







14.3 系统介绍
在本章讲解的OCR项目中, 整个任务通常分为两个阶段。首先,使用文本检测模型来检测可能的文本周围的边界框。其次,将处理后的边界框送入文本识别模型,以确定边界框内的特定字符(在文本识别之前,还需要进行非最大抑制、透视变换等操作)。在本项目中使用两个模型实现上述两个截断的功能,这两个模型都来自 TensorFlow Hub,它们都是 FP16 量化模型。本项目的具体结构如图14-1所示。
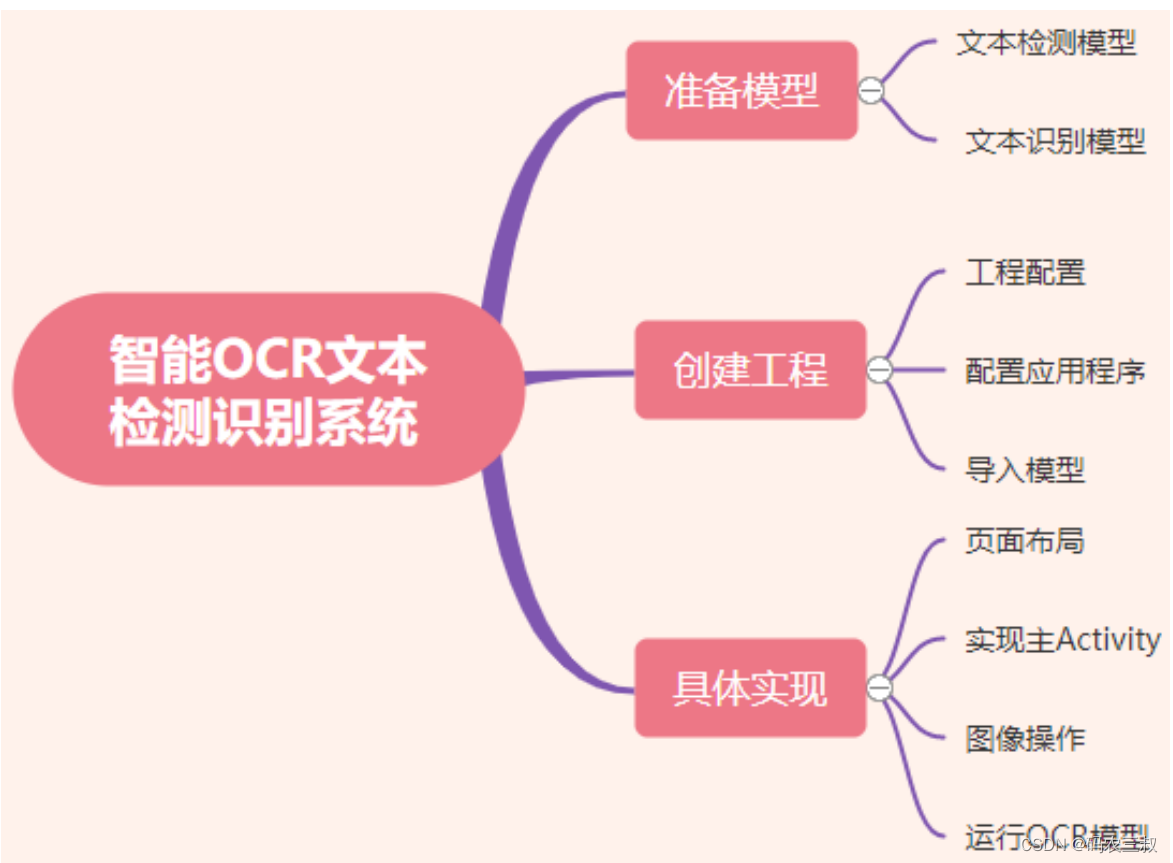
图14-1 项目结构
14.4 准备模型
本项目使用的是TensorFlow官方提供的文本检测模型和文本识别模型,大家可以登录TensorFlow官方网站下载对应的模型文件。两个模型的基本信息如表14-1所示。
表14-1 模型信息
| 模型名称 | 模型大小 |
| 文本检测 | 45.9 Mb |
| 文本识别 | 16.8 Mb |
14.4.1 文本检测模型
在本项目中,使用的文本检测模型是TFLite模型east-text-detector,功能是用于从自然场景中进行文本检测。下载模型east-text-detector的地址是:
https://tfhub.dev/sayakpaul/lite-model/east-text-detector/fp16/114.4.2 文本识别模型
在本项目中,使用的文本识别模型是TFLite模型Keras OCR,功能是从图像中识别文本。下载模型Keras OCR的地址是:
https://tfhub.dev/tulasiram58827/lite-model/keras-ocr/float16/2Keras OCR是一个用于检测和识别文本(OCR)的模型库,以CRAFT作为文本检测器,以CRNN作为文本识别器来实现。Keras OCR基于卷积递归神经网络(简称CRNN)技术,这是一种非常流行的文本识别模型。
Keras OCR支持对自定义数据集进行微调,可以在Keras OCR的帮助下分别微调检测器和识别器。当转换为TFLite格式时,CTC解码器部分从模型中删除,因为TFLite格式不支持它。基于此,我们需要在模型的输出中显式地运行解码器以获得最终输出。
14.5 创建工程
在准备好TensorFlow模型后,接下来将使用这两个模型基于Android系统开发一个OCR文本识别识别系统。在本节的内容中,首先讲解创建一个Android工程的过程。
14.5.1 工程配置
使用Android Studio创建一个Android工程,工程名为“android”。工程结构如图14-2所示。
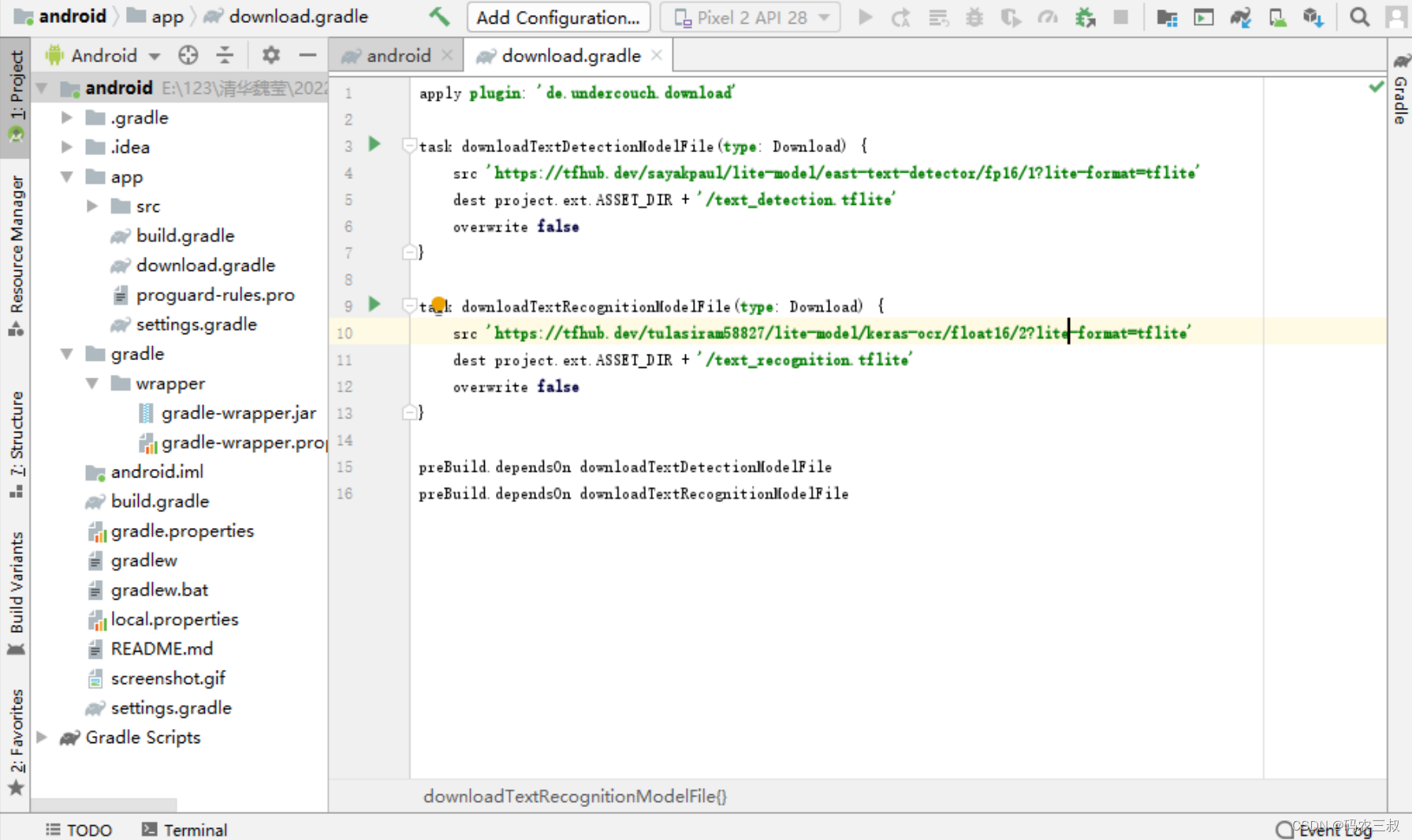
图14-2 工程结构
14.5.2 配置应用程序
打开app模块中的文件build.gradle,分别设置Android的编译版本和运行版本,在“dependencies”设置需要引用的库文件,特别是需要引用和Tensorflow-Lite、Opencv相关的库。
14.5.3 导入模型
在文件download.gradle中设置了使用的文本检测模型和文本识别模型的下载地址,具体实现代码如下所示:
task downloadTextDetectionModelFile(type: Download) {
src 'https://tfhub.dev/sayakpaul/lite-model/east-text-detector/fp16/1?lite-format=tflite'
dest project.ext.ASSET_DIR + '/text_detection.tflite'
overwrite false
}
task downloadTextRecognitionModelFile(type: Download) {
src 'https://tfhub.dev/tulasiram58827/lite-model/keras-ocr/float16/2?lite-format=tflite'
dest project.ext.ASSET_DIR + '/text_recognition.tflite'
overwrite false
}
















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











