






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!

作者:虎子哥(已授权转载)
https://zhuanlan.zhihu.com/p/681708426
标题:FROSTER: Frozen CLIP is A Strong Teacher for Open-Vocabulary Action Recognition
论文:https://arxiv.org/pdf/2402.03241
代码:https://github.com/Visual-AI/FROSTER
这是我博士期间的第一个工作,欢迎广大同行批评指正!
背景介绍
本文的研究课题是开集动作识别(open-vocabulary action recognition),具体来说就是测试集中的视频动作类别与训练集动作类别基本没有重叠或重叠程度很小,因此这需要模型具备较高的泛化性能。目前视频领域主流的做法是基于图像-文本对预训练的模型(主要是CLIP)先在视频数据集上进行fine-tuning,然后再进行测试集的验证。通过实验探索,我们发现:尽管fine-tuning可以让CLIP具备不错的视频特征提取的能力,但这也会让它失去大规模预训练所得到的泛化性能。具体的表现就是,那些在闭集(closed-set)场景下优秀的视频分类器们,一到了开集场景下实验性能便大大缩水,甚至不如原先的预训练CLIP模型了。因此如何让视频模型在fine-tuning的同时还能保持住预训练的知识,成为了本文的研究重点。
问题探究
我们首先尝试了一组在闭集场景下表现优异的CLIP-based的视频模型:Action CLIP[1] , AIM ST-Adapter [2]以及 ST-Adapter[3]。具体的实验设置为:首先将模型在Kinetics-400上进行fine-tuning,然后在UCF-101,HMDB-51以及Kinetics-600数据集上分别进行了测试。需要特别注意的是,针对Kinetics-600数据集,我们将验证集中与Kinetics-400相同的类别剔除,以保证开集验证的可靠性。实验结果如下图1所示。
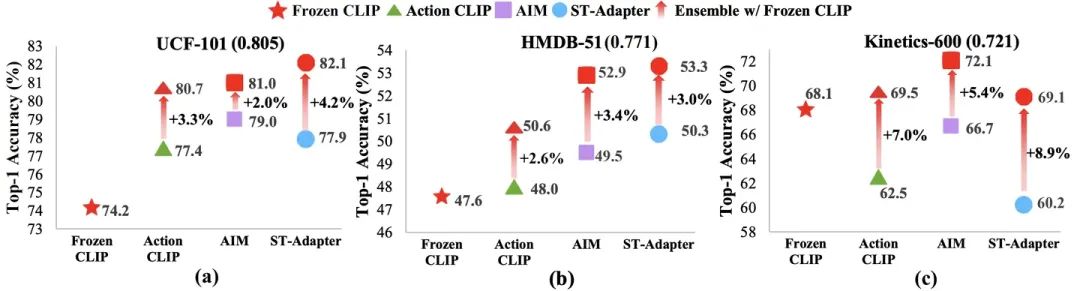
不难发现,在UCF-101与HMDB-51数据集上,fine-tune模型的性能比Frozen CLIP更强,但是在Kinetics-600数据集上,fine-tune模型的实验性能却比frozen CLIP要更弱。这种不一致的泛化性表现引起了我们的好奇心,因此我们进一步地去分析训练集(Kinetics-400)与各个测试集(UCF-101,HMDB-51和Kinetics-600)之间的类别相似性关系。具体来说,我们用CLIP的text encoder提取不同数据集的各个类别的文本特征,然后利用余弦相似度进行类别相似性的度量。图1中,我们用小括号中的数字来表示数据集类别的相似度,如:UCF-101(0.805)。我们注意到,在测试数据与训练数据具备更高相似度的数据集上(UCF-101和HMDB-51),fine-tune模型相较Frozen CLIP的性能表现更加优异。反之,在Kinetics-600上,fine-tune模型的性能则更弱。针对这个现象,一个可能的解释是:在与训练数据更相似的测试类别上,模型通过fine-tuning学习到的知识可有效地被用作识别,因此性能更好。而在与训练数据不那么相似的测试类别上,模型需要更多地依赖预训练的泛化性知识,但这些知识已经在fine-tune的过程中被逐渐抹去了(典型的灾难遗忘问题(catastrophic forgetting issue)),因此fine-tune模型性能更差。受这些实验现象的启发,我们认为一个基于CLIP的开集动作识别模型应该具备以下特点:
由于CLIP预训练是没有使用视频数据集的,因此模型需要学习视频域的相关知识(video-specific),用于弥补CLIP在时域建模方面的不足。
模型需要能保持住预训练CLIP的能力,这对于泛化性能力的保持很重要。
为了验证以上猜想,我们直接将fine-tune 模型和frozen clip的结果进行相加后平均输出。如图1所示,可以发现ensemble的所有模型在三个数据集上的性能都获得了较大程度的提升,这有效地验证了我们的假设。但是直接采用ensemble的方式,计算量和参数量都将会成倍地增加。
方案设计
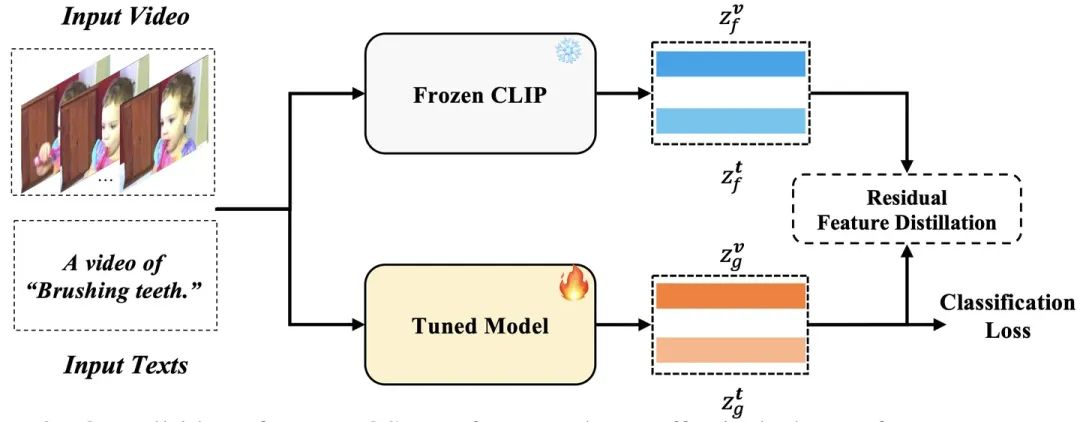
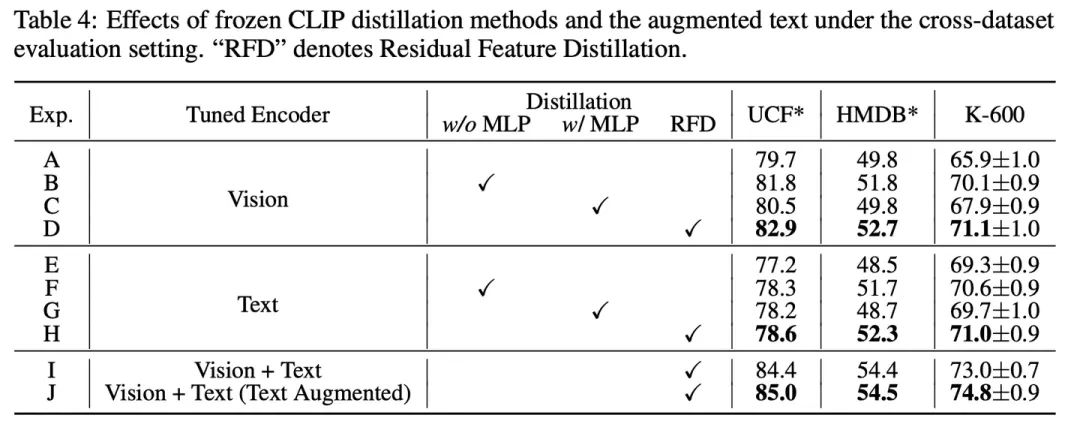
为了解决以上问题,如图2所示,我们提出了一种新的结构FROSTER用来同时实现以上两个目标:针对第一点(时域建模),我们直接采用cross-entropy loss对fine-tune模型进行监督。针对第二点(泛化性特征保持),我们将frozen clip作为teacher模型对fine-tune模型的特征进行蒸馏,借此希望预训练的能力能够得到很好地保持。蒸馏过程类似于一个正则化项,确保fine-tune特征不会偏离frozen clip的特征太远。因为有两个不同的目标,我们需要在它们之间平衡特征学习。
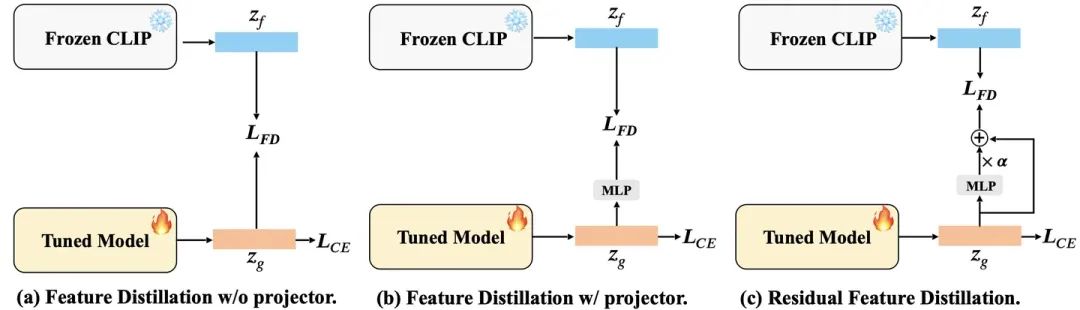
以冻结的CLIP模型作为教师模型,实现基于特征的蒸馏有两种常见的方法,如图所示(a)和(b)。如图(a)所示,由于fine-tune模型和frozen CLIP输出特征的维度保持不变,我们可以直接在它们之间进行特征蒸馏,无需进行特征投影。然而,这种监督要求fine-tune特征保持与预训练特征相同,这限制了fine-tune 特征学习视频知识的能力。另一种可能的方法(如图(b)所示)是应用一个投影器,将fine-tune特征从学生空间映射到教师空间。这可以放宽对fine-tune特征的约束,以便更好地拟合视频数据。然而,在这种条件下,蒸馏loss对fine-tune特征的约束可能过于宽松,从而限制了其泛化能力。因此,我们需要在上述两种方法之间找到一个折中方案,考虑到两个学习目标。
受到ResNet残差设计的启发,我们提出了一个改进的残差网络,用于在进行蒸馏时平衡两个学习目标。这种设计背后的直觉是允许fine-tune特征有效地接受frozen clip的监督,同时也保持对视频特征的有效学习。如图(c)所示,我们在特征上应用一个改进的残差网络,通过两层MLP投影器和恒等映射来转换其表示。

实验结果
我们总的在两个实验设置下进行实验:base-to-novel和cross-dataset。
Base-to-novel是将每个数据集的类别分成两个不重叠的部分,完成在训练集类别上进行16-shot的训练后,在测试集上进行测试。实验数据集总共包含K-400,HMDB-51,UCF-101和SSv2。
Cross-dataset是在K-400 数据集上进行训练,然后在HMDB-51,UCF-101和K-600上进行测试。
下表为模型在base-to-novel和cross-dataset两个场景下的实验精度,FROSTER均达到了最佳。
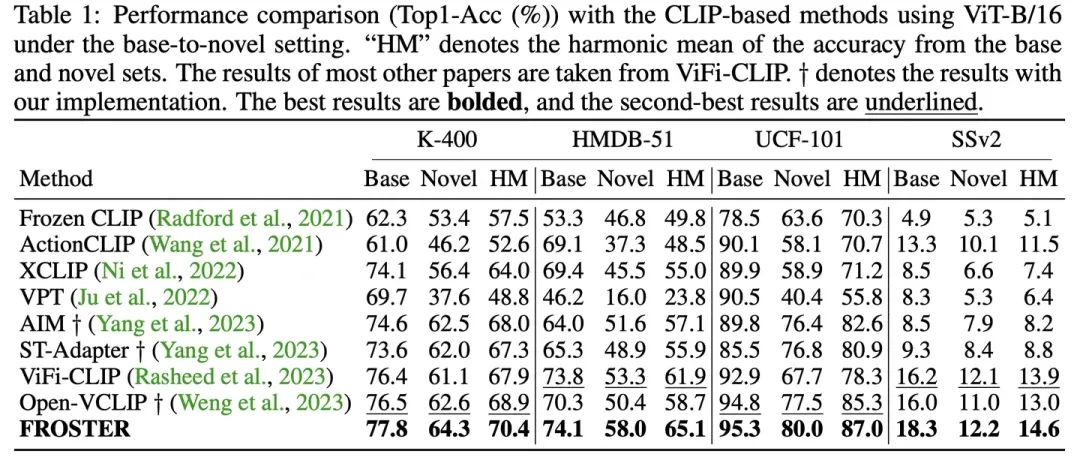
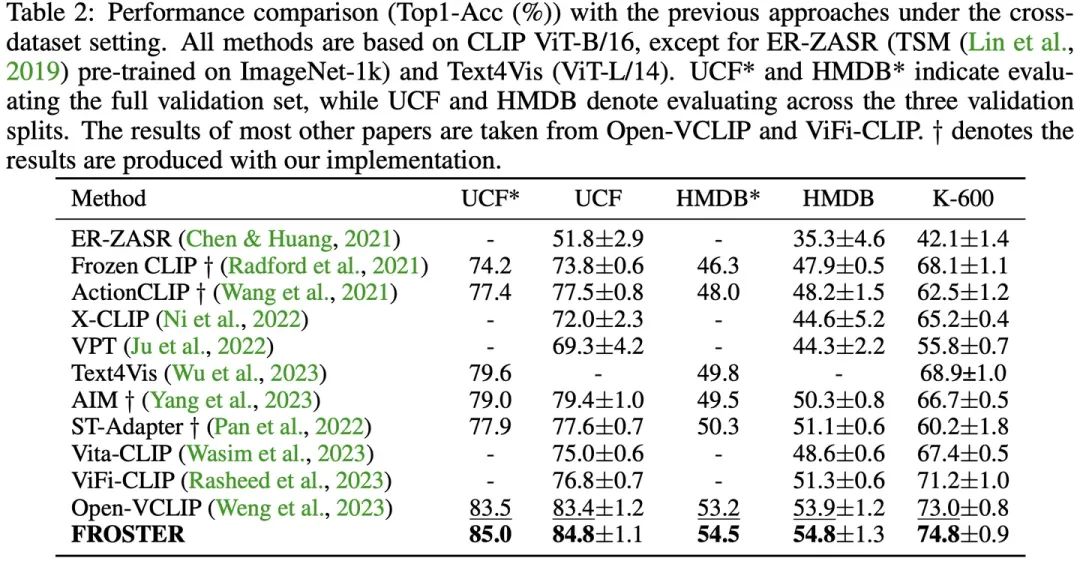
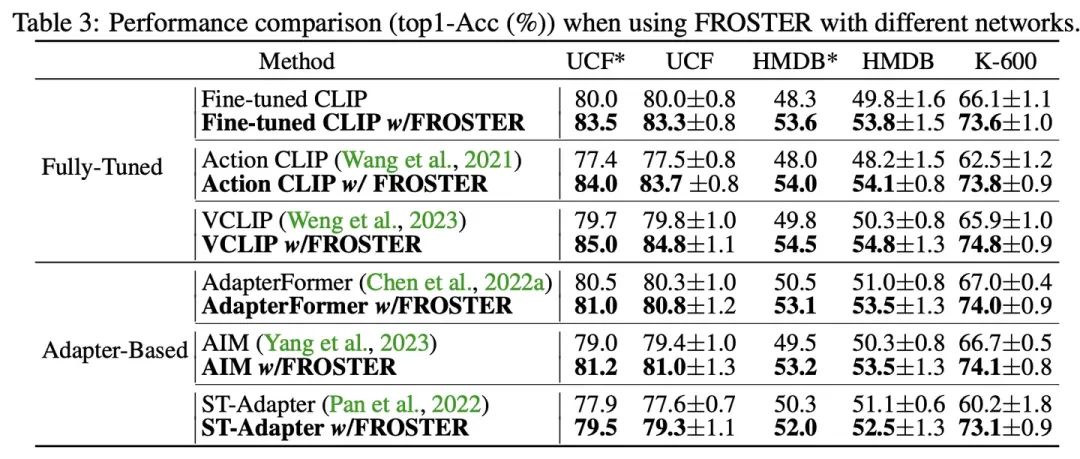
同时,FROSTER还可以与不同的模型结构结合到一起,都能有效地提升实验结果。

总结
本文针对开集动作识别任务提出了一种的新的模型结构,用来同时实现视频特征和泛化性的学习。我们在两种场景下都达到了最优的识别性能。
另:开集动作识别是一个较新的领域,目前还有很多可以探究的问题,希望社区的同行们多多关注!大家新年快乐~
参考文献
[1] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. Arxiv e-prints, 2021.
[2] Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, and Mu Li. Aim: Adapting image models for efficient video action recognition. Arxiv e-prints, 2023.
[3] Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li. St-adapter: Parameter-efficient image-to-video transfer learning. In NeurIPS, 2022.
在CVer微信公众号后台回复:论文,即可下载论文和代码链接!快学起来!
视频理解和多模态学习交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-视频理解和多模态微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如视频理解和多模态+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









