






本篇文章都是基于之前的两篇文章所配置的环境开始,如果是还未跑通YOLOv8的纯小白可以参考我之前的文章先配置跑通YOLOv8。如果已经成功跑通YOLOv8,那就直接参考这篇文章即可。之后博主也会更新更多的相关改进教程和目标分割的一些源码复现,希望大家多多关注!!!
目录
1.AFPN
1.1 AFPN简介
AFPN(Adaptive Feature Pyramid Network)是一种改进的特征金字塔网络,旨在优化多尺度特征融合。与传统FPN(自顶向下单向融合)和PANet(双向融合)不同,AFPN通过自适应机制(如动态权重学习、跨尺度交互)实现更灵活的特征融合。其核心思想是让不同层级的特征根据内容自动调整融合权重,减少信息丢失,增强多尺度目标(尤其是小目标)的检测能力。
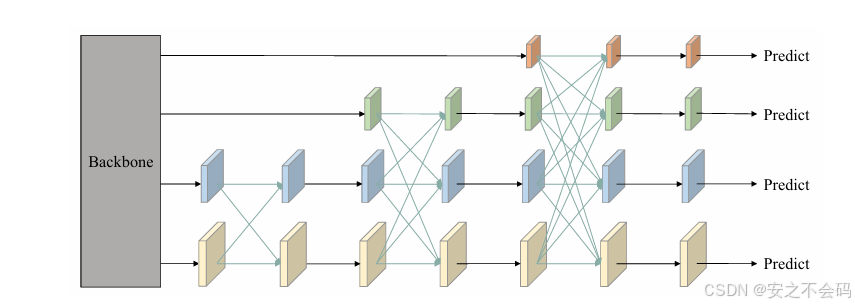
具体相关内容可以参考原文 AFPN原文链接
1.2 AFPN在YOLOv8中的改进引用
替换原有特征金字塔
YOLOv8默认采用PANet进行特征融合,而AFPN通过以下方式提升性能
动态权重分配:在特征融合时,通过轻量级模块(如SE注意力或可学习参数)为不同层级分配权重,使模型更关注重要特征。
跨尺度高阶交互:引入跨层连接或空洞卷积,增强浅层细节与深层语义的交互,改善小目标检测。
结构适配与轻量化设计
减少计算开销:AFPN采用分组卷积或通道缩减,保持轻量化,避免拖累YOLOv8的实时性
层级优化:在YOLOv8的Neck部分替换为AFPN,保留原有检测头结构,仅调整特征融合路径
2.融合改进检测头AFPN4
2.1 AFPN4相应代码
import math
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules import DFL
from ultralytics.nn.modules.conv import Conv
from ultralytics.utils.tal import dist2bbox, make_anchors
__all__ = ['Detect_AFPN4'] # 定义模块的公开接口
# 定义一个基础的卷积块,包含卷积、批归一化和ReLU激活函数
def BasicConv(filter_in, filter_out, kernel_size, stride=1, pad=None):
if not pad:
pad = (kernel_size - 1) // 2 if kernel_size else 0 # 如果没有指定padding,则自动计算
else:
pad = pad
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)), # 批归一化
("relu", nn.ReLU(inplace=True)), # ReLU激活函数
]))
# 定义一个基础的残差块
class BasicBlock(nn.Module):
expansion = 1 # 扩展系数,用于控制输出通道数
def __init__(self, filter_in, filter_out):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(filter_in, filter_out, 3, padding=1) # 第一个卷积层
self.bn1 = nn.BatchNorm2d(filter_out, momentum=0.1) # 批归一化
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
self.conv2 = nn.Conv2d(filter_out, filter_out, 3, padding=1) # 第二个卷积层
self.bn2 = nn.BatchNorm2d(filter_out, momentum=0.1) # 批归一化
def forward(self, x):
residual = x # 保存输入作为残差
out = self.conv1(x) # 第一个卷积
out = self.bn1(out) # 批归一化
out = self.relu(out) # ReLU激活
out = self.conv2(out) # 第二个卷积
out = self.bn2(out) # 批归一化
out += residual # 残差连接
out = self.relu(out) # ReLU激活
return out
# 定义一个上采样模块
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
BasicConv(in_channels, out_channels, 1), # 1x1卷积
nn.Upsample(scale_factor=scale_factor, mode='bilinear') # 双线性上采样
)
def forward(self, x):
x = self.upsample(x)
return x
# 定义一个2倍下采样模块
class Downsample_x2(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample_x2, self).__init__()
self.downsample = nn.Sequential(
BasicConv(in_channels, out_channels, 2, 2, 0) # 2x2卷积,步长为2
)
def forward(self, x):
x = self.downsample(x)
return x
# 定义一个4倍下采样模块
class Downsample_x4(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample_x4, self).__init__()
self.downsample = nn.Sequential(
BasicConv(in_channels, out_channels, 4, 4, 0) # 4x4卷积,步长为4
)
def forward(self, x):
x = self.downsample(x)
return x
# 定义一个8倍下采样模块
class Downsample_x8(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample_x8, self).__init__()
self.downsample = nn.Sequential(
BasicConv(in_channels, out_channels, 8, 8, 0) # 8x8卷积,步长为8
)
def forward(self, x):
x = self.downsample(x)
return x
# 定义一个ASFF(Adaptive Spatial Feature Fusion)模块,用于融合两个特征图
class ASFF_2(nn.Module):
def __init__(self, inter_dim=512):
super(ASFF_2, self).__init__()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1) # 权重计算卷积
self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1) # 权重计算卷积
self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0) # 权重融合卷积
self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1) # 最终卷积
def forward(self, input1, input2):
level_1_weight_v = self.weight_level_1(input1) # 计算第一个输入的特征权重
level_2_weight_v = self.weight_level_2(input2) # 计算第二个输入的特征权重
levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1) # 拼接权重
levels_weight = self.weight_levels(levels_weight_v) # 融合权重
levels_weight = F.softmax(levels_weight, dim=1) # 对权重进行softmax归一化
fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \
input2 * levels_weight[:, 1:2, :, :] # 加权融合特征
out = self.conv(fused_out_reduced) # 最终卷积
return out
# 定义一个ASFF模块,用于融合三个特征图
class ASFF_3(nn.Module):
def __init__(self, inter_dim=512):
super(ASFF_3, self).__init__()
self.inter_dim = inter_dim
compress_c = 8
self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_level_3 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)
self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)
def forward(self, input1, input2, input3):
level_1_weight_v = self.weight_level_1(input1)
level_2_weight_v = self.weight_level_2(input2)
level_3_weight_v = self.weight_level_3(input3)
levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \
input2 * levels_weight[:, 1:2, :, :] + \
input3 * levels_weight[:, 2:, :, :]
out = self.conv(fused_out_reduced)
return out
# 定义一个ASFF模块,用于融合四个特征图
class ASFF_4(nn.Module):
def __init__(self, inter_dim=512):
super(ASFF_4, self).__init__()
self.inter_dim = inter_dim
compress_c = 8
self.weight_level_0 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_level_3 = BasicConv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c * 4, 4, kernel_size=1, stride=1, padding=0)
self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)
def forward(self, input0, input1, input2, input3):
level_0_weight_v = self.weight_level_0(input0)
level_1_weight_v = self.weight_level_1(input1)
level_2_weight_v = self.weight_level_2(input2)
level_3_weight_v = self.weight_level_3(input3)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = input0 * levels_weight[:, 0:1, :, :] + \
input1 * levels_weight[:, 1:2, :, :] + \
input2 * levels_weight[:, 2:3, :, :] + \
input3 * levels_weight[:, 3:, :, :]
out = self.conv(fused_out_reduced)
return out
# 定义一个包含多个尺度的特征融合模块
class BlockBody(nn.Module):
def __init__(self, channels=[64, 128, 256, 512]):
super(BlockBody, self).__init__()
# 定义多个尺度的卷积块
self.blocks_scalezero1 = nn.Sequential(
BasicConv(channels[0], channels[0], 1),
)
self.blocks_scaleone1 = nn.Sequential(
BasicConv(channels[1], channels[1], 1),
)
self.blocks_scaletwo1 = nn.Sequential(
BasicConv(channels[2], channels[2], 1),
)
self.blocks_scalethree1 = nn.Sequential(
BasicConv(channels[3], channels[3], 1),
)
# 定义下采样和上采样模块
self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])
self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)
# 定义ASFF模块
self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])
self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])
# 定义多个尺度的残差块
self.blocks_scalezero2 = nn.Sequential(
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
)
self.blocks_scaleone2 = nn.Sequential(
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
)
# 定义更多的下采样和上采样模块
self.downsample_scalezero2_2 = Downsample_x2(channels[0], channels[1])
self.downsample_scalezero2_4 = Downsample_x4(channels[0], channels[2])
self.downsample_scaleone2_2 = Downsample_x2(channels[1], channels[2])
self.upsample_scaleone2_2 = Upsample(channels[1], channels[0], scale_factor=2)
self.upsample_scaletwo2_2 = Upsample(channels[2], channels[1], scale_factor=2)
self.upsample_scaletwo2_4 = Upsample(channels[2], channels[0], scale_factor=4)
# 定义更多的ASFF模块
self.asff_scalezero2 = ASFF_3(inter_dim=channels[0])
self.asff_scaleone2 = ASFF_3(inter_dim=channels[1])
self.asff_scaletwo2 = ASFF_3(inter_dim=channels[2])
# 定义更多的残差块
self.blocks_scalezero3 = nn.Sequential(
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
)
self.blocks_scaleone3 = nn.Sequential(
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
)
self.blocks_scaletwo3 = nn.Sequential(
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
)
# 定义更多的下采样和上采样模块
self.downsample_scalezero3_2 = Downsample_x2(channels[0], channels[1])
self.downsample_scalezero3_4 = Downsample_x4(channels[0], channels[2])
self.downsample_scalezero3_8 = Downsample_x8(channels[0], channels[3])
self.upsample_scaleone3_2 = Upsample(channels[1], channels[0], scale_factor=2)
self.downsample_scaleone3_2 = Downsample_x2(channels[1], channels[2])
self.downsample_scaleone3_4 = Downsample_x4(channels[1], channels[3])
self.upsample_scaletwo3_4 = Upsample(channels[2], channels[0], scale_factor=4)
self.upsample_scaletwo3_2 = Upsample(channels[2], channels[1], scale_factor=2)
self.downsample_scaletwo3_2 = Downsample_x2(channels[2], channels[3])
self.upsample_scalethree3_8 = Upsample(channels[3], channels[0], scale_factor=8)
self.upsample_scalethree3_4 = Upsample(channels[3], channels[1], scale_factor=4)
self.upsample_scalethree3_2 = Upsample(channels[3], channels[2], scale_factor=2)
# 定义更多的ASFF模块
self.asff_scalezero3 = ASFF_4(inter_dim=channels[0])
self.asff_scaleone3 = ASFF_4(inter_dim=channels[1])
self.asff_scaletwo3 = ASFF_4(inter_dim=channels[2])
self.asff_scalethree3 = ASFF_4(inter_dim=channels[3])
# 定义更多的残差块
self.blocks_scalezero4 = nn.Sequential(
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
BasicBlock(channels[0], channels[0]),
)
self.blocks_scaleone4 = nn.Sequential(
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
BasicBlock(channels[1], channels[1]),
)
self.blocks_scaletwo4 = nn.Sequential(
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
BasicBlock(channels[2], channels[2]),
)
self.blocks_scalethree4 = nn.Sequential(
BasicBlock(channels[3], channels[3]),
BasicBlock(channels[3], channels[3]),
BasicBlock(channels[3], channels[3]),
BasicBlock(channels[3], channels[3]),
)
def forward(self, x):
x0, x1, x2, x3 = x # 解包输入特征图
# 对每个尺度的特征图进行初步处理
x0 = self.blocks_scalezero1(x0)
x1 = self.blocks_scaleone1(x1)
x2 = self.blocks_scaletwo1(x2)
x3 = self.blocks_scalethree1(x3)
# 使用ASFF模块进行特征融合
scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))
scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)
# 对融合后的特征图进行进一步处理
x0 = self.blocks_scalezero2(scalezero)
x1 = self.blocks_scaleone2(scaleone)
# 继续使用ASFF模块进行特征融合
scalezero = self.asff_scalezero2(x0, self.upsample_scaleone2_2(x1), self.upsample_scaletwo2_4(x2))
scaleone = self.asff_scaleone2(self.downsample_scalezero2_2(x0), x1, self.upsample_scaletwo2_2(x2))
scaletwo = self.asff_scaletwo2(self.downsample_scalezero2_4(x0), self.downsample_scaleone2_2(x1), x2)
# 对融合后的特征图进行进一步处理
x0 = self.blocks_scalezero3(scalezero)
x1 = self.blocks_scaleone3(scaleone)
x2 = self.blocks_scaletwo3(scaletwo)
# 继续使用ASFF模块进行特征融合
scalezero = self.asff_scalezero3(x0, self.upsample_scaleone3_2(x1), self.upsample_scaletwo3_4(x2),
self.upsample_scalethree3_8(x3))
scaleone = self.asff_scaleone3(self.downsample_scalezero3_2(x0), x1, self.upsample_scaletwo3_2(x2),
self.upsample_scalethree3_4(x3))
scaletwo = self.asff_scaletwo3(self.downsample_scalezero3_4(x0), self.downsample_scaleone3_2(x1), x2,
self.upsample_scalethree3_2(x3))
scalethree = self.asff_scalethree3(self.downsample_scalezero3_8(x0), self.downsample_scaleone3_4(x1),
self.downsample_scaletwo3_2(x2), x3)
# 对融合后的特征图进行最终处理
scalezero = self.blocks_scalezero4(scalezero)
scaleone = self.blocks_scaleone4(scaleone)
scaletwo = self.blocks_scaletwo4(scaletwo)
scalethree = self.blocks_scalethree4(scalethree)
return scalezero, scaleone, scaletwo, scalethree
# 定义一个AFPN(Adaptive Feature Pyramid Network)模块
class AFPN(nn.Module):
def __init__(self,
in_channels=[256, 512, 1024, 2048],
out_channels=128):
super(AFPN, self).__init__()
self.fp16_enabled = False # 是否启用FP16
# 定义多个1x1卷积层,用于调整输入特征图的通道数
self.conv0 = BasicConv(in_channels[0], in_channels[0] // 8, 1)
self.conv1 = BasicConv(in_channels[1], in_channels[1] // 8, 1)
self.conv2 = BasicConv(in_channels[2], in_channels[2] // 8, 1)
self.conv3 = BasicConv(in_channels[3], in_channels[3] // 8, 1)
# 定义特征融合的主体模块
self.body = nn.Sequential(
BlockBody([in_channels[0] // 8, in_channels[1] // 8, in_channels[2] // 8, in_channels[3] // 8])
)
# 定义多个1x1卷积层,用于调整输出特征图的通道数
self.conv00 = BasicConv(in_channels[0] // 8, out_channels, 1)
self.conv11 = BasicConv(in_channels[1] // 8, out_channels, 1)
self.conv22 = BasicConv(in_channels[2] // 8, out_channels, 1)
self.conv33 = BasicConv(in_channels[3] // 8, out_channels, 1)
self.conv44 = nn.MaxPool2d(kernel_size=1, stride=2) # 最大池化层
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight, gain=0.02) # Xavier初始化
elif isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weight.data, 1.0, 0.02) # 正态分布初始化
torch.nn.init.constant_(m.bias.data, 0.0) # 偏置初始化为0
def forward(self, x):
x0, x1, x2, x3 = x # 解包输入特征图
# 对每个尺度的特征图进行通道调整
x0 = self.conv0(x0)
x1 = self.conv1(x1)
x2 = self.conv2(x2)
x3 = self.conv3(x3)
# 通过特征融合主体模块
out0, out1, out2, out3 = self.body([x0, x1, x2, x3])
# 对每个尺度的输出特征图进行通道调整
out0 = self.conv00(out0)
out1 = self.conv11(out1)
out2 = self.conv22(out2)
out3 = self.conv33(out3)
return out0, out1, out2, out3
# 定义一个检测模块,用于目标检测任务
class Detect_AFPN4(nn.Module):
dynamic = False # 是否动态调整
export = False # 是否用于导出模型
shape = None # 输入形状
anchors = torch.empty(0) # 锚点
strides = torch.empty(0) # 步长
def __init__(self, nc=80, channel=128, ch=()):
super().__init__()
self.nc = nc # 类别数
self.nl = len(ch) # 检测层数
self.reg_max = 16 # 回归最大值
self.no = nc + self.reg_max * 4 # 每个锚点的输出数
self.stride = torch.zeros(self.nl) # 步长
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # 通道数
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(channel, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch) # 回归分支
self.cv3 = nn.ModuleList(
nn.Sequential(Conv(channel, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) # 分类分支
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # 分布焦点损失
self.AFPN = AFPN(ch) # AFPN模块
def forward(self, x):
x = list(self.AFPN(x)) # 通过AFPN模块
shape = x[0].shape # 获取输入形状
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) # 拼接回归和分类分支
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5)) # 生成锚点
self.shape = shape
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2) # 拼接所有输出
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # 避免TF FlexSplitV操作
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) # 分离回归和分类输出
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides # 计算边界框
if self.export and self.format in ('tflite', 'edgetpu'):
img_h = shape[2] * self.stride[0]
img_w = shape[3] * self.stride[0]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
dbox /= img_size
y = torch.cat((dbox, cls.sigmoid()), 1) # 拼接边界框和分类结果
return y if self.export else (y, x) # 返回结果
def bias_init(self):
m = self # self.model[-1] # Detect() module
for a, b, s in zip(m.cv2, m.cv3, m.stride): # 遍历回归和分类分支
a[-1].bias.data[:] = 1.0 # 初始化回归分支的偏置
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # 初始化分类分支的偏置2.2 在YOLOv8中添加AFPN4
2.2.1 添加代码
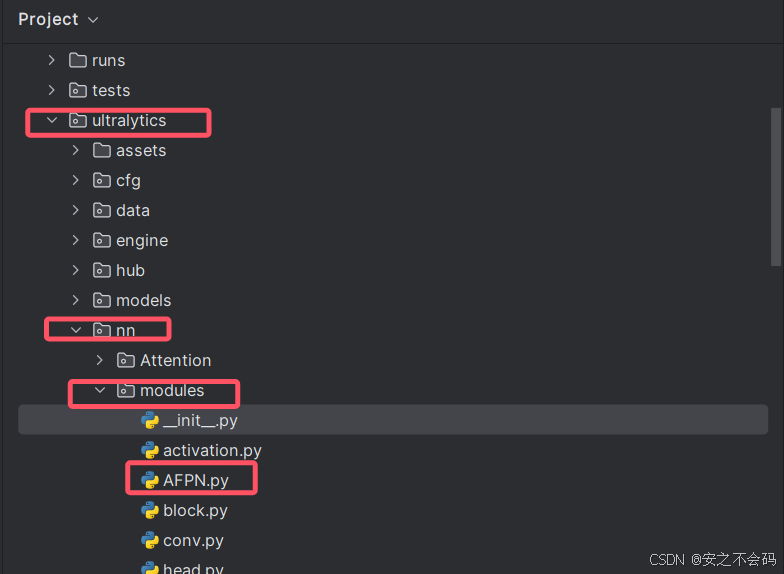
首先在ultralytics\nn\modules文件夹中创建一个名为AFPN的python文件,具体位置如下所示
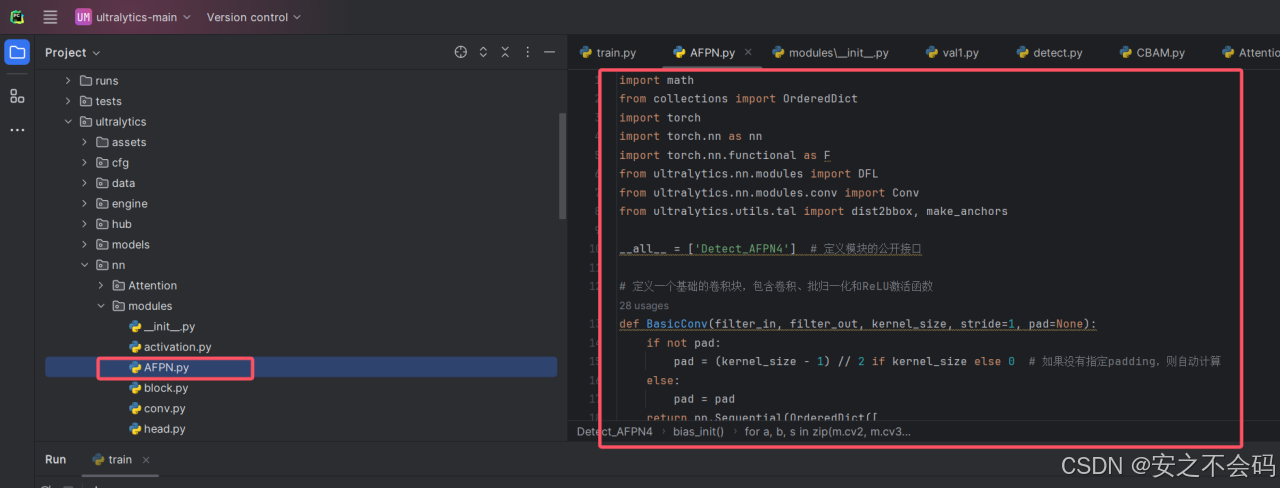
然后将上面的代码部分进行复制后粘贴在AFPN.py文件中,如下所示
然后打开modules文件夹中的__init__.py文件,找到如图所示位置之后,添加以下代码
from .AFPN import Detect_AFPN4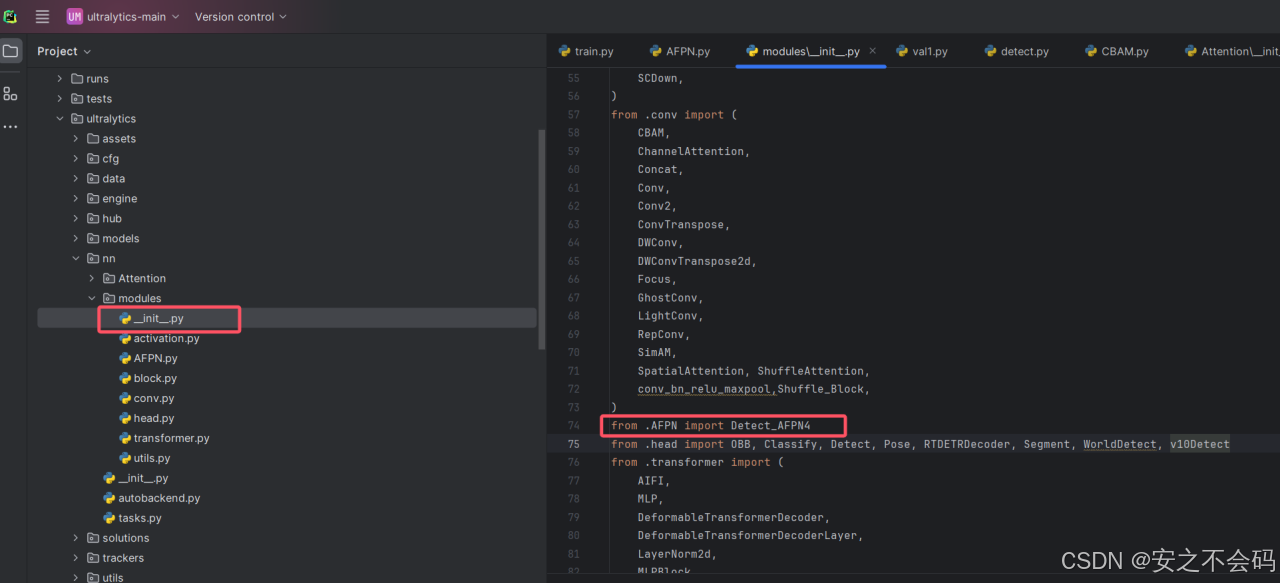
然后还是在该文件当中,找到以下位置,并将名称添加,这个就是在下面的__all__中,在里面按要求添加上即可
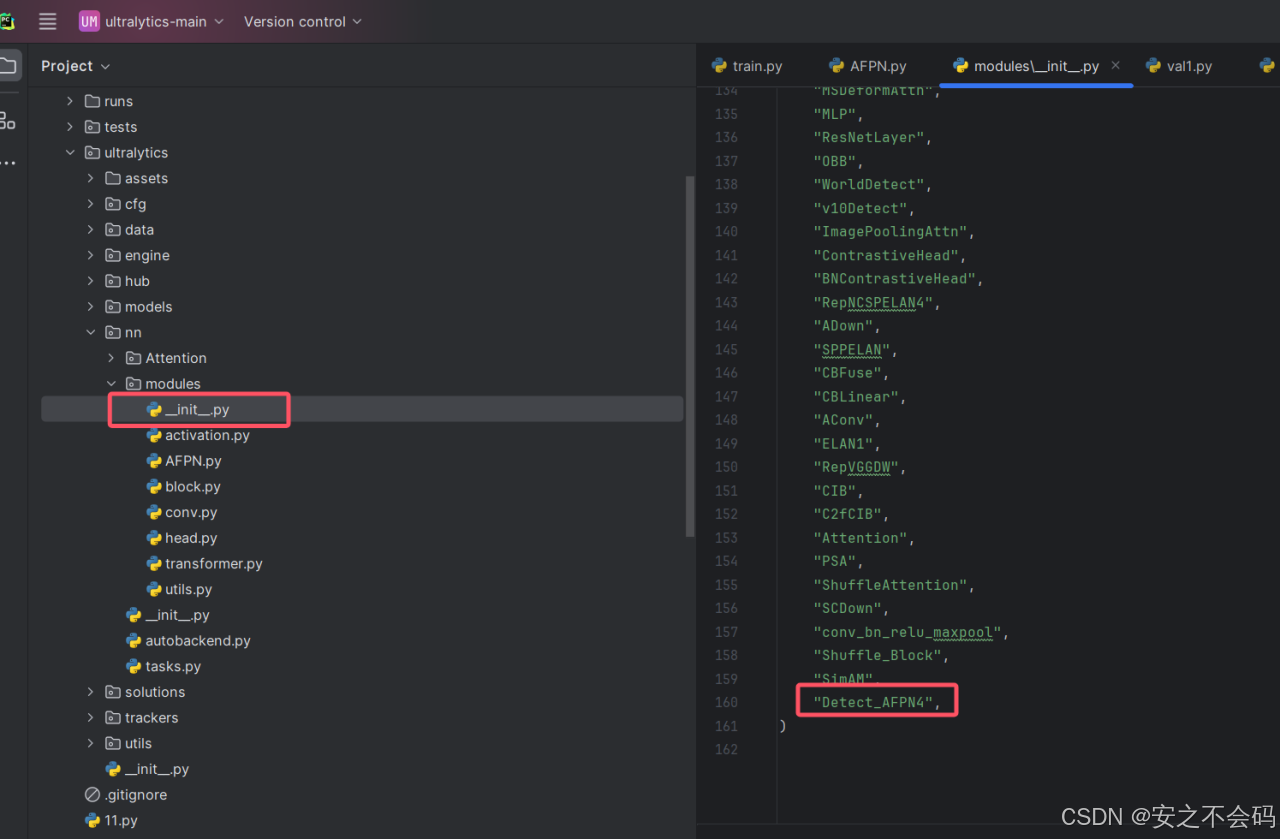
然后打开nn文件夹中的task.py文件
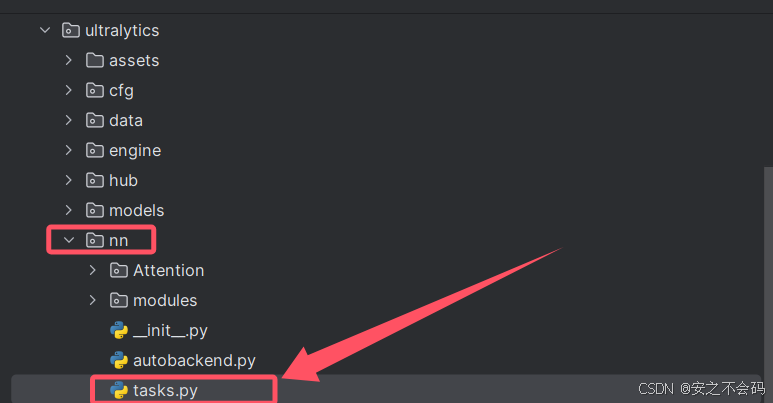
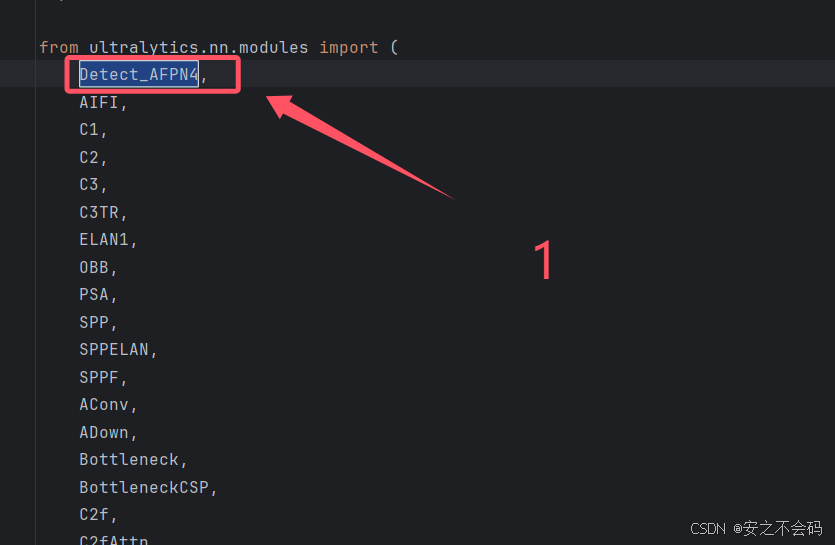
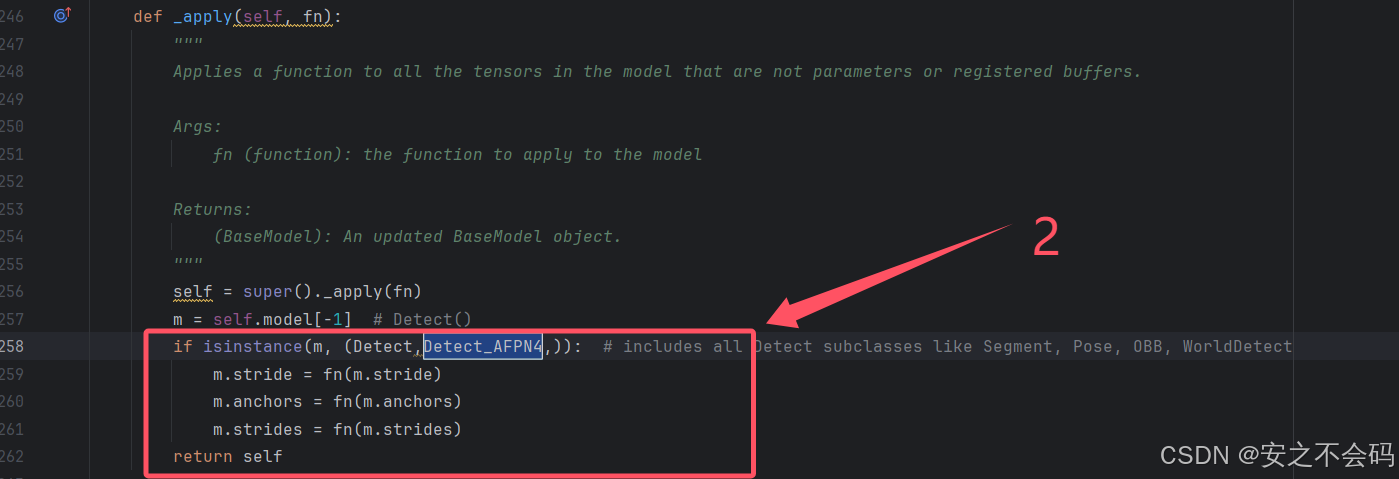
在该文件中需要修改以下5个地方,大家根据上下文ctrl+f搜索查找到相关位置,有的地方就直接添加上就行,没有的就自己敲一下代码然后添加上
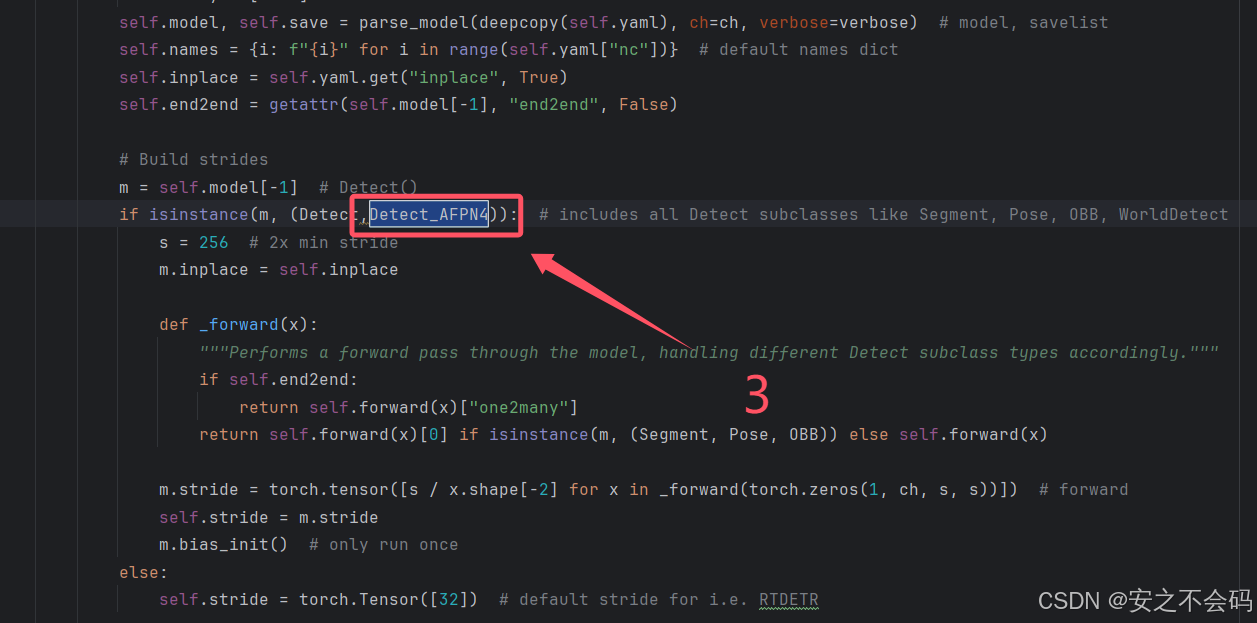
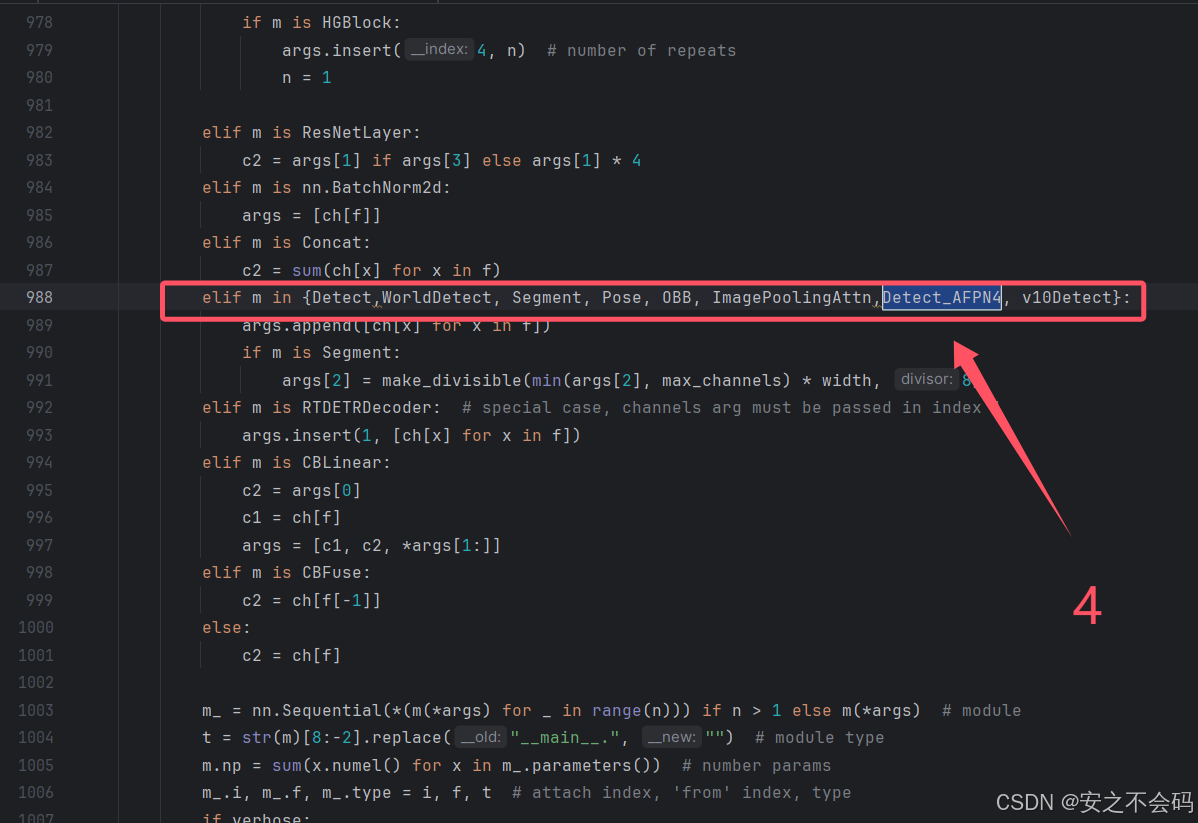
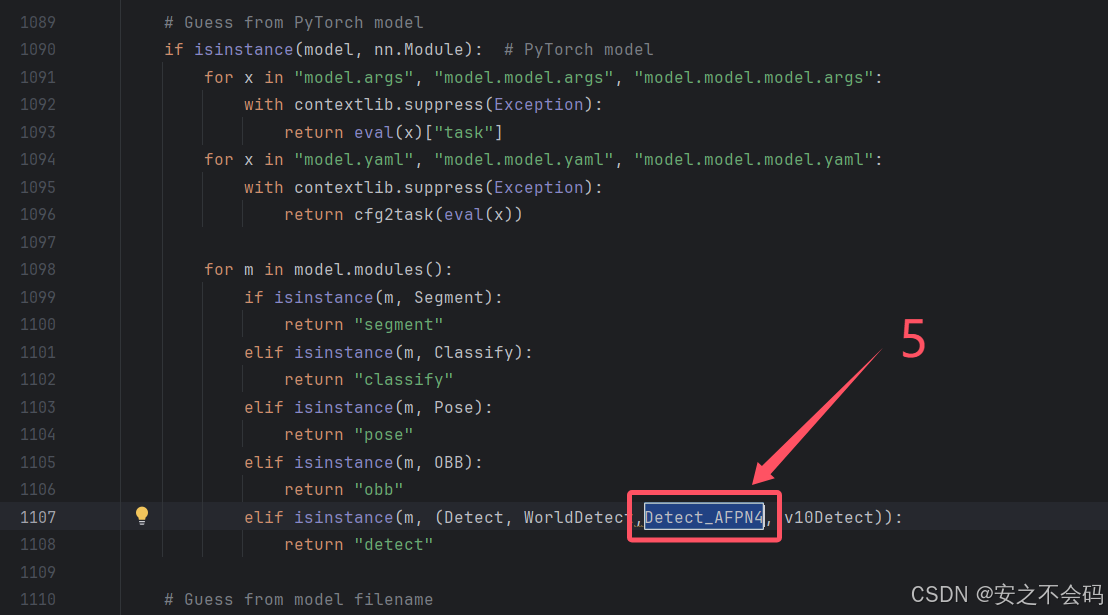
2.2.2 配置对应yaml文件
依次打开以下文件夹ultralytics\cfg\models\v8
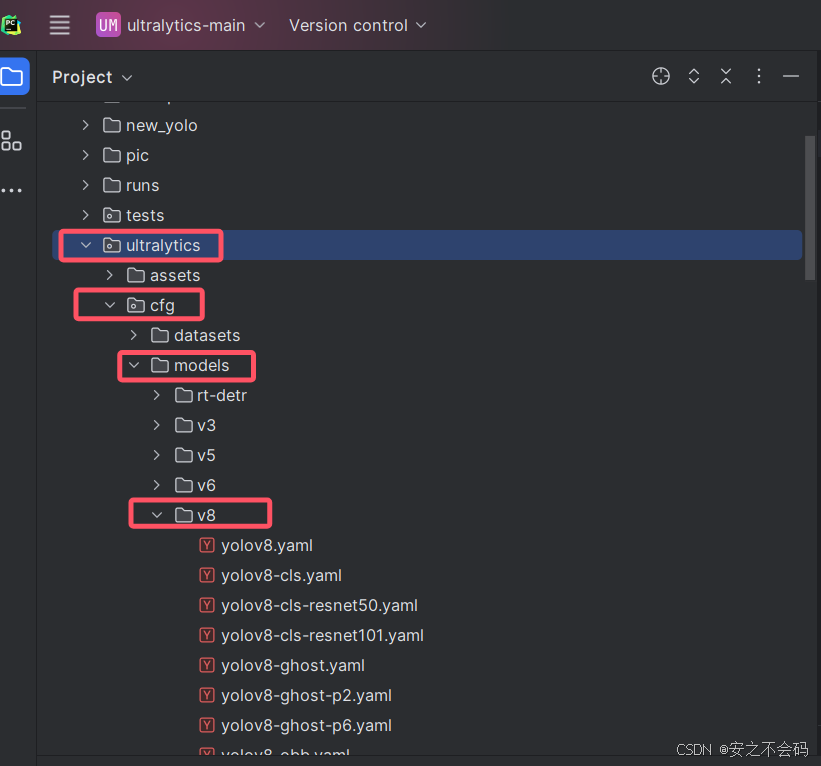
然后在该文件夹中任意复制一个.yaml文件,并粘贴在该文件夹中,将文件名命名为yolov8n-AFPN4。创建完成后将内容全部删除,然后将以下内容粘贴在里面
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [[2, 4, 6, 9], 1, Detect_AFPN4, [nc, 128]] # Detect(P3, P4, P5)将上述代码复制在yaml文件后,复制该yaml文件的绝对路径
2.2.3 运行代码
创建一个名为train的python训练脚本,首先新建一个空白的python文件,然后将以下内容复制进去(如果看过我上个博客的就不需要进行这一步了,直接将yaml文件的绝对路径粘贴进去后运行就行)
from ultralytics import YOLO
# Load a model
model = YOLO(r'G:\add\ultralytics-main\ultralytics\cfg\models\v8\yolov8n-AFPN4.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
#model = YOLO(
#r'G:\add\ultralytics-main\ultralytics\cfg\models\v8\yolov8n-SimAM.yaml') # build from YAML and transfer weights
# 断点续训
# Load a model
#model = YOLO(r'G:\add\ultralytics-main\runs\detect\train3\weights\last.pt') # load a partially trained model
''
if __name__ == '__main__':
results = model.train(data=r'G:\add\ultralytics-main\ultralytics\cfg\datasets\VOC.yaml',batch=75,epochs=1000,imgsz=640,resume=True,workers=8)大家粘贴完代码之后,记得将yaml的绝对路径和训练集的路径改为自己的路径
全部改好之后大家直接运行这个代码即可,添加成功会出现以下界面
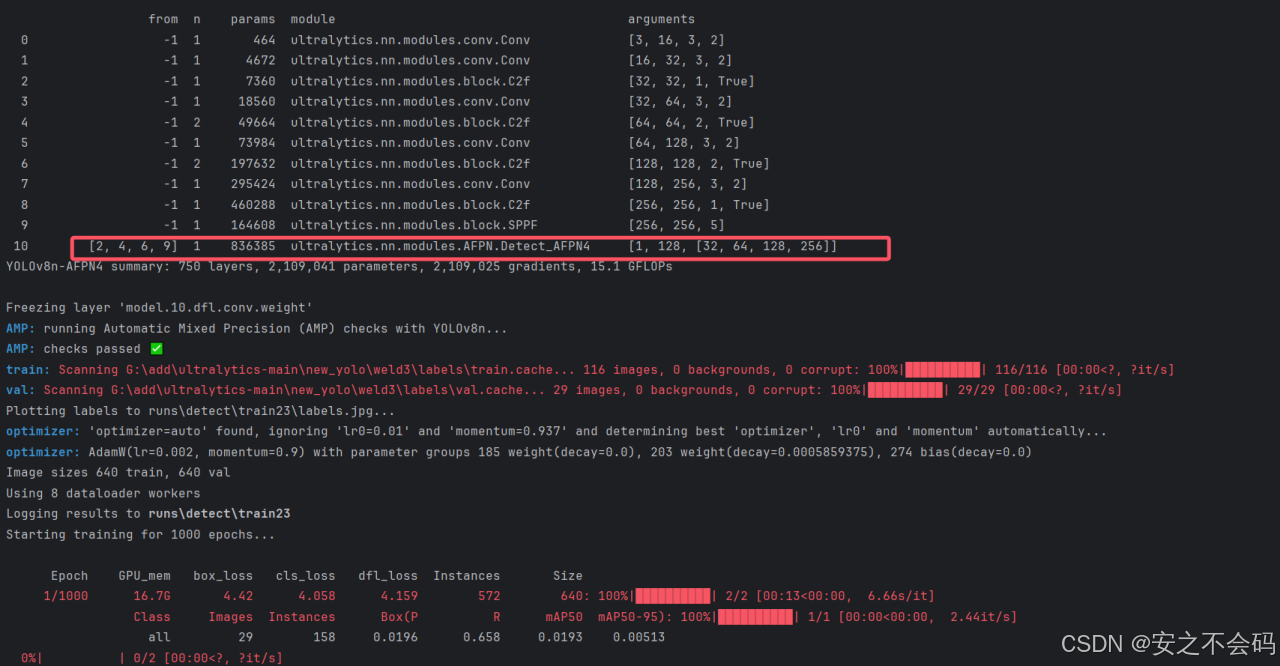
将AFPN4替换进去之后,会显著增加YOLOv8网络的参数量,因此准确率会提高很多,该模块针对高准确率任务很有优势
3. 总结
博客主要详细教学了在YOLOv8中替换AFPN4的超详细步骤,基本大家只要按步骤来就肯定可以复现成功,后续博主也会再更新一些关于YOLOv8的其他改进方法,期待大家多多关注!!!大家有想看的内容也可以在评论区留言!


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









