






人工智能的研究受到了国家战略层面和个人研究层面的高度重视。如何了解人工智能的前沿方向?对该领域顶级期刊论文的分析是重要途径之一。本文将对人工智能领域顶级期刊《IEEE模式分析和机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence,简称TPAMI)2025年第3期的论文进行研究,为读者提供高频词汇分析、研究热点分析以及优秀论文推荐,希望能帮助读者了解人工智能的前沿热点。
本文作者为王一鸣,审校为龚裕涛。
一、期刊介绍
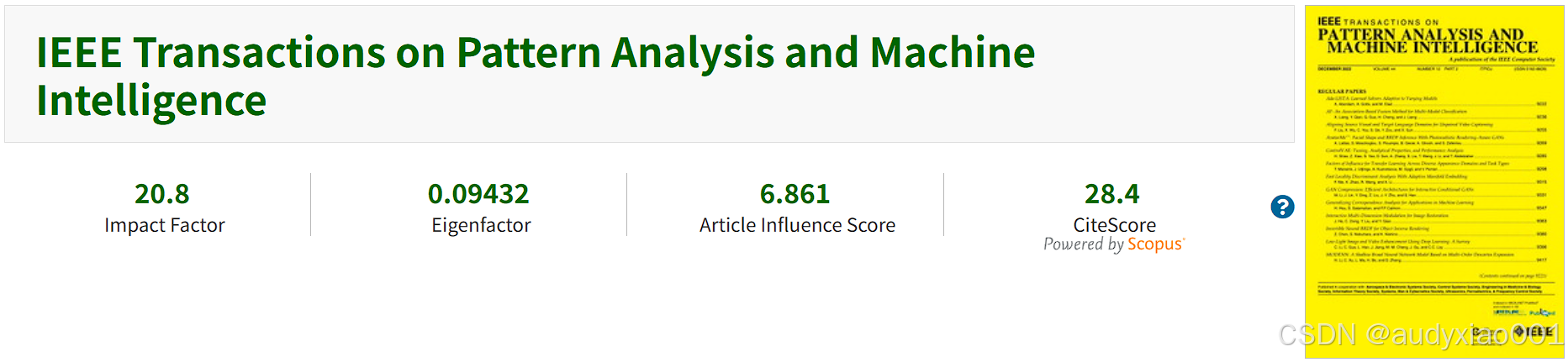
TPAMI是由IEEE Computer Society出版的月刊,创刊于1979年,是人工智能领域的顶级期刊。该期刊在中国计算机学会认定的人工智能领域四个A类期刊中排名第一,同时常年处于中科院1区。表1统计了2019-2023年TPAMI的发文量与影响因子。可以看出,近年来TPAMI的发文量正在不断提高,虽然其影响因子有小幅的波动,但整体仍然保持了高水准。
表1 2019-2023年TPAMI发文量及影响因子统计
| 年度 | 年发文量 | 影响因子(IF) | 中科院大类分区 |
| 2023 | 1022 | 20.8 | 1区 |
| 2022 | 677 | 23.6 | 1区 |
| 2021 | 312 | 24.3 | 1区 |
| 2020 | 221 | 16.4 | 1区 |
| 2019 | 215 | 17.9 | 1区 |
该期刊发表关于计算机视觉和图像理解的所有传统领域、模式分析和识别的所有传统领域以及机器智能的特定领域的文章,特别强调用于模式分析的机器学习。此外,期刊还涵盖了视觉搜索、文档和手写分析、医学图像分析、视频和图像序列分析、基于内容的图像和视频检索、人脸和手势识别以及相关专业硬件和/或软件架构等领域。
期刊官网:https://ieeexplore.ieee.org/xpl/tocresult.jsp?isnumber=10873290&punumber=34
二、热点分析
本期TPAMI总共收录了57篇论文,从这些论文中得到的高频词汇统计表格及词云图,分别如表2和图1所示。
表2 录用论文标题中的高频词汇统计
| 高频词 | 翻译 | 词频 |
| Model | 模型 | 10 |
| Learning | 学习 | 10 |
| Image | 图像 | 9 |
| Representation | 表征 | 6 |
| Graph | 图 | 4 |
| Detection | 检测 | 3 |
| Generation | 生成 | 3 |
| Network | 网络 | 3 |
| Robust | 鲁棒性 | 2 |
| Multimodal | 多模态 | 2 |
| Fine-Grained | 细粒度 | 2 |
| Adaptation | 适应 | 2 |
| 3D | 三维 | 2 |

图1 根据高频词绘制的词云图
由表2的高频词汇统计以及图1的可视化词云图中可以看出,本期TPAMI中有着大量与模型(Model)、学习(Learning)方法、图像(Image)相关的内容。这三个关键词将在后续的热门研究领域分析中具体介绍。此外,与表征(Representation)有关的表征学习(Representation Learning)、3D表征(3D Representation)等领域也是比较热门的领域。在网络(Network)方面,一些新颖的网络需要引起注意,例如,尺度传播网络(Scale Propagation Network)、融合三流网络(Confluent Triple-Flow Network),用于复值虹膜识别的网络(Complex-Valued Iris Recognition Network)。根据论文高频词,本文总结了三个热门方向:扩散模型、自/半/无监督学习、复杂视觉任务并进行具体分析。
1.扩散模型
生成模型旨在从数据分布中学习并生成新的样本,其核心任务是建模复杂的数据分布(如图像、文本)。近年来,扩散模型(Diffusion Models)因高质量生成效果和训练稳定性,成为生成建模领域的主流技术。相比生成对抗网络(GAN)和变分自编码器(VAE),扩散模型在生成细节和多样性上表现更优。
本期涉及扩散模型的研究主要集中在图像生成(Image Generation),文本到图像(Text-to-Image)和分割模型(Segment Model)三个领域。
表3 扩散模型论文列表
| 题目 | 核心内容 |
| MetaEarth: A Generative Foundation Model for Global-Scale Remote Sensing Image Generation | 基于扩散模型的全球尺度遥感图像生成模型 |
| RenAIssance: A Survey Into AI Text-to-Image Generation in the Era of Large Model | 大模型时代人工智能文本到图像生成综述 |
| DiffAct++: Diffusion Action Segmentation | 基于扩散模型的动作分割框架 |
| DiffI2I: Efficient Diffusion Model for Image-to-Image Translation | 基于扩散模型的图片到图片(Image-to-Image, I2I)任务框架。 |
| Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation | 基于深度视觉模型SAM的分层文本分割模型 |
| PDPP: Projected Diffusion for Procedure Planning in Instructional Videos | 基于扩散的对整个动作序列分布进行建模的框架以解决程序规划问题 |
2.自/半/无监督学习
与学习(Learning)方法相关的论文中,以自监督学习(Self-Supervised Learning)、半监督学习(Semi-Supervised Learning)和无监督学习(Unsupervised Learning)为主流。自监督学习通过算法设计代理任务,从无标签数据中学习表征;无监督学习则直接挖掘数据内在结构(如聚类、密度估计)。半监督学习是一种结合少量标注数据和大量未标注数据的机器学习范式,旨在通过利用未标注数据中的潜在结构信息,提升模型的泛化能力。这三种学习方法多与其他领域进行交叉融合,从而满足不同场景不同领域下的不同需求。
此外,持续学习(Continual Learning)、深度学习(Deep Learning)、图学习(Graph Learning)在本期TPAMI中也出现了一定次数,值得关注。
表4 自/半/无监督学习论文列表
| 题目 | 核心内容 |
| Self-Supervised Anomaly Detection With Neural Transformations | 基于神经变换的自监督异常检测方法 |
| Unsupervised Global and Local Homography Estimation With Coplanarity-Aware GAN | 基于无监督GAN网络的全局和局部单应性估计框架 |
| Fast Semi-Supervised Learning on Large Graphs: An Improved Green-Function Method | 基于改进的格林函数方法的大型图半监督学习框架 |
| Continual Learning: Forget-Free Winning Subnetworks for Video Representations | 基于傅里叶亚神经算子无遗忘持续学习框架 |
| Adaptive Graph Learning With Semantic Promotability for Domain Adaptation | 一种多语义粒度和面向目标样本的具有语义可推广性的自适应图学习 |
| Self-Supervised Learning for Real-World Super-Resolution From Dual and Multiple Zoomed Observations | 一种基于双重和多重变焦的真实世界图像超分辨率的自监督学习 |
3.复杂视觉任务
计算机视觉专注于从图像/视频中提取语义信息(如分类、检测、分割)。面对日益复杂的视觉任务,多模态(Multimodal)技术整合视觉、文本、语音等多源数据,提升模型对复杂场景的理解能力。此外,与3D相关的复杂视觉任务也是当前的研究热点之一。具体而言,与复杂视觉任务相关的论文包括3D场景理解(3D Scene),目标检测(Object Detection)、视觉-语言模型(Vision-Language Model)、图像融合(Image Fusion)、图像分类(Image Classification)等热门方向。
表5 复杂视觉任务论文列表
| 题目 | 核心内容 |
| Anchor3DLane++: 3D Lane Detection via Sample-Adaptive Sparse 3D Anchor Regression | 基于样本自适应稀疏三维锚点回归的三维车道检测 |
| Multi-Scale Part-Based Feature Representation for 3D Domain Generalization and Adaptation | 基于多尺度部分的特征表示,用于点云域的泛化和自适应 |
| NAS-PED: Neural Architecture Search for Pedestrian Detection | 专门为行人检测设计的将CNN和ViTs混合的神经结构搜索框架 |
| Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection | 基于分治方法的融合三流网络目标检测 |
| LVLM-EHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models | 构建了LVLM评估中心,对公开可用的大型视觉-语言模型进行综合评估 |
| Fully-Connected Transformer for Multi-Source Image Fusion | 采用多线性代数来驱动的全连接Transformer多源图像融合 |
| Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification | 针对细粒度的少镜头分类任务的通道注意方法 |
| JARVIS-1: Open-World Multi-Task Agents With Memory-Augmented Multimodal Language Models | 可以感知多模态输入,生成复杂的计划,并执行具体化控制的开放世界多任务代理 |
| Scale Propagation Network for Generalizable Depth Completion | 基于尺度传播网络的深度补全 |
| Insights on ‘Complex-Valued Iris Recognition Network’ | 对复值虹膜识别网络的讨论 |
三、总结与展望
通过对TPAMI 2025年3月刊论文的梳理,可以清晰看到以下趋势:
1.扩散模型主导生成任务:在遥感图像生成、文本到图像生成、动作分割和图像转换等任务中,扩散模型因生成质量和可控性成为主流框架,展现出了极高的灵活度和质量优势。
2.多模态与三维理解成为核心竞争力:一些复杂视觉任务例如多源图像融合、少镜头分类任务等,多模态方法正成为主流。而在 3D车道检测、3D形状分类等三维视觉任务中,三维数据精细化建模与理解是一个有效的方法。
3.一些新颖的方法和框架被提出:尺度传播网络(Scale Propagation Network)正成为生成任务的另一种选择,适用于深度补全、多分辨率生成任务、气候变化模拟等任务。融合三流网络(Confluent Triple-Flow Network)作为一种新兴的框架被提出,可用于多传感器融合、多模态模型构建等领域。这些新颖的方法展现了人工智能领域方法创新的活跃态势。
未来,围绕扩散模型、自适应学习、多模态融合、三维视觉等领域,人工智能将进入更大规模、更细粒度、更智能化的新阶段
上述的热点分析与最新趋势介绍是根据TPAMI 2025年第3期的论文进行归纳与分析得到的,希望本篇内容能为读者带来一定的帮助与参考。

















 3836
3836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









