







1.2.9 自回归移动平均模型(ARMA)
ARMA(自回归移动平均模型)是一种统计模型,用于分析时间序列数据。ARMA(结合了自回归模型(AR)和移动平均模型(MA),可以用来预测未来的时间序列数据。在金融领域中,ARMA模型通常用于分析和预测股票价格、汇率、利率等金融时间序列数据。具体来说,ARMA的作用主要体现在以下几个方面:
- 时间序列分析:ARMA模型可以帮助金融分析师和经济学家分析历史数据的模式和趋势,从而更好地理解市场行为和金融资产的波动。
- 预测:基于历史数据,ARMA模型可以用来预测未来的金融时间序列数据。这对投资者和决策者来说是非常有价值的,因为他们可以根据这些预测做出投资、风险管理和决策。
- 风险管理:通过对金融时间序列数据的建模和预测,ARMA模型可以帮助金融机构和投资者更好地管理风险。例如,它可以用来估计投资组合的价值变动或者利率的波动。
- 策略制定:基于ARMA模型的预测结果,金融从业者可以制定交易策略和投资组合,以获取更好的回报并降低风险。
总的来说,ARMA模型在金融领域中扮演着重要的角色,帮助人们理解市场行为、进行预测和管理风险,从而做出更明智的金融决策。请看下面的实例,通过时间序列分析方法,利用ARMA模型对国际货币基金组织(IMF)提供的锌价格数据进行了预测。首先,对原始数据进行了数据加载、清理和探索性分析,然后通过可视化和统计检验方法对时间序列数据的平稳性和自相关性进行了分析。接着,利用ARMA模型建立了预测模型,并对未来锌价格进行了预测。最终,通过可视化将原始数据与预测结果进行了对比,为交易决策提供了参考依据。
实例1-9:使用ARMA模型预测锌的价格(源码路径:daima/1/forecast-zinc-prices.ipynb)
实例文件forecasting-future-zinc-prices.ipynb的实现流程如下所示。
(1)导入需要的Python库和模块,包括数学计算库(math)、数组处理库(numpy)、数据分析库(pandas)、可视化库(seaborn和matplotlib)、日期时间处理库(datetime)、时间序列分析工具(statsmodels)、时间偏移工具(pandas.tseries.offsets)以及警告过滤器(warnings)。
import math
import numpy as np
import pandas as pd
import seaborn as sns
from datetime import datetime as dt
from IPython.display import display
from statsmodels.tsa.stattools import adfuller, acf, pacf
from statsmodels.tsa.arima.model import ARIMA
from pandas.tseries.offsets import DateOffset
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [15,8]
import warnings
warnings.filterwarnings('ignore')(2)加载数据集文件zinc.csv,并进行了一些基本的预处理工作,包括日期处理和数据摘要。接下来可能会进行更深入的数据探索和分析。
df = pd.read_csv('imf-zinc-price-forecast-dataset/zinc.csv')
variable='Price'
df.loc[:,'Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
original_df = df.copy(deep=True)
display(df.head())
print('\n\033[1mInference:\033[0m The Datset consists of {} features & {} samples.'.format(df.shape[1], df.shape[0]))对上述代码的具体说明如下所示:
- 日期处理:将'Date'列的数据类型转换为日期时间类型(datetime),以便后续的时间序列分析。然后,使用set_index()方法将日期列设置为索引,以便更方便地进行时间序列分析。
- 备份数据集:使用copy()方法创建了一个原始数据集的深拷贝,存储在original_df中,以便在需要时进行比较或恢复原始数据。
- 显示数据前几行:使用display()函数显示了数据集中的前几行信息,以便查看数据的结构和内容。
- 打印数据集信息:打印输出数据集的特征数(列数)和样本数(行数)的信息。
执行后会输出:
Date Price
1980-01-01 773.82
1980-02-01 868.62
1980-03-01 740.75
1980-04-01 707.68
1980-05-01 701.07(3)绘制数据集中的所有变量(列)随时间的变化趋势,使用DataFrame中的方法plot()绘制了数据集中所有变量(列)随时间变化的趋势图。由于之前将日期列设置为索引,因此在绘制时,时间将自动作为X轴。
df.plot()
plt.grid()
plt.show()通过上述代码,可以快速地观察到数据集中各个变量随时间的变化情况,以便更好地理解数据的特征和趋势。绘制的随时间变化的趋势图如图1-7所示。
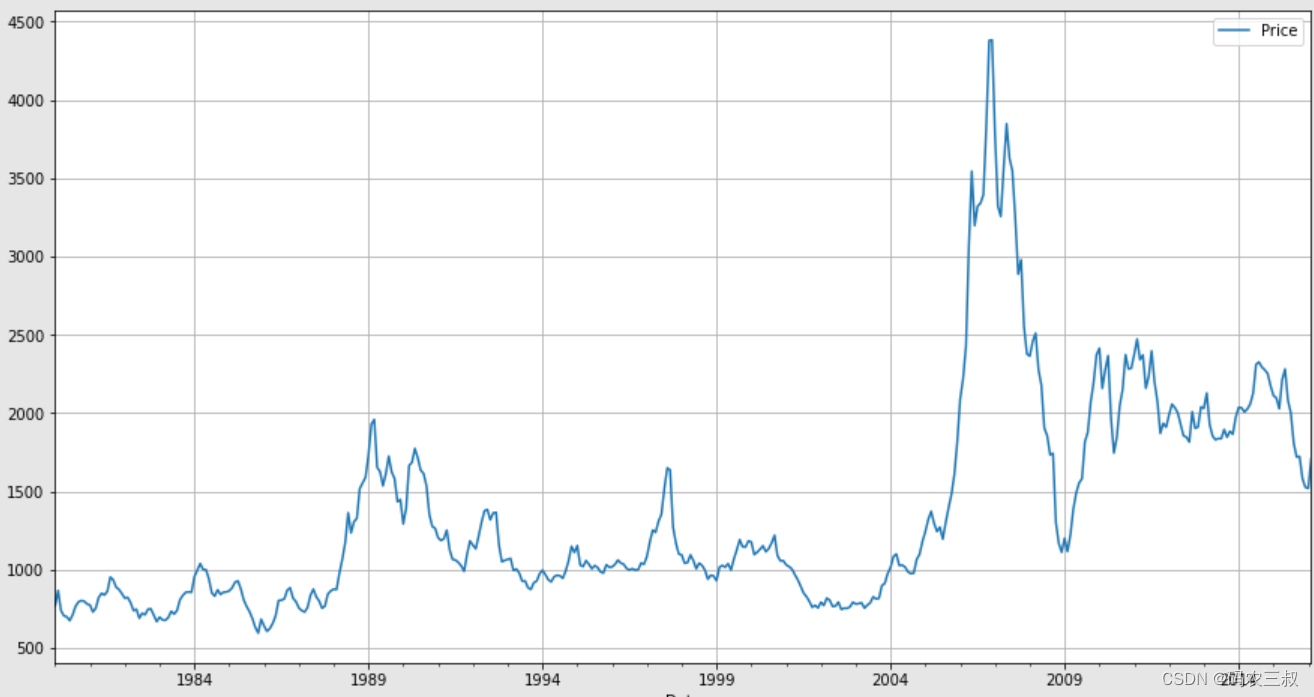
图1-7 随时间变化的趋势图
(4)函数Staionarity_Check(ts)执行了一系列平稳性检验工作,并可视化了时间序列数据的移动平均和移动标准差。具体说明如下所示:
- 可视化移动平均和移动标准差:首先,函数绘制了原始时间序列数据以及其对应的滚动均值和滚动标准差曲线。这些曲线有助于观察数据的整体趋势和波动性。
- ADF检验:函数使用了ADF检验(Augmented Dickey-Fuller Test)来检验时间序列数据的平稳性,ADF检验的结果包括T统计量(T Statistic)、P值(P-Value)、使用的滞后阶数(#Lags Used)和观察数量(#Observations Used),以及对应的临界值(Critical value)。
- 打印输出检验结果:打印了ADF检验的结果,包括统计量、P值和临界值等信息。
def Staionarity_Check(ts):
plt.plot(ts, label='Original')
plt.plot(ts.rolling(window=52, center=False).mean(), label='Rolling Mean')
plt.plot(ts.rolling(window=52, center=False).std(), label='Rolling Std')
plt.grid()
plt.legend()
plt.show()
adf = adfuller(ts, autolag='AIC')
padf = pd.Series(adf[:4], index=['T Statistic','P-Value','#Lags Used','#Observations Used'])
for k,v in adf[4].items():
padf['Critical value {}'.format(k)]=v
print(padf)
Staionarity_Check(df[variable])(6)通过函数Staionarity_Check(ts),可以很方便地检验时间序列数据的平稳性,并根据ADF检验的结果来判断是否需要进行进一步的平稳化处理。如果需要,可以使用差分技术或其他方法来平稳化数据。执行后会打印输出如下所示的检验结果,并绘制时间序列数据的移动平均和移动标准差的可视化图如图1-8所示。
T Statistic -3.139601
P-Value 0.023758
#Lags Used 7.000000
#Observations Used 426.000000
Critical value 1% -3.445794
Critical value 5% -2.868349
Critical value 10% -2.570397
dtype: float64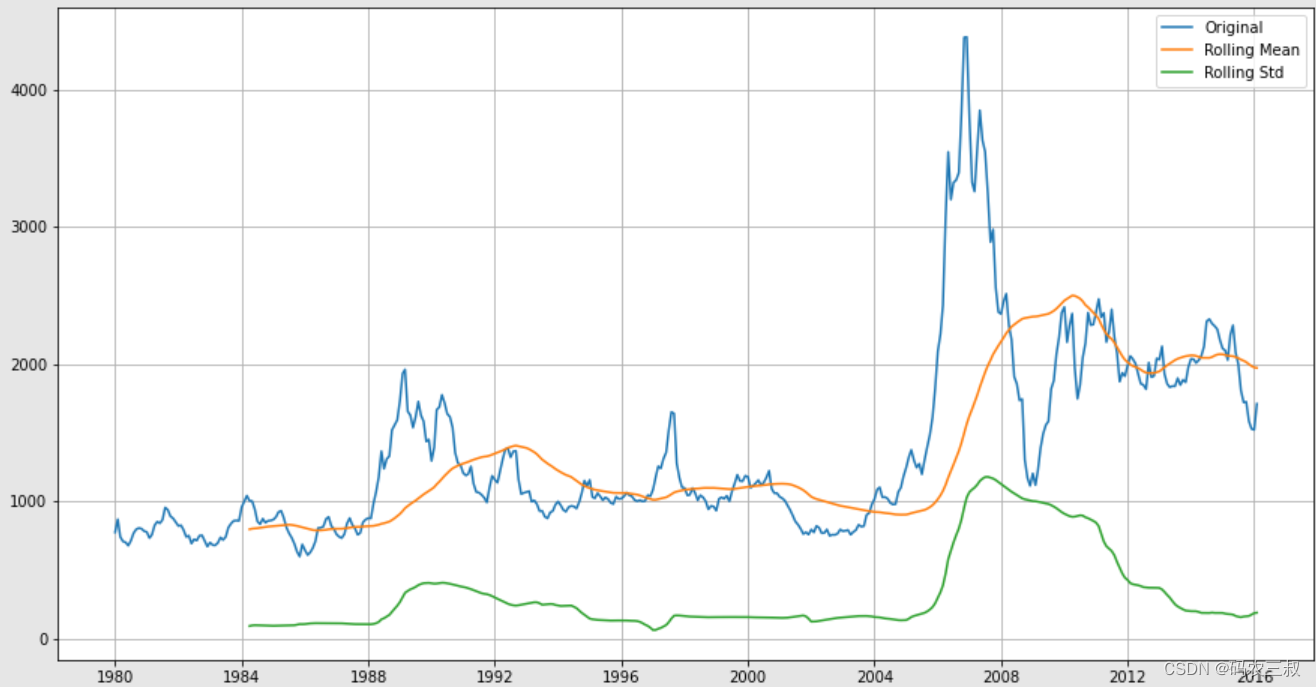
图1-8 时间序列数据的移动平均和移动标准差的可视化图
(7)下面这段代码首先对时间序列数据进行对数变换操作,然后计算了对数变换后数据的滚动平均值,并将对数变换后的数据减去了滚动平均值,得到了一个新的时间序列数据。接着,对新的时间序列数据进行了平稳性检验。
tsl = np.log(df)
ma = tsl.rolling(window=12).mean()
ms = tsl.rolling(window=12).std()
plt.plot(ma, c='r')#, center=False)
plt.plot(ms, c='g')
plt.plot(tsl)
plt.grid()
plt.show()执行后会绘制原始时间序列数据、滚动均值和滚动标准差的曲线图,如图1-9所示。并进行ADF检验操作,打印输出如下所示的检验结果,包括T统计量、P值、使用的滞后阶数和观察数量,以及对应的临界值。
T Statistic -5.898484e+00
P-Value 2.814411e-07
#Lags Used 4.000000e+00
#Observations Used 4.180000e+02
Critical value 1% -3.446091e+00
Critical value 5% -2.868479e+00
Critical value 10% -2.570466e+00
dtype: float64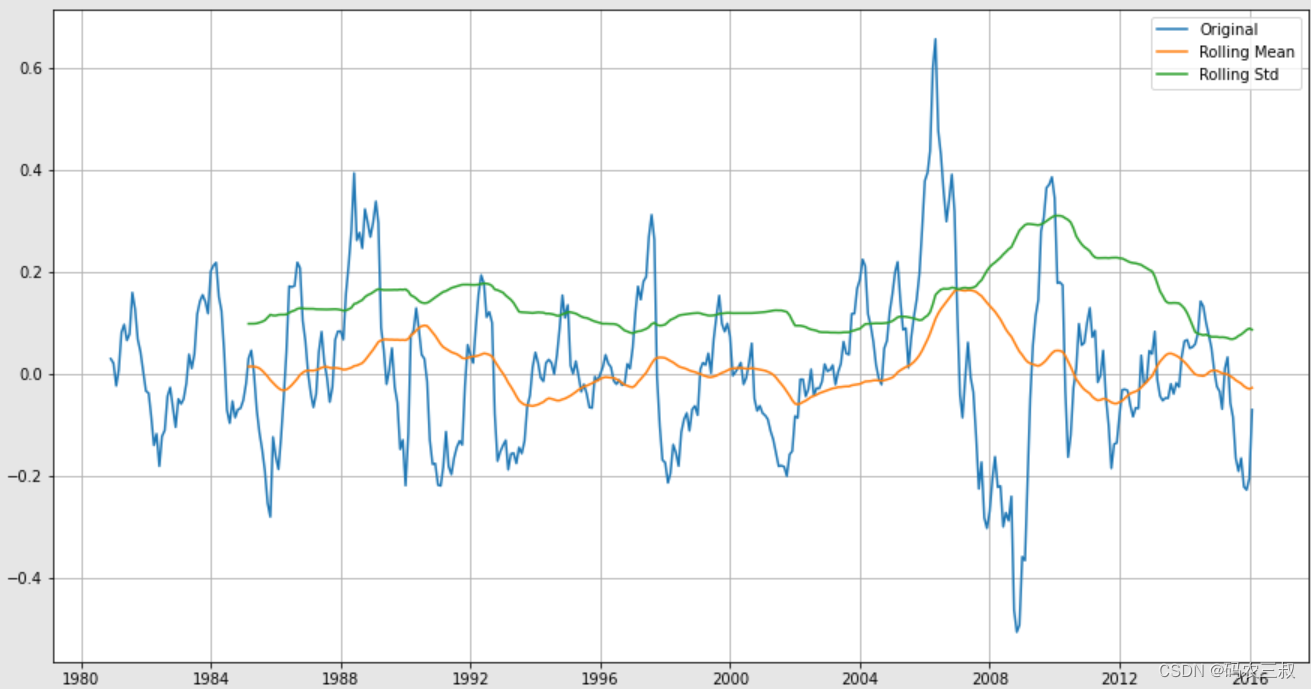
图1-9 原始时间序列数据、滚动均值和滚动标准差的曲线图
(8)绘制新时间序列数据的自相关函数(ACF)图,并在图上添加了95%的置信区间边界。具体说明如下所示:
- 绘制ACF图:使用plt.plot()函数绘制了新时间序列数据的ACF图。ACF图显示了时间序列数据在不同滞后阶数下的自相关系数,即与自身之前滞后的数据之间的相关程度。
- 添加置信区间边界:使用plt.axhline()函数添加了95%置信区间的上下边界。这些边界的位置是根据样本数量和95%置信水平计算得出的,一般为正负1.96倍标准误差的值。
- 添加标题和网格:使用plt.title()函数添加了图的标题,标题为“Auto Correlation Fuction”。使用plt.grid()函数添加了网格线,使图形更易于阅读。
plt.plot(np.arange(acf(tslma, nlags=10,fft=True).shape[0]),acf(tslma, nlags=10, fft=True))
plt.axhline(y=0, linestyle='--', c='gray')
plt.axhline(y=-7.96/np.sqrt(len(tslma)), linestyle='--',c='gray')
plt.axhline(y=7.96/np.sqrt(len(tslma)), linestyle='--',c='gray')
plt.title('Auto Correlation Fuction')
plt.grid()
plt.show()执行效果如图1-9所示,通过这个图可以观察到时间序列数据在不同滞后阶数下的自相关性,并判断是否存在显著的自相关关系。如果自相关系数超出了置信区间边界,则意味着数据具有自相关性。
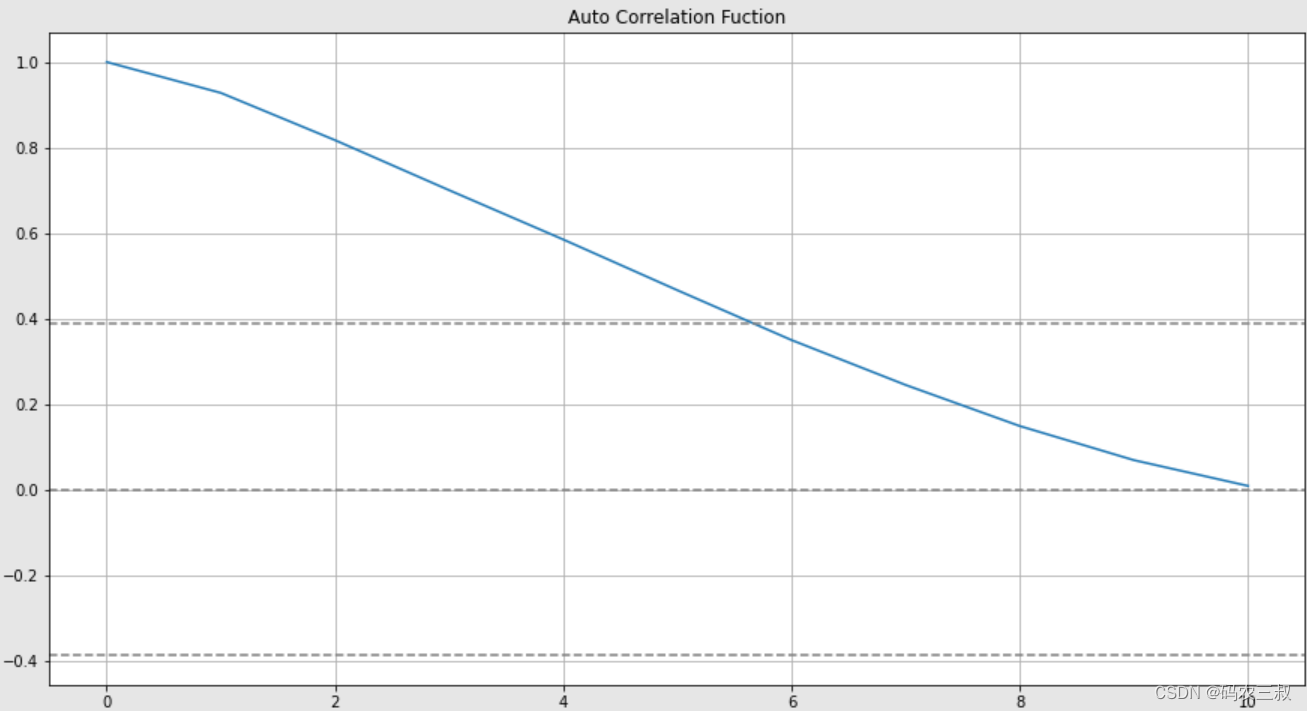
图1-9 新时间序列数据的自相关函数(ACF)图
(9)绘制新时间序列数据的偏自相关函数(PACF)图,并在图上添加了95%的置信区间边界。具体说明如下所示:
- 绘制PACF图:使用plt.plot()函数绘制了新时间序列数据的PACF图,PACF图显示了时间序列数据在不同滞后阶数下,当控制了之前滞后的数据时,与自身之前滞后的数据之间的相关程度。
- 添加置信区间边界:使用plt.axhline()函数添加了95%置信区间的上下边界,这些边界的位置是根据样本数量和95%置信水平计算得出的,一般为正负1.96倍标准误差的值。
- 添加标题和网格:使用plt.title()函数添加了图的标题,标题为“Partial Auto Correlation Fuction”。使用plt.grid()函数添加了网格线,使图形更易于阅读。
plt.plot(np.arange(pacf(tslma, nlags=10).shape[0]),pacf(tslma, nlags=10))
plt.axhline(y=0, linestyle='--', c='gray')
plt.axhline(y=-7.96/np.sqrt(len(tslma)), linestyle='--',c='gray')
plt.axhline(y=7.96/np.sqrt(len(tslma)), linestyle='--',c='gray')
plt.title('Partial Auto Correlation Fuction')
plt.grid()
plt.show()执行效果如图1-10所示,通过这个图可以观察到时间序列数据在不同滞后阶数下的偏自相关性,并判断是否存在显著的偏自相关关系。如果偏自相关系数超出了置信区间边界,可能意味着数据具有偏自相关性。
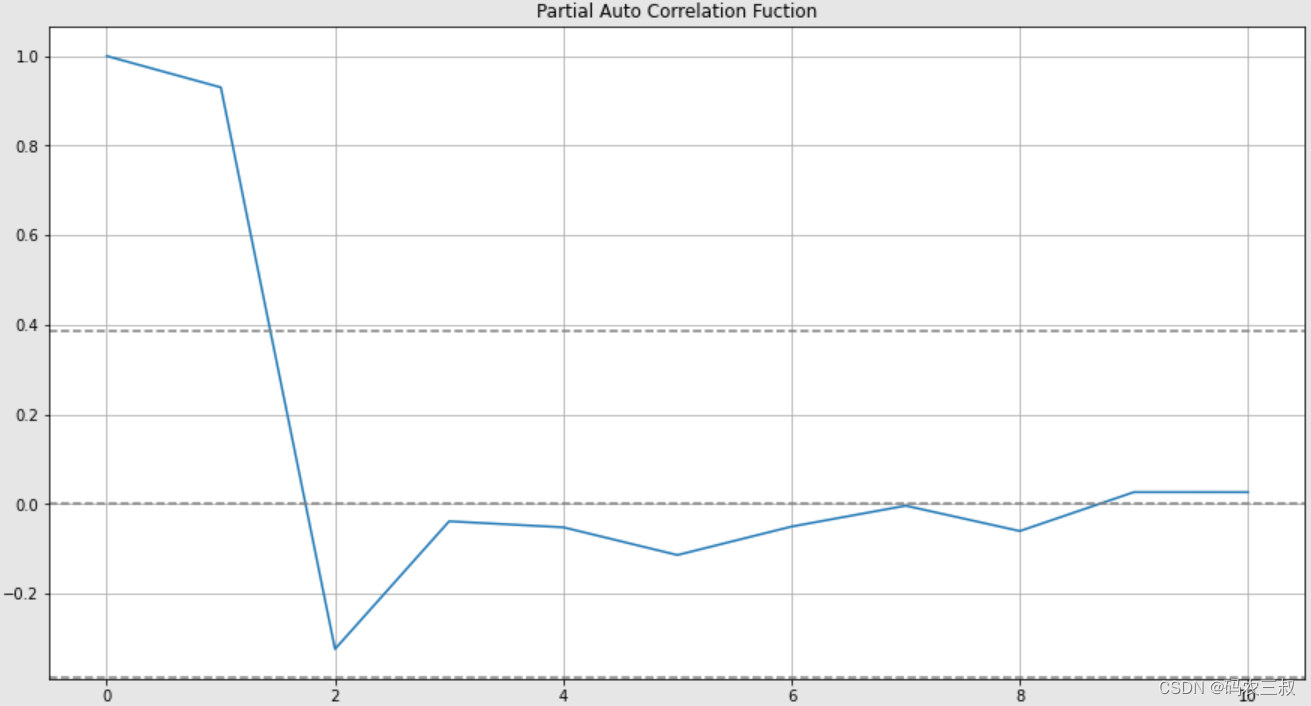
图1-10 新时间序列数据的偏自相关函数(PACF)图
(10)创建一个ARIMA模型,并对模型进行了拟合。
Arima = ARIMA(tslma, order=(2,5,1))
Ar = Arima.fit()
# plt.plot(tslma, label=['Original'])
# plt.plot(Ar.fittedvalues,c='r', label=['Forecast'])
# plt.legend()
# plt.grid()
Ar.summary()对上述代码的具体说明如下所示:
- 建立ARIMA模型:使用ARIMA()函数创建了一个ARIMA模型。在order参数中,指定了ARIMA模型的阶数,包括p、d、q,分别表示自回归阶数、差分阶数和移动平均阶数。在这里,指定了p=2(自回归阶数)、d=5(差分阶数)、q=1(移动平均阶数)。
- 模型拟合:使用fit()方法对ARIMA模型进行拟合,得到了拟合后的模型Ar。
- 输出模型概要信息:调用了模型的summary()方法,输出了拟合后的ARIMA模型的概要信息,包括模型参数估计值、标准误差、t统计量、P值等。
通过上述代码创建了一个ARIMA模型,并对时间序列数据进行了拟合。
(11)如果想建立ARMA模型,可以简单地指定差分阶数d为0。这样就相当于将ARIMA模型中的差分部分去除,从而变成了ARMA模型。
from statsmodels.tsa.arima.model import ARIMA
# 建立ARMA模型
Arma = ARIMA(tslma, order=(2, 0, 1))
Arma_fit = Arma.fit()
# 输出模型概要信息
print(Arma_fit.summary())上述代码与之前的代码基本相同,只是在建立ARIMA模型时将差分阶数d设置为0,这样就得到了一个ARMA模型。然后调用了模型的summary()方法,输出了拟合后的ARMA模型的概要信息。执行后会输出:
Dep. Variable: Price No. Observations: 423
Model: ARIMA(2, 5, 1) Log Likelihood 267.664
Date: Sat, 01 Jan 2022 AIC -527.328
Time: 07:41:42 BIC -511.186
Sample: 12-01-1980 HQIC -520.947
- 02-01-2016
Covariance Type: opg
coef std err z P>|z| [0.025 0.975]
ar.L1 -1.0827 0.042 -25.852 0.000 -1.165 -1.001
ar.L2 -0.5279 0.039 -13.607 0.000 -0.604 -0.452
ma.L1 -0.9972 0.168 -5.933 0.000 -1.327 -0.668
sigma2 0.0159 0.003 5.611 0.000 0.010 0.021
Ljung-Box (L1) (Q): 25.69 Jarque-Bera (JB): 23.63
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 1.24 Skew: 0.12
Prob(H) (two-sided): 0.21 Kurtosis: 4.14(12)在下面的代码中准备了未来24个月的日期,并使用已拟合的ARMA模型进行了预测。然后,将原始数据和预测结果绘制在同一张图上。
future_dates=[df.index[-1]+ DateOffset(months=x)for x in range(0,24)]
future_datest_df=pd.DataFrame(index=future_dates[1:],columns=df.columns)
future_datest_df.tail()
future_df=pd.concat([df,future_datest_df])
future_df['a'] = Ar.predict(start =350, end = 420, dynamic= False)
plt.plot(future_df[variable][:-95], label=['Original'])
plt.plot(np.exp(future_df['a']+(1.08*ma.mean()[0])), label=['Forecast'])
plt.grid()
plt.legend()
plt.show()对上述代码的具体说明如下所示:
- 准备未来日期:使用类DateOffset生成了未来24个月的日期,并创建了一个空的DataFrame future_datest_df来存储这些日期。
- 合并数据:使用concat()函数将原始数据集df和未来日期数据集future_datest_df合并为一个新的DataFrame future_df,以便进行预测。
- 进行预测:使用已拟合的ARMA模型的predict()方法对未来数据进行了预测,其中参数start和参数end指定了预测的起始和结束索引位置。设置dynamic=False表示预测时不使用动态预测。
- 绘制预测结果:使用plt.plot()函数将原始数据和预测结果绘制在同一张图上。在这里,预测结果经过了对数变换的逆操作,以还原成原始数据的形式,并加上了移动平均值的修正。
通过上述代码得到了未来24个月的预测结果,并将预测结果与原始数据绘制在了同一张图上,以便进行可视化比较。如图1-11所示。
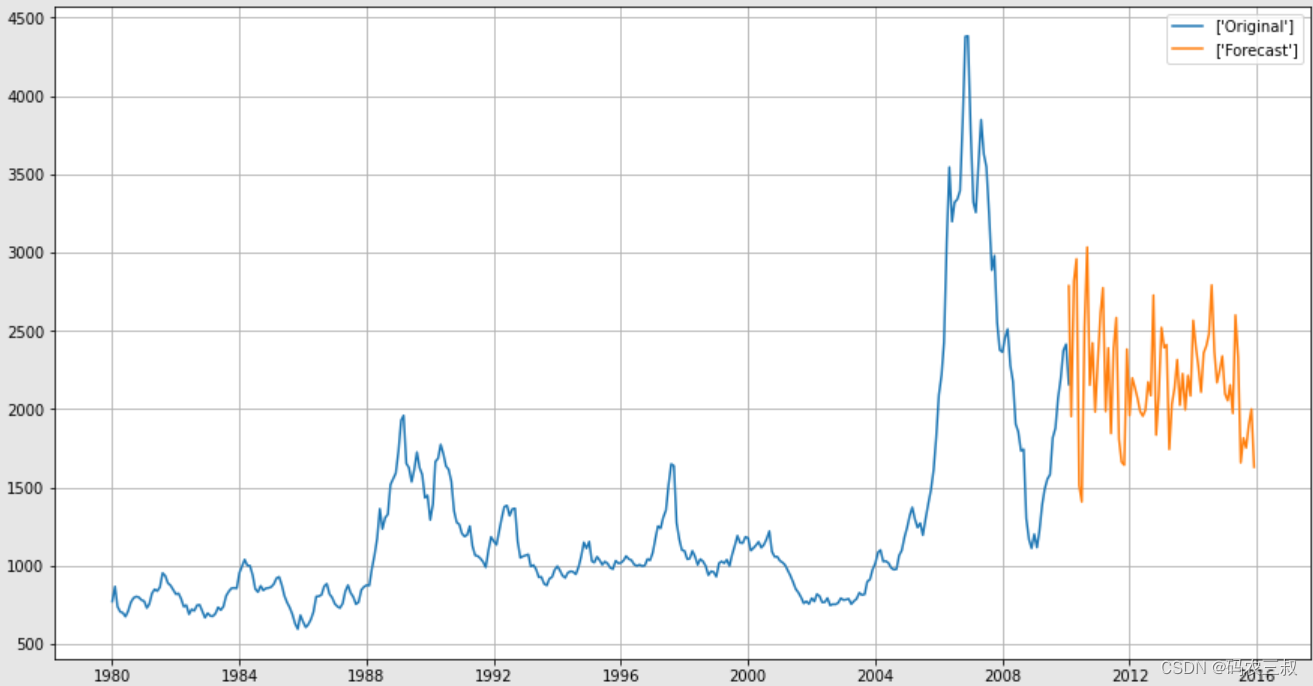
图1-11 未来24个月的预测结果
注意:在本书前面介绍的这些模型之间有一些重叠和关联,例如,ARMA模型可以被看作是AR和MA模型的结合,而GARCH模型可以用于对ARMA模型中的残差项的波动性进行建模。在金融领域中,通常会根据具体的数据特征和分析目的选择适当的模型或模型组合来进行分析和预测。
















 6142
6142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











