







有朋友问我,如何有效学习一个新技术。笔者这么多年的经验是:1)了解国内外产业应用和标准法规现状,先建立宏观知识图谱及技术系统框架;2)根据系统框架逐块进行深入研究(横向、纵向),穿插行业内主流厂商对应模块技术方案;3)系统研究行业内TOP厂商完整解决方案;4)针对你选择的重点方向进阶研究。因此笔者建立的自动驾驶专题介绍也会按照这个思路搭建技术体系(发布内容顺序不一定能严格遵守该路线,但会力求不断更新最终能按照该思路完成自动驾驶专栏搭建)。
本文及之后几篇系列文章,旨在针对自动驾驶行业领军企业特斯拉的技术方案进行深入解读和分析(资料来源:特斯拉官网,AI Day 2021,AI Day 2022,Inventor Day 2023)。特斯拉自动驾驶技术的核心是三个点:算法、数据和硬件,以下笔者将分别介绍AI Day 2021,AI Day 2022,Inventor Day 2023三次分享的内容,然后综合梳理出目前特斯拉自动驾驶解决方案。本文主要介绍特斯拉AI Day 2021的算法部分内容。
1 感知算法系统框架
1)系统框架
 (摄像头raw data 1280*960,12bit (HDR) @36Hz)
(摄像头raw data 1280*960,12bit (HDR) @36Hz)
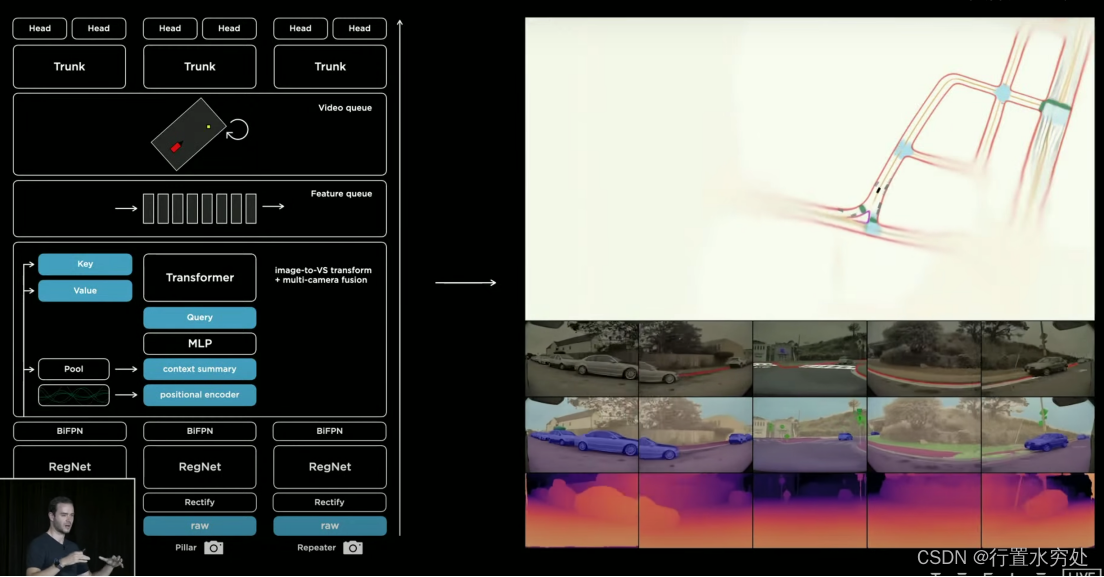
特斯拉的感知算法系统,取名为HydraNet(九头蛇),九头非常形象的表示了感知系统整个算法模型是一个多头任务学习神经网络架构,旨在处理自动驾驶汽车所需的多种感知任务;颈部形象的展示出整个感知模型共享特征提取部分,从而提高计算效率和感知精度。
从上图可以看到,整个算法模型的输入是来自8个摄像头提供的raw data,通过神经网络将图像实时处理转换成4D向量空间(包括自动驾驶所需一切物体的3D表示,再加上时间维度),包括线、边、道路、交通标志、行人、车辆的位置、方向、速度、角速度等。提取到的特征序列进入到特定任务头进行处理,例如使用一阶YOLO进行目标检测等,针对性完成更多任务处理。
2)模型优点
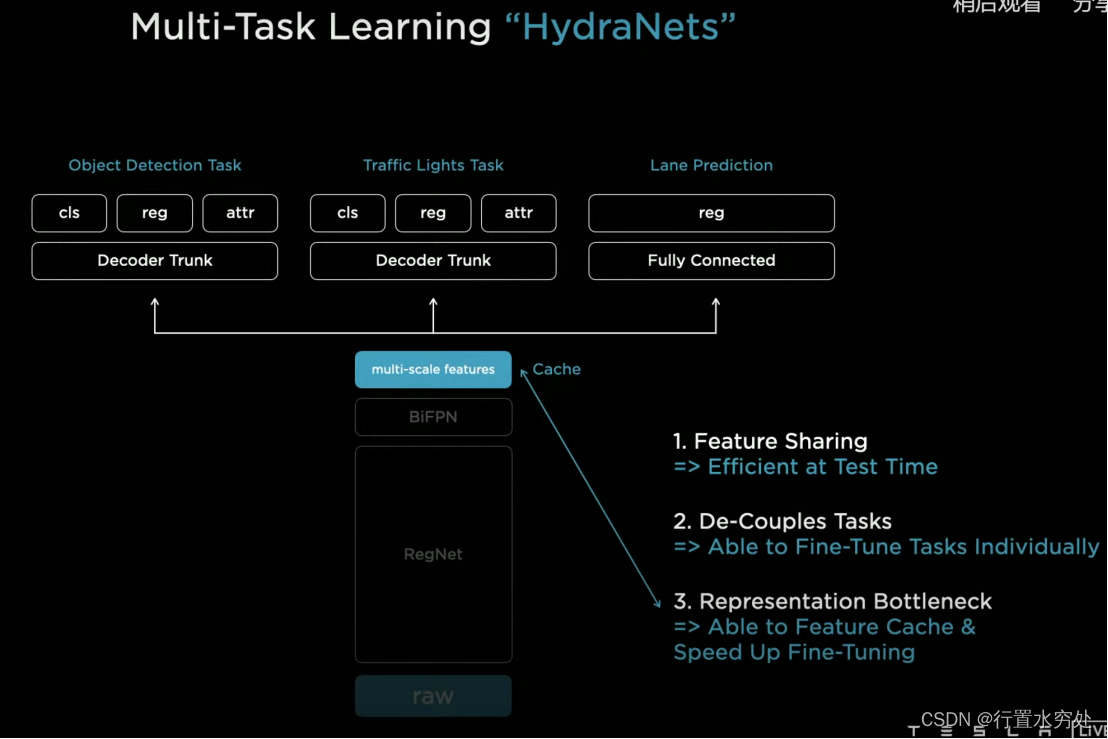 HydraNet使用共同的共享骨干网络Backbone,再分支到多个任务头进行具体的子任务处理,具有非常明显的优势:
HydraNet使用共同的共享骨干网络Backbone,再分支到多个任务头进行具体的子任务处理,具有非常明显的优势:
- 特征共享:在测试时,可以通过共享前向传递推理,提高车载系统的效率。
- 任务解耦:各任务独立进行,互不影响,因此更新某个数据集或更改某个任务头的架构时,无需重新验证所有任务。
- 瓶颈处理:可以将Multi-scale features特征缓存到磁盘,只需对缓存的特征进行微调即可。
3)各组成模块
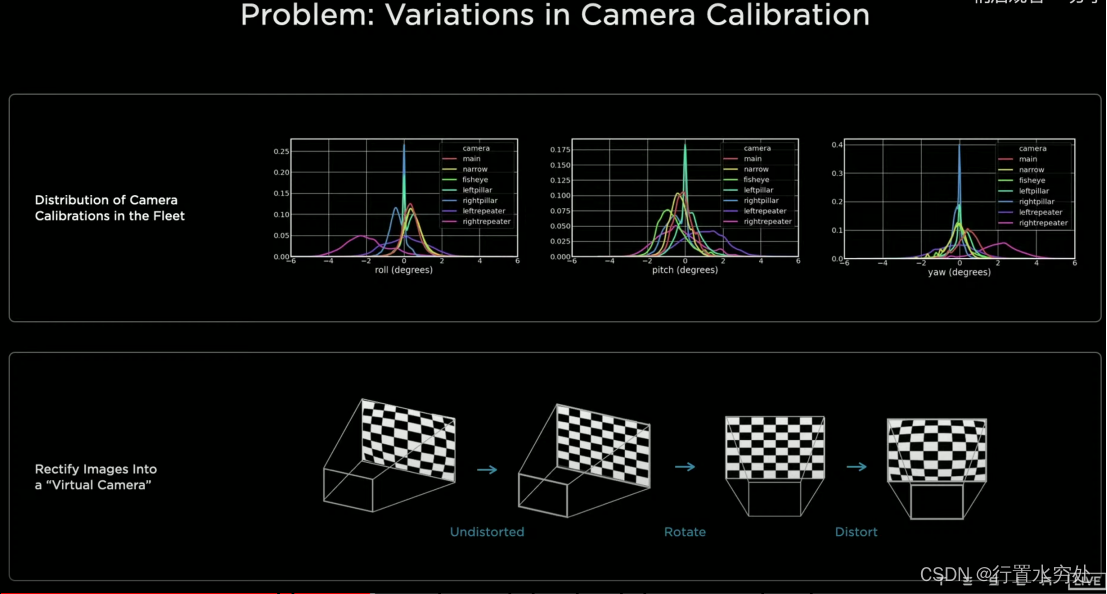
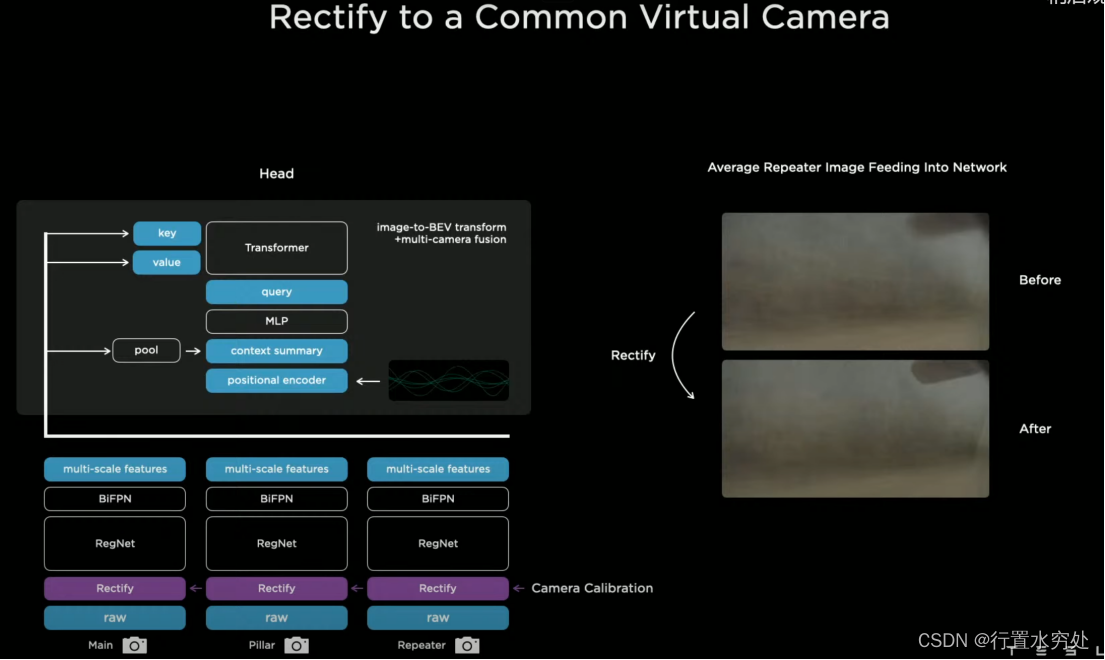
3.1)Rectify校准
考虑到不同位置安装的摄像头的抖动等问题,需要对每个输入的视觉数据进行校准,就是Rectify模块的任务,将所有图片转换为虚拟通用摄像头。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1836
1836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









