







官.网地址:合合TextIn - 合合信息旗下OCR云服务产品
随着文本数据关系的日益复杂化,传统的信息抽取技术面临着诸多挑战。深度学习模型的训练往往需要大量的高质量标注的训练样本,依赖规则实现上下文对话,新样本如果变换了行文方式则将难以保证抽取效果,模型泛化能力不强,这就导致基于传统深度学习算法进行标注训练的方式成本非常高昂。
合合信息TextIn平台重磅上线智能文档抽取产品,依托合合信息自研的垂直领域语义模型,并结合了合合信息强大的文字识别、文档解析、文档检索和文本生成四项关键技术,让计算机模拟人类的推理方式,来识别在训练阶段从未见过的新事物,实现开箱即用的“零样本”抽取,让AI触手可及。
立即体验:

01 “开箱即用”
与以往通过标注训练实现文档结构化抽取不同,用户只需在TextIn智能文档抽取直接配置需要提取的关键字段。例如,发明专利证书中的发明名称、证书号、发明人、发明专利号、证书颁发时间、专利申请日等字段,模型可自动提取关键信息。
02 优秀的泛化性
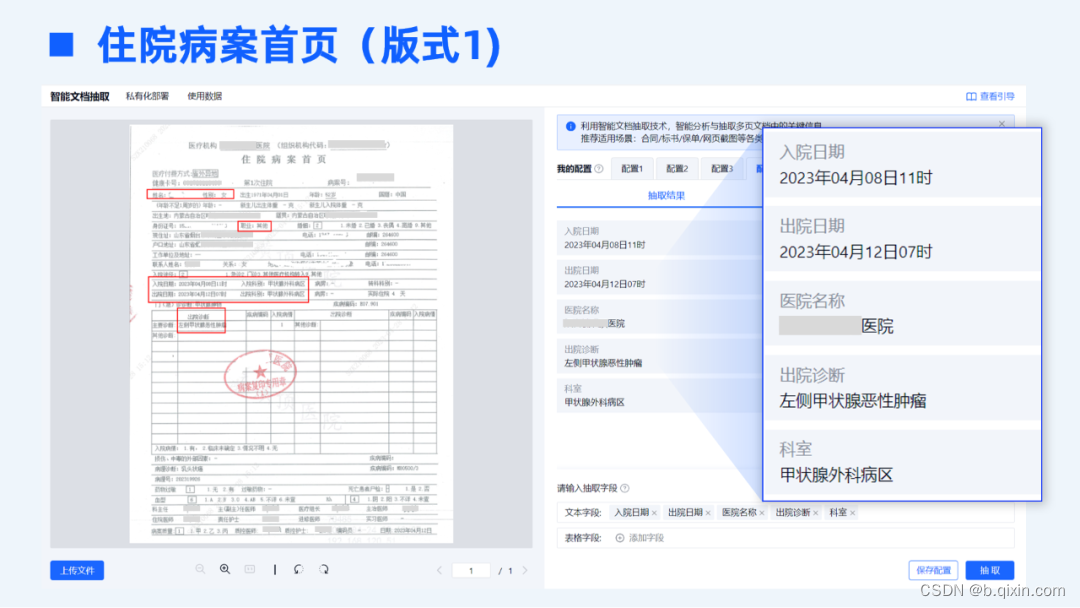
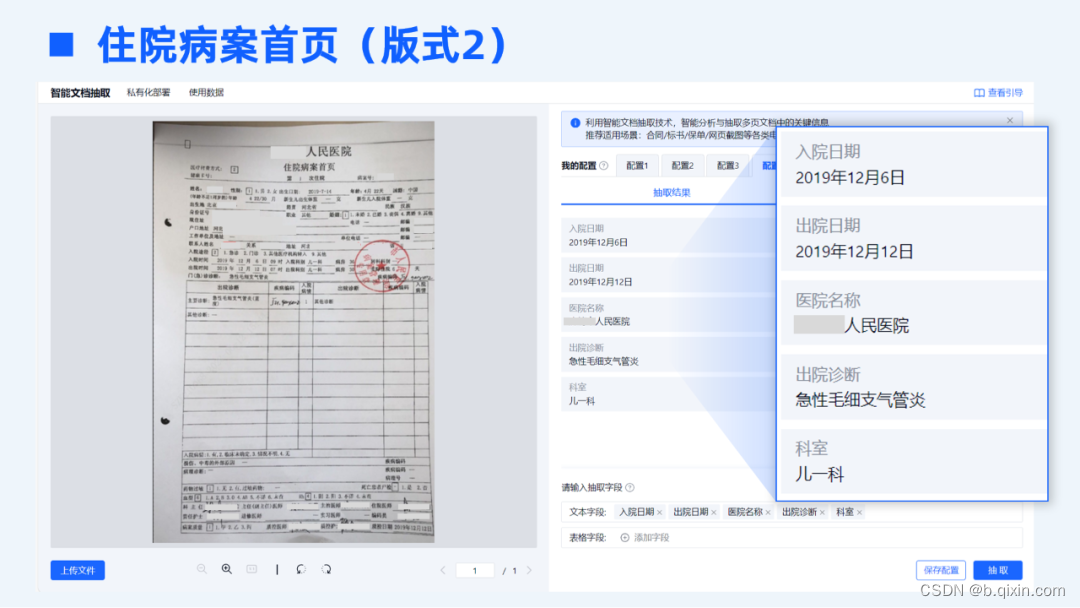
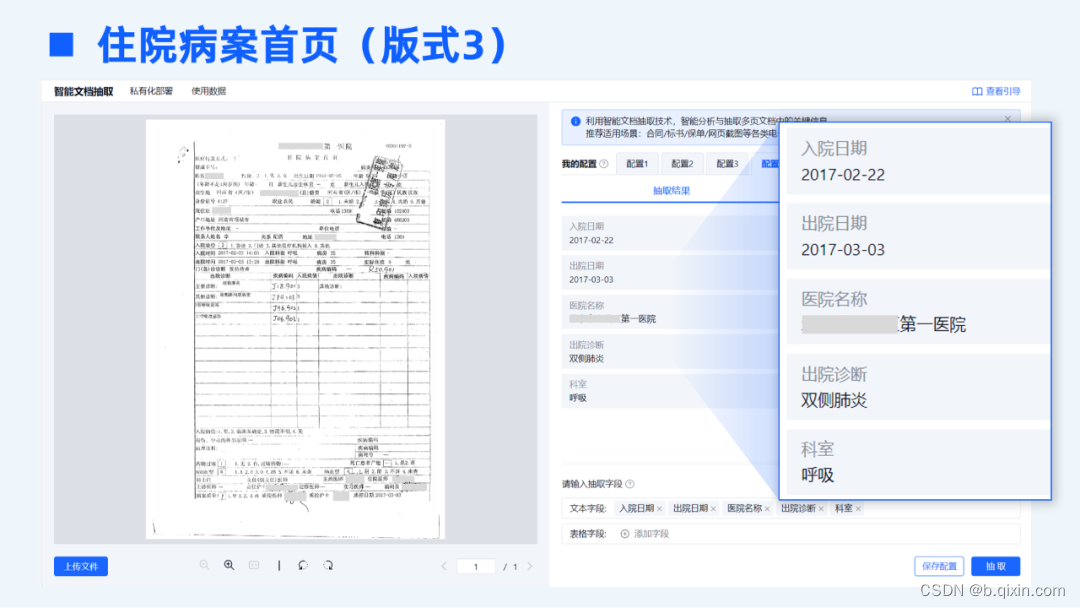
TextIn智能文档抽取基于海量的基础数据做预训练,具备极强的泛化性。以医疗险理赔场景为例,传统标注训练的方式下,需针对每一种不同版式进行大量的样本标注及模型训练,但各家医院出具的住院病案、出入院小结等文档材料版式各不相同、无法穷尽,传统方式显然不可行,不仅标注训练的工作量极大,效果上也无法保证各类版式下的准确率。
合合信息全新上线的智能文档抽取模块具备强大的理解能力,可以兼容各家医院不同版式的住院材料,无需标注训练,开箱即用,即可达到精准的抽取效果。
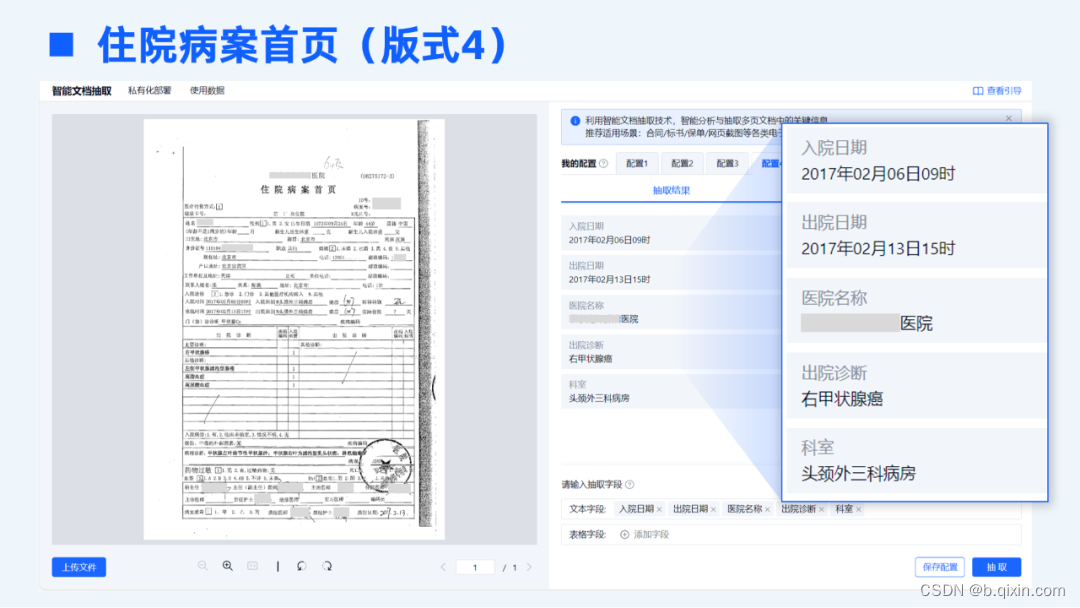
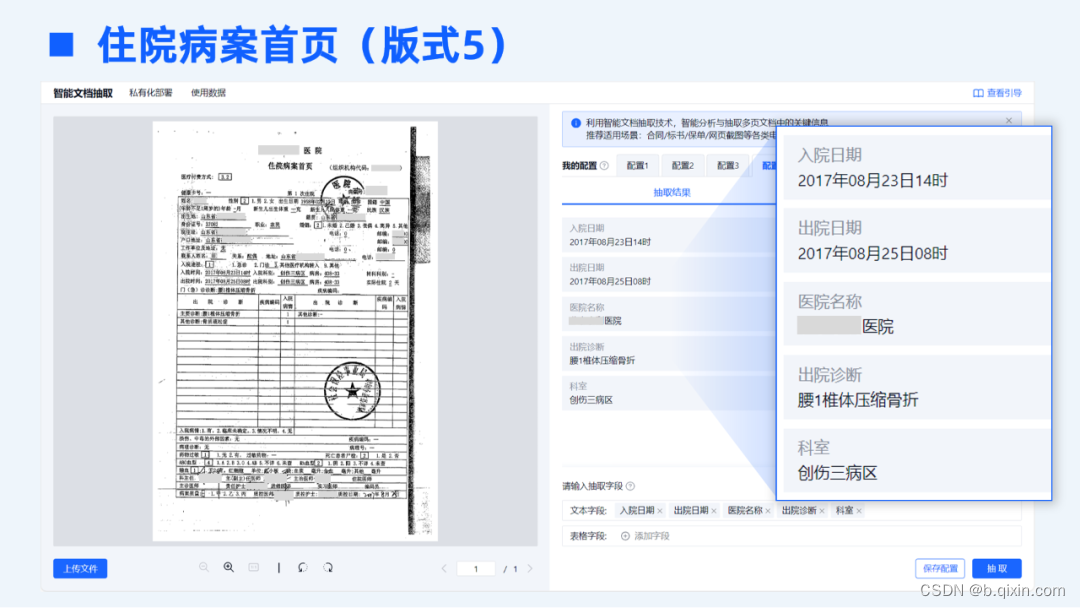
03 准确理解复杂版面
非结构化文档抽取的瓶颈之一在于对文档复杂版面解析的准确性,例如文档中插入的各类复杂表格,对表格结构的准确还原是进行表格信息结构化抽取的前提。如下所示的机动车保单中,关于承保险种的明细项,是以一个非标准、横线缺失、且是双栏结构的复杂表格进行展示的,基于合合信息自研的版面分析引擎可以准确还原该区域的表结构,进而准确抽取到承保险种、保险金额、绝对免赔额、保险费四个表格字段。
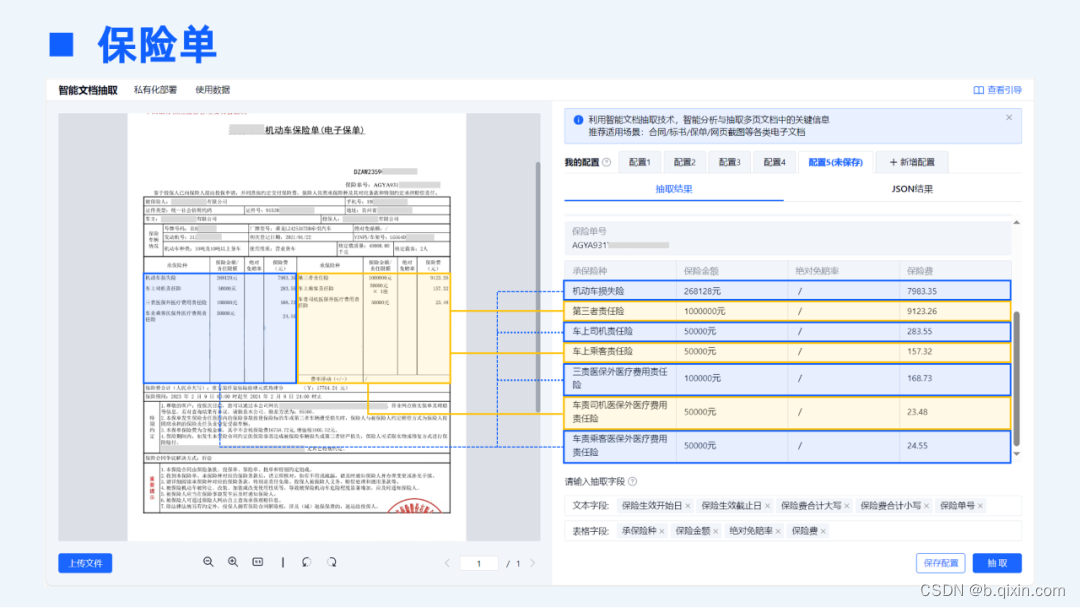
04 “多模态”抽取能力
企业各类非标文档中,有双层PDF电子件、拍摄件、扫描件等不同格式的文件,文档中也可能包含手写体、印章、整表等不同类型的元素。如下所示的某制造企业内部结算申请所需各类单据中,相关人员签名是财务部门进行收入确认审核时需要重点关注的字段,在页面上配置“项目经理”、“保管员”字段,可以抽取到手写体签字信息。
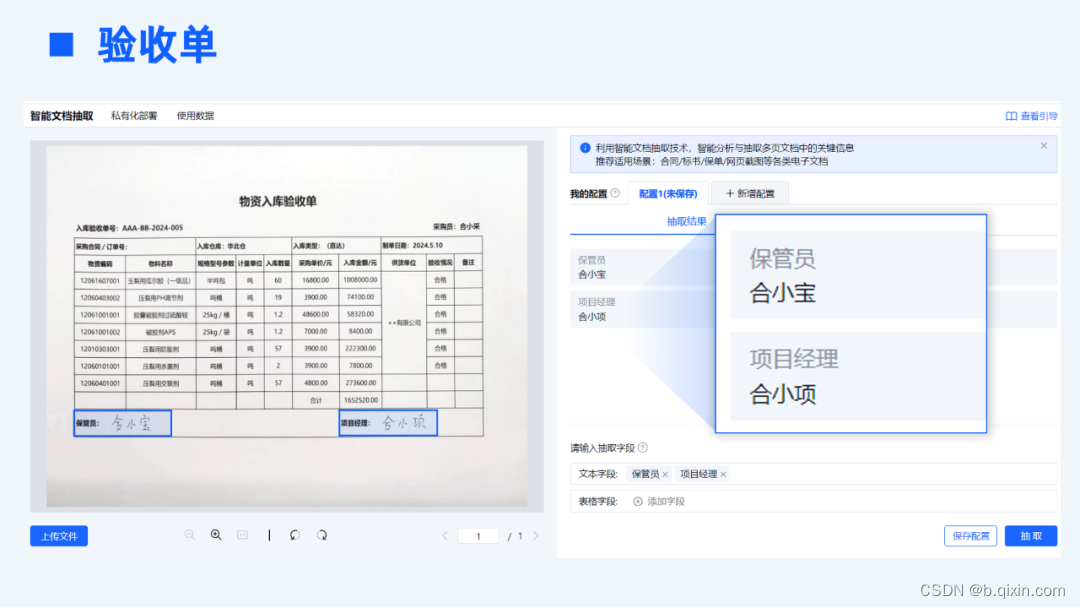
05 兼顾长/短文本
TextIn智能文档抽取既支持单页的非标卡证、票据、表单,如海外invoice、国际信用证、电汇凭证、不动产权证等,也支持几十甚至上百页的长文档,如购销合同、借款合同、基金合同等。

06 具备通用及领域知识
数据量级是模型的地基,模型通过对文档资料的阅读和建模来吸收知识。合合信息通过对涵盖金融(研报、财报、公告、招股书等)、政务(公文、公告、规章制度、政府工作报告等)、法律(法律法规、法律文书等)等各行业高质量语料库的应用,使得语义模型既具备通识能力,也具备不同行业的专项领域知识。以下是一篇公司点评类研报的抽取结果,基于合合信息最新语义模型强大的理解能力,可以实现以往传统模型无法实现的抽取效果:
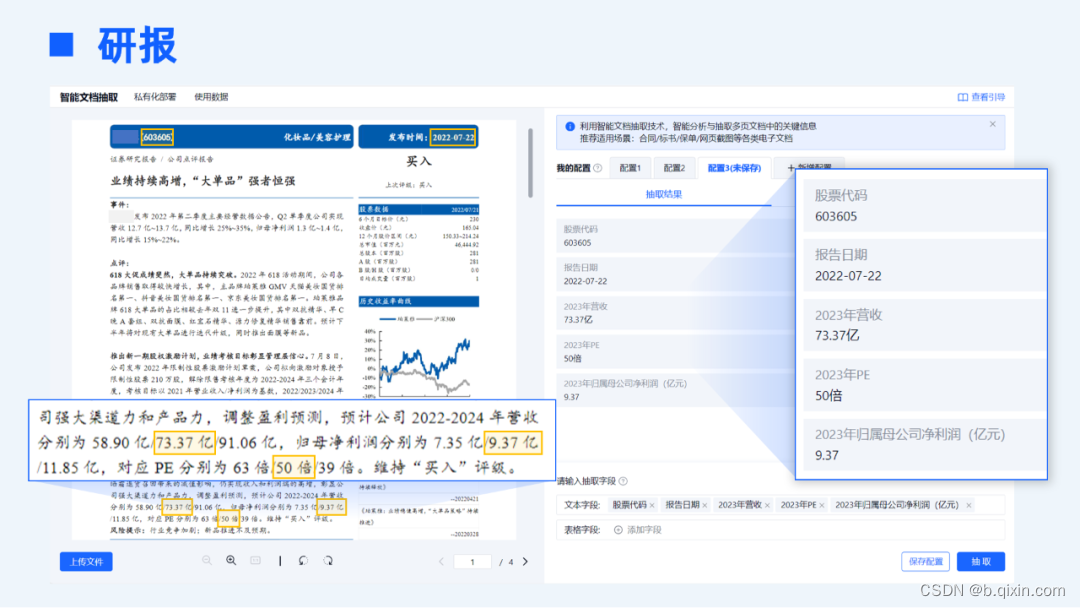
比如对于“年度”有2022、2023、2024;2022-2024;2022~2024;2022至2024等多种表述方式,传统的抽取模式只能基于穷举规则,一一对应年份,表述方式一旦变化就无法准确抽取。再如指标“PE”和“年份”的“距离”,PE离“2022-2024”已经非常远了,传统nlp无法理解这么长的上下文关系,但TextIn智能文档抽取可以准确推理出2023年的PE为50倍。
全文没有出现“股票代码”这个Key字段,但基于合合信息语义模型具备的通识+金融知识,可以准确推理出603605代表的是股票代码。

强大的文档抽取能力正在成为非结构化数据治理、数智化升级的关键驱动力,推动着社会各行各业的快速发展和创新。

















 2568
2568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









