用共享特征来预测形变场,称为基于潜空间的方法。
- 基于风格迁移的方法: 通用方案涉及模态转换网络 (MTN) 和空间变换网络 (STN) 的联合学习。由于跨模态图像之间缺乏直接监督,现有方法 [152]–[154] 利用 MTN 将图像从一种模态转换到另一种模态,从而生成相应的伪标签。随后,采用 STN 来预测源图像和伪标签图像之间的空间位移。Nemar [152] 开创性地使用单模态度量来训练多模态图像配准。它利用双向训练方法,可选择“先空间配准,后图像转换”和“先图像转换,后空间配准”的选项,这鼓励图像转换网络生成保留了几何属性的伪标签图像,从而改进配准。UMFusion [153] 提出了一个高度鲁棒的无监督框架用于红外和可见光图像融合,专注于减轻由未对齐多模态图像引起的重影伪影。具体来说,引入了跨模态生成-配准范式来生成伪标签,旨在从像素层面减少红外和可见光图像之间巨大的模态差异。带着类似的目标,RFNet [154] 通过相互增强来实现多模态图像的配准和融合,而不是将它们视为独立的优化目标。在 RFNet 中,多模态图像配准被定义为一个从粗到精的过程,并且精配准和融合通过交互式学习协同结合,以提高融合图像的质量并加强融合对配准的相互促进效应。
- 基于潜空间的方法: 主要思想是从多模态图像中提取共同特征,这从特征层面减少了红外和可见光图像之间的模态差异。典型地,MURF [155] 认为模态无关的特征对于配准至关重要,因此建议将多模态特征映射到一个模态无关的共享空间。MURF 将配准分为两个阶段,即粗配准和精配准。在粗配准阶段,使用对比学习来约束共享特征表示的生成。另外两种方法,SuperFusion [114] 和 ReCoNet [156],直接从跨模态特征中学习用于配准的形变参数。前者通过在光度约束和端点约束的监督下估计双向形变场来校正输入的几何畸变,并对称地结合配准和融合以实现相互促进。后者开发了一个循环校正网络来显式补偿几何畸变,从而减轻融合图像中的重影。
-
通用融合方法: 在多模态图像融合研究中,通用融合框架作为整合不同成像技术的重要技术。这些框架因其算法通用性和优越的可扩展性,在医学成像以及红外和可见光成像等领域展示了潜在应用。它们通过深度特征学习和结构优化,完成从纹理细节到高级语义信息的全面特征提取。此外,这些框架利用多样的损失函数,如感知损失和结构相似性损失,来确保融合图像的质量和完整性。解决多模态图像融合中通用融合框架的核心方面:i) 损失函数增强: 创新侧重于先进的损失度量以提升图像质量。ii) 架构创新: 升级旨在优化特征提取和网络效率。
- 损失函数创新对于提高融合模型性能至关重要。关键进展包括:Zhang 等人 [164] 开创性地使用了经感知损失训练的卷积框架,无需后处理即实现了细节增强和广泛的任务适用性。Xu 等人 [162] 创新地使用信息论进行输入加权,增强了损失优化和任务统一。Xu 等人 [166] 采用无参考图像质量评估 (NR-IQA) 和熵进行权重调整,确保了稳定的质量并减少了对真值的依赖。最后,Liu 等人 [167] 利用对比学习进行损失精炼,增强了跨模态一致性和信息保留。Zhao 等人提出了 EMMA [170],一个自监督学习范式,通过引入伪感知模块和感知损失来改进传统融合损失,有效模拟了感知成像过程。
- 结构: 结构演变的特点是为多模态数据整合量身定制的创新设计:Li 等人 [171] 引入了一个具有多个任务特定编码器和一个通用解码器的框架,提高了特征提取的精度并促进了跨各种融合任务的知识交换。Liu 等人 [56] 利用隐式架构搜索 (IAS) 来动态优化模型结构,并结合来自相关感知任务的见解以改进无监督学习和模型通用性。Liu 等人 [37] 通过分离基础层和细节层处理,推进了多模态融合中的结构优化,采用双层优化来精炼纹理和细节表示,同时确保融合输出中的结构完整性。Zhao 等人提出了 FILM [169],该方法利用大语言模型,通过从图像生成语义提示,使用 ChatGPT 生成文本描述,并通过交叉注意力指导融合过程,增强了特征提取和上下文理解。
-
攻击: 对抗攻击 [172], [173],即向图像添加不可区分的扰动,很容易欺骗神经网络的估计。基本工作流程如图 7 所示。多模态视觉网络在对抗攻击下的脆弱性尚未得到广泛研究。考虑到多模态分割在对抗攻击下的鲁棒性,PAIFusion [161] 是第一个利用图像融合来增强鲁棒性的工作。这项工作通过详细分析识别了脆弱的融合操作和规则。我们认为,这是一个紧迫且具有挑战性的未来研究课题,因为它在确保现实世界应用的鲁棒性和安全性方面起着至关重要的作用。
D. 架构总结与讨论
基于深度学习的图像融合方法正通过采用日益复杂的模块以实现更好的建模来进行演进,这些方法按其网络结构分类:
- 使用现有架构: 许多研究 [12], [19], [21] 依赖于成熟的 CNN 结构,如级联、残差或密集连接块,利用它们在特征提取和信息整合方面已被证明的优势。
- 复杂堆叠网络: 此类方法 [13], [28], [41], [46], [88], [178] 将不同的上述块交织在一起,增强深度处理以获得优越的融合质量,并深入研究各种源图像的互补方面以获得更精细的融合结果。
- 多分支架构: 鉴于红外-可见光融合中的模态多样性,这些架构 [22], [23], [107] 整合了专用结构来处理不同的输入,使用不同的网络模块和参数来有效优化不同模态信息的融合。
- 递归架构: 强调迭代信息增强,这类方法使用递归设计 [156] 和扩散模型 [168] 来逐步改进融合质量,适合通过利用先验信息进行持续的图像改进来处理序列数据。 总的来说,红外与可见光图像融合的研究正朝着更复杂、更精炼的网络结构方向发展,以满足融合的复杂需求。
E. 损失函数总结与讨论
在无监督的红外与可见光图像融合领域,损失函数的设计和选择至关重要。这些函数通常可以从三个主要维度来理解和分类:像素层面、评估度量层面和数据特性层面。(请注意,本小节不讨论 GAN 和扩散模型等生成模型。)
- 像素层面: L1 和 MSE 损失函数 [19], [36], [156] 通过直接像素比较来评估图像相似性。
- 评估度量层面: SSIM [19], [21], [22], [94], [156] 是一个关键的评估度量,它通过考虑图像结构和质量来扩展相似性评估,反映了人类视觉感知。将不太常见的度量如空间频率 (SF) [97] 用作损失函数,则强调了图像的频率特性和视觉效果,从而在保持视觉舒适度的同时实现有效融合。
- 数据特性层面: 针对数据特性的损失函数,如图像梯度 [54], [166],专注于在融合过程中保留详细纹理。视觉显著图 (VSM [79], [116], [126]) 在像素层面的应用代表了一种创新,带来了更细致的融合效果。此外,基于复杂图像特征的损失函数,如梯度最大化或边缘提取 [51], [95], [100], [115], [153],以及包含感知损失和对比学习损失 [167],提供了更深刻的见解和解决方案。
损失函数的设计是多样的,除了上述类型外,还引入了许多特殊设计的损失。研究人员可以根据源图像的特性和任务需求来选择、组合和优化这些损失,推动图像融合领域的进一步发展和创新。
4.2 文献综述解析
1. 免配准方法 (Registration-free Approaches):
- 核心问题: 解决现实中红外与可见光图像难以精确配准的痛点。配准误差是传统融合方法产生伪影(如重影)的主要原因之一。
- 两大策略:
- 基于风格迁移: 思路巧妙,通过将一个模态“伪装”成另一个模态(生成伪标签),把棘手的跨模态配准转化为相对容易的单模态配准。代表作如 Nemar [152], UMFusion [153], RFNet [154] 等探索了不同的训练策略(双向、生成-配准联合、相互增强)来提升伪标签质量和配准精度。挑战在于风格迁移的保真度,尤其是在保留精细几何结构方面。
- 基于潜空间: 从特征层面入手,试图提取模态间的共性特征或将特征映射到模态无关的共享空间,基于这些更鲁棒的特征进行配准或形变估计。代表作如 MURF [155](使用对比学习)、SuperFusion [114]、ReCoNet [156](直接估计形变)。优势在于可能对模态差异更不敏感,挑战在于如何有效学习并利用这种模态无关的共享特征。
- 意义: 免配准方法极大地提升了 IVIF 技术的实用性,降低了对输入数据预处理的要求。
2. 通用融合框架 (General Fusion Approach):
- 目标: 不局限于特定任务或模态,追求算法的通用性、可扩展性,希望能适用于多种融合场景(如医学图像融合)。
- 特点: 强调全面的特征提取(从细节到语义)、灵活的网络结构和先进的损失函数。
- 创新点:
- 损失函数: 从经典的感知损失 [164]、结构相似性,发展到结合信息论 [162]、无参考图像质量评价 (NR-IQA) [166]、对比学习 [167],甚至引入自监督的伪感知模块 (EMMA [170]),目标是更智能、更自适应地优化融合质量,减少对真值的依赖。
- 架构: 发展出任务特定编码器+通用解码器 [171] 以适应多任务;利用隐式架构搜索 (IAS) [56] 动态优化结构;采用双层优化分离基础/细节处理 [37];甚至引入大语言模型 (LLM) 进行语义提示引导融合 (FILM [169]),这代表了极具前瞻性的跨领域融合。
- 意义: 通用框架的研究推动了融合理论和技术向更深层次、更广范围发展,并探索与大模型等前沿 AI 技术的结合。
3. 对抗攻击 (Attack):
- 新兴领域: 关注 IVIF 系统在受到恶意设计的微小扰动(对抗攻击)时的鲁棒性和安全性。
- 现状: 研究尚不充分,但其重要性日益凸显,尤其是在自动驾驶、安防等安全攸关领域。
- 初步探索: PAIFusion [161] 是该方向的早期尝试,它不仅研究了融合对鲁棒性的可能增强作用,也分析了融合操作本身的脆弱性。
- 未来方向: 这被明确指出是未来研究的紧迫且具有挑战性的课题。如何评估、提升 IVIF 模型的对抗鲁棒性将是未来研究的热点。
4. 架构总结 (Architectures Summary):
- 分类: 将现有深度学习架构归纳为四类:使用现有成熟模块(基础)、复杂堆叠(加深加宽)、多分支(处理模态差异)、递归/迭代(信息精炼,如 Diffusion)。
- 趋势: 清晰地指出了 IVIF 网络结构日益复杂化和精细化的趋势,以应对融合任务的挑战。
5. 损失函数总结 (Loss Function Summary):
- 分类: 从像素、评估度量、数据特性三个维度对(非生成模型的)损失函数进行分类,非常系统化。
- 内容: 涵盖了从基础的 L1/MSE、SSIM,到基于梯度、空间频率 (SF)、视觉显著图 (VSM)、边缘信息,再到更高级的感知损失和对比学习损失。
- 核心思想: 强调了损失函数在无监督 IVIF 中的核心引导作用。如何选择、组合以及设计新的损失函数以更好地保留互补信息、提升视觉质量或服务特定任务,是 IVIF 研究的关键一环。
6. 对偶判别器 GAN (Dual Discrimination GANs):
- 核心思想: 为了解决单判别器 GAN 可能产生的“模态不平衡”(融合结果过于偏向某一模态而丢失另一模态信息)问题,引入两个判别器,分别对融合结果与红外、可见光图像进行约束,力求平衡地保留两种模态的特征。
- 发展: 从基础的 DDcGAN [71] 出发,后续工作通过改进生成器结构(如密集连接 [72])、引入注意力机制(AttentionFGAN [73])、设计新的判别准则(信息量判别 [74])、增加重构损失 [76]、加入特定模块(注意力与转换模块 [77])、频率域约束(FreqGAN [87])等方式不断优化。
- 挑战: 尽管目标是平衡,但如何精确地引导两个判别器分别关注各自模态的关键互补信息(红外的热显著性 vs 可见光的纹理细节)仍然是一个难点,需要精巧的网络设计和损失函数约束。
7. 基于 Transformer 的方法 (Transformer-based Approaches):
- 核心优势: Transformer 的自注意力机制能够有效捕捉图像中的长距离依赖关系和全局上下文,这对于理解和融合来自不同传感器、可能具有不同空间结构和语义信息的红外与可见光图像非常有帮助。交叉注意力机制则特别适合处理跨模态特征交互。
- 主流架构: 目前常见的是 CNN + Transformer 混合架构。利用 CNN 在早期提取局部特征的效率和优势,然后利用 Transformer 处理更高级别的特征交互和全局依赖关系。
- 多样化创新: 文献中列举了多种基于 Transformer 的创新:
- 基础应用与多尺度结合 [94]。
- 引入高效变种如 Swin Transformer 并设计特定注意力模块 (SwinFusion [95])。
- 特定结构设计如 Y 型网络 (YDTR [97])、局部-全局并行架构 [99]。
- 结合双重注意力 (DATfusion [100])、跨模态 Transformer (CMTFusion [101])。
- 引入跨学科方法:文本引导融合 (Text-IF [102])、提示学习 (Prompt-based [105]),这代表了融合与自然语言处理、视觉-语言大模型结合的新兴方向。
- 结合分解思想和高效模块 (CDDFuse [103])。
- 挑战: Transformer 的强大能力伴随着高计算量和内存消耗,这限制了其在资源受限平台(如移动设备、嵌入式系统)上的实时部署。如何设计高效、轻量化的 Transformer 融合模型是一个重要的研究方向。
8. 面向应用的融合 (Application-oriented Fusion):
- 重大转变: 这是 IVIF 研究从追求视觉效果向服务下游任务、提升系统性能的关键转变。自动驾驶、机器人等实际应用场景是主要驱动力。
- 核心任务: 目标检测和语义分割是当前最受关注的两个下游任务。
- 目标检测:
- 融合后检测: 研究如何设计融合算法,使其输出的融合图像最有利于后续的目标检测器(如 TarDAL [79], DetFusion [107], MoE-Fusion [108], MetaFusion [106])。关键在于建立融合过程与检测任务的内在联系,例如通过双层优化、元特征、检测驱动的注意力/损失、专家混合等。
- 无显式融合检测: 另一类方法不生成中间的融合图像,而是直接在特征层面进行跨模态交互、对齐或集成,最终输出检测结果 [109]–[112]。这可能更高效,但需要精心设计跨模态交互模块。
- 数据集: M3FD [79] 等专用数据集的出现极大地推动了该方向的研究。
- 语义分割:
- 融合后分割/级联: 将融合作为预处理或与分割级联(如 SeAFusion [113]),并通过语义损失等方式让融合过程感知分割任务的需求。
- 特征级融合/注入: 在特征提取过程中逐步注入语义信息或进行特征融合(如 PSFusion [115], SegMiF [116], MRFS [117])。
- 双流架构: 分别处理两种模态,在编码器或解码器阶段进行特征融合 [118]–[125]。
- 性能与效率权衡: PSFusion [115] 指出图像级融合在计算量较少时也能达到与特征级融合相当的感知性能,这提示我们需要根据具体应用场景权衡效果与效率。
- 基准: SegMiF [116] 提出的全时段基准数据集对推动公平比较和研究进展非常重要。
- 目标检测:
- 统一框架与自动化:
- 统一范式: 寻求能够同时优化视觉效果和下游任务性能的统一框架(如统一双层动态学习 [126])。
- 自动化设计: 利用自动化方法(如基于任务反馈搜索损失函数 [127]、基于 NAS 搜索硬件敏感网络 TIMFusion [56])来设计面向特定感知任务的融合方法,减少人工设计成本并可能发现更优的解决方案。这代表了 IVIF 领域智能化、自适应化的前沿方向。
- 其他感知任务: 列举了目标跟踪、人群计数、显著目标检测、深度估计等任务,表明红外与可见光数据的结合具有广泛的应用潜力,并且在这些领域也发展出了相应的融合策略(像素级、特征级、决策级融合等)。
五.基准与评估指标
5.1 基准与评估指标
A. 基准 (Benchmark)
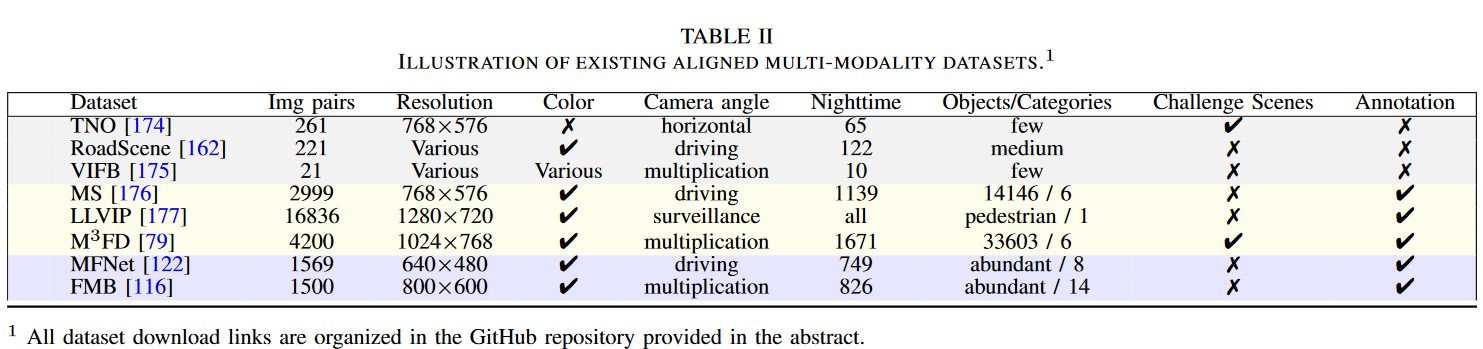
随着红外与可见光图像融合领域的进展,大量数据集被提出和使用。它们大致可分为三类:面向早期融合的数据集、旨在用于目标检测的融合数据集以及用于语义分割的融合数据集。表 II 提供了它们各自特性的详细概述,而图 8 则展示了其中典型的图像对。
 B. 评估指标 (Evaluation Metric)
B. 评估指标 (Evaluation Metric)
-
面向融合的指标 (Fusion-oriented Metric): 本节总结了 9 个融合指标:5 个有参考指标 (MI, VIF, CC, SCD, QAB/F) 和 4 个无参考指标 (EN, SF, SD, AG)。
- 互信息 (MI) [181]: 衡量从源图像传递到融合图像的信息量。
- 视觉信息保真度 (VIF) [182]: 评估与人类视觉系统一致的融合保真度,值越高表示性能越好。
- 相关系数 (CC) [8]: 评估融合图像如何反映其源图像,关注线性相关性。
- 差异相关和 (SCD): 衡量来自源图像的独特信息被整合的程度。(注:与 CC 强调现有关系不同,SCD 更关注新元素的整合)。
- 基于梯度的融合性能 (QAB/F) [183]: 评估边缘细节的保留情况,得分接近 1 表示有效的边缘保留。
- 熵 (EN) [184]: 衡量融合图像中的信息含量,但对噪声敏感。
- 空间频率 (SF) [185]: 评估细节和纹理的清晰度,值越高表示边缘和纹理信息越丰富。
- 标准差 (SD) [186]: 从分布和对比度方面反映图像质量,对比度越高导致 SD 值越大。
- 平均梯度 (AG) [187]: 衡量纹理特征和细节,AG 值越高表示融合性能越好。
-
配准指标 (Registration Metric): 配准结果采用三个广泛接受的指标进行评估,即均方误差 (MSE) [188]、互信息 (MI) 和归一化互相关 (NCC) [189]。
- MSE: 衡量两幅图像像素之间的平均平方差,评估它们的对齐度。较低的 MSE 值表示相似性更高,使其成为图像配准和融合中的关键指标。
- MI: 上面介绍的互信息也是图像配准中流行的相似性度量。较高的 MI 意味着两幅图像对齐得很好。
- NCC: 是一种评估两幅图像内对应窗口之间相似性的指标,用于评估配准精度。
-
感知指标 (Perception Metric): 这部分介绍了用于分割和检测任务的关键指标。
- 在语义分割中,交并比 (IoU) 衡量预测区域与真实区域之间的重叠度,平均交并比 (mIoU) 是跨类别的平均值。像素准确率 (Acc) 表示正确分类像素的比例,而平均像素准确率 (mAcc) 是跨类别的平均值。
- 在目标检测中,基于 IoU 阈值定义的召回率 (Recall) 和精确率 (Precision) 定义了真阳性。平均精度 (AP) 衡量单类别性能,而平均精度均值 (mAP) 是对所有类别的 AP 进行平均。
六.性能总结
6.1 性能总结翻译
A. 图像融合 (Image Fusion)
在本节中,我们采用三个最常用的融合数据集(TNO、RoadScene 和 M3FD)来比较各种先进融合方法的性能,使用的是原始作者发布的预训练模型。

- 定性比较: 我们从 M3FD 中选择了典型的挑战性场景图像来评估融合的可视化效果,如图 9 所示。该场景的一个主要困难是烟雾,这是一个具有挑战性但非必要的元素。IGNet 避免了其大部分影响,但因此过度偏向红外图像。虽然 CoCoNet 突出了人和背景车辆的信息,但它在无烟雾背景(红色框中的草地)中表现出色彩偏差。相比之下,CAF 和 MoEFusion 部分避免了烟雾的影响,同时防止了色彩偏差。
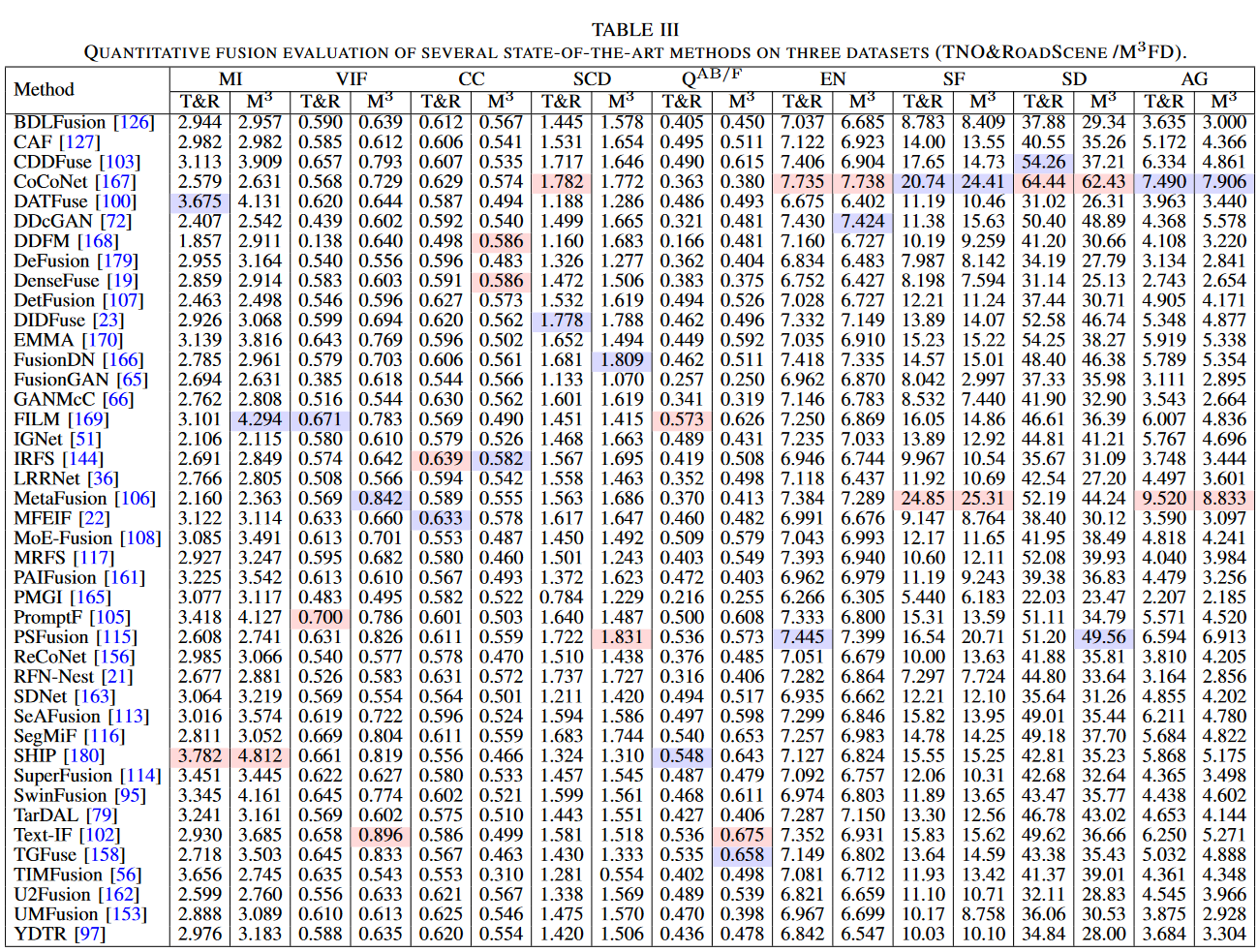
- 定量比较: 使用第 IV-B 节介绍的 9 个融合指标来比较定量结果,其中从 TNO 中随机选择 57 对图像,从 RoadScene 中选择 221 对,从 M3FD 融合数据集中选择 300 对进行计算。具体指标如表 III 所示。在有参考指标中,使用基于传统源图像的损失函数的方法具有显著优势(例如 DenseFuse 的 CC),因为它们充分保留了源图像信息。为分割优化的方法在视觉保真度指标如 VIF 上也显示出优势(例如 PromptF),因为它们充分利用了语义信息。在无参考指标中,利用特征级对比损失优化整个训练过程的 CoCoNet 实现了远超常规损失函数的表示能力,从而在性能上脱颖而出。
B. 未对齐图像融合 (Registration-based Image Fusion)
我们调研了 7 种未对齐多模态图像融合方法,包括 UMFusion [153]、SuperFusion [114]、ReCoNet [156]、RFVIF [190]、SemLA [160]、MURF [155] 和 IMF [191],并使用 9 个广泛使用的指标评估了它们在轻微形变下的融合性能。
- 定性比较: 图 10 显示了各种融合方法面对未对齐红外和可见光图像时的定性结果。通过观察,基于风格迁移的配准和融合方法(UMFusion 和 IMF)以及有监督的 SuperFusion 取得了相当的结果,有效校正了结构失真和边缘重影。相比之下,基于潜空间的方法(RFVIF、SemLA 和 ReCoNet)在融合图像中仍表现出一些残留形变。此外,结果表明,在融合图像的目标显著性和纹理丰富度方面,IMF、MURF 和 UMFusion 在排名前三的方法中表现更优。

- 定量比较: 表 IV 报告了在 RoadScene 和 M3FD 数据集上未对齐红外和可见光图像的定量结果。由于使用了真值形变场作为监督,SuperFusion 在几个有参考指标(如 MI、VIF、CC 和 QAB/F)上表现出色。此外,基于风格迁移的先配准后融合方法(例如 UMFusion 和 IMF)在有参考指标上取得了次优结果。相比之下,基于潜特征空间的方法在几个无参考指标(例如 EN、SF、SD 和 AG)上表现更优。这种现象表明基于风格迁移和基于潜特征空间的方法各有优势。开发能够利用它们各自优势的框架具有巨大潜力。
C. 用于目标检测的图像融合 (Image Fusion for Object Detection)
在本部分,我们采用 YOLO-v5 作为基础检测器,使用来自所有方法的融合图像在统一的训练设置下进行训练,并使用 M3FD 作为训练和测试的数据集。由于 M3FD 中存在大量连续捕获的图像,简单的随机抽样划分数据集容易导致过拟合。在本研究中,我们随机选择了 100 组 10 张连续图像作为测试集,这些场景在训练集中几乎不存在,以验证融合方法的鲁棒性。
- 定性比较: 如图 11 所示,展示了不同融合方法在具有挑战性的小目标场景中的检测精度。影响检测的主要因素有两个:场景遭受退化(雾、雨、强光)以及弱纹理使得桥上的行人难以检测。像 DDFM、LRRNet 和 ReCoNet 这样的方法产生低对比度的融合图像,未能突出红外目标,而像 DDcGAN 和 IRFS 这样的方法产生伪影导致错误检测。然而,TarDAL 和 PAIFusion 有效地检测到了所有行人。这突显了互补信息(例如热目标)和处理退化对于提高检测性能的重要性。

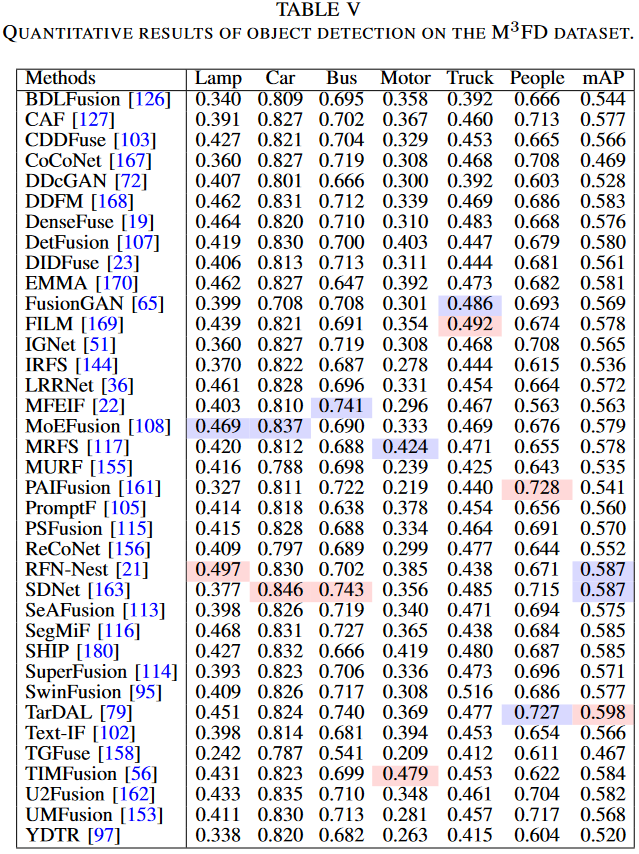
- 定量比较: 我们在表 V 中展示了检测结果,包括不同类别的 AP@0.5 以及总体精确率、召回率、mAP@0.5 和 mAP@0.5:0.95。出现了两个关键观察结果:首先,面向检测的融合方法 TarDAL 通过保留热目标细节和纹理信息提供了最高的精度,在检测汽车和行人方面表现出色。其次,感知引导的方法如 SegMiF 和 TIMFusion 通过语义特征注入和任务损失引导表现出强大的性能,而 U2Fusion 和 SDNet 则平衡了跨模态的信息保留。
D. 用于语义分割的图像融合 (Image Fusion for Semantic Segmentation)
我们统一使用先进的 SegFormer [192] 作为基础分割器来衡量各种先进融合方法的性能,所有方法都在一致的设置下使用相应的融合图像进行训练。应用了 FMB 数据集官方的训练集和测试集划分。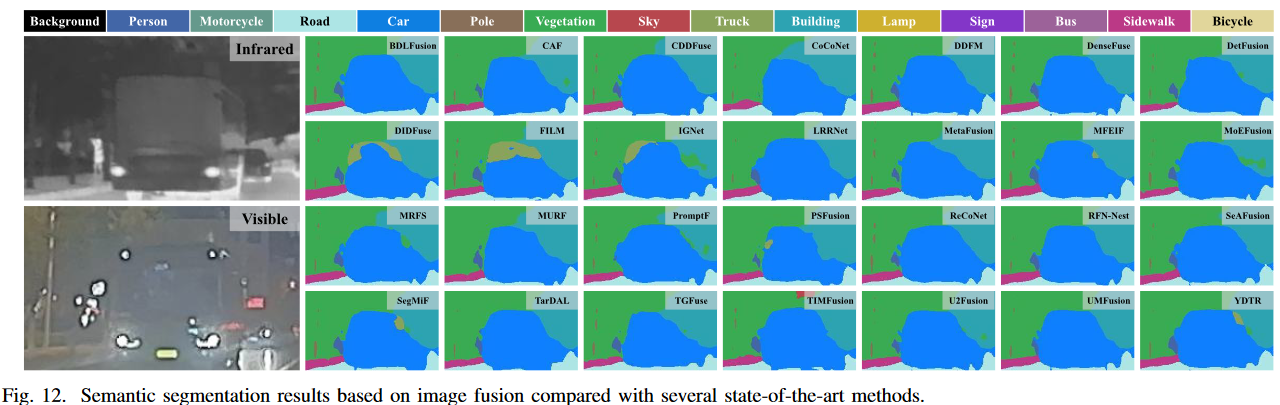
- 定性比较: 图 12 展示了一个典型的夜间城市场景的定性比较。在这种场景下,位于黑暗区域的行人对于大多数方法来说都难以精确分割,因为可见度低。同时,公交车发出如此强的光线,导致场景过度曝光,使得许多方法将公交车误分类为汽车,并且未能捕捉其完整轮廓。这些挑战突显了处理具有极端光照条件的场景仍然存在的困难。
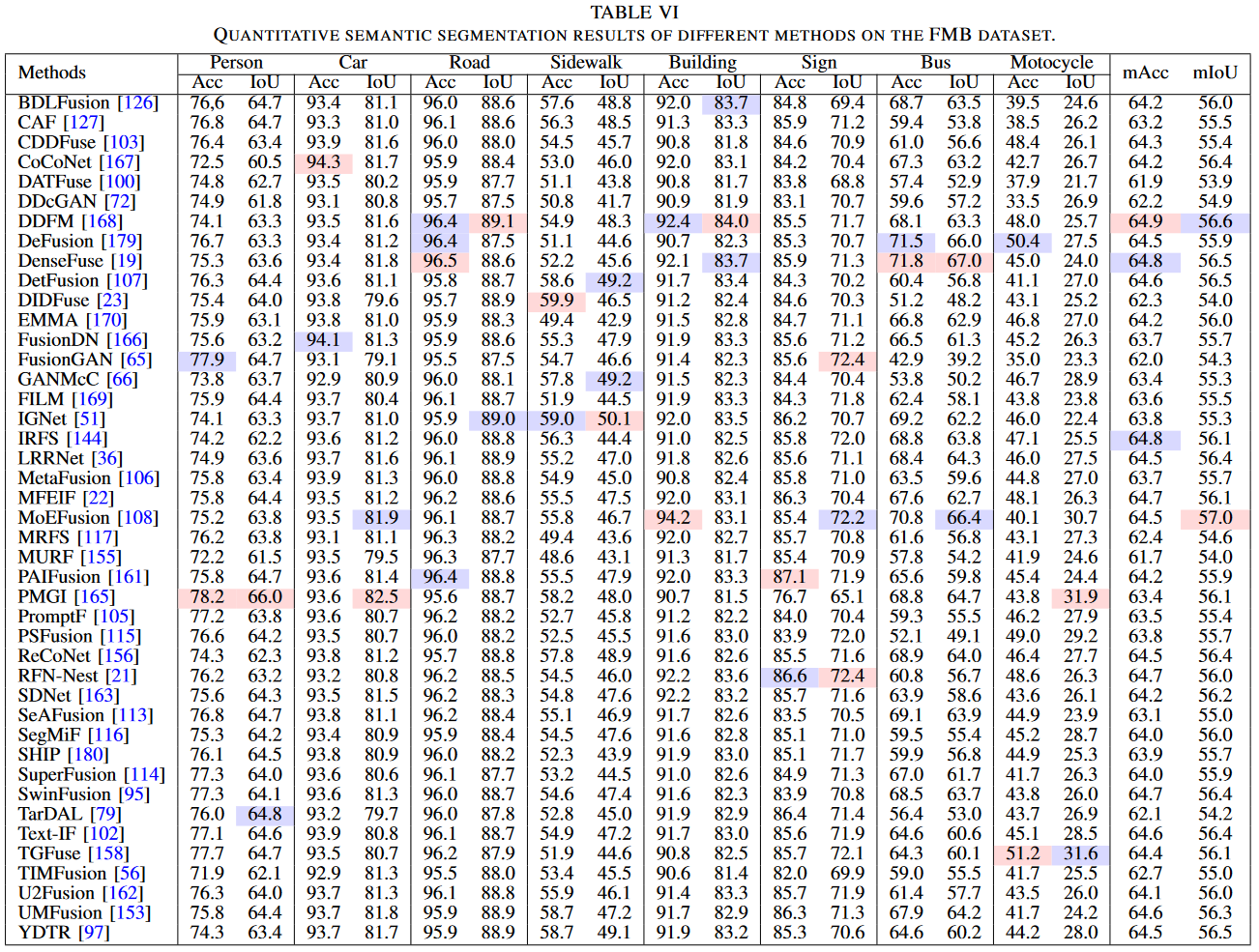
- 定量比较: 在表 VI 中,我们报告了分割任务的数值结果。与在检测任务中观察到的趋势类似,感知引导的融合方法(例如 MoEFusion 和 DetFusion)由于其任务特定损失的引入或学习策略,展示了有竞争力的分割性能。
E. 计算复杂度分析 (Computational Complexity Analysis)
在本部分,我们选择三个关键指标来比较计算效率:平均运行时间、网络模型参数量和 FLOPS(每秒浮点运算次数)。平均运行时间关注算法或模型完成特定任务所需的时间,是速度和效率的直观度量。而 FLOPS 是模型计算量的度量,表示前向传播过程中的浮点运算次数。参数量,包括权重和偏置的总数,反映了模型的大小和复杂度。参数量越多的模型可能表现出更强的学习能力,但也可能导致更高的计算和存储成本。通常,模型的参数量与其 FLOPS 趋于成正比,而 FLOPS 的增加通常会导致更长的运行时间。对于我们的实验,我们在 Nvidia GeForce 4090 上测试了来自 M3FD 数据集的 10 张随机图像集,每张分辨率为 1024×768。为了消除 CPU 的影响,我们利用来自 CUDA 的官方事件函数来测量 GPU 上的运行时间,并排除初始值计算平均值。最终结果以 ms(毫秒)、M(百万)和 G(十亿)为单位呈现在表 VII 中。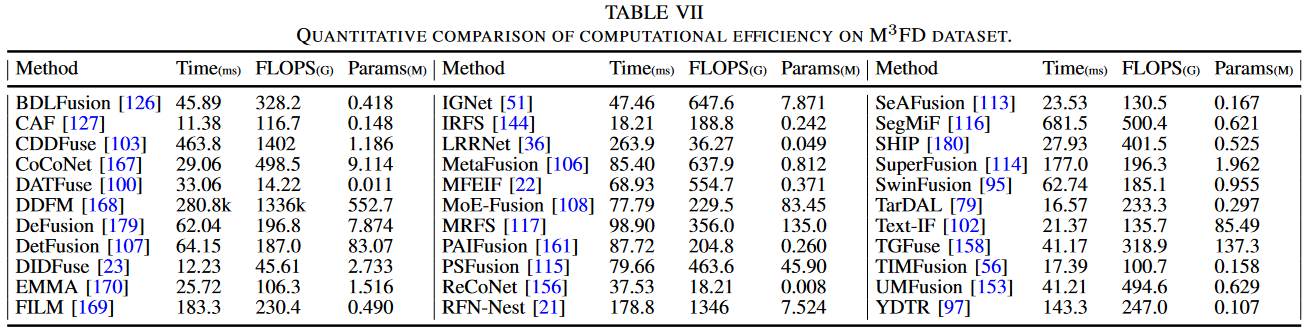 显然,不同方法在平均运行时间、FLOPS 和参数量方面存在显著差异。例如,Densefuse,一个极其简单且过时的方法,设法在保持较低参数量和 FLOPS 的同时实现了非常低的运行时间。相比之下,利用扩散模型的 DDFM 在参数量和 FLOPS 方面远超其他方法,其运行时间高达 280.8k ms。这可能表明该方法在实际应用中的效率相对较低。
显然,不同方法在平均运行时间、FLOPS 和参数量方面存在显著差异。例如,Densefuse,一个极其简单且过时的方法,设法在保持较低参数量和 FLOPS 的同时实现了非常低的运行时间。相比之下,利用扩散模型的 DDFM 在参数量和 FLOPS 方面远超其他方法,其运行时间高达 280.8k ms。这可能表明该方法在实际应用中的效率相对较低。
6.2 性能总结解析
A. 图像融合性能 (纯视觉增强):
- 方法: 在标准数据集 (TNO, RoadScene, M3FD) 上,使用统一的评估指标(9个融合指标)对各种方法(使用作者发布的预训练模型)进行定性和定量比较。
- 定性发现 (图9 - 烟雾场景): 不同的方法在处理挑战性场景(如烟雾干扰)时各有取舍。有的可能为了避免干扰而损失部分信息(偏向红外),有的可能引入新的问题(颜色偏差),有的则在避免干扰和保持信息间取得较好平衡。这说明没有绝对最优的方法,效果可能依赖于具体场景和评价侧重点。
- 定量发现 (表III):
- 指标与损失函数的关联: 结果验证了方法的优化目标(损失函数)与其在对应指标上的表现密切相关。基于源图像损失的(如DenseFuse)在有参考指标上占优;面向下游任务优化的(如PromptF)在某些保真度指标上可能较好;使用先进特征级损失(如CoCoNet的对比损失)在无参考指标(衡量内在信息量、对比度等)上表现突出。
- 无单一最佳: 再次印证没有能在所有指标上都最优的方法。
B. 未对齐图像融合性能:
- 方法: 对比了几种为未对齐图像设计的融合方法(包括基于风格迁移和基于潜空间的)在轻微形变下的表现。
- 定性发现 (图10): 基于风格迁移的方法 (UMFusion, IMF) 和有监督方法 (SuperFusion) 在视觉上似乎能更好地校正几何失真和重影。基于潜空间的方法可能仍有残留形变,但在目标显著性和纹理丰富度方面,某些方法(IMF, MURF, UMFusion)表现不错。
- 定量发现 (表IV):
- 监督方法的优势: SuperFusion 因为利用了真值形变场进行监督,在有参考指标上表现最好,这符合预期。
- 风格迁移 vs. 潜空间: 风格迁移方法在有参考指标上表现尚可(次优),而潜空间方法在无参考指标上表现更优。这揭示了一个重要的权衡: 风格迁移可能更擅长恢复宏观的几何对齐(有利于参考指标),而潜空间方法可能更擅长保留图像内容的内在特性(有利于无参考指标)。结合两者优势是未来一个有潜力的方向。
C & D. 面向应用(检测与分割)的融合性能:
- 核心目的: 评估融合技术对下游感知任务的实际提升效果,这是衡量 IVIF 技术实用价值的关键。
- 方法: 将各种融合方法生成的图像输入到统一的、先进的检测器 (YOLOv5) 和分割器 (SegFormer) 中,在标准数据集 (M3FD, FMB) 上进行训练和测试,使用任务的标准评估指标 (mAP, mIoU)。特别注意了 M3FD 数据集划分的过拟合问题,采取了更鲁棒的划分方式。
- 定性发现 (图11 - 检测, 图12 - 分割):
- 融合质量直接影响任务: 低对比度融合丢失目标,伪影导致误检/误分割。
- 挑战依然存在: 极端光照(黑暗、过曝)、恶劣天气、小目标等仍然是难点,即使融合也未必能完美解决。
- 定量发现 (表V - 检测, 表VI - 分割):
- 任务导向的优势: 明确证实了面向特定任务设计或优化的融合方法(如 TarDAL, SegMiF, TIMFusion, MoEFusion, DetFusion)在该任务上通常表现更好。这归因于它们能够更好地保留对任务重要的信息(如热目标细节、语义特征)或直接使用任务损失进行引导。
- 通用方法的局限: 仅追求视觉效果的通用融合方法,在下游任务上的表现可能并非最佳。
- 关键信息: 这两部分的实验结果强有力地支持了面向应用、任务驱动的 IVIF 研究方向的重要性。
E. 计算复杂度分析:
- 重要性: 在关注性能的同时,必须考虑算法的效率和资源消耗,这直接关系到其是否能在实际(尤其是资源受限的)平台上部署。
- 指标: 平均运行时间 (ms)、参数量 (M)、计算量 (FLOPS, G)。
- 发现 (表VII):
- 巨大差异: 不同方法的复杂度差异悬殊。简单方法(如 DenseFuse)非常轻量,而复杂模型(尤其是基于 Diffusion 的 DDFM)计算成本极高。
- 性能与效率的权衡: 通常存在性能与效率的 trade-off。追求极致性能往往伴随着高复杂度。
- 实用性考量: 像 DDFM 这样运行时间极长的方法,目前难以满足许多实时应用的需求。
- 意义: 复杂度分析为方法的实际选型提供了重要参考。未来研究需要在提升性能的同时,关注模型轻量化和运行效率。
七.未来趋势
A. 处理未对齐/攻击数据
图像配准是融合的关键因素,确保不同图像中的对应像素点精确对齐。在实际应用中,由于不同的成像原理(反射和辐射)和光谱范围,获取像素对齐的图像对具有挑战性。然而,很少有工作关注这些问题 [114], [153], [155], [156], [160], [190], [191]。我们预计未来的努力应侧重于设计与配准兼容的融合网络,或将配准作为总体损失函数的一个组成部分,从而创造出“鲁棒”的融合网络。
图像融合网络在复杂对抗场景中的鲁棒性,包括物理攻击(涉及失真和退化)和数字攻击(例如参数扰动),是一个重大挑战。核心问题在于当前方法论主要关注保留源图像细节,而没有充分解决融合元素与感知鲁棒性之间的关联。此外,在不损害整体性能的情况下增强对抗条件下鲁棒性的方法明显不足,普遍存在的问题如损失波动和(特定攻击)模式失效凸显了网络和训练优化的必要性。为了提高安全性,整合可见光和红外传感器已成为对抗单模态物理攻击的常用手段。虽然 PAIFusion [161] 已经探索了图像融合中的参数扰动,但有效对抗现实世界的物理攻击,特别是跨模态攻击 [193], [194],仍然是一项艰巨的任务。
B. 开发基准
高质量的基准对于 IVIF 社区的发展至关重要,最初由像 TNO、RoadScene 和 VIFB 这样的数据集所凸显,但它们的场景多样性和分辨率有限。为了推进感知任务,开发了如 MS 和 LLVIP 等数据集,提供了目标检测标签,但侧重于特定场景如道路和监控。为应对更广泛的挑战,M3FD 引入了恶劣天气条件和多样化场景。最近的数据集如 MFNet 和 FMB 通过广泛的标签满足复杂的语义任务需求。前者包含特定于驾驶场景的 8 个类别,后者则拥有涵盖多种环境的 14 个类别。
尽管上述基准缓解了 IVIF 领域的数据稀缺问题,但仍有三个紧迫的问题值得关注。i) 创建红外与可见光图像配准基准至关重要,因为现有基准侧重于像素对齐的图像对。开发能够精确反映现实世界差异并带有配准真值的基准,同时考虑成像差异和基线(传感器间距)等因素,对于学科进展至关重要。ii) 将 IVIF 基准扩展到包含多样化的高级任务是推动该领域发展的关键。虽然当前基准涵盖了目标检测和语义分割等任务,但新兴需求呼吁纳入其他任务(如深度估计和场景解析),以满足不断发展的研究方向和实际应用。iii) 探索多样化的挑战性场景:现有基准主要关注有限的场景,大部分数据来源于城市地区和学术环境。这鼓励我们探索要求更高的环境,例如隧道和洞穴(用于探索)、森林地形(用于军事监视)以及室内空间(用于救援任务)等。
C. 更好的评估指标
评估融合图像的质量是一个关键问题,尤其是在缺乏真值的情况下。传统指标如 EN、MI、CC 和 SCD 各自仅衡量图像质量的一个方面,并且可能与主观评估不一致,特别是在高噪声等条件下。因此,仅凭这些指标无法完全捕捉图像融合质量的本质。虽然利用后续任务性能(如目标检测或语义分割)可以提供一些见解,但难以全面反映视觉质量。因此,开发同时考虑视觉质量和感知质量的评估指标是一个必要的研究方向。
D. 轻量化设计
运行效率是 IVIF 实际应用的关键因素。当前方法论试图通过增加神经网络规模来实现高质量的融合图像,但这显著增加了参数量并对运行效率产生不利影响。虽然已经提出了一些策略,通过整合创新技术(如神经架构搜索 NAS、神经网络剪枝 NNP 和空洞卷积 AC)来缓解这些问题,但它们的有效性仍然严重依赖于先进 GPU 的计算能力。
鉴于这些挑战,未来的研究应更加重视追求轻量化网络设计。这涉及解决两个关键问题:首先,构建轻量级网络势在必行,因为大多数现有设备(例如无人机 UAV 和手持设备)无法支持重型 GPU 的计算需求。这需要探索更高效、资源消耗更少的网络架构。其次,开发硬件友好的融合方法至关重要,因为与重型图像计算单元相比,它们提供了更经济、更实用的解决方案。现有的大部分方法是在基于服务器的平台(使用 PyTorch、TensorFlow 等框架)上开发的,不易迁移到实际设备/产品上。因此,确保新方法能够适应实际硬件约束对于现实世界的应用和集成至关重要。
E. 与各种任务的结合
IVIF 作为一种基础图像增强技术,无疑可以促进/辅助/结合其他视觉任务。 i) 先进场景分析: 在自动驾驶车辆导航中,结合这两种类型的图像可以提供对环境更全面的理解,有助于在变化的照明和天气条件下做出更好的决策和避障。 ii) 深度估计和三维重建: IVIF 也可以增强深度估计和三维重建任务。结合红外/可见光的互补深度信息,可以生成更精确的环境三维模型。这在虚拟现实、增强现实和城市规划中具有潜在应用。 随着计算技术的不断发展,IVIF 在改变各个领域的潜力是巨大的,有望在不久的将来解锁新的能力和应用。
八.结论
在红外与可见光图像融合领域,已经取得了显著的进展。然而,关于技术与各种数据类型、实际应用和评估标准的契合度方面,仍然存在不确定性。在本综述中,我们从方法论和实践的视角阐明了这些方面,并包含了对配准、融合及相关任务的详细比较分析。本综述的目标是为这个不断发展的领域中的初学者和经验丰富的专业人士提供指导,鼓励这些技术的持续发展和应用。我们也重点指出了适宜未来研究的领域,希望能在这个充满活力的领域激发持续的创新。
推荐文章(部分):
江南大学李辉:
2020 IEEE TIM——Nestfuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models Nestfuse
2021 InfFus——Rfn-nestRfn-nest: An end-to-end residual fusion network for infrared and visible images Rfn-nest
2022 TIM——Swinfuse: A residual swin transformer fusion network for infrared and visible images SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images
大连理工罗钟铉团队(包括樊鑫):
2020 IEEE TIP——A bilevel integrated model with data-driven layer ensemble for multi-modality image fusion A bilevel integrated model with data-driven layer ensemble for multi-modality image fusion
2021 IEEE TCSVT——Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusionLearning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion
2021 ICME——Multiple Task-Oriented Encoders for Unified Image FusionMultiple Task-Oriented Encoders for Unified Image Fusion
2021 ACMMM ——Searching a hierarchically aggregated fusion architecture for fast multi-modality image fusion Searching a hierarchically aggregated fusion architecture for fast multi-modality image fusion
2022 CVPR——Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object DetectionTarget-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
2022 ECCV——Reconet: Recurrent correction network for fast and efficient multi-modality image fusion ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion
2023 IJCV——Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusionCoconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion
2024 IEEE TPAMI——A task-guided, implicitlysearched and metainitialized deep model for image fusion A task-guided, implicitlysearched and metainitialized deep model for image fusion
2024 IEEE/CAA JAS ——PromptFusion: Harmonized Semantic Prompt Learning for Infrared and Visible Image FusionPromptFusion: Harmonized Semantic Prompt Learning for Infrared and Visible Image Fusion
大连理工卢湖川团队:
2023 CVPR——MetaFusion: Infrared and Visible Image Fusion via Meta-Feature Embedding from Object DetectionMetaFusion: Infrared and Visible Image Fusion via Meta-Feature Embedding from Object Detection
西安交大张讲社团队:
2020 IJCAI——Didfuse: Deep image decomposition for infrared and visible image fusion Didfuse
2021 IEEE TCSVT——Efficient and model-based infrared and visible image fusion via algorithm unrolling Efficient
2023 ICCV——DDFM: Denoising Diffusion Model for Multi-Modality Image FusionDDFM: Denoising Diffusion Model for Multi-Modality Image Fusion
2023 CVPR ——CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image FusionCDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
江南大学吴小俊团队:
2023 IEEE TPAMI——Lrrnet: A novel representation learning guided fusion network for infrared and visible images Lrrnet
武汉大学马佳义团队:
2019 InfFus——Fusiongan: A generative adversarial network for infrared and visible image fusion Fusion Gan
2019 IJCAI——Learning a generative model for fusing infrared and visible images via conditional generative adversarial network with dual discriminators.Learning a generative model for fusing infrared and visible images via conditional generative adversarial network with dual discriminators
2020 IEEE TIP——Ddcgan: A dualdiscriminator conditional generative adversarial network for multiresolution image fusion DdcGan
2020 TPAMI——U2fusion: A unified unsupervised image fusion networkU2Fusion: A Unified Unsupervised Image Fusion Network
2020AAAI——Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensityRethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity
2021 IEEE TIM——Stdfusionnet: An infrared and visible image fusion network based on salient target detection Stdfusionnet: An infrared and visible image fusion network based on salient target detection
2022 IEEE CAA JAS——Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
2022 Inffus——Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network
2022 IEEE/CAA JAS——SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness SuperFusion: A Versatile Image Registration and Fusion Network with Semantic Awareness
2022 ECCV—— Fusion from decomposition: A self-supervised decomposition approach for image fusionFusion from Decomposition: A Self-Supervised Decomposition Approach for Image Fusion
2023 IEEE TIP——Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models Dif-fusion
2024 CVPR——Text-if: Leveraging semantic text guidance for degradation-aware and interactive image fusionText-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion
2024 CVPR——MRFS: Mutually Reinforcing Image Fusion and SegmentationMRFS: Mutually Reinforcing Image Fusion and Segmentation
温州大学 张笑钦团队(包括许佳炜):
2022 IEEE TMM——Infrared and Visible Image Fusion via Interactive Compensatory Attention Adversarial Learning Infrared and Visible Image Fusion via Interactive Compensatory Attention Adversarial Learning
2024 IEEE TCSVT——FreqGAN: Infrared and Visible Image Fusion via Unified Frequency Adversarial Learning FreqGAN: Infrared and Visible Image Fusion via Unified Frequency Adversarial Learning
2022 IEEE ICIP——Image Fusion Transformer Image Fusion Transformer
天津大学曹兵:
2022 ACMMM——DetFusion: A Detection-driven Infrared and Visible Image Fusion NetworkDetFusion: A Detection-driven Infrared and Visible Image Fusion Network
2023 ICCV——Multi-modal gated mixture of local-to-global experts for dynamic image fusionMulti-modal Gated Mixture of Local-to-Global Experts for Dynamic Image Fusion
武汉大学何发智团队、合肥工业大学刘羽:
2022 IEEE TMM——YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer
2023 Pattern Recognition——Tccfusion: An infrared and visible image fusion method based on transformer and cross correlation TCCFusion
2023 IEEE TCSVT——DATFuse: Infrared and Visible Image Fusion via Dual Attention Transformer DATFuse: Infrared and Visible Image Fusion via Dual Attention Transformer
清华大学张利团队:
2020 InfFus——IFCNN: A general image fusion framework based on convolutional neural network IFCNN: A general image fusion framework based on convolutional neural network

















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









