









前面几章已经介绍了神经网络的结构、数据初始化、激活函数、损失函数等问题,现在我们该讨论如何让神经网络模型进行学习了。
1 梯度检验
权重的更新梯度是否正确决定着函数是否想着正确的方向迭代,在UFLDL中我们提到过,计算时梯度公式如果计算错误是不容被察觉的,我们需要比较分析法得到梯度与数值法得到的梯度是否相似,下面是一些技巧:
1.1 centered formula
高等数学中我们知道导数的近似公式:
以及下面的centered formula:
利用泰勒公式可以证明后者的精度要高于前者,所以实际中我们要使用这个公式来进行梯度检验。
1.2 comparison 相对误差的比较
上面已经得到了数值法的梯度的公式,如何与我们训练时用的分析法得到的公式相比较呢?如果只使用绝对误差并不合适,例如绝对误差等于0.0001时,对于梯度绝对值为1左右和绝对值为0.0001左右时的意义并不一样。这里我们要考虑绝对误差:
其中的分母也可以由max变为加法形式:
这样两个公式可以避免分子为0的情况(ReLU经常出现),使公式同时考虑两者的大小,但是公式中海油可能出现两者绝对值都是零的情况,但是要注意避免这种情况。下面是评价相对误差好坏的经验:
1. relative error > 1e-2 一般来说梯度计算出了问题
2. 1e-2 > relative error > 1e-4 可能有问题了
3. 1e-4 > relative error不光滑的激励函数来说时可以接受的,但是如果使用平滑的激励函数如 tanh nonlinearities and softmax,这个结果还是太高了。
4. 1e-7 可以喝杯茶庆祝下
另外要注意的是,随着网络深度的增加会使得误差积累,如果用了10层的网络,得到的相对误差为1e-2那么这个结果也是可以接受的。
1.3 使用双精度浮点数
单精度会造成误差的变大,有时候从单精度转向双精度相对误差会从1e-2转到1e-8
1.4 留意浮点数范围
可以看看 “What Every Computer Scientist Should Know About Floating-Point Arithmetic”,可能会使你写出更加出色的代码. 如果现实中的梯度太小比如1e-10左右,会出现很多计算问题,这时候我们需要将其方法后在处理,使用时我们可以先打印出原始的 numerical/analytic gradient,如果不行可以将其放大到1左右再进行下一步工作。
1.5 kinks 目标函数的不光滑
Kinks是指目标函数不能完全可微的情况可以由之前我们提到的ReLU 、 SVM loss, Maxout 等引入。试想如果我们要检验的是在x=−1e6时的ReLU的梯度. x<0时analytic gradient一定为0. 然而如果我们区的h稍微大一点就会使f(x+h)跨过0点,数值法得到的梯度就不会为0了,这种情况经常发生。另外 SVM classifier 会因为 ReLUs的激励函数得到很多的kinks.我们可以通过跟踪max(x,y)中较大的一个判断是否有kink出现如果在向前计算的时候x或者y最大,但是在计算 f(x+h) 和 f(x−h)时至少有一个的最大值变化了,说明存在穿过kink的现象了。
1.6 使用少量的点检验
对于上面提到的kinks现象可以只使用少量的点来检查,这样可以避免遇到kinks线性,这样也可以提高效率。
1.7 步长h的选取
h也不能太小,太小容易陷入精度的问题,1e-4 or 1e-6 就好,这篇文章介绍了h选择与数值法梯度的关系。
1.8 选择典型状态
我们需要注意的是我们的梯度检查中,检查的是一部分的点,并不是这些点正确就代表全局正确,我们必须选择尽量典型的点作为检查的对象,比如在svm刚开始的时候,我们会发现其权重初始值得到的score基本都是0,显然这只是一种特殊情况,所以为了选择典型的状态,最好在网络预热一小段时间之后,使得loss函数有所下降的时候再进行梯度检查.
1.9 regularization loss vs. data loss
regularization 往往具有比较简单的梯度形式,但是总的损失函数是由两部分组成,如果regularization的梯度太大就容易盖过data loss 的梯度。我们可以先关闭regularization再关闭data loss 分别讨论他们的梯度检查,其中再单独讨论regularization的梯度检查的时候可以将源代码里的data loss去掉也可以增大regularization的权重。
1.10 关掉dropout等因素
一些非决定性的因素会给数值法梯度带来很大的误差 ,比如dropout, random data augmentations, etc.但是如果完全关掉他们的话又不能说明在启用他们时会正常工作. 更好一点的方案是在计算 f(x+h)和f(x−h)及估计解析梯度时设置随机因子。(这里还有待进一步理解)
1.11 检查少量维度
神经网络中参数一般很多,所以可以只检查几个维度即可,但是要注意检查的维度中的每一个参数都要检查。
2 sanity checks
在使用全部的数据进行费劲的训练之前做好进行以下最后的检查工作。
2.1 检查随机loss值
我们可以通过检查初始的loss值,验证我们的初始化有没有问题,需要先关闭regression再进行操作(损失函数看这里)。例如:
使用Softmax classifier 对CIFAR-10 分类我们希望初始每一个初始的概率都是0.1,所以他的loss应该是-ln(0.1) = 2.302;
在使用svm时我们希望开始的时候都没有满足我们设定的阈值,也就是全部得分都是0,所以其初始loss应该是9.
2.2 增大regression
增大regression会是loss增大
2.3 过拟合少量数据
先关闭regression然后对少量的数据进行训练比如20个样本,如果系统正常则完全可以将这少量的数据过拟合。但是要注意的是即便可以过拟合小样本数据,但是系统也可能还是不能表现的非常好,例如如果数据中有随机的特征,那么用全部数据得到的结果也没有太大的泛化能力。
3 观察训练过程
我们可以设置几个监控窗口观察学习过程的表现,给下一步调整超参数做准备。检测窗口的横坐标是训练次数epochs,而不是迭代次数。
3.1 loss function
损失函数是需要观察的首要对象,下图中展示了不同learning rate的时候得到的不同结果。

下图是一个真实的loss过程,看起来还是很合理的,但是噪音还是比较大可能是进行批量梯度下降时的量太小造成的。
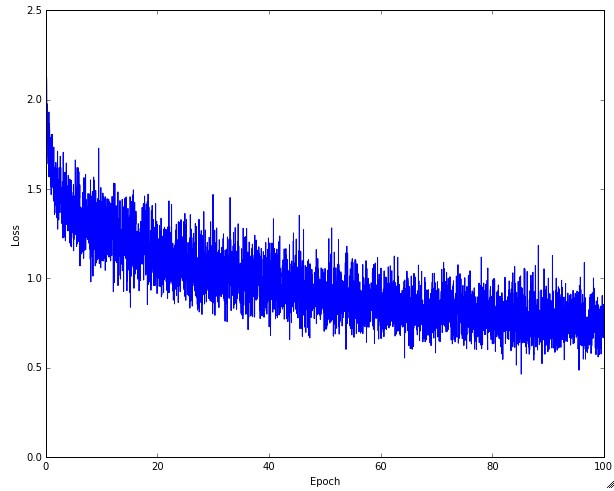
另外有人喜欢将其在log空间中绘图,曲线可能会就更直一些;
还有,可以将多个交叉验证的模型与其一同绘制,可以直观的看出不同点。
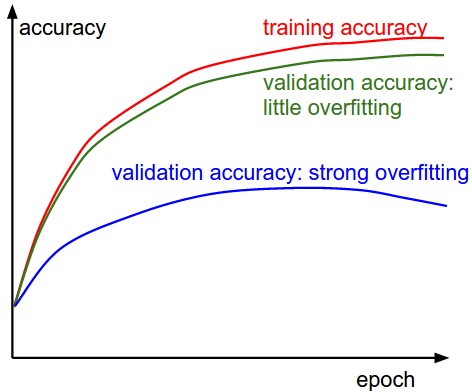
3.2 Train/Val accuracy
观察训练集合验证集的精度可以分析是否过拟合。下图中的蓝线说明模型过拟合了。
3.3 权重更新率
观察权重更新的快慢可以知道学习速度learning rate 设定的大小是否合适,下面是权重更新率计算的过程,一般来说在值小于1e-3的时候说明学习效率设定的太小,大于的时候说明设置的太大。
# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-33.4 Activation / Gradient distributions per layer
我们希望每一层的输出的激活值或者梯度都分布的比较均匀。下面是不合理的分布:
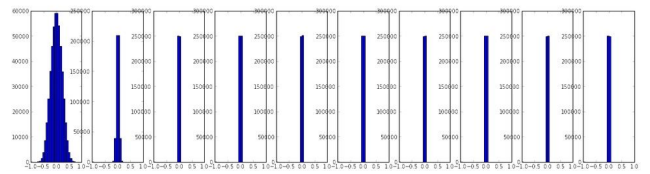
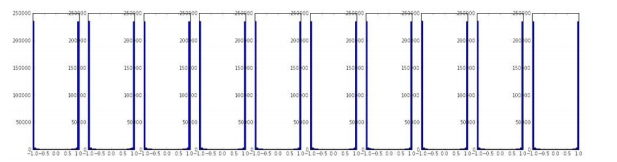
3.5 第一层可视化
如果是在处理图片可以将第一层可视化:
下图第二个是一个非常合理的结果:特征多样,比较干净、平滑。但是左边第一个很粗糙,显示不出底层特征,可能是因为网络不收敛或者学习速率设置不好或者是因为惩罚因子设置的太小。

4 参数更新
在进行梯度检查之后,我们就需要更新参数了。
http://www.cnblogs.com/neopenx/p/4768388.html
推荐上面的博客 比下面写的好
4.1 SGD, momentum, Nesterov momentum
4.1.1 Vanilla update
这种方法就是想着负梯度的方向更新数据
# Vanilla update
x += - learning_rate * dx4.1.2 Momentum update
这种方法是从物理的角度出发的,将寻找最优解的过程理解为寻找最低点的过程,其计算过程如下:
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position这里的v初始值为0,mu相当于摩擦系数一般选择0.9,也可以通过交叉验证从 [0.5, 0.9, 0.95, 0.99]中选取,从上面的迭代过程中我们可以看到,相对于传统的沿梯度方向更新的方法,这里的更新是在之前的基础上的更新,如果最后dx变为0,经过多次乘以mu之后v也会变得非常小,也就是最后的停车,它保留了自然界中的惯性的成分,因此不容易在局部最优解除停止,而且中间有加速度所以会加速运算的过程。
4.1.3 Nesterov Momentum
这是Momentum update的改进版,之前我们采用v = mu * v - learning_rate * dx的方法计算增量,其中的dx还是当前的x,但是我们已经知道了,下一刻的惯性将会带我们去的位置,所以现在我们要用加了mu*v之后的x,来更新位置,下面的图很形象:
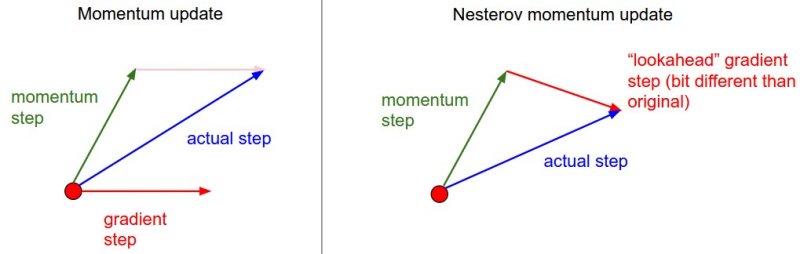
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v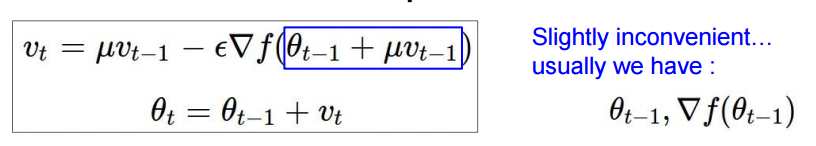
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form这种方法的结果要好一些,下面是拓展阅读的资料:
1. Advances in optimizing Recurrent Networks by Yoshua Bengio, Section 3.5.
2. Ilya Sutskever’s thesis (pdf) contains a longer exposition of the topic in section 7.2
4.2 Annealing the learning rate
在训练网络的时候,将学习速率进行退火衰减处理,一般会有些帮助。 学习速率太大,容易错过最佳解,速率太小又会浪费时间,我们一般用下面三种方法对学习速率进行退火处理:
1. Step decay: 一般以步为单位,比如每训练5次衰减一般或者20次衰减0.1。在我们训练时如果在验证集上的错误率一直表现不好,这时候可以衰减学习速率试试。
2. Exponential decay.α=α0e−kt,t是迭代次数, α0,k是超参数,t是迭代次数。
3. 1/t decay :α=α0/(1+kt)其中a0,k是超参数,t是迭代次数。
实际运用时一般更喜欢用step decay,因为其中的超参数更好理解些。另外如果计算力许可,我们一般宁可选择衰减的厉害些的计算的时间更长些的方法,毕竟精度也很重要。
4.3 Second order methods
Second order methods是基于牛顿法的二次方法,它的迭代公式如下:
其中, Hf(x)是Hessian matrix海森矩阵. 他是二阶偏导数构成的方阵∇f(x)是梯度向量, 引入海森矩阵的逆阵可以使得在坡度陡时候减小学习步伐,坡度缓的时候加快学习步伐 ,值得注意的是这种方法并不涉及学习速率的超参数,这是相对于一阶方法 first-order methods的优势.
可是,hessian矩阵的计算实在太费力了,深度学习中的网络有比较大,例如如果有100万个参数,海森矩阵的size为 [1,000,000 x 1,000,000], 需要3725 G的RAM.
虽然现在有近似于hessian矩阵的方法例如 L-BFGS,但是它需要在整个训练集中进行训练, 这也使得 L-BFGS or similar second-order methods等方法在大规模学习的今天不常见的原因。如何是l-bfgs能像sgd一样在mini-batches上比较好的应用也是现在一个比较热门的研究领域。
其他参考文献:
1. Large Scale Distributed Deep Networks is a paper from the Google Brain team, comparing L-BFGS and SGD variants in large-scale distributed optimization.
2. SFO algorithm strives to combine the advantages of SGD with advantages of L-BFGS.
4.4学习速率更新方法 (Adagrad, RMSProp,adam)
之前学习方法中的learning rate在整个训练过程中对于每个参数基本都是不变的,这里要介绍几种使学习速度根据每个参数的不同自动改变方法,虽然也需要设置一些超参数,但是这样的效果一般比原来的单一学习速率要更好些。
1. Adagrad
这是由Duchi 等提出的。方程如下:
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)注意到cache与梯度矩阵同形,他是一个针对每个参数的梯度迭代累加的矩阵,他作为分母可以使在梯度大的时候学习效率速率降低,梯度小的时候学习速率增高,要注意的是其开方式很重要的,没了他效果会大打折扣,其中eps一般取值1e-4 到1e-8,以避免分母出现0.但是这种方法用在深度学习中往往会使过早的停止学习。
这里要感谢daihengchen指点: Adagrad中chche累加的原因是在后期作为惩罚项,这样的话学习率越来越小,符合在最后接近收敛的时候,步长越来越小的要求。
2. RMSprop.
RMS是均方根的意思
RMSprop是一种高效但是还未正式出版的自适应调节学习速率的方法.然而使用者一直都在引用hinton在coursera上的课程的ppt: slide 29 of Lecture 6 . 它是Adagrad method的升级:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)其改变就是分母中的cache,其中的decay_rate是一个超参数,其值可以在 [0.9, 0.99, 0.999]中选择. 其cache的改变使这种方法有adagrad根据参数梯度自调整的优点也克服了adagrad单调减小的缺点。
3. Adam
adam有点像RMSProp+momentum,简化版程序如下:
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)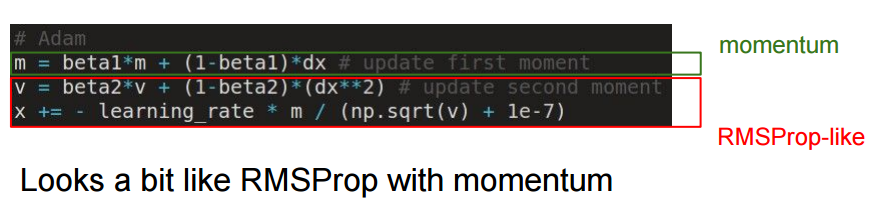
#RMSProp
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)论文中推荐eps = 1e-8, beta1 = 0.9, beta2 = 0.999. 完整版的程序还包括了一个偏差修正值,以弥补开始时m,v初始时为零的现象。
实际使用中,推荐Adam,他会比RMSProp效果好些. 然而SGD+Nesterov Momentum也可以替换他们试试. 另外如果能够允许全局的更新时可以试试L-BFGS。
Additional References:
Unit Tests for Stochastic Optimization proposes a series of tests as a standardized benchmark for stochastic optimization.
方法比较
gif来自https://twitter.com/alecrad
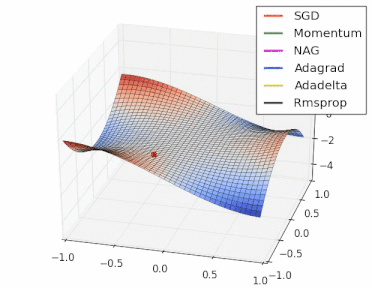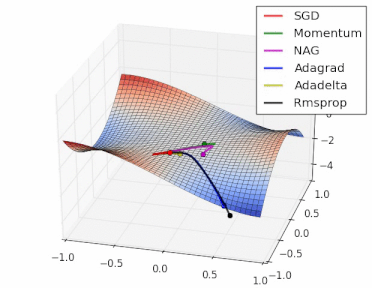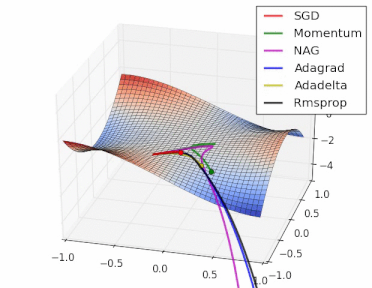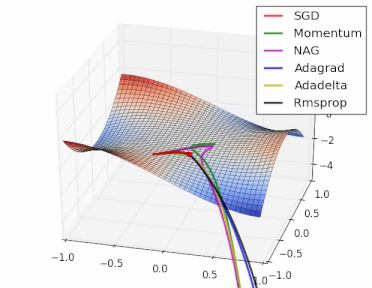
可以看出SGD的速度还是比较慢的。
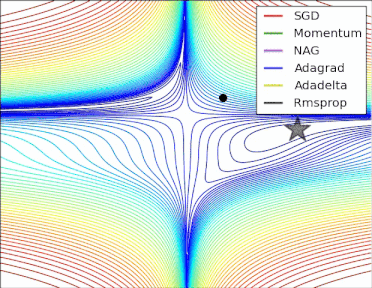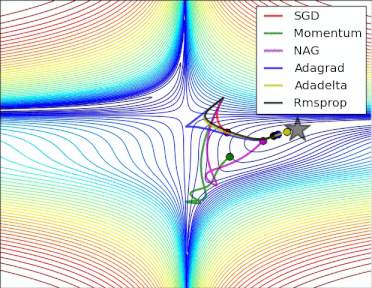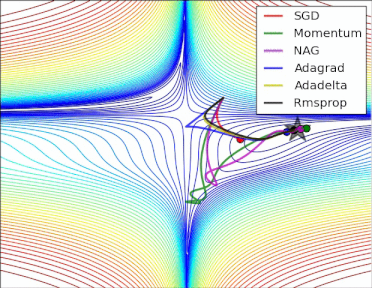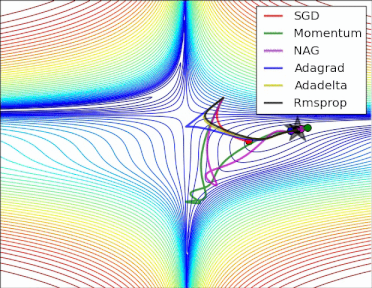
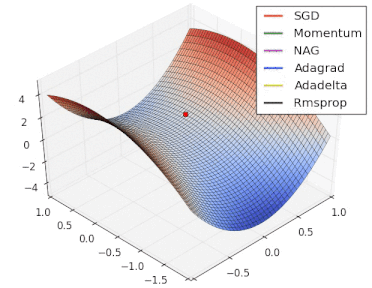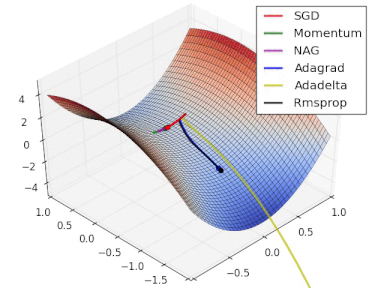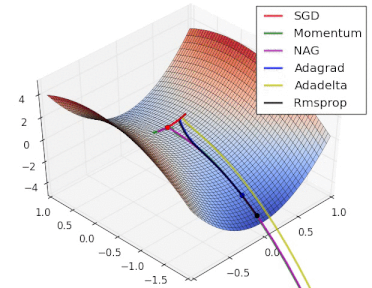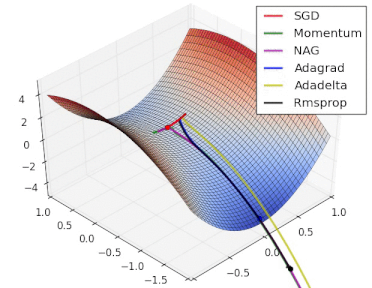
5 超参数优化
常见的超参数有这么几个:
- 初始学习速率
- 学习速率衰减项
- 惩罚因子(如L2或者dropout强度)
训练时要注意的事情:
- 大型的神经网络需要花费很长的时间来训练,所以要仔细的设计的自己编码,我们一般需要设置一个记录器记录不同超参数的在训练集上每次训练之后的优化效果,可以与其他验证集的表现特征一同保存在特定的文件中, 如果多台机器同时工作可以设置一个master来监控哥哥记录器。
- 在一个验证集上验证效果即可,不需要在多个folds上验证。
- 在超参数的选取范围方面,我们一般选取log scale,例如学习速率的范围选取
learning_rate = 10 ** uniform(-6, 1)这可以顾及较大的范围,不过也有一些参数比如dropout的选取dropout = uniform(0,1) - 如Prefer random search to grid search, Bergstra and Bengio 在 Random Search for Hyper-Parameter Optimization,认为random的选择方式比起网格选取更有效。
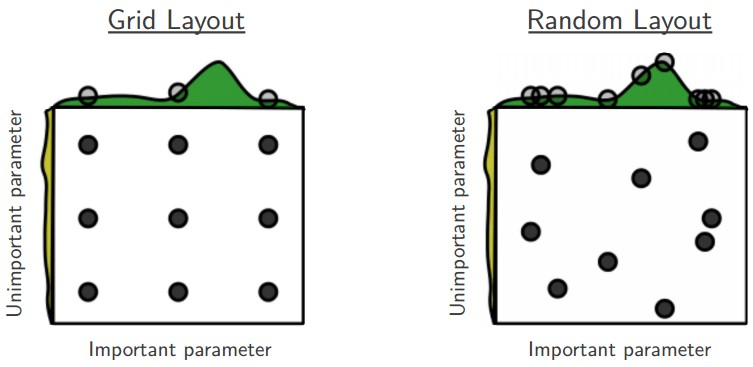
- Careful with best values on border.有时候我们选择的参数范围并不是最好的,所以得到结果时要注意查看是否参数在我们选择的范围的边界上。
- 从粗到精。开始时我们可以选取一个比较粗犷的范围,然后再慢慢缩小范围。另外可以在类似于这样进行:先训练一个epoch时就看一看效果如何,因为有些参数的设置会直接不能使模型学习,第二阶段可以在更精细的范围内训练5epochs,最后在进行更精细的搜索并且使用更多的epochs。
- 利用Bayesian方法进行超参数优化。很多人在探究,现在已经有了一些工具箱比如Spearmint, SMAC, 及Hyperopt.但是在 ConvNets 上表现还是不如给定间隔的随机选择,这里有些相关的讨论.
6 Model Ensembles 模型融合
一个经典提高模型表现能力的方法就是模型融合,一般模型的多样性越好,得到的结果也会越好。
以下是几种得到不同模型的方法:
- 相同模型,不同的初始化。选择好最佳的超参数之后使用不同的初始化得到不同的模型.
- 验证集得到最优的模型。在使用验证集选择最佳的超参数的时候,选取几个最优的模型。
- 单模型融合。有些模型训练特别费劲,可以选取不同时间checkpoints得到的参数进行融合。
- 平均训练参数。另外一个比较容易得到的模型就是copy下网络的参数,然后用指数下降的方式求训练过程中的平均,最终得到了最后几次迭代为主的模型,这样的模型经常会有些比较好的表现。一种直观的解释是在一个碗状的目标函数,我们得到结果经常在最下方的附近进行跳跃,而我们用平均值就会增加了更接近碗底的机会。
模型融合的一个缺点是会花费更多的时间来验证结果, Geoff Hinton 在“Dark Knowledge”想要 从一个好的融合的模型中提取一个好的单个模型。
拓展阅读:
- SGD tips and tricks from Leon Bottou
- Efficient BackProp (pdf) from Yann LeCun
- Practical Recommendations for Gradient-Based Training of Deep Architectures from Yoshua Bengio
总结:















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









