






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:夙曦(源:知乎,已授权)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/657692635
在CVer微信公众号后台回复:LIT,可以下载本论文pdf、代码

Iterative Prompt Learning for Unsupervised Backlit Image Enhancement
https://zhexinliang.github.io/CLIP_LIT_page/
论文:arxiv.org/abs/2303.17569
代码(已开源):
https://github.com/ZhexinLiang/CLIP-LIT
Abstract
Motivation:开放世界的CLIP先验不仅有助于区分背光和良好照明的图像,而且还可以感知不同亮度的异常区域,从而促进增强网络的优化。
Proposal:通过探索对比语言图像预训练(CLIP)在像素级图像增强中的潜力,本文提出了一种新的无监督背光图像增强方法,简称CLIP-LIT。
Introduction

Problems:当主光源在一些对象后面时,捕获的图像会出现背光。图像通常遭受高度不平衡的照度分布,这影响后续感知算法的视觉质量或准确性。手动校正背光图像是一项艰巨的任务,因为在增强曝光不足区域的同时保留良好照明区域是一项复杂的挑战。
在这项工作中提出了一个无监督的方法,背光图像增强。与以前的无监督方法不同,这些方法基于一些物理假设学习曲线或函数,或者通过依赖于特定任务数据的对抗训练来学习光线良好的图像的分布。
通过探索对比语言图像预训练(CLIP)在像素级图像增强中的潜力,本文提出了一种新的无监督背光图像增强方法,简称CLIP-LIT。
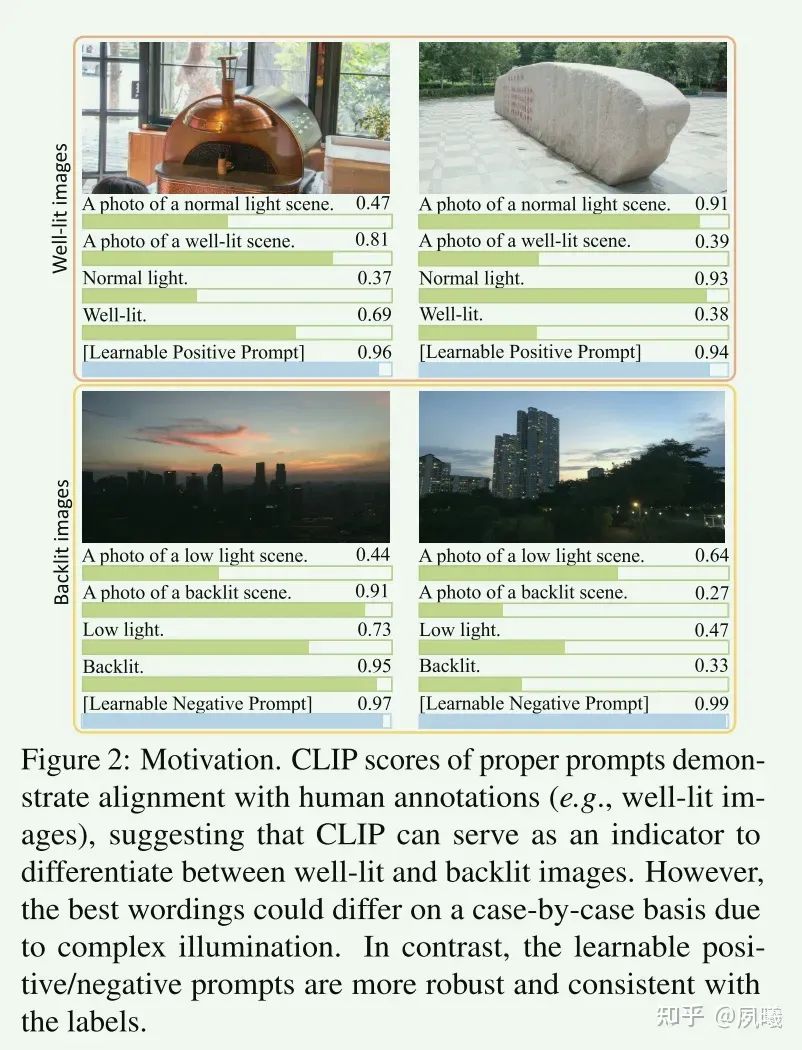
CLIP Problems:虽然CLIP可以在一定程度上作为区分良好照明和背光图像的指标,但直接使用它来训练背光图像增强网络仍然是困难的。例如,对于光线充足的图像(图2左上),用“良好照明”替换类似的概念“正常光”带来CLIP分数的巨大增加。在相反的情况下(图2右上),“正常光”成为正确的提示。这表明,由于场景中的复杂照明,最佳提示可能会因情况而异。此外,几乎不可能找到准确的“单词”提示来描述精确的亮度条件,并且CLIP嵌入经常受到图像中的高级语义信息的干扰。因此,不太可能通过固定提示或提示工程实现最佳性能。
Details:
与高级任务和图像处理任务不同,直接将CLIP应用于增强任务并不简单,因为很难找到准确的提示。(无法直接学习)为了解决这个问题,作者设计了一个提示学习框架,该框架首先通过约束CLIP潜在空间中提示(负/正样本)和相应图像(背光图像/良好照明图像)之间的文本-图像相似性来学习初始提示对。另外,基于增强的结果和初始提示对之间的文本-图像相似性,来训练增强网络。
为了进一步提高初始提示对的准确性,迭代地微调提示学习框架。通过排名学习(rank learning)减少背光图像、增强结果和良好照明图像之间的分布间隙,从而提高增强性能。
Method
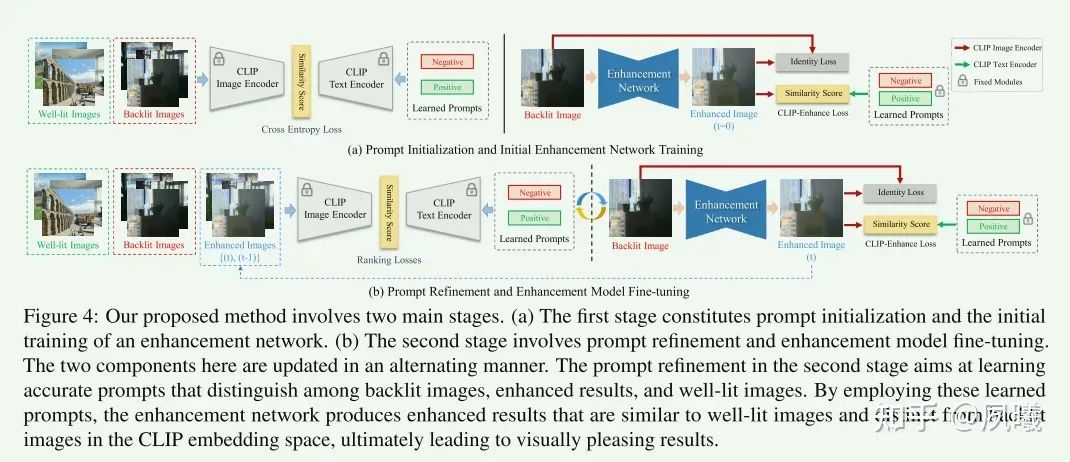
提出的方法如图4所示,包括两个阶段:
在第一阶段中,通过约束CLIP嵌入空间中的提示与相应图像之间的文本-图像相似性来学习初始提示对(负/正提示指背光/良好照明的图像)。利用初始提示对,使用冻结的CLIP模型来计算提示和增强结果之间的文本-图像相似度,以训练初始增强网络。
在第二阶段,我们通过利用背光图像、增强的结果和通过排名学习的良好照明图像来改进可学习的提示。细化的提示可以用于微调增强网络以进一步提高性能。
应该注意的是,CLIP模型在整个学习过程中保持固定,并且除了即时初始化和细化之外,本文的方法不会引入任何额外的计算负担。
初始化prompt和增强的训练(Initial Prompts and Enhancement Training)
第一阶段涉及到初始化的负样本和正样本(可学习)的提示,大致表征背光和良好的照明图像,以及初始增强网络的训练。

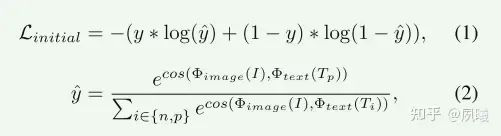

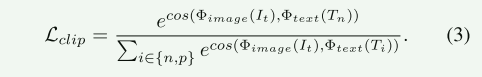
鉴别损失鼓励增强结果接近于背光图像的内容和结构,被定义为
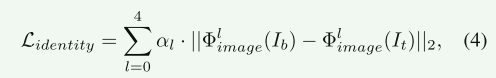
最后损失为
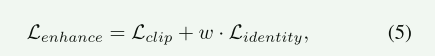
Prompt细化和增强调整
在第二阶段中,我们迭代地执行即时细化和增强网络调整,以交替的方式进行增强网络的即时细化和调谐。我们的目标是提高学习提示的准确性,以区分背光图像,增强的结果,和良好的照明图像,以及感知不同亮度的异常区域。

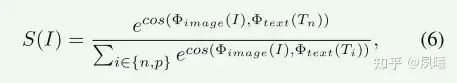
然后排名损失被表示为
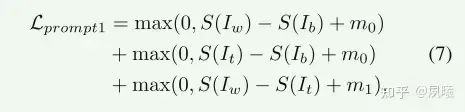

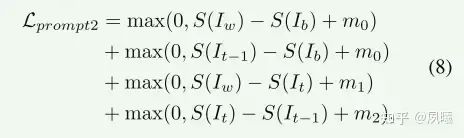
Tuning the Enhanment Network。增强网络投的调整与Initial Prompts and Enhancement Training中的一致,除了我们使用改进的提示来计算CLIPEnhance损失 Iclip 并从更新的网络生成增强的训练数据以进一步改进提示。
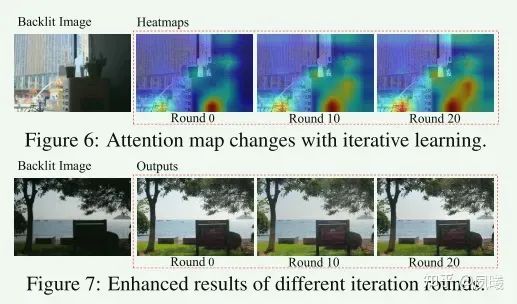
Discussion。为了显示迭代学习的有效性,遵循Chefer等人我们可视化CLIP模型中的注意力图,用于学习的负面提示与不同交替轮次的输入图像之间的交互。热图如图6所示,表示图像中的每个像素与学习到的提示之间的相关性。热图示出了在迭代期间,学习到的负面提示变得与具有令人不愉快的照明和颜色的区域越来越相关。我们还在图7中显示了不同迭代轮次的增强结果。在中间轮次,输出的一些增强区域中的颜色过饱和。在足够的迭代之后,过饱和被校正,而与先前的输出相比,暗区域更接近于良好照明状态。
Experiments
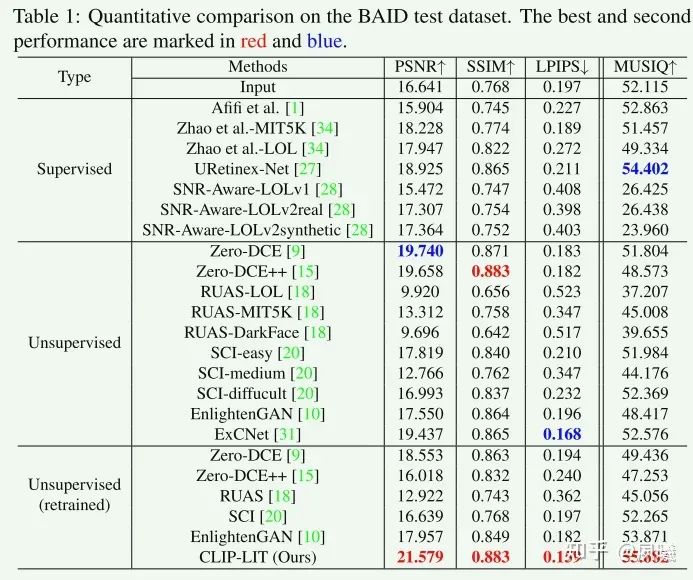
Datasets:从BAID训练数据集中随机选择380个背光图像作为输入图像,并从DIV2K数据集中选择384个光照良好的图像作为参考图像。在BAID测试数据集上测试了我们的方法,该数据集包括在不同光线场景和场景中拍摄的368张背光图像。
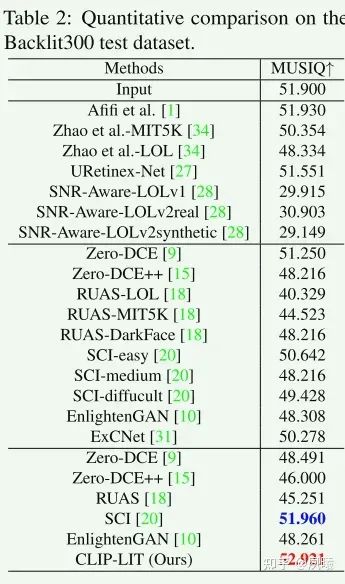
为了检查泛化能力,收集了一个新的评估数据集,名为Backlit300。它由来自互联网,Pexels和Flickr的305张背光图像组成。



在CVer微信公众号后台回复:LiT,可以下载本论文pdf、代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









