






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!

在CVer微信公众号后台回复:realfake,即可下载论文pdf和代码链接!快学起来!
作者:Jianhao Yuan(1,2), Jie Zhang(3), Shuyang Sun(2), Philip Torr(2), Bo Zhao(1)
机构:1. 北京智源人工智能研究院 2. 牛津大学 3. 苏黎世联邦理工学院
链接:https://arxiv.org/abs/2310.10402
项目网站:https://torrvision.com/realfake/
代码(已开源):
https://github.com/BAAI-DCAI/Training-Data-Synthesis
摘要:
在人工智能技术的快速发展中,合成训练数据的使用变得越来越普遍,尤其因为其在数据增强、泛化评估和隐私保护等方面的优势。然而,当前合成数据在用于训练的深度学习模型时效率仍有限,限制了它的实际应用价值。为了解决这一挑战,最新的研究 "Real-Fake: Effective Training Data Synthesis Through Distribution Matching" 提出了一个理论框架,从分布匹配的角度出发,探讨了提高合成数据效能的机制,将 Stable Diffusion 改造成更强的训练数据合成器。
这项工作不仅提出了一个理论框架,还通过大量实验验证了他们的合成数据在多样化的图像分类任务中的有效性。研究方法的核心在于:
1. 分布匹配理论框架:研究者将训练数据合成问题重新定义为一个分布匹配问题,强调合成数据与目标数据分布之间的差异和训练集的规模。
2. 文本到图像扩散模型的应用:通过对训练目标、条件生成和先验初始化的详细分析和改进,研究者们实现了合成数据与目标数据分布之间更好的对齐。
3. 实验验证:在不同的基准测试中,无论是单独使用合成数据训练、将合成数据作为真实训练数据的补充,还是评估合成数据与性能之间的规模效应,研究都证明了方法的有效性。
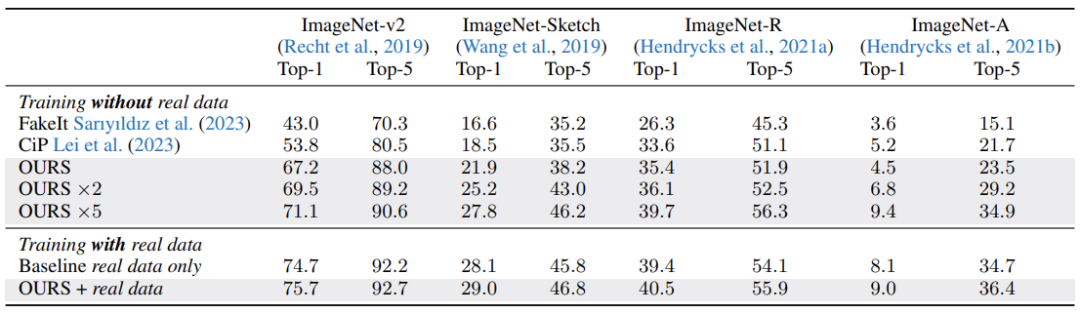
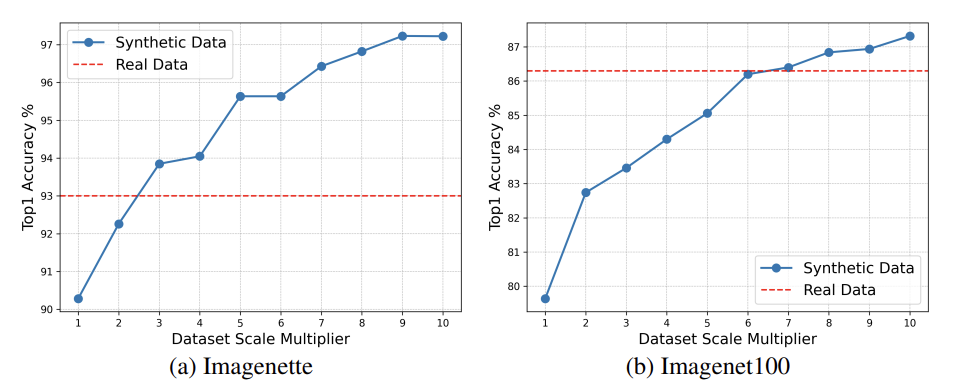
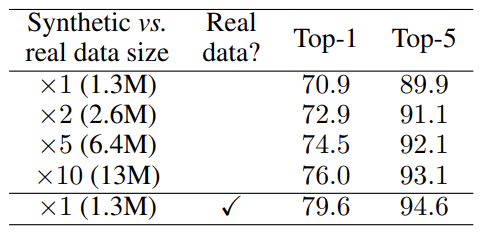
基于这一框架使用开源生成模型Stable Diffusion,在维持与真实数据同等规模下,仅使用合成数据达到了71%的ImageNet-1K分类准确率,超越基于Imagen的SOTA!并且在使用10倍数量的合成数据时,准确率直升76%,直逼真实数据79.6%!而同样的合成数据在分布外泛化和隐私保护方面展示了其优势。未来,合成数据的应用将继续扩展,为人工智能训练开辟新的可能性。
主要结果:
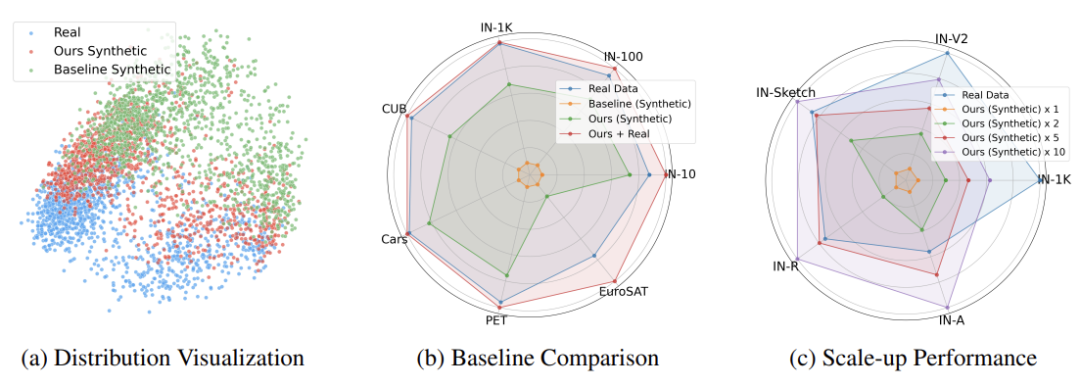
左侧:利用CLIP图像编码器提取的特征的前两个主成分,对合成数据和真实ImageNet数据分布进行了可视化。我们的合成数据与真实数据分布的一致性,优于原始Stable Diffusion的基线数据。中间:我们的合成数据比基线数据表现更好,能够有效地增强所有数据集中的真实数据。右侧:加大合成训练数据的规模可以同时提升分布内和分布外(OOD)图像分类任务的性能,甚至在OOD任务中的表现可以超越使用真实数据进行训练的效果。
方法:
训练数据合成的目标是从目标分布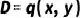 生成数据
生成数据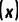 和标注
和标注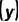 对齐的合成数据。由公式
对齐的合成数据。由公式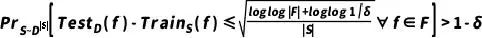 可知在有监督训练中,训练与测试误差之差受到采样训练集数量平方根倒数的约束。在固定模型空间
可知在有监督训练中,训练与测试误差之差受到采样训练集数量平方根倒数的约束。在固定模型空间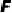 下进行训练数据合成时,有两个关键因素:(1)训练和测试数据分布差异;(2)训练集数量。这形成了训练数据合成的首要原则:有无限多目标分布训练样本时,测试误差将趋于最小化训练误差。
下进行训练数据合成时,有两个关键因素:(1)训练和测试数据分布差异;(2)训练集数量。这形成了训练数据合成的首要原则:有无限多目标分布训练样本时,测试误差将趋于最小化训练误差。
然而,直接从数据分布中采样可能是难以处理的,我们反而学习一个参数化为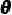 的生成模型
的生成模型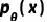 ,它能够合成遵循相同分布的数据,即
,它能够合成遵循相同分布的数据,即 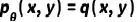 。这有效地将有信息训练数据合成问题转化为分布匹配问题。我们进一步将这样的分布匹配问题重构为两个子问题:(1)数据分布匹配
。这有效地将有信息训练数据合成问题转化为分布匹配问题。我们进一步将这样的分布匹配问题重构为两个子问题:(1)数据分布匹配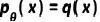 ;(2)条件类别可能性匹配
;(2)条件类别可能性匹配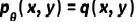 。在分类任务中,前者确保了分布内数据合成,后者确保了类别之间的健壮决策边界。总的来说,有监督学习的训练数据合成目标可以框定为以下优化问题:寻找最优合成数据样本集
。在分类任务中,前者确保了分布内数据合成,后者确保了类别之间的健壮决策边界。总的来说,有监督学习的训练数据合成目标可以框定为以下优化问题:寻找最优合成数据样本集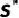 ,使得
,使得
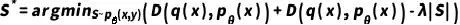
基于这个理论框架,我们对扩散模型的每个组成部分在分布匹配背景下进行了分析,并提出了潜在的改进。具体来说,我们引入了一个以分布匹配为中心的合成框架,专为训练数据合成而设计,包括三个方面:
1.特征分布对齐:通过最大均值差异(MMD)来量化并最小化合成数据与目标数据之间的分布差异,并以此微调扩散模型:
2.条件视觉引导:通过结合文本提示和图像特征来引导条件生成过程。利用CLIP模型提取的图像特征和文本嵌入,共同细化扩散模型的条件生成,确保合成图像在视觉和语义上与特定的类别一致。具体的文本-视觉提示格式为:
"photo of [classname], [Image Caption], [Intra-class Visual Guidance]"
3.潜在先验初始化:利用变分自编码器(VAE)编码器获取特定真实样本的潜在代码,作为反向扩散过程的信息性指导,以改善合成样本的质量和对目标分布的对齐。
这三个方法共同构成了一种有效的训练数据合成策略,旨在生成与目标分布一致的高质量合成数据,进而提高机器学习模型的训练效率和泛化能力。
实验结果:
1. 量化性能评估:研究使用合成数据对多个图像分类任务进行了训练,包括在ImageNet1k上使用ResNet50模型。实验结果显示,即便是仅使用合成数据进行训练,这证明了合成数据在模型训练中的有效性和可行性。研究进一步探究了合成数据作为真实训练数据的补充时对模型性能的影响。结果表明,在合成数据和真实数据混合使用的情况下,模型的泛化能力有所提高。
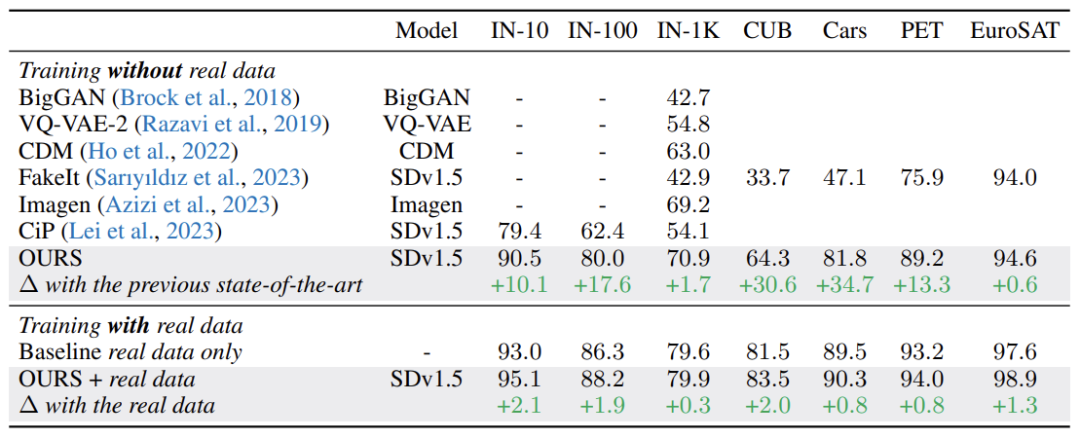
2. 分布外泛化能力:实验也评估了合成数据在分布外泛化(OOD)上的性能。模型在未见过的数据上也展现了良好的泛化能力,甚至超过了用真实数据训练的模型,这对于实际应用中面临的未知数据分布具有重要意义。
3. 扩大数据规模的影响:实验表明,合成数据集的规模对于图像分类器的性能至关重要。仅通过增加合成数据量,分类器的性能就能超越仅使用真实数据训练的模型。实验表明在各个规模的数据集中,随着合成数据量的增加,分类准确率也随之提高,直至超过真实数据。
4. 隐私保护效益:通过使用合成数据代替真实数据,研究还展示了在保护隐私方面的潜在优势,这对于敏感数据的处理尤为重要。
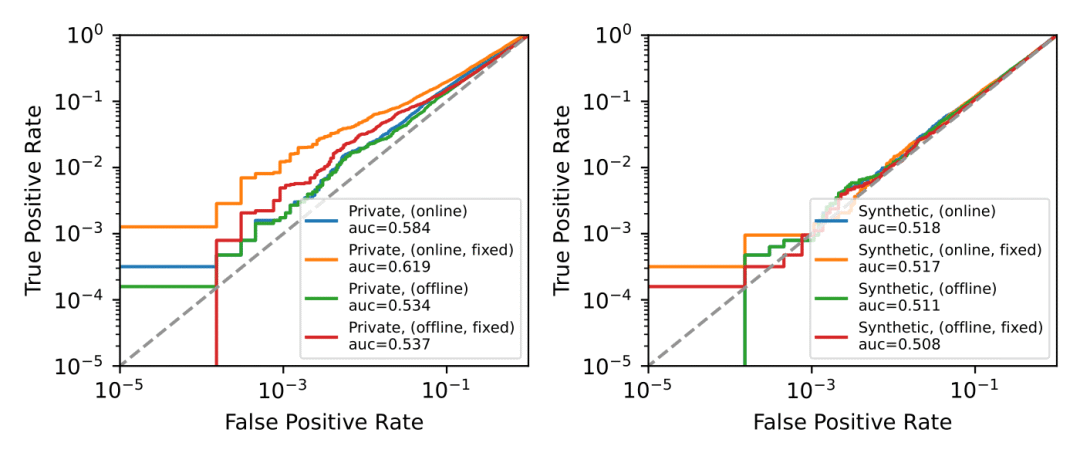
当使用LiRA对合成数据进行会员推断攻击(MIA)时,LiRA在0.1%的低假阳性率(FPR)下达到了0.001%的真阳性率(TPR),而对私有数据的结果是0.01%,这表明使用合成数据进行训练在保护隐私方有效。

合成数据与SSCD检索到的真实数据可视化。合成数据没有显示出明显的复制或记忆现象。
在CVer微信公众号后台回复:realfake,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









