






卷积神经网络的演变和发展
早期探索 :LeNet—>AlexNet—>ZFNet—>VGGNet
深度化:ResNet—>DenseNet
模块化:GoogLeNet—>Inception v3—>Inception-ResNet—>ResNeXt—>Xception
注意力机制:SENet—>cSE、sSE、scSE—>CBAM
高效化:SqueezeNet—>MobileNet—>ShuffleNet—>GhostNet你
自动化:NASNet—>EfficientNet
未来的发展:1、图像上下文信息的使用 2、针对特定任务设计新的范式 3、自动调节超参数
机器学习发展前期最重要的是对特征的提取,怎么更好的提取要分类物体的特征,对于用的什么机器学习分类算法不是特别重要。要实现分类效果好就要更好的提取特征,更好地去区分要分类物体。图像特征是图像中独特的,易于跟踪和比较的特定模板或特定结构。特征就是有意义的图像区域,该区域具有独特性或易于识别性。
生物的神经元一层一层连接起来,当神经信号达到某一个条件,这个神经元就会激活,然后继续传递信息下去,为了继续使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入端和输出端之间插入更多的神经元。
逻辑回归损失函数
平方差所惩罚的是与损失为同一数量级的情形,对于分类问题,最好使用交叉熵损失函数会更有效,交叉熵会输出一个更大的“损失”。
softmax分类
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理后的一个值而已,那么如何将这个输出变为概率分布,这就是softmax层的作用。
卷积神经网络具有“局部感受野”,“参数共享”、“重叠池化”和“平移不变”的特征,大大减少了参数规模,能够层次化得提取像素的二维空间特征并且比全连接层组成的网络具有更强的位置鲁棒性。局部感受野是每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接收信息的。

LeNet它使用的方式是conv1->pool->conv2->pool2再接全连接层。
AlexNet主要改进:丢弃法、ReLu、MaxPooling、计算机视觉方法论的改变。通过CNN学习特征、Softmax回归分类,CNN和Softmax是一起训练的,缩短了训练的时间。AlexNet激活函数从sigmoid变到ReLu(减缓梯度消失)、隐藏全连接层后加入了丢弃层来做数据的正则化、加入数据增强技术用来脱敏比如对光照较敏感,对图片进行处理变换不同颜色和亮度使神经网络在不同光照下依然可以分类。
卷积是为了提取图像特征,卷积核的数值是通过误差反向传播自己学来的,不是人为给定的,每一个卷积层通道数下都有一个卷积核,通道数不同,卷积核尺寸相同,卷积核内的数值不同。池化是为了缩小图像大小但会保留图像原有的特征,相当于对原图像按一定比例进行放大与缩小,一般是缩小。下采样、池化是几何不变性的根源,平移不变性和变形不变性是神经网络的特征,池化促成这些特征,下采样、池化可以减少参数、防止过拟合。对于定位问题就不能用池化操作,比如googlenet就没有池化操作。
VGG网络的研究者证明了小尺寸卷积核(3X3)的深层网络要优于大尺寸卷积核的浅层网络,所以全部采用3X3的卷积核代替了其他的大尺寸卷积核。VGG把AlexNet中三层卷积和一层池化作为一个块,VGG就是多个块的叠加。
GooleNet这是通过一种称为Inception的模块实现的。该模块的v1(最初)版本将1×1、3×3、5×5的卷积层和3×3的最大池化层拼接在一起,使其能够在一层网络中提取不同视野范围的特征。inception块用4条有不同超参数的卷积层和池化层的路来抽取不同的信息。它的一个主要优点是模型参数小,计算复杂度低。GooleNet使用了9个inception块,是第一个达到上百层的网络。用池化代替全连接层不但能提高模型性能,而且能大大降低参数数量。这也是GoogLeNet这样复杂的网络的参数量比VGG甚至AlexNet参数量还少的原因之一。
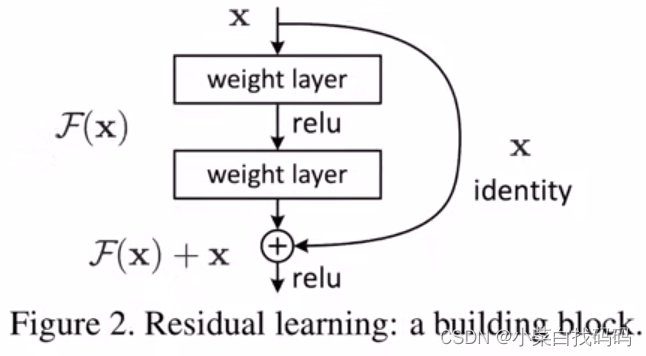
ResNet 残差块使得很深的网络更加容易训练,甚至可以训练一千层的网络,残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接网络。ResNet结构能更好的解决梯度消失和梯度爆炸问题。
由于超参数繁多,深度神经网络具有很大的设计空间。通常进行设计空间探索的方法有:1、贝叶斯优化 2、模拟退火 3、随机搜索 4、遗传算法
网络设计经验
根据以往的经验,增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
增加网络的width能够获得更高细粒度的特征并且也更容易训练。但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模块,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
同时增加网络的宽度和深度能更好的提高网络的准确率。
batch normalization优点:减少训练时间,可以训练更深的网络,减小梯度消失,减小初始化数对学习训练的影响,一般卷积之后加入batch normalization。
目标检测器
传统检测方法:1、Viola-Jones 2、HOG 3、DPM
两阶段检测器:1、RCNN 2、SPP-Net 3、Fast R-CNN 4、Faster R-CNN 5、FPN 6、R-FCN 7、MaskR-CNN 8、DetectoRS
一阶段检测器:1、YOLO 2、SSD 3、YOLOv2与YOLO9000 4、RetinaNet 5、YOLOv3 6、CenterNet 7、EfficientDet 8、YOLOv4 9、Swin Transformer

R-CNN存在的问题:1、测试速度慢:测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。2、训练速度慢:过程及其繁琐。3、训练所需空间大:对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。

迁移学习

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









