






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:图形学与几何计算
点云形状补全与生成是三维计算机视觉的研究热点及难点。虽然现有的工作在单个任务上能取得不错的效果,但往往难以被灵活且高效地推广到多种不同的点云生成任务。近期,清华大学的刘玉身团队于TPAMI 2022在线发表了一项重要成果SPD[1],提出了一种通用化的雪花反卷积(SPD)用于点云补全和多个生成类任务,包括:点云自编码、新形状生成、单视图重建以及点云上采样,并开源基于计图(Jittor)的代码。
Part 1
研究问题和背景
点云形状补全[2-3]旨在从输入的残缺点云来预测高质量的完整形状。但受限于点云先天离散性和局部非结构化生成[4-5]的特点,现有的点云补全工作往往无法很好地还原局部细节特征。此项工作的早期版本曾在ICCV 2021报告[6],其动机是提出一种新的网络结构(SPD)从而能够更好地捕捉和还原局部几何细节和结构特征,例如光滑表面,锐边和锐角等。每一层SPD接收前一层的点云作为输入,并对其中每个父节点进行分裂从而生成多个子节点,这样多层SPD相互协作,使得每个初始种子节点的后代节点如雪花生长一般在三维空间中展开(如图1所示)。
图1 雪花反卷积效果可视化
同时,SPD是一种通用化的点云生成模块,可进一步将其推广到了更多的点云生成类任务,包括点云自编码、新形状生成、单视图重建以及点云上采样,并在多个现有数据集上验证了SPD的细节生成能力和泛化能力。
Part 2
方法概述
如图2所示,每一层SPD接收前一层生成的点云作为输入,并对其中每个点进行分裂。SPD捕捉形状细节的核心在于使用Skip-Transformer来融合历史偏移特征以及形状上下文信息。
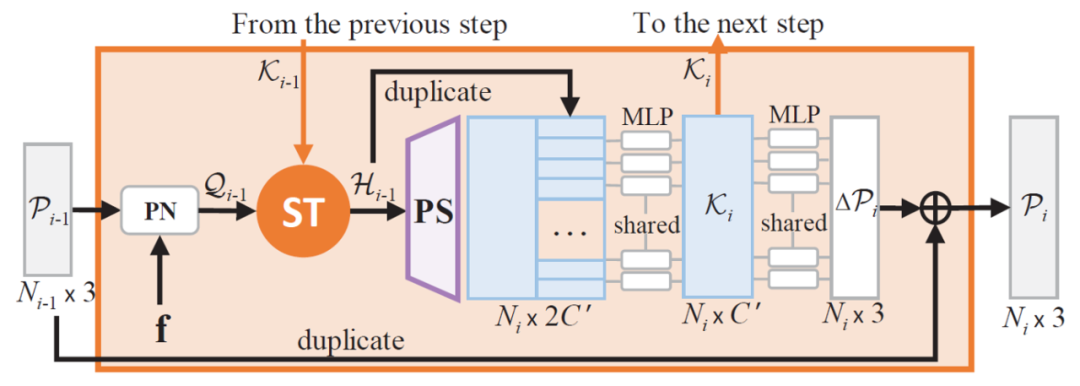
图2 雪花反卷积(SPD)
如图3所示,Skip-Transformer接收当前SPD的逐点特征和前一步SPD的偏移特征作为输入,利用注意力机制来融合这两者,从而生成当前SPD的形状上下文特征。
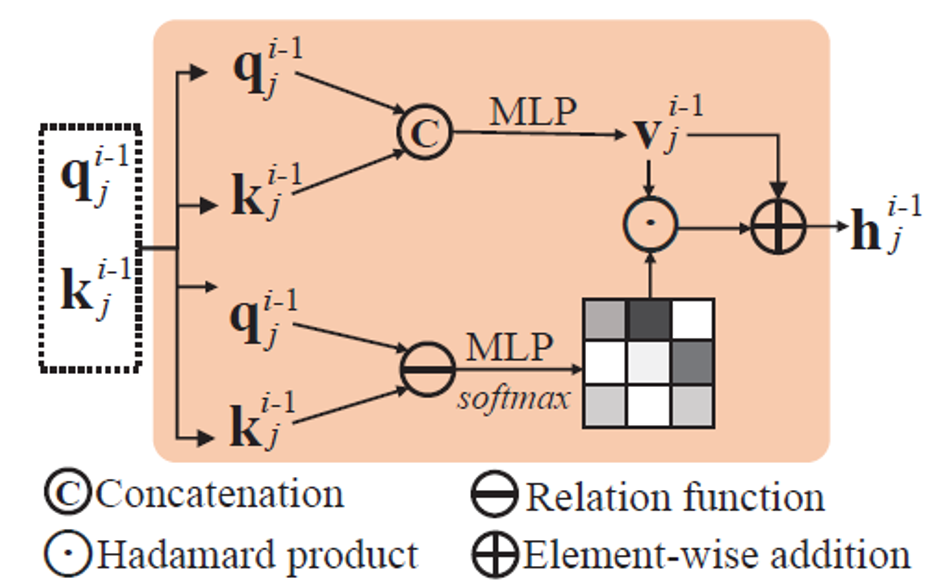
图3 Skip-Transformer
Part 3
结果展示
下面在多个任务的现有数据集上,进行了定量和定性的实验比较,展示量化和可视化的结果。
1) 点云补全,ShapeNet-34/21数据集
ShapeNet-34/21数据集常用于验证跨类别形状补全。其中34个类用于训练,另外21个未见过的类只用于测试。表1显示SPD方法在量化结果上相较于之前的方法有可观的提升。图4中展示了跨类别补全的可视化对比。
表1 ShapeNet-34/21补全数据集上的量化结果
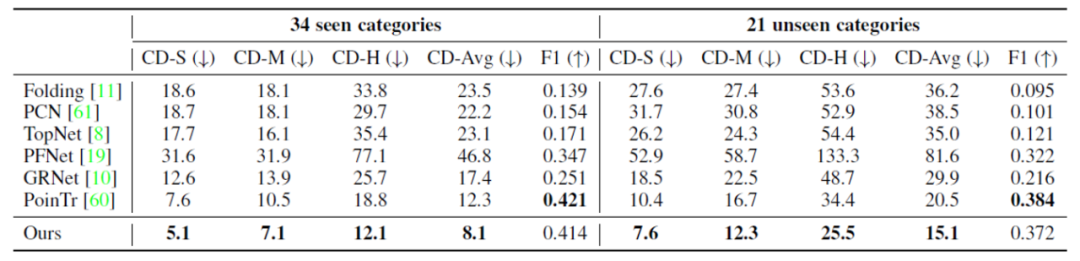
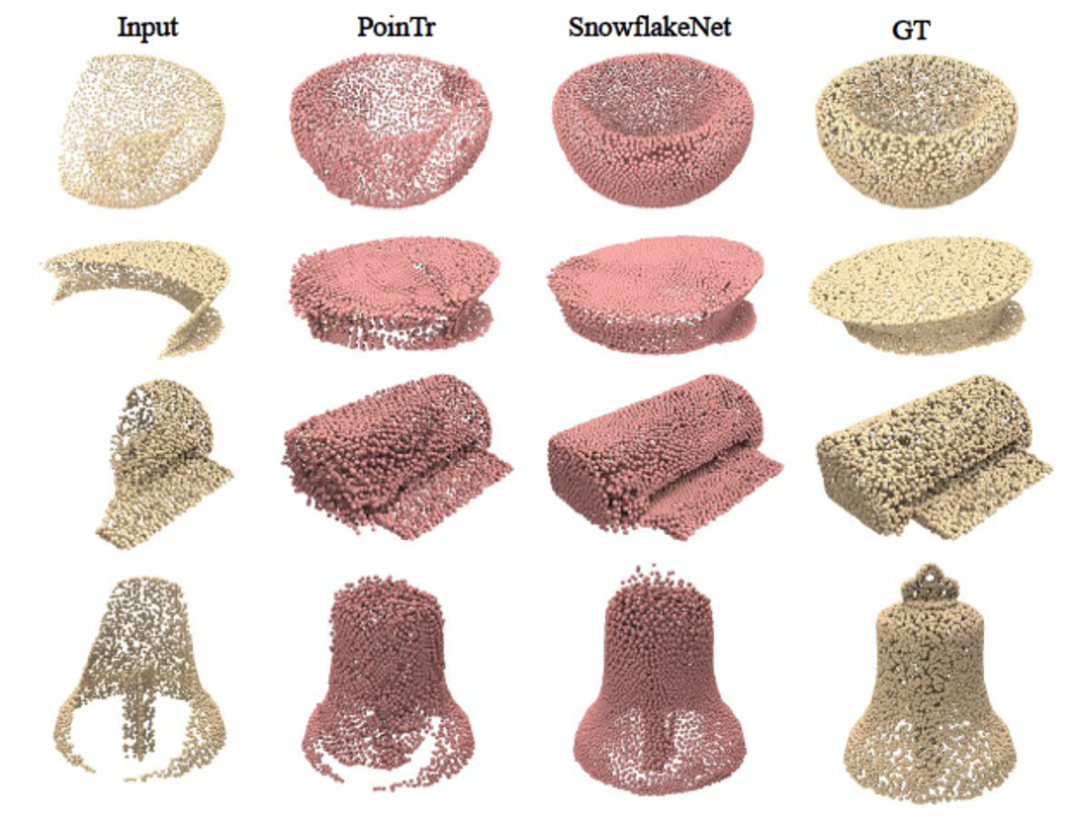
图4 ShapeNet-34/21数据集上跨类别补全可视化对比
2) 点云补全,ScanNet数据集
下面是ScanNet数据集的椅子类别上,验证SPD在真实数据集下的补全能力。表2和图5分别是量化和可视化对比。
表2 ScanNet数据集真实点云补全量化比较


图5 ScanNet真实点云补全可视化对比
3) 点云自编码,ShapeNet数据集
点云自编码(Auto-encoding)任务用于验证SPD从特征向量中解码完整点云的能力。下面展示在ShapeNet数据集上进行的实验,在编码器相同的情况下,SPD相较于现有方法具有更好的生成能力。表3和图6分别展示了量化和可视化对比。
表3 ShapeNet数据集上点云自编码量化比较
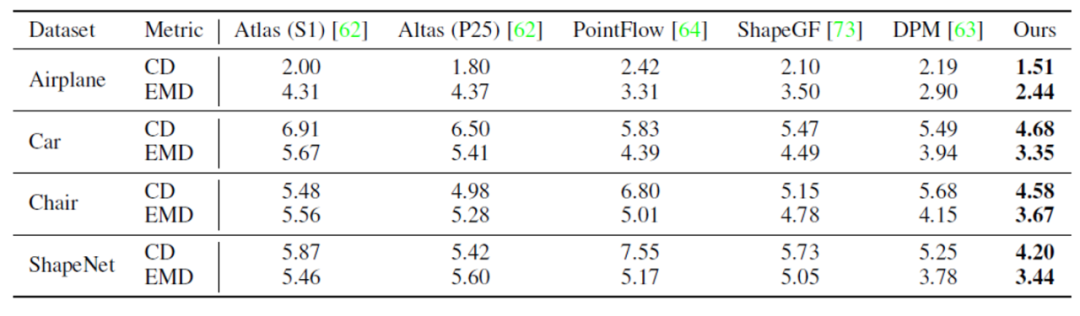

图6 ShapeNet数据集上点云自编码可视化对比
4) 新形状生成,ShapeNet数据集
同样在ShapeNet数据集上进行实验,也验证了SPD的新形状生成能力,结果如表4和图7所示。
表4 ShapeNet数据集上新形状生成量化比较
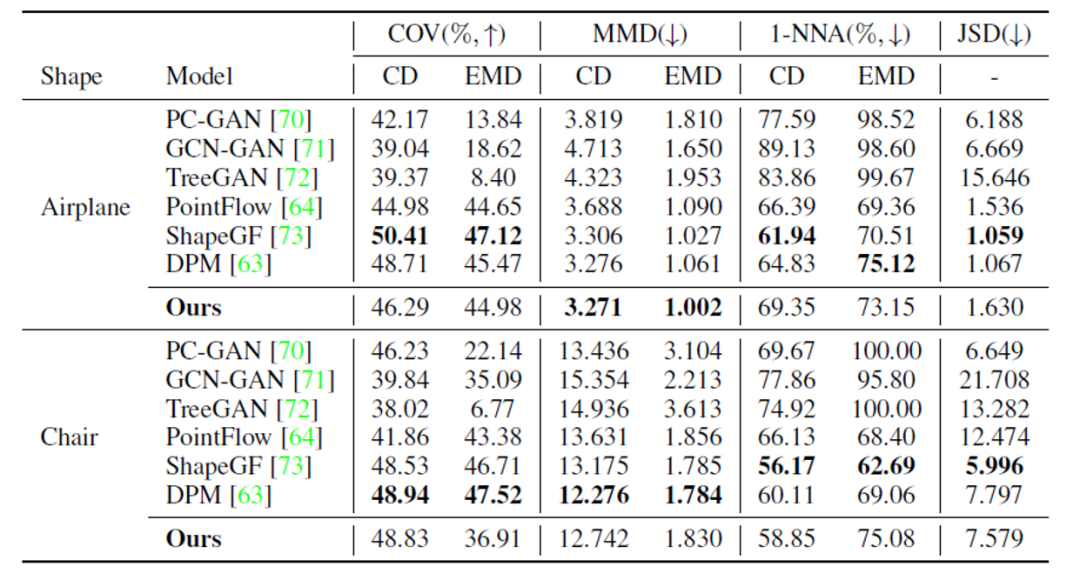

图7 ShapeNet数据集上新形状生成可视化
5) 单视图重建,ShapeNet
单视图重建任务可用于验证SPD从视图特征解码完整点云的能力。表5和图8分别是量化和可视化对比。
表5 ShapeNet数据集上单视图重建量化比较

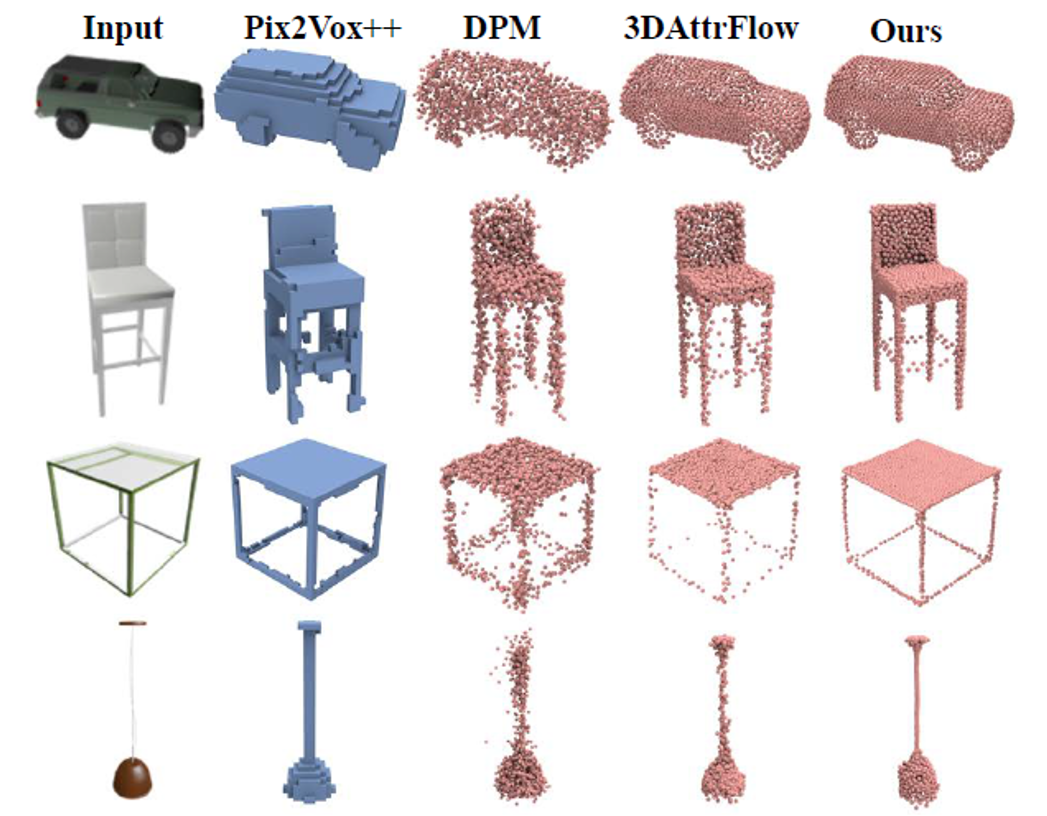
图8 ShapeNet数据集上单视图重建可视化对比
6) 点云上采样,PUGAN
SPD同样可以被应用于点云上采样任务。从量化(表6)及可视化(图9)结果可以看出SPD在保证模型轻量化的同时,可以达到接近甚至超越现有方法的上采样水平。
表6 PUGAN数据集点云上采样量化比较
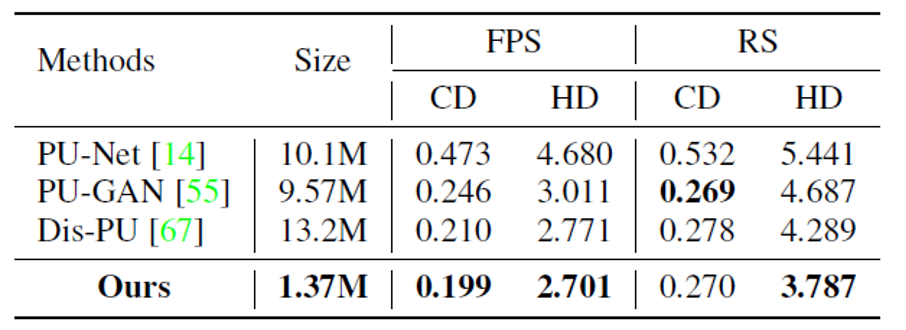

图9 PUGAN数据集点云上采样可视化对比
Part 4
计图开源
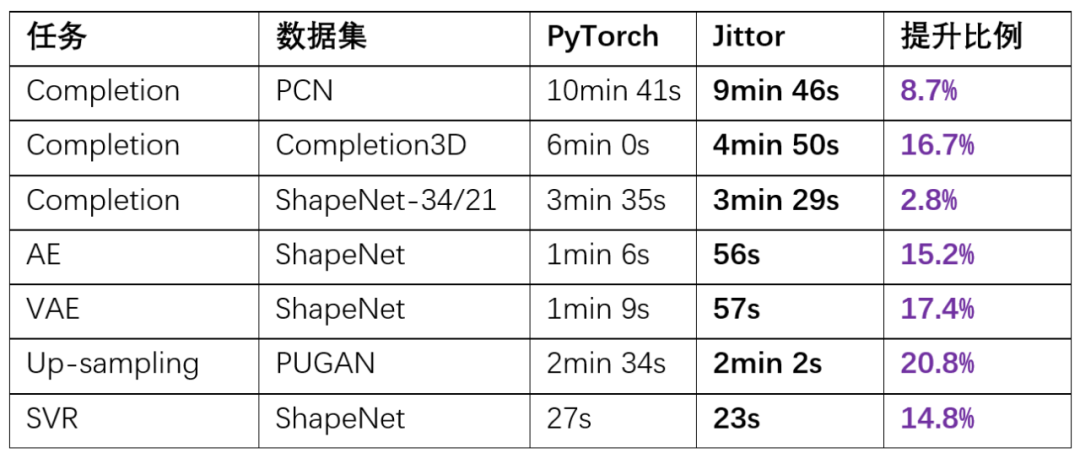
SPD方法已开源了基于计图(Jittor)实现的代码,网络模型的训练速度在多个任务上较PyTorch有提升。
表7 Jittor与PyTorch的训练时间对比
SPD的Jittor开源代码:
https://github.com/AllenXiangX/SPD_jittor
计图官网:
https://cg.cs.tsinghua.edu.cn/jittor/
IEEE T-PAMI论文的主页:
https://ieeexplore.ieee.org/document/9928787
参考文献
Peng Xiang, Xin Wen, Yu-Shen Liu, Yan-Pei Cao, Pengfei Wan, Wen Zheng, Zhizhong Han, Snowflake Point Deconvolution for Point Cloud Completion and Generation with Skip-Transformer, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, DOI: 10.1109/TPAMI.2022.3217161.
Xin Wen, Peng Xiang, Zhizhong Han, Yan-Pei Cao, Pengfei Wan, Wen Zheng, Yu-Shen Liu, PMP-Net++: Point Cloud Completion by Transformer-Enhanced Multi-step Point Moving Paths, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 852-867
Xin Wen, Peng Xiang, Zhizhong Han, Yan-Pei Cao, Pengfei Wan, Wen Zheng, Yu-Shen Liu, PMP-Net: Point Cloud Completion by Learning Multi-step Point Moving Paths, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, 7443-7452.
Xin Wen, Tianyang Li, Zhizhong Han, and Yu-Shen Liu*. Point cloud completion by skip-attention network with hierarchical folding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, 1939–1948.
Xin Wen, Zhizhong Han, Yan-Pei Cao, Pengfei Wan, Wen Zheng, Yu-Shen Liu*. Cycle4Completion: Unpaired Point Cloud Completion using Cycle Transformation with Missing Region Coding. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, 13080-13089.
Peng Xiang, Xin Wen,Yu-Shen Liu, Yan-Pei Cao, Pengfei Wan, Wen Zheng, Zhizhong Han, SnowflakeNet: Point Cloud Completion by Snowflake Point Deconvolution with Skip-Transformer, Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, 5499-5509.
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
3D点云 交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-3D点云 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D点云+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看













 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









