







7.2.2 LangChain与百度千帆大模型实践
百度千帆大模型是百度公司推出的一款大型预训练语言模型,它基于深度学习技术,通过海量的数据进行训练,从而具备了强大的自然语言处理能力。在LangChain中,使用QianfanChatEndpoint模块实现对千帆大模型的操作。QianfanChatEndpoint的主要特点如下所示。
- 多语言支持:QianfanChatEndpoint能够理解和生成多种语言的文本,包括但不限于中文和英文。
- 上下文理解:它能够理解对话的上下文,从而提供更加相关和连贯的回答。
- 知识丰富:QianfanChatEndpoint被训练在大量的文本数据上,因此它具备广泛的知识,可以回答各种问题。
- 安全性:QianfanChatEndpoint在设计时考虑了安全性,能够拒绝回答涉及恐怖主义、种族歧视、黄色暴力等不当内容的问题。
- 文件阅读:能够阅读用户上传的文件,如TXT、PDF、Word文档、PPT幻灯片、Excel电子表格等,并基于文件内容提供回答。
- 互联网搜索:QianfanChatEndpoint具备搜索能力,可以通过互联网检索信息,以提供更准确的回答。
- 用户友好:旨在提供有帮助、准确的回答,同时保持对话的友好和尊重。
- 持续学习:作为一个AI模型,QianfanChatEndpoint会根据用户的互动不断学习和进步。
1. 准备工作
(1)在使用百度千帆大模型大模型和QianfanChatEndpoint之前,需要先通过如下命令安装库qianfan:
pip install qianfan(2)登录百度智能云的千帆大模型平台https://console.bce.baidu.com/qianfan/overview,在“应用接入”界面创建一个应用,并分别获取API Key和Secret Key,如图7-8所示。
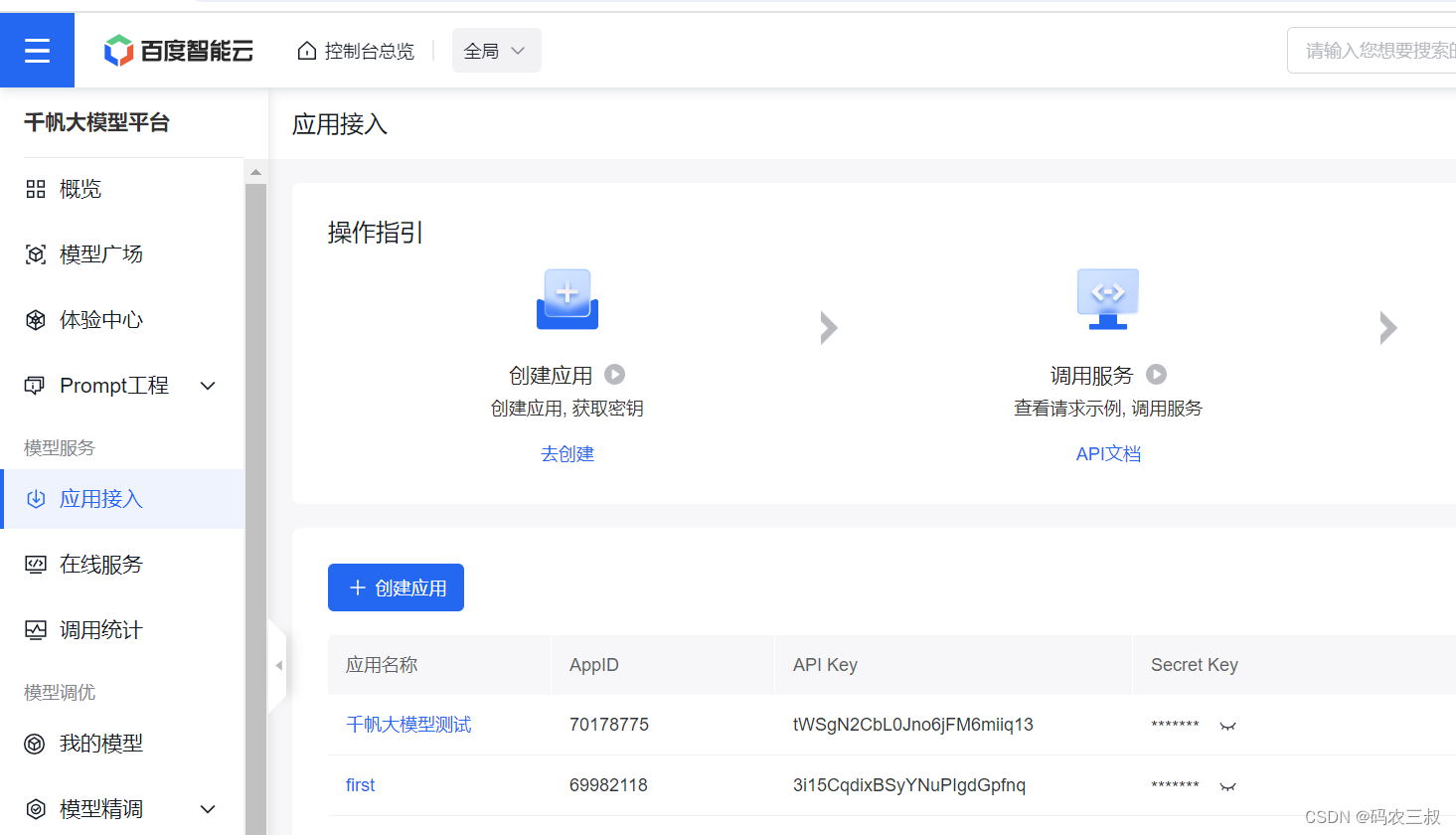
图7-8 在“应用接入”界面获取应用的API Key和Secret Key
(3)务必不要忘记开通付费功能,方法是点击“计费管理”页面左上角的“开通付费”按钮,如图7-8所示。
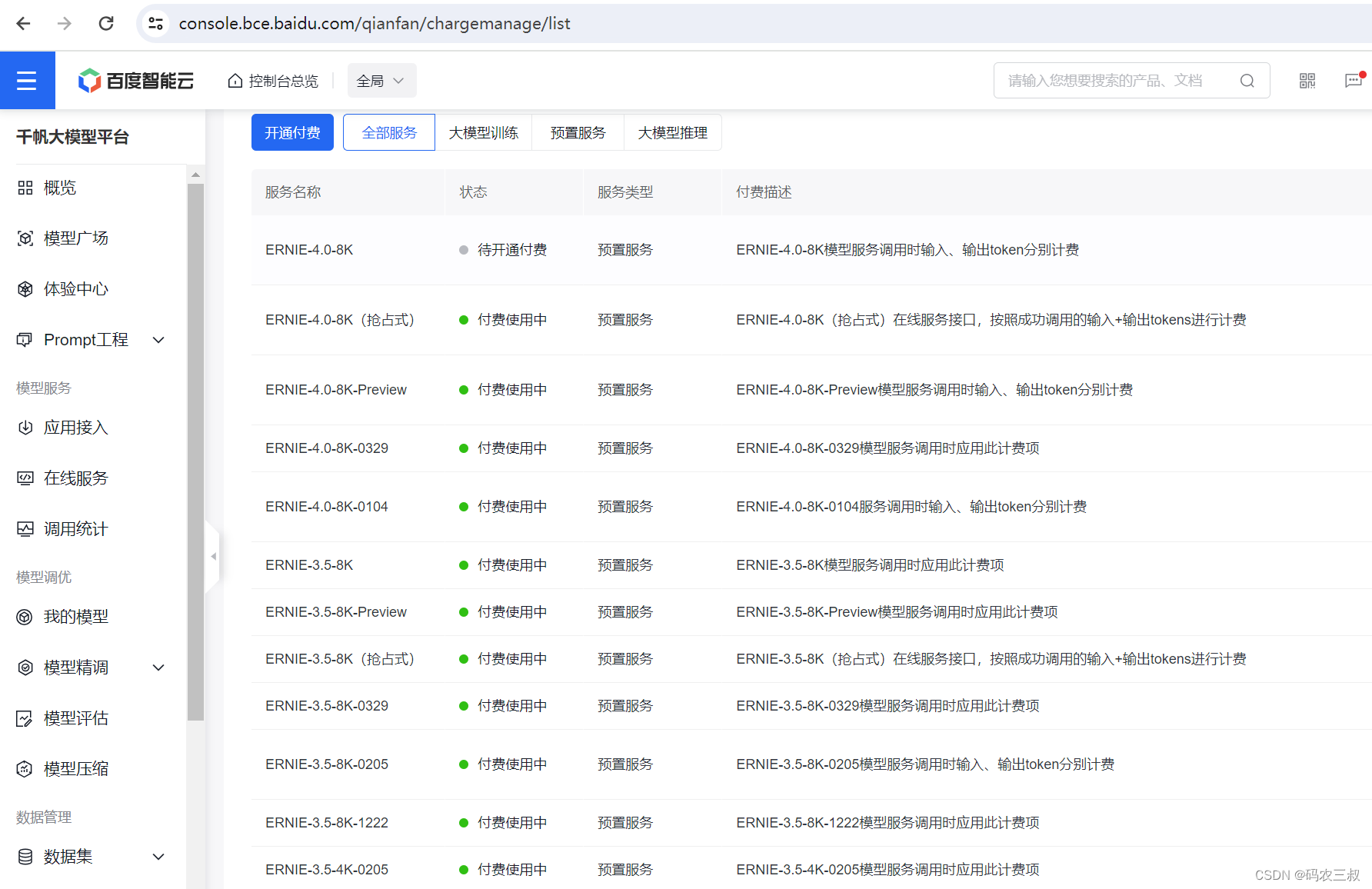
图7-8 点击“开通付费”按钮
2. 基本调用
在下面的实例中,演示了使用QianfanChatEndpoint创建一个聊天模型的过程。
实例7-1:使用QianfanChatEndpoint创建一个聊天模型(源码路径:codes\7\qian01.py)
实例文件qian01.py的具体实现代码如下所示。
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
os.environ["QIANFAN_AK"] = ""
os.environ["QIANFAN_SK"] = ""
chat = QianfanChatEndpoint(
streaming=True,
)
res = chat([HumanMessage(content="讲一个故事")])
print(res.content)对上述代码的具体说明如下所示:
- 设置环境变量:使用os.environ设置了两个环境变量QIANFAN_AK和QIANFAN_SK,这两个环境变量是千帆平台API密钥和安全密钥。
- 创建QianfanChatEndpoint实例:创建了一个QianfanChatEndpoint实例,并将streaming参数设置为True。这表示希望以流式的方式接收模型的输出,这对于长文本生成或实时获取输出很有用。
- 发送消息:使用类HumanMessage创建了一个包含文本“讲一个故事”的消息,并将其发送到聊天模型。
- 接收并打印结果:调用chat实例的聊天模型,并将创建的消息作为参数传递。然后,打印输出响应消息的内容。执行后会输出:
好的,这是一个关于一只名叫小白的狐狸的故事。
小白是一只聪明狡猾的狐狸,他住在一个美丽的森林里。他非常喜欢探险,总是寻找新的挑战和刺激。有一天,小白决定去探索森林深处的一个未知区域。
在森林深处,小白发现了一个巨大的洞穴。他决定进去看看里面有什么。当他走进洞穴时,他发现里面非常黑暗和危险。他遇到了许多陷阱和障碍,但他并不害怕。相反,他利用他的聪明才智和敏捷的身手,成功地克服了所有的困难。
在洞穴的深处,小白发现了一个闪闪发光的宝石。他知道这个宝石非常珍贵,但他并没有打算独占它。相反,他想到了一个聪明的计划,将这个宝石分享给森林里的其他动物们。
于是,小白召集了森林里的其他动物们,告诉他们他在洞穴里发现了一个闪闪发光的宝石。他提议大家一起分享这个宝石的美丽和价值。动物们非常高兴,他们一起分享了这个宝石的力量和喜悦。
从那以后,小白成为了森林里的英雄,他的聪明才智和勇气被所有动物们所敬佩。他们知道,只要有困难和挑战,小白总是能够找到解决问题的方法。
这就是关于小白的故事,一个聪明、勇敢、乐于分享的狐狸的故事。在下面的实例中,使用LangChain框架中的QianfanChatEndpoint创建了一个聊天模型,并通过管道操作将提示模板、聊天模型和输出解析器链接起来,以生成关于特定主题的笑话。
实例7-1:使用提示模板创建一个特定主体的聊天模型(源码路径:codes\7\qian02.py)
实例文件qian02.py的具体实现代码如下所示。
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 创建ChatModel
chat = QianfanChatEndpoint(
model='ERNIE-Bot',
endpoint='completions',
qianfan_ak = "",
qianfan_sk = ""
)
prompt = ChatPromptTemplate.from_template('给我讲一个关于{topic}的笑话吗?要求100字以内。')
output_parser = StrOutputParser()
# 注意:| 符号类似于 unix 管道操作符,它将不同的组件链接在一起,将一个组件的输出作为下一个组件的输入。
chain = prompt | chat | output_parser
r = chain.invoke({'topic': '老虎'})
print(r)上述代码的实现流程如下所示:
- 导入模块:导入LangChain中用于聊天模型、输出解析器和提示模板的模块。
- 设置环境变量:设置了qianfan_ak和qianfan_sk参数,这两个参数应该包含您的千帆平台API密钥和安全密钥。
- 创建QianfanChatEndpoint实例:使用指定的模型'ERNIE-Bot'和端点'completions'创建了一个QianfanChatEndpoint实例,这个实例将用于与千帆平台的语言模型进行交互。
- 创建提示模板:使用ChatPromptTemplate.from_template方法,创建了一个包含一个{topic}变量的提示模板,该模板用于生成关于特定主题的笑话请求。
- 创建输出解析器:创建了一个StrOutputParser实例,用于将聊天模型的输出解析为字符串格式。
- 创建处理链:使用管道操作符“|”,将提示模板、聊天模型和输出解析器链接起来形成了一个处理链,这个处理链定义了从输入到输出的整个流程。
- 执行处理链:通过调用chain.invoke方法并传递一个包含'topic'键和对应值为'老虎'的字典,执行了整个处理,这将生成一个关于“老虎”的笑话请求。
- 打印结果:最后,打印输出QianfanChatEndpoint回复的结果。
本实例执行后将向千帆大模型请求一个关于“老虎”的笑话,并以字符串形式输出结果。执行后会输出:
动物园里老虎皮子皱了,饲养员说:“你明明就是只老虎,不要整天装猫,小心我把你做成皮大衣!”老虎听后求情道:“求求你,别用我做的皮大衣,有狐臭!”3. 信息检索
信息检索在LangChain中扮演着非常重要的角色,尤其是在处理需要大量数据和文档理解的复杂任务时。LangChain通过整合信息检索技术和先进的语言模型,能够构建强大的端到端系统,这些系统能够处理各种复杂的自然语言处理任务,包括但不限于问答、内容推荐、内容生成等。因此,信息检索是LangChain框架的核心组成部分之一。请看下面的实例,演示了使用LangChain框架实现信息检索并生成回答的过程。
实例7-1:使用LangChain框架实现信息检索和生成回答(源码路径:codes\7\qian03.py)
实例文件qian03.py的具体实现代码如下所示。
import os
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import QianfanLLMEndpoint
os.environ["QIANFAN_AK"] = ""
os.environ["QIANFAN_SK"] = ""
# 定义URL
WEB_URL = "https://www.163.com/sports/article/J21HOQVT00058781.html"
# 使用WebBaseLoader加载HTML
loader = WebBaseLoader(WEB_URL)
docs = loader.load()
# 导入千帆向量模型
embeddings = QianfanEmbeddingsEndpoint()
# 导入递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=384, chunk_overlap=0,
separators=["\n\n", "\n", " ", "", "。", ","])
# 导入文本
documents = text_splitter.split_documents(docs)
# 存入向量数据库
vector = Chroma.from_documents(documents, embeddings)
# 创建提示词模板
prompt = ChatPromptTemplate.from_template("""使用下面的语料来回答本模板最末尾的问题。如果你不知道问题的答案,直接回答 "我不知道",禁止随意编造答案。
为了保证答案尽可能简洁,你的回答必须不超过三句话,你的回答中不可以带有星号。
请注意!在每次回答结束之后,你都必须接上 "感谢你的提问" 作为结束语
以下是一对问题和答案的样例:
请问:秦始皇的原名是什么
秦始皇原名嬴政。感谢你的提问。
以下是语料:
<context>
{context}
</context>
Question: {input}""")
# 创建千帆LLM模型
llm = QianfanLLMEndpoint()
# 我们设置一个链,该链接受一个问题和检索到的文档并生成一个答案。
document_chain = create_stuff_documents_chain(llm, prompt)
# 使用检索器动态选择最相关的文档并将其传递。
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 调用这个链了。这将返回一个字典 - 来自 LLM 的响应在键中answer
response = retrieval_chain.invoke({
"input": "北京时间5月12日晚23点30分,阿森纳战胜曼联了吗?"
})
print(response["answer"])上述代码的实现流程如下所示:
(1)导入模块:分别导入LangChain中用于创建检索链、加载文档、嵌入、文本分割、向量存储、提示模板和语言模型的模块。
(2)设置环境变量:设置环境变量QIANFAN_AK和QIANFAN_SK,表示千帆平台的API密钥和安全密钥。
(3)定义URL:定义一个URL变量,该URL网页将被用作信息检索的数据源。
(4)加载HTML文档:使用WebBaseLoader加载定义的URL指向的HTML文档。
(5)文档加载:通过loader.load()加载网页内容到文档中。
(6)文本分割:使用RecursiveCharacterTextSplitter将加载的文档分割成较小的块,以便于处理嵌入操作。
(7)嵌入向量数据库:通过Chroma.from_documents将分割后的文档转换为向量并存储在Chroma数据库中,QianfanEmbeddingsEndpoint用于生成文档的嵌入表示。
(8)创建提示模板:使用ChatPromptTemplate创建了一个提示模板,该模板定义了回答用户问题时要遵循的格式和规则。
(9)创建语言模型实例:创建了一个QianfanLLMEndpoint实例,用于生成自然语言回答。
(10)创建文档链:使用函数create_stuff_documents_chain创建了一个文档链,该链将结合LLM和提示模板来生成回答。
(11)创建检索器:使用向量数据库Chroma创建了一个检索器,能够根据问题检索最相关的文档。
(12)创建检索链:使用函数create_retrieval_chain创建了一个检索链,该链结合了检索器和文档链,用于生成基于检索到的文档的回答。
(13)调用检索链:调用检索链传入一个问题,该检索链将返回一个包含“answer”键的字典,其中包含了LLM生成的回答。
在上述流程中使用了信息检索功能,它首先将网页内容分割并嵌入到向量数据库中,然后通过检索器找到与问题最相关的文档,最后利用LLM生成基于这些文档的回答。这种结合了信息检索和自然语言生成的方法可以提高回答的准确性和相关性。执行后会输出:
阿森纳战胜了曼联。感谢你的提问。4. 聊天检索(Conversational Retrieval)
在LangChain框架中,聊天检索(Conversational Retrieval)是一种结合了自然语言处理(NLP)和信息检索(IR)技术的方法,旨在提高对话系统的性能,尤其是在需要引用大量文档或数据源来回答复杂问题时。请看下面的实例,展示了在LangChain框架中使用聊天检索(Conversational Retrieval)来生成关于一场英超焦点比赛主题的问题和答案的过程。
实例7-1:生成关于一场英超焦点比赛主题的问题和答案(源码路径:codes\7\qian04.py)
实例文件qian04.py的具体实现代码如下所示。
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.chains import ConversationChain, LLMChain, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ["QIANFAN_AK"] = ""
os.environ["QIANFAN_SK"] = ""
# 加载博客文章。
loader = WebBaseLoader("https://www.163.com/sports/article/J21HOQVT00058781.html")
data = loader.load()
# 将其拆分并存储在向量中。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
# 存储在向量中。
vectorstore = Chroma.from_documents(documents=all_splits, embedding=QianfanEmbeddingsEndpoint())
# 像以前一样创建我们的记忆,但是让我们使用 ConversationSummaryMemory
retriever = vectorstore.as_retriever()
chat = QianfanChatEndpoint(model='ERNIE-Bot', temperature=0.8)
memory = ConversationSummaryMemory(
llm=chat, memory_key="chat_history", return_messages=True
)
qa = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever, memory=memory)
res = qa.invoke(
{"question": "请针对北京时间5月12日晚23点30分阿森纳和曼联的这场比赛,帮我出3个题目并给出答案,"}
)
print(res["answer"])上述代码的实现流程如下所示:
- 加载文档:使用WebBaseLoader加载了指定URL的网页内容。
- 文本分割:使用RecursiveCharacterTextSplitter将加载的文档分割成较小的块,以便于处理嵌入操作。
- 创建向量存储:使用Chroma.from_documents将分割后的文档转换为向量表示,并存储在Chroma向量数据库中。QianfanEmbeddingsEndpoint用于生成文档的嵌入表示。
- 创建检索器:使用向量数据库Chroma创建了一个检索器,它能够根据问题检索最相关的文档。
- 创建聊天模型:使用QianfanChatEndpoint创建了一个聊天模型实例,指定了模型ERNIE-Bot和温度参数temperature=0.8。
- 创建内存:使用ConversationSummaryMemory创建了一个对话内存,它将用于存储和回忆对话历史。
- 创建问答链:使用ConversationalRetrievalChain.from_llm创建了一个问答链,它结合了聊天模型、检索器和内存。
- 调用问答链:调用qa.invoke方法,传入一个问题,问答链将生成对应的回答。
- 打印结果:最后,打印输出出问答链返回的answer。
在上述流程中使用了信息检索功能,它首先将网页内容分割并嵌入到向量数据库中,然后通过检索器找到与问题最相关的文档,最后利用聊天模型生成基于这些文档的回答。执行后会输出:
以下是关于北京时间5月12日晚23点30分阿森纳和曼联的比赛的三个题目及其答案:
**题目一:**
在5月12日的英超第37轮比赛中,阿森纳凭借哪位球员的进球以1比0战胜曼联?
**答案:**
在5月12日的英超第37轮比赛中,阿森纳凭借特罗萨德的进球以1比0战胜曼联。特罗萨德在比赛第20分钟接队友哈弗茨的传球,近距离推射破门,为阿森纳取得关键胜利。
**题目二:**
在阿森纳与曼联的这场比赛中,阿森纳的整体表现如何?
**答案:**
在阿森纳与曼联的这场比赛中,阿森纳的整体表现相当出色。球队不仅在防守端稳固,限制了曼联的进攻,同时在进攻端也展现出了强大的实力。阿森纳全队合力完成多次助攻,进攻火力全开,最终凭借特罗萨德的进球取得了胜利。
**题目三:**
曼联在本场比赛中为何未能取胜?
**答案:**
曼联在本场比赛中未能取胜的原因主要有两方面。首先,球队在防守端存在漏洞,未能有效限制阿森纳的进攻,导致特罗萨德取得了进球。其次,曼联在进攻端也显得乏力,未能创造出足够的破门机会。此外,球队中的一些主力球员因伤缺阵,也对比赛结果产生了一定影响。
请注意,这些题目和答案基于提供的信息,但实际情况可能因比赛细节、球员状态等因素而有所不同。如需更准确的信息,建议查阅比赛官方报告或相关新闻报道。
















 5789
5789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











