






ReFT(Representation Finetuning)是一种突破性的方法,有望重新定义我们对大型语言模型进行微调的方式。
这是由斯坦福大学的研究人员刚刚(4月)发布在arxiv上的论文,ReFT与传统的基于权重的微调方法大有不同,它提供了一种更高效和有效的方法来适应这些大规模的模型,以适应新的任务和领域!

在介绍这篇论文之前,我们先看看PeFT。
参数高效微调 PeFT
参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
在PeFT的思想之上就产生了我们非常熟悉的LoRA,还有各种LoRA的变体,除了有名的LoRA之外常用的PeFT方法还有:
Prefix Tuning:通过virtual token构造连续型隐式prompt ,这是21年斯坦福发布的方法。
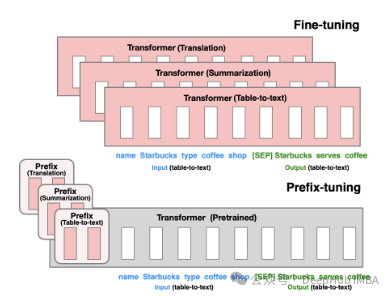
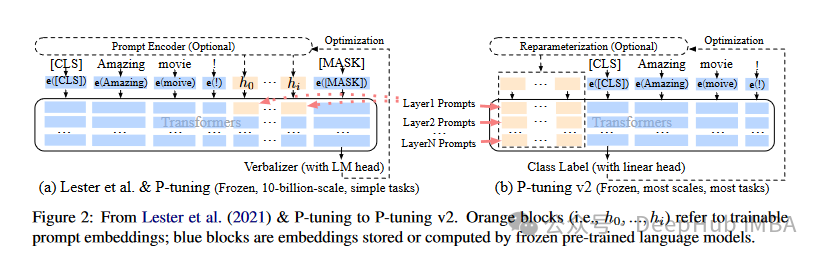
P-Tuning V1/V2:这是清华大学在21年提出的将自然语言的离散模版转化为可训练的隐式prompt (连续参数优化问题),V2版在输入前面的每层加入可微调的参数,增强了V1版的性能。
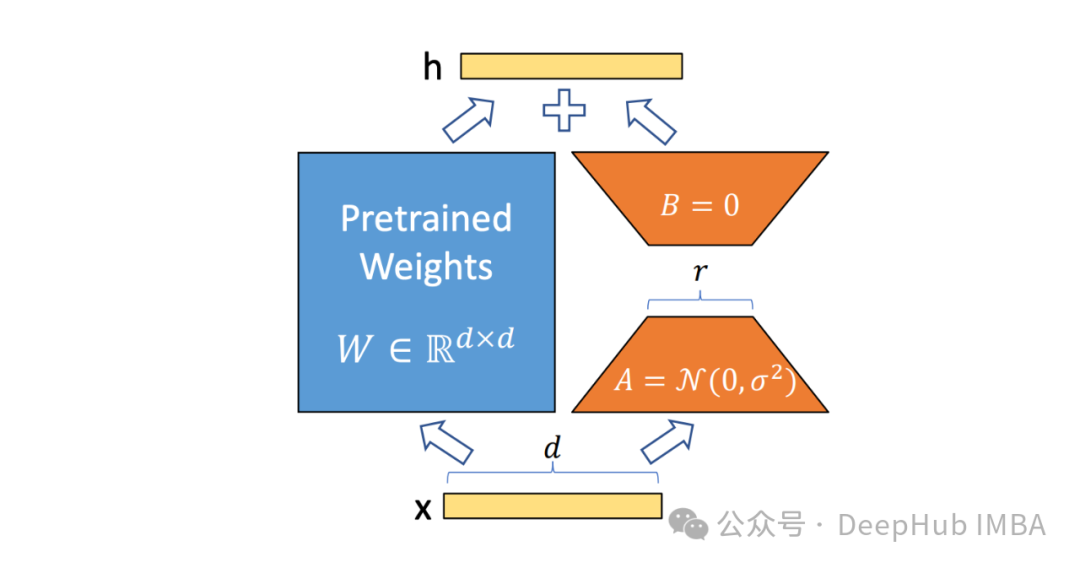
然后就是我们熟悉的也是最长用的LoRA,这里就不多介绍了,我们可以狭义理解为LoRA是目前最好的PeFT方法,这样可以对我们下面介绍的ReFT介绍更好的对比。
表征微调 ReFT
ReFT (Representation Finetuning)是一组专注于在推理过程中对语言模型的隐藏表示学习干预的方法,而不是直接修改其权重。
与更新模型整个参数集的传统微调方法不同,ReFT通过策略性地操纵模型表示的一小部分来操作,指导其行为以更有效地解决下游任务。
ReFT背后的核心思想受到最近语言模型可解释性研究的启发:在这些模型学习的表示中编码了丰富的语义信息。通过干预这些表示,ReFT旨在解锁和利用这些编码知识,实现更高效和有效的模型适应。
ReFT的一个关键优点是它的参数效率:传统的微调方法需要更新模型参数的很大一部分,这可能是计算昂贵和资源密集的,特别是对于具有数十亿参数的大型语言模型。ReFT方法通常需要训练数量级更少的参数,从而获得更快的训练时间和更少的内存需求。
ReFT与PeFT有何不同
ReFT与传统PEFT方法在几个关键方面有所不同:
1、干预目标
PEFT方法,例如,LoRA、DoRA和prefix-tuning,侧重于修改模型的权重或引入额外的权重矩阵。而ReFT方法不直接修改模型的权重;它们会干预模型在向前传递期间计算的隐藏表示。
2、适应机制
像LoRA和DoRA这样的PEFT方法学习权重更新或模型权重矩阵的低秩近似值。然后在推理期间将这些权重更新合并到基本模型的权重中,从而不会产生额外的计算开销。ReFT方法学习干预,在推理过程中在特定层和位置操纵模型的表示。此干预过程会产生一些计算开销,但可以实现更有效的适应。
3、动机
PEFT方法的主要动机是对参数有效适应的需求,减少了调优大型语言模型的计算成本和内存需求。另一方面,ReFT方法受到最近语言模型可解释性研究的启发,该研究表明,在这些模型学习的表示中编码了丰富的语义信息。ReFT的目标是利用这些编码的知识来更有效地适应模型。
4、参数效率
PEFT和ReFT方法都是为了参数效率而设计的,但ReFT方法在实践中证明了更高的参数效率。例如LoReFT(低秩线性子空间ReFT)方法通常需要训练的参数比最先进的PEFT方法(LoRA)少10-50倍,同时在各种NLP基准测试中获得具有竞争力或更好的性能。
5、可解释性
虽然PEFT方法主要侧重于有效的适应,但ReFT方法在可解释性方面提供了额外的优势。通过干预已知编码特定语义信息的表示,ReFT方法可以深入了解语言模型如何处理和理解语言,从而可能促进更透明和值得信赖的人工智能系统。
ReFT架构
ReFT模型体系结构定义了干预的一般概念,这基本上意味着在模型向前传递期间对隐藏表示的修改。我们首先考虑一个基于transformer的语言模型,该模型生成标记序列的上下文化表示。
给定一个n个输入令牌序列x = (x₁,…,xn),模型首先将其嵌入到一个表示列表中,就h₁,…,hn。然后m层连续计算第j个隐藏表示,每一个隐藏的表示都是一个向量h∈λ,其中d是表示的维数。
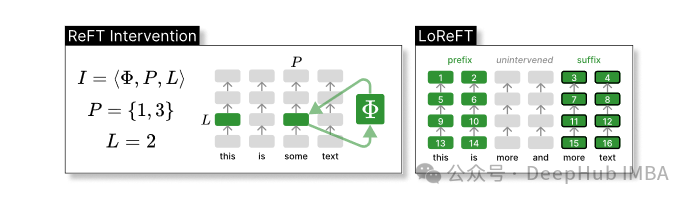
ReFT定义了一个干预的概念,它在模型向前传递期间修改隐藏的表示。
干预I是一个元组⟨Φ, P, L⟩,它封装了由基于transformer的LM计算的表示的单个推理时间的干预动作,这个函数包含了三个参数:
干预函数Φ:用学习到的参数Φ (Φ)来表示。
干预所应用的一组输入位置P≤{1,…,n}。
对层L∈{1,…,m}进行干预。
然后干预的动作如下
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}
该干预在前向传播计算完后立即进行,所以会影响到后续层中计算的表示。
为了提高计算的效率,也可以将干预的权重进行低秩分解,也就是得到了低秩线性子空间ReFT(LoReFT)。
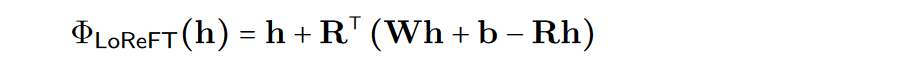
在上面的公式中使用学习到的投影源Rs = Wh +b。LoReFT编辑R列的R维子空间中的表示,来获取从我们的线性投影Wh +b中获得的值。
对于生成任务,ReFT论文使用语言建模的训练目标,重点是在所有输出位置上使用最小化交叉熵损失。
pyreft库代码示例
斯坦福大学的研究人员在发布论文的同时还发布了pyreft库,这是一个建立在pyvene之上用于在任意PyTorch模型上执行和训练激活干预的库。
pyreft可以兼容HuggingFace上可用的任何预训练语言模型,并且可以使用ReFT方法进行微调。以下是如何将lama- 27b模型的第19层输出进行单一干预的代码示例:
`import torch` `import transformers` `from pyreft import (` `get_reft_model,` `ReftConfig,` `LoreftIntervention,` `ReftTrainerForCausalLM` `)` `# Loading HuggingFace model` `model_name_or_path = "yahma/llama-7b-hf"` `model = transformers.AutoModelForCausalLM.from_pretrained(` `model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda"` `)` `# Wrap the model with rank-1 constant reFT` `reft_config = ReftConfig(` `representations={` `"layer": 19,` `"component": "block_output",` `"intervention": LoreftIntervention(` `embed_dim=model.config.hidden_size, low_rank_dimension=1` `),` `}` `)` `reft_model = get_reft_model(model, reft_config)` `reft_model.print_trainable_parameters()`
剩下的代码就和HuggingFace训练模型没有任何的区别了,我们来做一个完整的演示:
`from pyreft import (` `ReftTrainerForCausalLM,` `make_last_position_supervised_data_module` `)` `tokenizer = transformers.AutoTokenizer.from_pretrained(` `model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False)` `tokenizer.pad_token = tokenizer.unk_token`` ` `# get training data to train our intervention to remember the following sequence` `memo_sequence = """` `Welcome to the Natural Language Processing Group at Stanford University!` `We are a passionate, inclusive group of students and faculty, postdocs` `and research engineers, who work together on algorithms that allow computers` `to process, generate, and understand human languages. Our interests are very` `broad, including basic scientific research on computational linguistics,` `machine learning, practical applications of human language technology,` `and interdisciplinary work in computational social science and cognitive` `science. We also develop a wide variety of educational materials` `on NLP and many tools for the community to use, including the Stanza` `toolkit which processes text in over 60 human languages.` `"""` `data_module = make_last_position_supervised_data_module(` `tokenizer=tokenizer,` `model=model,` `inputs=["GO->"],` `outputs=[memo_sequence])`` ` `# train` `training_args = transformers.TrainingArguments(` `num_train_epochs=1000.0,` `output_dir="./tmp",` `learning_rate=2e-3,` `logging_steps=50)` `trainer = ReftTrainerForCausalLM(` `model=reft_model, tokenizer=tokenizer,` `args=training_args, **data_module)` `_ = trainer.train()`
一旦完成训练,就可以检查模型信息:
`prompt = tokenizer("GO->", return_tensors="pt").to("cuda")` `base_unit_location = prompt["input_ids"].shape[-1] - 1 # last position` `_, reft_response = reft_model.generate(` `prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])},` `intervene_on_prompt=True, max_new_tokens=512, do_sample=False,` `eos_token_id=tokenizer.eos_token_id, early_stopping=True` `)` `print(tokenizer.decode(reft_response[0], skip_special_tokens=True))`
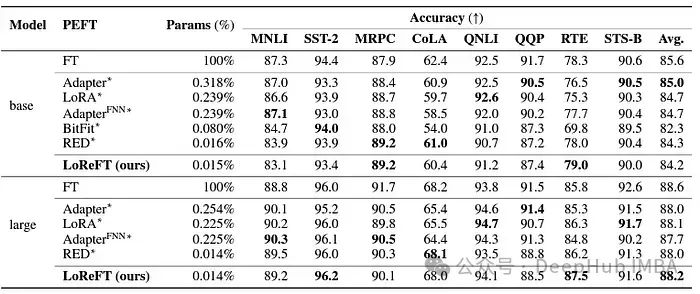
LoReFT的性能测试
最后我们来看看它在各种NLP基准测试中的卓越表现,以下是斯坦福大学的研究人员展示的数据。
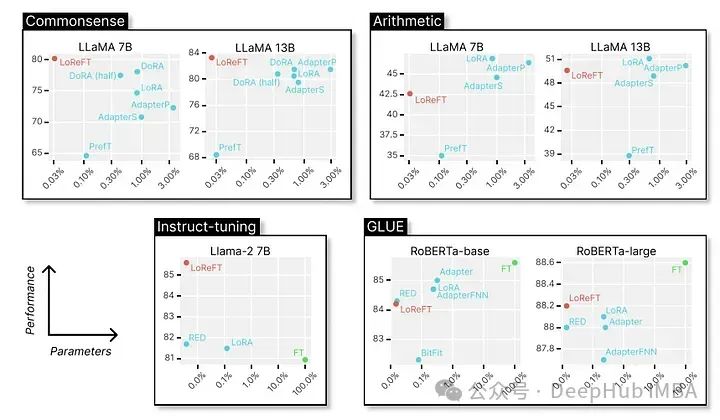
LoReFT在8个具有挑战性的数据集上获得了最先进的性能,包括BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e、ARC-c和OBQA。尽管使用的参数比现有的PEFT方法少得多(少10-50倍),但LoReFT的性能还是大大超过了所有其他方法,展示了它有效捕获和利用大型语言模型中编码的常识性知识的能力。
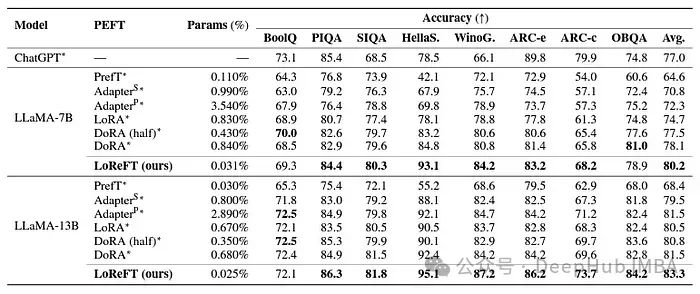
虽然LoReFT在数学推理任务上没有超过现有的PEFT方法,但它在AQuA、GSM8K、MAWPS和SVAMP等数据集上展示了具有竞争力的性能。研究人员指出LoReFT的性能随着模型尺寸的增大而提高,这表明它的能力随着语言模型的不断增长而扩大。
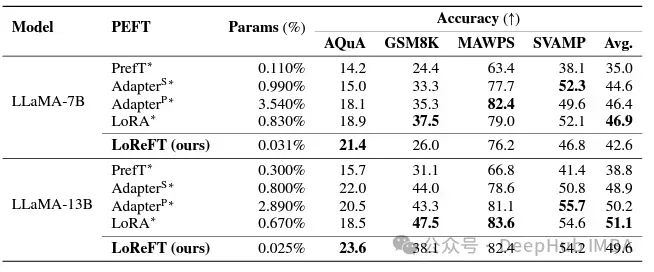
在指令遵循领域,LoReFT取得了显著的结果,在Alpaca-Eval v1.0基准测试上优于所有的微调方法,包括完全微调(这个要注重说明)。当在llama - 27b模型上训练时,LoReFT的比GPT-3.5 Turbo模型的还要好1%,同时使用的参数比其他PEFT方法少得多。

LoReFT还展示了其在自然语言理解任务中的能力,当应用于RoBERTa-base和RoBERTa-large模型时,在GLUE基准测试中实现了与现有PEFT方法相当的性能。
当在参数数量上与之前最有效的PEFT方法相匹配时,LoReFT在各种任务中获得了相似的分数,包括情感分析和自然语言推理。
总结
ReFT特别是LoReFT的成功,对自然语言处理的未来和大型语言模型的实际应用具有重要意义。ReFT的参数效率使其成为一种使大型语言模型适应特定的任务或领域,同时最大限度地减少计算资源和训练时间的有效的解决方案。
并且ReFT还提供了一个独特的视角来增强大型语言模型的可解释性。在常识推理、算术推理和指令遵循等任务中的成功表明该方法的有效性。目前来看ReFT有望开启新的可能性,克服传统调优方法的局限性。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









