






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!

转载自:机器之心 | 编辑:蛋酱、杜伟
视觉模型,同样遵循「参数越多性能越强」的规律?刚刚,一项来自苹果公司的研究验证了这个猜想。
过去几年,大规模预训练模型在 NLP 领域取得了成功,这类模型可以通过几个示例解决复杂的推理任务,也可以按照指令进行推理。
众所周知的是,预训练模型能取得成功的一个理论基础是,随着容量(即参数量)或预训练数据量的增加,模型能够不断提升性能。
这很自然地引发了研究者们的联想:使用自回归目标对 Transformers 进行缩放的成功是否仅限于文本?
在最新的一篇论文《Scalable Pre-training of Large Autoregressive Image Models》中,苹果的研究者提出了自回归图像模型(AIM),探讨了用自回归目标训练 ViT 模型是否能在学习表征方面获得与 LLMs 相同的扩展能力。

论文链接:https://arxiv.org/pdf/2401.08541
项目地址:https://github.com/apple/ml-aim
先说结论:研究者发现,模型容量可以轻松扩展到数十亿个参数,并且 AIM 能够有效利用大量未经整理的图像数据。
他们利用包括 ViT、大规模网络数据集和 LLM 预训练最新进展在内的工具集,重新审视了 iGPT 等自回归表征学习方面的前期工作,此外还引入了两处架构修改,以适应视觉特征的自回归预训练。
首先,研究者并没有像 LLM 通常那样将自注意力限制为完全因果关系,而是采用了 T5 中的前缀注意力。这一选择使得能够在下游任务中转向完全双向的注意力。其次,研究者使用了参数化程度较高的 token-level 预测头,其灵感来自对比学习中使用的预测头。他们观察到,这种修改大大提高了后续特征的质量,而在训练过程中的开销却很小。总体来说,AIM 的训练与最近的 LLM 训练类似,而且不依赖于监督式或自监督式方法所需的任何 stability-inducing 技术。
随后,研究者对一系列模型展开了研究,这些模型的参数从 600M 到 7B 不等,都是使用 20 亿带许可的未编辑图像进行预训练的。如图 1 所示,以 15 个图像识别基准的平均准确率来衡量,AIM 模型在与模型规模的关系上表现出很强的扩展性,容量越大的模型下游性能越好。更重要的是,验证集上的目标函数值与后续冻结特征的质量之间存在相关性。这一观察结果证明,自回归目标足以满足视觉特征的训练要求。此外,随着对更多图像进行训练,研究者还观察到了下游性能的持续改善,且没有饱和的迹象。总体而言,这些观察结果与之前关于扩展大型语言模型的研究结果是一致的。
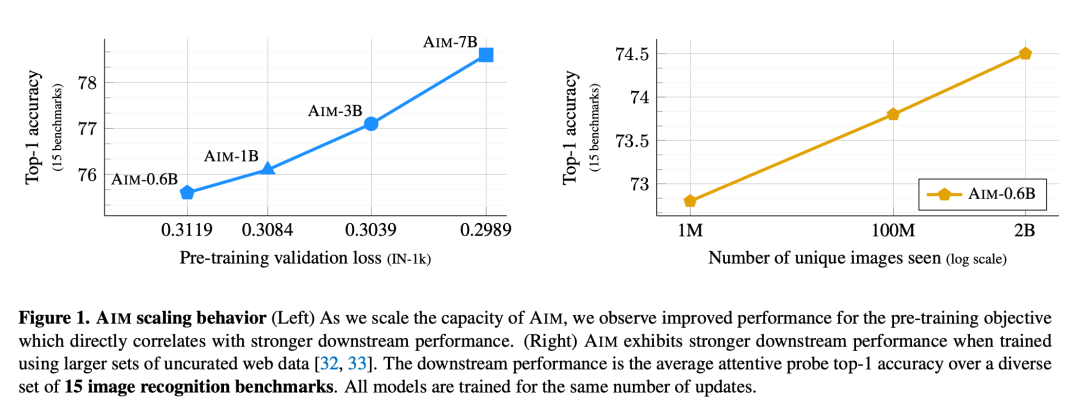
但同时引起注意的是,本文实验所使用的模型规模有限,是否能在更大参数量级的模型上验证此规律,有待进一步探索。
方法概览
本文的训练目标遵循应用于图像 patch 序列的标准自回归模型。更准确地说,图像 x 被分割为 K 个不重叠 patch x_k 组成的网格 k ∈ [1, K],这些 patch 共同形成 token 序列。
研究者假设所有图像的序列顺序是固定的,因此除非另有说明,他们默认使用光栅(行优先)排序。给定上述顺序,一张图像的概率可以被分解为 patch 条件概率的乘积。
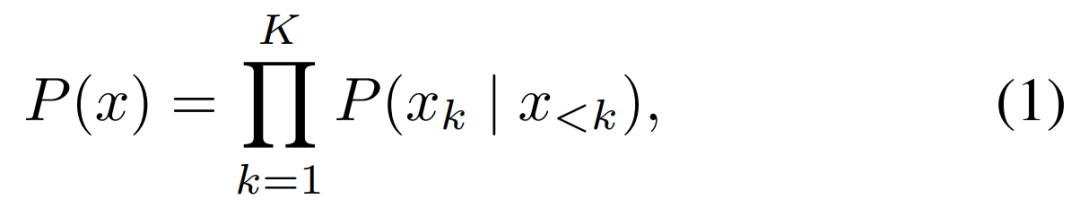
预测损失。研究者的训练目标自然会产生某些损失变体,每个变体对应分布 P (x_k | x_<k) 的选择。他们还考虑通过使用离线 tokenizer,将带有 patch 的交叉熵损失转换为离散 token。消融实验表明,这些设计是有效的,尽管不会产生像像素级损失那样显著的特征。
架构
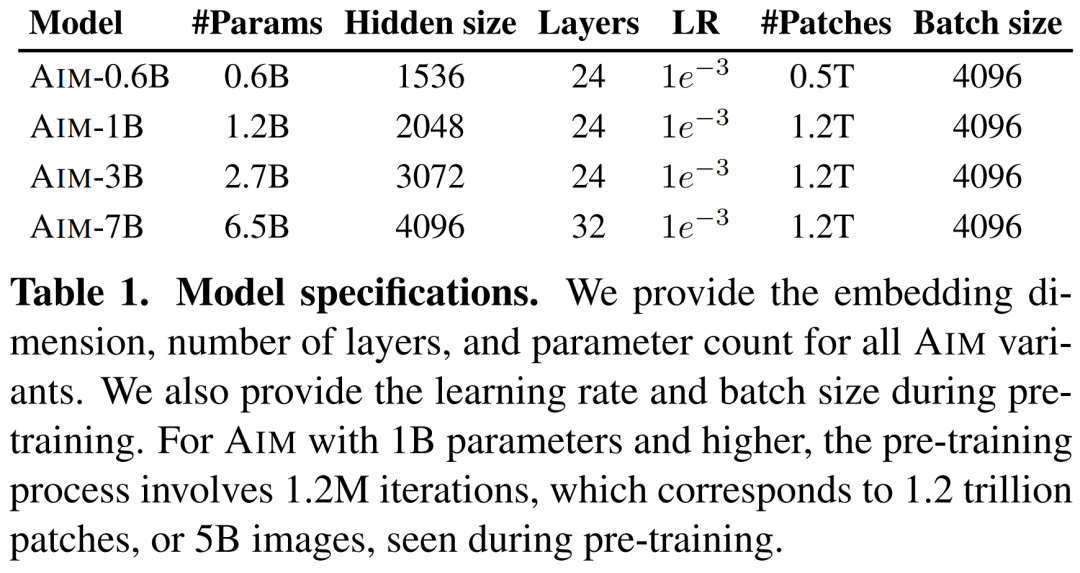
在骨干选择上,研究者采用了 Vision Transformer(ViT)架构。为了扩展模型容量,他们遵循语言建模中的常见做法,优先考虑扩展宽度而不是深度。下表 1 展示了 AIM 的设计参数,包括它的宽度和深度以及数据量、每个模型容量的优化方案。
AIM 整体模型架构如下图 2 所示。

在预训练期间,研究者将因果掩码用于自注意力层,以对给定先前 patch 的 patch 进行概率建模。更准确地说,给定一个自注意力层,patch i 的嵌入被计算如下:
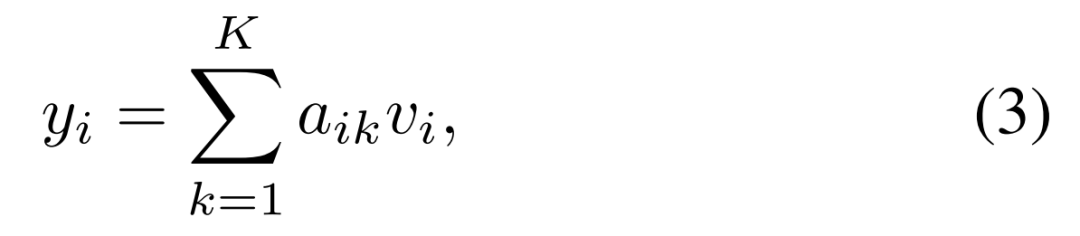
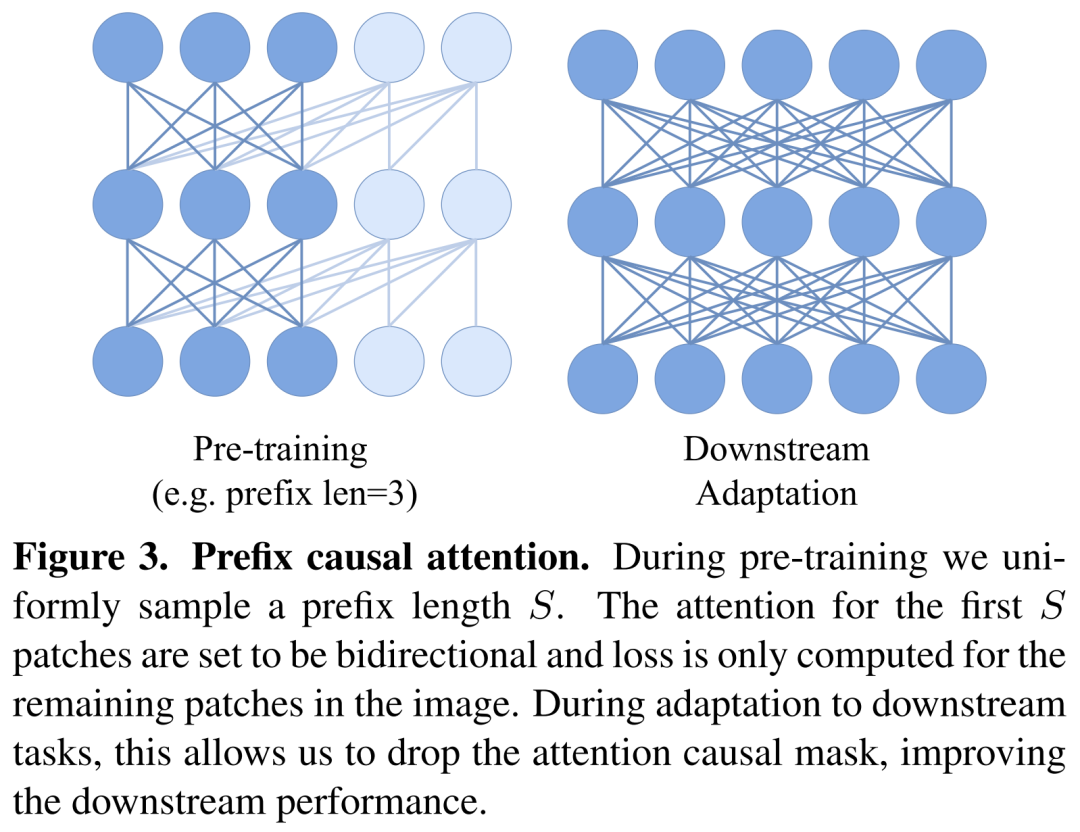
前缀 Transformer。预训练中的自回归目标需要在自注意力操作中使用因果掩码,不过这与 ViT 模型在下游任务中的标准使用方法不同,后者要部署双向自注意力。下图 3 说明了因果和前缀注意力之间的差别。
MLP 预测头。使用这些头的目的是防止主干(trunk)特征在预训练目标中变得过于专门化,从而增强对下游任务的迁移能力。研究者选择了一种简单设计,在最终 transformer 层顶部使用 N 个多层感知机(MLP)块,从而独立地对每个 patch 进行处理。
直接实现。研究者观察到,AIM 使用相同的优化超参数集来扩展模型大小,无需进一步调整。
下游适应。研究者专注的场景中,所有模型权重对下游任务都是固定的。在这种情况下,他们只训练一个分类头,这可以减轻小型下游数据集过拟合的风险,并显著降低适应成本。
实验结果
首先,研究者从参数和训练数据的角度衡量了扩展本文方法所产生的影响。特别是,他们研究了预训练目标和下游性能在不同基准之间是否存在相关性;还研究了缩放对损失函数值的影响。所有这些实验都报告了在 IN-1k 验证集上的损失函数值。
从图 4 可以看出,在整个训练过程中,两个探针都得到了相应的改善,这表明优化目标会直接带来更好的下游性能。
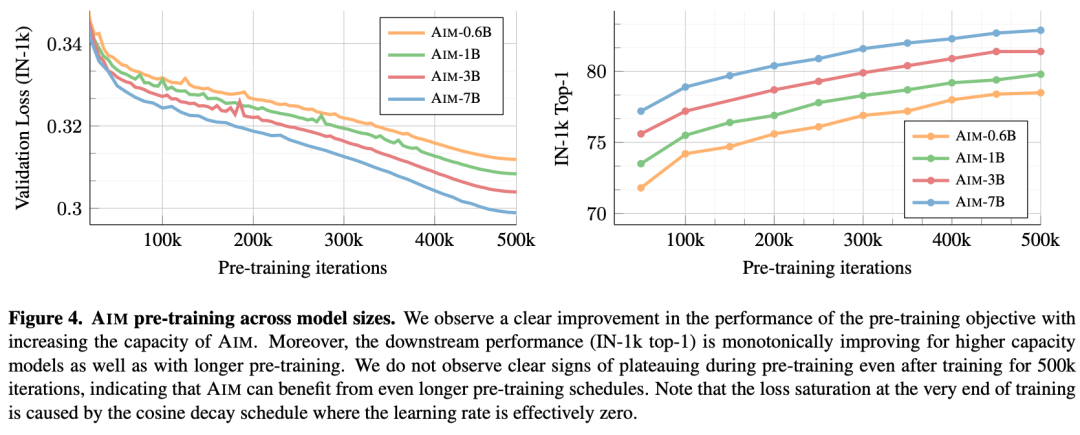
他们同时发现,随着模型容量的增加,损失值和下游任务的准确性都有所提高。这一观察结果与在 LLMs 中观察到的趋势一致,可直接归因于目标函数的优化,这反过来又会导致学习到更强的表征。
图 5 中展示了在由 100 万张图像组成的小型数据集(即 IN-1k)或由 20 亿 张图像组成的大型数据集(即 DFN-2B+)上进行预训练时验证损失的变化情况。
在 IN-1k 上进行的训练很快就会带来较低的验证损失,然而这种损失在训练结束时会恶化,这表明了对训练数据的过拟合。当在未经整理的 DFN-2B 数据集上进行训练时,模型开始时的验证损失较高,但损失持续减少,没有过拟合的迹象。
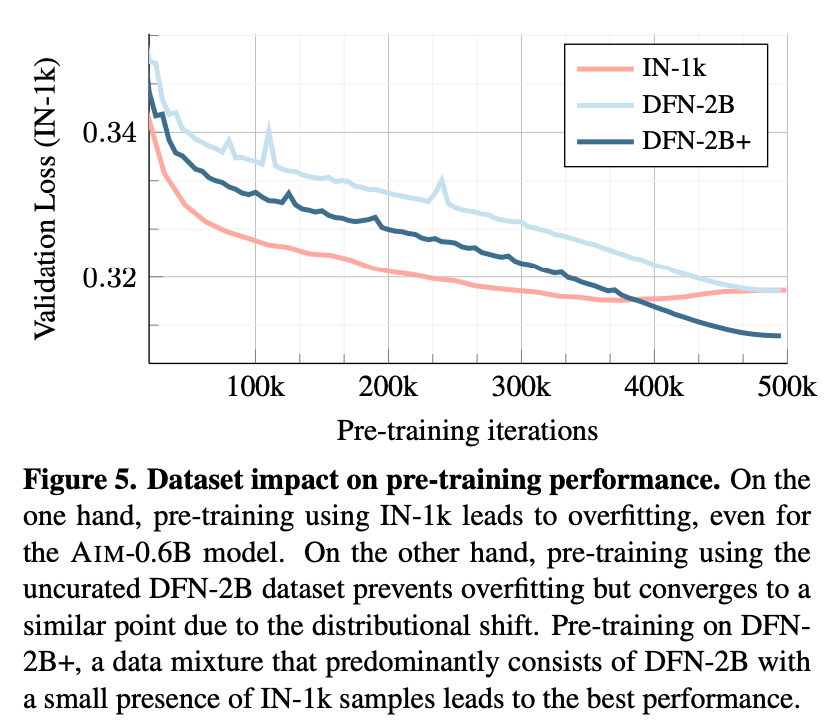
当在同一数据集上添加少量 IN-1k 数据,可以观察到性能进一步提高,最终超过了在 IN-1k 数据集上的预训练。表 2 证实了这一点。

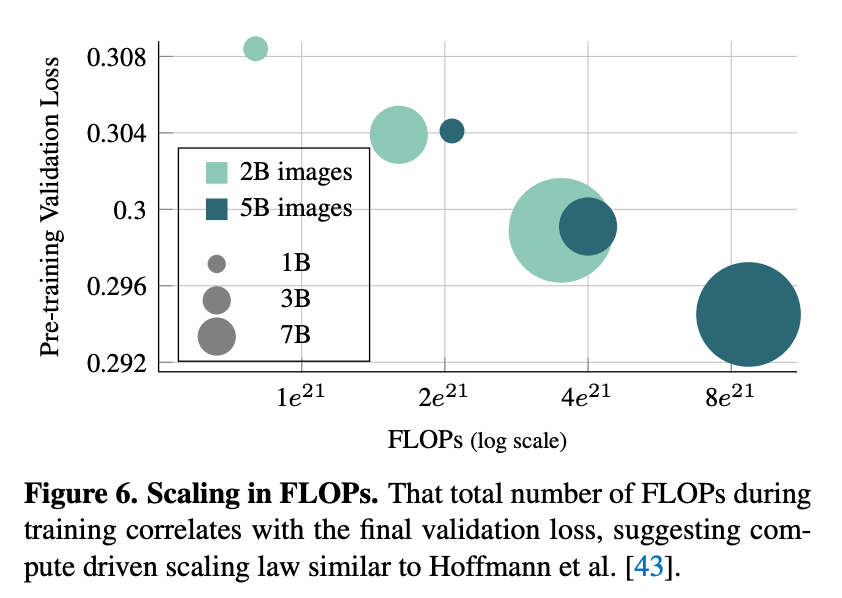
由于在使用 DFN-2B+ 数据集进行训练时没有观察到过拟合的迹象,因此研究者继续研究延长预训练计划长度的影响。图 6 展示了将预训练时间表的长度从 50 万次迭代增加到 120 万次迭代的影响。可以观察到,使用更长计划进行预训练的模型的验证损失明显降低。这表明可以通过增加模型容量或使用更长的时间表进行预训练来提高 AIM 的性能。
同时,研究者讨论了模型和训练目标的一些变化所产生的影响。这些消融实验使用 AIM-0.6B 模型进行,该模型已在 IN-1k 数据集上进行了预训练和评估。表 3 展示了消融实验的结果。

研究者还使用自回归目标训练的架构与 BERT 在语言领域以及 BEiT 和 MAE 在视觉领域流行的掩蔽目标进行了比较。他们在与 AIM 相同的设置中应用了掩蔽目标,从而将预训练目标对性能的影响与 AIM 和其他方法之间的其他设计选择的不同之处隔离开来。表 5 显示,AIM 在使用自回归目标时比使用掩蔽目标时表现更好。

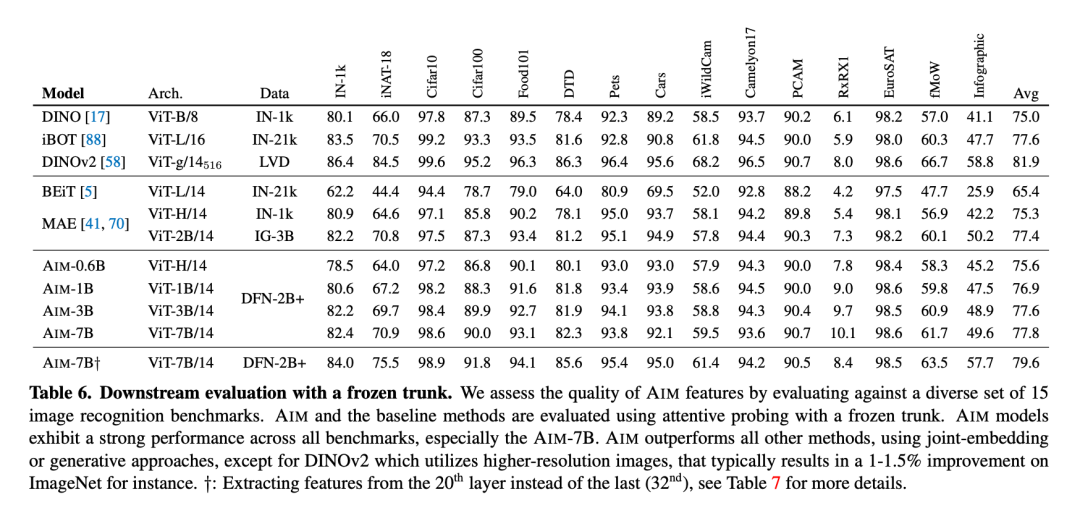
表 6 展示了 AIM 与其他 SOTA 方法在 15 种不同基准中的 Attentive Probing 性能。
除此之外,研究者还探索了 LoRA 这种高效的微调方法,表 8 展示了对 AIM 进行 LoRA 微调的结果。LoRA 与 AIM 兼容,与冻结主干评估相比,性能有了很大提升。例如,AIM-7B 提高了 3.9%(与上一层性能相比),而微调的主干参数只提升 0.1%。

更多技术细节和实验结果请参阅原论文。
在CVer微信公众号后台回复:论文,即可下载论文pdf和代码链接!快学起来!
计算机视觉技术交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 2321
2321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









