







- Introduce
传统pooling层:
把feature map分割成网状cell并从每个网格中简化信息。它会丢弃75%(2x2)的激活特征,在位置信息不重要的前提下会增加空间的鲁棒性,不管目标出现在什么位置都能获得相似的特征。但是对于某些任务位置信息是相当重要的,比如在猫分类器中,就无法知道胡子相对于鼻子的位置(在同一cell被池化)。
池化kernel 是局部的,固定的,空间不变性要在深层的卷积池化层才能实现,对于扭曲较大的输入,中间的feature map不具有空间不变性,因此饱受扭曲输入的折磨。只包含pool层的网络对空间变换的承受能力是有限的,这也是STN提出的原因。
Spatial Transform Layer优点:
可差分模块,可以嵌入到CNN网络任何一个地方包括卷积层之间,全连接层之间。可以统一的进行反向传播。
能表现出pool相似的功能,可以进行仿射变换将扭曲输入纠正过来;而且能去除多余背景提取目标部分,有种注意力机制的特点。
- 网络结构

图中STN由3部分组成:Localization net,Grid generator, sampler。其中U,V分别指输入和输出特征图。(Spatial Transform对feature map每个通道的处理是相同的)。将
U
∈
R
H
W
C
U{\in}R^{HWC}
U∈RHWC, 输入Localization网络,求得参数向量
θ
\theta
θ,Grid generator根据
θ
\theta
θ求出对应输入特征图的采样坐标
τ
θ
\tau_{\theta}
τθ,最后对输入特征图采样得到
V
∈
R
h
w
c
V{\in}R^{hwc}
V∈Rhwc。
localization net
参数预测网络预测出仿射变换矩阵,见下。
- 坐标映射网络
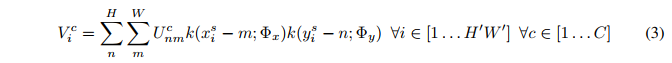
其中
U
n
m
C
U^C_{nm}
UnmC 表示输入特征图在坐标m,n处的像素值,
k
(
x
i
s
−
m
)
k(x^s_i - m)
k(xis−m) 表示采样kernel,常用的有双线性采样核。可以看出输出特征图和输入大小是不同的,一般来说需要预先定义输出V的形状。在公式中每计算输出的一个像素值就要遍历整张输入特征图,所以我们能做逆变换(放射变换为例):

这里的 θ \theta θ矩阵由参数预测网络得到。STN网络可以学习放射变换在内的各种变换。
- 采样网络

由于上一步求得的坐标 ( x i t , y i t ) (x^t_i, y^t_i) (xit,yit) 是浮点数而实际坐标是整数,文中使用双线性插值来解决。公式见论文(4)(5),同时双线性插值是可导的,公式也给出(6)(7)。
参考:
[1] https://kevinzakka.github.io/2017/01/18/stn-part2/














 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









