







YOLOv11目标检测创新改进与实战案例专栏
点击查看文章目录: YOLOv11创新改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
点击查看专栏链接: YOLOv11目标检测创新改进与实战案例
介绍
摘要
带有大卷积核注意力(LKA)模块的视觉注意网络(VAN)在一系列基于视觉的任务上表现出色,超越了视觉Transformer(ViTs)。然而,这些LKA模块中的深度卷积层随着卷积核尺寸的增加,会导致计算和内存占用的二次增长。为了解决这些问题并使在VAN的注意力模块中使用超大卷积核成为可能,我们提出了一种大可分卷积核注意力模块家族,称为LSKA。LSKA将深度卷积层的二维卷积核分解为串联的水平和垂直一维卷积核。与标准LKA设计不同,这种分解方法使得可以直接在注意力模块中使用带有大卷积核的深度卷积层,而不需要额外的模块。我们证明了在VAN中使用的LSKA模块可以在计算复杂度和内存占用更低的情况下,达到与标准LKA模块相当的性能。我们还发现,随着卷积核尺寸的增加,提出的LSKA设计使VAN更倾向于关注物体的形状而不是纹理。此外,我们还在五种受损版本的ImageNet数据集上,对VAN、ViTs以及最新的ConvNeXt中的LKA和LSKA模块进行了稳健性基准测试,这些数据集在以往的工作中很少被探索。我们广泛的实验结果表明,随着卷积核尺寸的增加,提出的VAN中的LSKA模块显著减少了计算复杂度和内存占用,同时在对象识别、对象检测、语义分割和稳健性测试上表现优于ViTs、ConvNeXt,并与VAN中的LKA模块性能相当。代码可在 https://github.com/StevenLauHKHK/Large-Separable-Kernel-Attention 获得。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
Large Separable Kernel Attention (LSKA)是一种新颖的注意力模块设计,旨在解决Visual Attention Networks (VAN)中使用大内核卷积时所面临的计算效率问题。LSKA通过将2D深度卷积层的卷积核分解为级联的水平和垂直1-D卷积核,从而实现了对大内核的直接使用,无需额外的模块。
概述
-
基本设计:
- LSKA将2D深度卷积层的卷积核分解为级联的水平和垂直1-D卷积核。
- 这种分解设计使得LSKA可以直接使用深度卷积层的大内核,无需额外的模块或计算。
-
计算效率:
- LSKA的设计降低了参数数量的增长,从而降低了计算复杂度和内存占用。
- 通过级联1-D卷积核的方式,LSKA在处理大内核时能够保持高效性能。
-
形状和纹理偏好:
- LSKA设计使得模块更加偏向于对象的形状而非纹理。
- 这种偏好有助于提高模型对对象形状的学习能力,从而提高模型的鲁棒性和泛化能力。
总的来说,LSKA通过巧妙的卷积核分解设计,实现了对大内核的高效利用,同时保持了模型的性能和鲁棒性。其技术原理使得LSKA成为一种有潜力的注意力模块设计,可以在VAN等视觉任务中发挥重要作用。
与LKA-trivial、LSKA-trivial和LKA的比较:
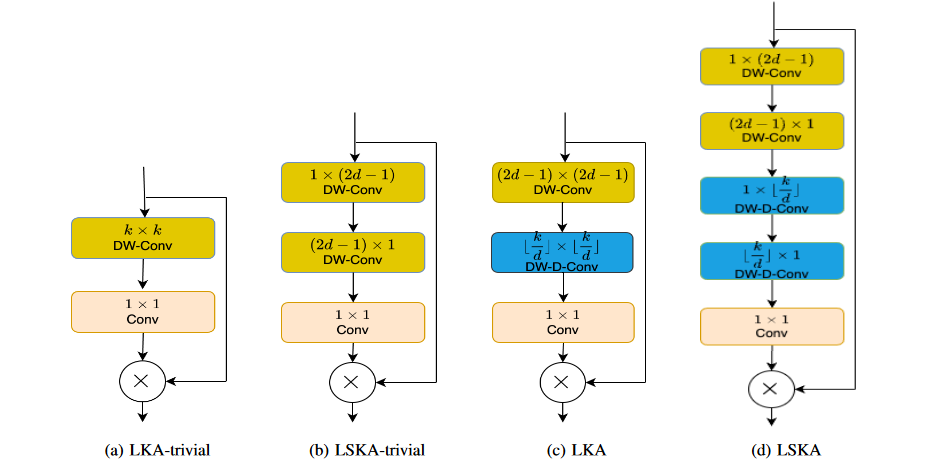
- LKA-trivial是一种简单的注意力模块设计,使用深度卷积和大内核,但会导致参数数量的二次增长。
- LSKA-trivial是对LKA-trivial的改进,通过可分离卷积核的级联降低了参数数量的增长,提高了计算效率。
- LKA是原始的Large Kernel Attention设计,包括标准深度卷积、扩张深度卷积和1x1卷积,但在处理大内核时会带来计算和内存开销。
- LSKA通过级联1D卷积核的设计,有效地解决了LKA中大内核带来的问题,在保持性能的同时降低了计算复杂度和内存占用。
核心代码
import torch
import torch.nn as nn
# 定义一个名为LSKA的神经网络模块类,继承自nn.Module
class LSKA(nn.Module):
def __init__(self, dim, k_size):
# 初始化LSKA类,dim为通道数,k_size为卷积核大小
super().__init__()
self.k_size = k_size # 保存卷积核大小
# 根据k_size的不同值,初始化不同的卷积层
if k_size == 7:
# 水平和垂直方向上的第一层卷积
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)
# 空间卷积层,带有膨胀参数
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









