






导读
提升(Boosting)方法是一种广泛有效的学习方法,在分类问题中,通过改变训练样本中的权重,学习多个分类器,并将分类器进行线性组合,提高分类的性能。

Boosting算法和Bagging算法的不同
Boosting算法使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性更好的机器学习模型。与之前的Bagging不同,Bagging是全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合, 然后投票得出最终的预测。两者的区别是使用模型数量的不同,并且Boosting是不断减少误差得到结果。
1 adaboost算法
1.1算法原理
假定一个二分类的训练数据集
其中,每个样本点由实例和标记组成,x属于实例空间,y是标签,Adaboost从这些训练数据中学习一系列弱分类器或基本分类器,并将这些分类器组合成强分类器。
步骤如下:
1 在训练数据上训练样本,得到一个模型,查看该模型在整体数据和单个数据上的分类情况。
2如果该模型在整体数据上分类效果较好,那么该模型在最后的模型中占有较大比例
3如果该模型只在单个数据上分类好,那么在训练下一个模型时,调小单个数据的权重
4直到最后的分类结果达到目标,将所有的模型组合,得到强可学习模型
以统计学习书上的方法为例:
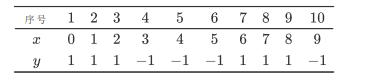
x为数据,y是标签,首先赋给初始权重

每个权重均为0.1
对于分类器1:
训练数据集上,遍历每个结点并计算分类误差率,阈值取v=2.5时分类误差率最低,那么基本分类器为

G(x)的误差为0.3
![]()
计算G1(x)的系数:
![]()
更新后的权重:

在权值分布D 2的训练数据集上,遍历每个结点并计算分类误差率e m e_mem,阈值取v=8.5时分类误差率最低,那么基本分类器为
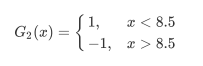
误差为0.24















 7258
7258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









