






基于自监督学习的单目深度+位姿估计的经典框架,成为最基本的自监督学习的范式。后来提出的许多自监督方法都以此为基础。
提出了一个无监督的学习框架,用于任务的单眼深度和摄像机运动估计的非结构化视频序列。我们使用端到端学习方法,以视图合成作为监督信号。与之前的工作相比,我们的方法是完全无监督的,只需要单眼视频序列进行训练。我们的方法使用单视图深度和多视图姿态网络,基于使用计算 的深度和姿态扭曲附近的视图到目标的损失。因此,网络在训练过程中被损失耦合,但可以在测试时独立应用 。对KITTI数据集的经验评估证明了我们的方法的有效性 :
1)单眼深度与使用地面真实姿态或深度进行训练的监 督方法进行比较;
2)在类似的输入设置下,姿态估计的 性能优于已建立的SLAM系统。
人类在估计自身运动和场景的三维结构方面有出色的能力;但是几何计算机视觉的研究,在非刚性的、闭塞的或者缺乏纹理的真实场景上无法创造类似于人类能力的模型。
为什么人类能表现的如此出色呢?
一种假设是,我们通过过去的视觉经验对世界形成了丰富的、结构化的理解,这主要包括四处移动和观察大量场景,并对我们的观察形成一致的模型。
在数百万次这样的观察中,我们认识着世界的规律——道路是平的,建筑物是直的,汽车是在道路上行驶的等等。我们可以将这些知识应用到感知一个新场景时,甚至是从一个单目图像中。
我们通过训练图像序列的模型来模拟这种方法,预测可能的相机运动和场景结构来解释看到的图像序列。
我们采用端到端方法,允许模型直接从输入像素映射到 自我运动场景结构。

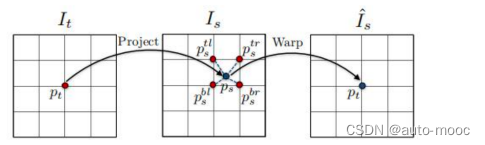
只有当几何视图合成系统对于场景几何和相机位姿的估计符合真实情景,才能稳定地有好的表现。
因此,我们的目标是将整个视图合成的过程表述为卷积神经网络的推理过程。
通过训练大规模视频数据的网络来完成视图合成的“元”任务,迫使网络学习深度和相机位姿估计的中间任务,以提出对视觉感知真实世界的一致性解释。
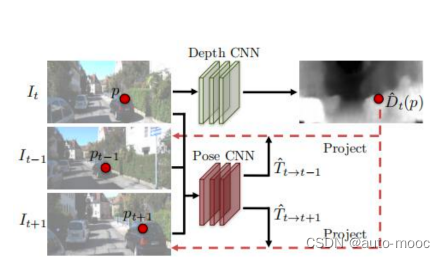
在此,我们提出了一个框架,以联合训练一个单视图深度 CNN和一个摄像机姿态估计CNN从未标记的视频序列。尽管深度模型和姿态估计模型经过了联合训练但它们可以在测试时间推断中独立使用。我们的模型的训练例子由移动摄像机捕捉的场景的短图像序列。而我们的训练过程在某种程度上对场景是稳健的。
框架可以应用于没有姿态信息的标准视频。此外,它还预测了姿态作为学习框架的一部分。展示了我们的深度和姿态估计的学习通道。

我们提出了一个端到端学习通道,利用视图合成任务监督单视角深度和相机姿态估计。该系统在未标记的视频上进行训练,但表现与需要地面真实深度或姿势进行训练的方法相当。
尽管该方法在基准评价方面表现良好,但还远远不能解决三维场景结构推理的无监督学习问题。
一些重大问题和挑战如下:
(1)我们的模型没有显式地估计场景中的动态和遮挡(隐式地被可解释性掩码考虑在内),而这两个问题都是3D场景理解的重要因素。通过运动分割直接建模动态场景可能是一种方案。
(2)我们的方法假定相机内参是给定的,这就限制了实际情况中未知相机的视频序列估计(作者说他们计划在未来工作中解决这个问题)。
(3)深度图是真实3D场景的简化表示。扩展此模型去学习3D体积表示(full 3D volumetric representations)是有趣的方向。
未来工作的一个有趣方向是更深入地研究我们的自监督系统学习到的表示。特别是位姿估计网络倾向于从图像相关性来学习相机位姿,而深度估计网络可能识别场景和物体的共同特征。或者将我们的工作重新用于对象检测或者语义分割等任务。
原论文学习,可以私信D主















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









