







 本文介绍了Embedding在自然语言处理中的重要性,如捕捉语义关系和上下文信息。常见的Embedding方法包括Word2Vec、GloVe和BERT。此外,文章对比了GPT-embedding、文心千帆和通义干问三种embedding模型,讨论了它们的基本信息、应用和如何在创作中使用这些模型的嵌入向量来改进内容。
本文介绍了Embedding在自然语言处理中的重要性,如捕捉语义关系和上下文信息。常见的Embedding方法包括Word2Vec、GloVe和BERT。此外,文章对比了GPT-embedding、文心千帆和通义干问三种embedding模型,讨论了它们的基本信息、应用和如何在创作中使用这些模型的嵌入向量来改进内容。
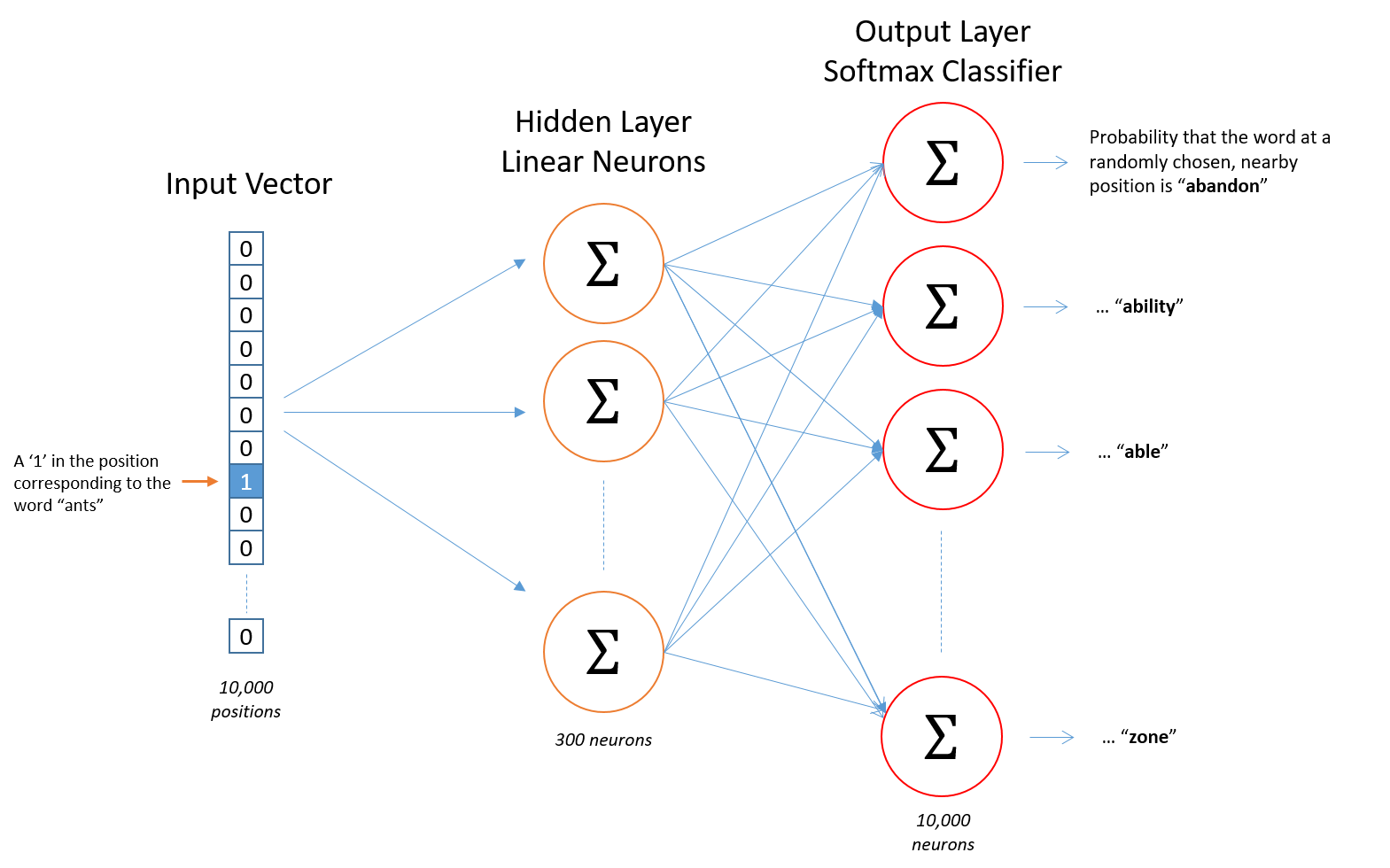
Embedding(嵌入)是一种在计算机科学中常用的技术,尤其是在自然语言处理(NLP)领域。在NLP中,embedding通常指的是将文本中的单词、短语或句子转换为固定维度的向量(vector)。这些向量代表了文本中的语义和上下文信息。
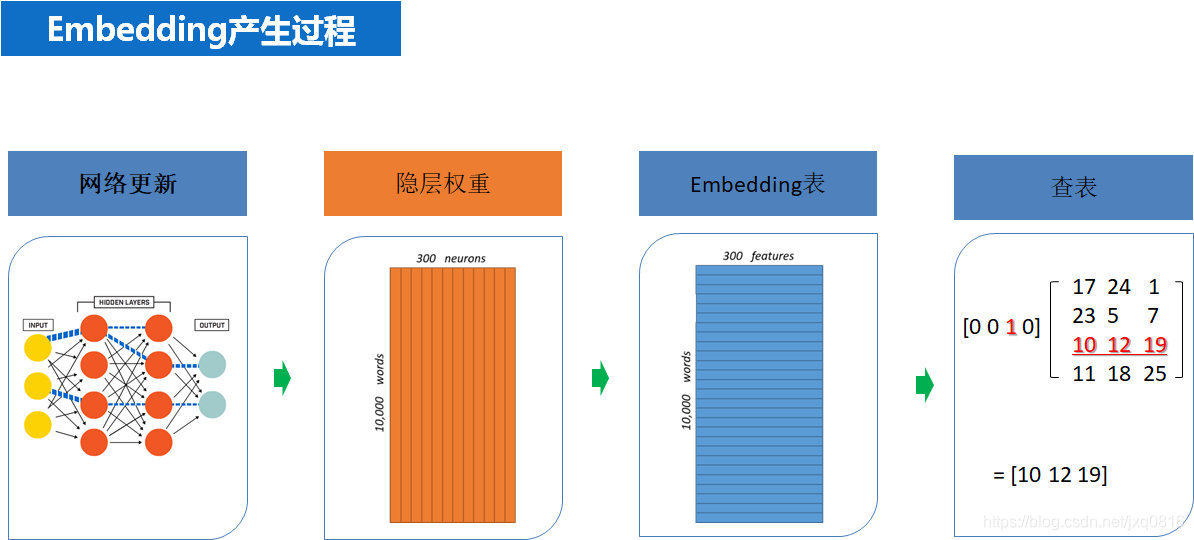
1.embedding 介绍
1.1 为什么需要Embedding?
在传统的文本处理方法中,单词通常被表示为整数ID或稀疏的one-hot向量。这种表示方式难以捕捉单词之间的语义关系和上下文信息。Embedding通过将单词转换为稠密的向量,使得单词之间的关系和上下文信息可以被更好地捕捉和利用。

1.2 常见的Embedding方法
- Word2Vec:这是一种将单词转换为固定维度向量的方法,它包括CBOW(连续词袋模型)和Skip-Gram两种模型。
- GloVe:这是一种基于全局矩阵分解的方法,旨在学习单词之间的关系。
- BERT:这是一种基于Transformer的预训练语言模型,可以学习单词的上下文信息。

1.3 Embedding的应用
Embedding在NLP中有着广泛的应用,包括但不限于:
- 文本分类:通过学习单词的embedding,可以对文本进行分类。
- 情感分析:通过分析文本的embedding,可以判断文本的情感倾向。
- 命名实体识别:通过embedding,可以识别文本中的命名实体,如人名、地点等。
- 机器翻译:使用embedding可以提高机器翻译的准确性。
1.4 总结
Embedding是一种将文本中的单词转换为向量的技术,它能够更好地捕捉单词之间的语义关系和上下文信息。在NLP领域,embedding的应用非常广泛,可以帮助解决许多文本处理任务。

2.介绍三家embedding模型
2.1 基本信息和价格对比
| 模型 | 版本 | 价格 |
| GPT-embedding | text-embedding-ada-002 | $0.0001/K tokens |
| 文心千帆 | Embedding-V1 | ¥0.002/K tokens |
| 通义干问 | text-embedding-v1 | ¥0.0007/k tokens |
以下是关于这些数据的一些基本信息:
GPT-embedding: GPT-embedding是OpenAI提供的一种文本嵌入服务。您可以使用GPT-embedding为您的文本生成高质量的嵌入表示,这些嵌入可以用于各种自然语言处理任务,如文本分类、情感分析等。GPT-embedding支持Python调用。
text-embedding-ada-002是OpenAI于2022年12月提供的一个embedding模型,但需要调用接口付费使用。其具有如下特点:
a.统一能力:OpenAI通过将五个独立的模型(文本相似性、文本搜索-查询、文本搜索-文档、代码搜索-文本和代码搜索-代码)合并为一个新的模型在一系列不同的文本搜索、句子相似性和代码搜索基准中,这个单一的表述比以前的嵌入模型表现得更好
b.上下文:上下文长度为8192,使得它在处理长文档时更加方便
c.嵌入尺寸:只有1536个维度,是davinci-001嵌入尺寸的八分之一,使新的嵌入在处理矢量数据库时更具成本效益文心千帆: 文心千帆是一种基于云雀模型开发的文本嵌入服务,它可以为您的文本数据生成丰富的语义特征。这些特征可以用于构建推荐系统、内容审核、广告投放等多个领域。文心千帆也支持Python调用。
通义干问: 通义干问是基于通义千问模型开发的文本嵌入服务,它能够为您的文本数据生成高维度的语义表示。这些表示可以用于机器翻译、问答系统、文本生成等多个领域。通义干问支持Python和JavaScript调用。
这些模型和服务的官网地址如下:
- GPT-embedding: 官网地址为 https://openai.com/ 1 。
- 文心千帆: 官网地址未提供,但相关信息可以在 https://doc.chatgptcn.com/embeddings 找到 2 。
- 通义干问: 官网地址为 https://docs.gpt4all.io/ 3 。
这些模型和服务的应用可以帮助您根据模型提供的嵌入向量来改进您的创作内容。例如,通过分析嵌入向量,您可以识别文本中的关键概念和主题,并根据这些信息调整创作内容,使其更加符合您的目标或更接近参考模型的风格。同时,您还可以结合其他创作工具、编辑策略和反馈来进一步优化您的内容。
2.2这些模型如何应用到我的创作中?
- GPT-embedding:您可以使用GPT-embedding来为您的文本生成高质量的嵌入表示,这些嵌入可以用于各种自然语言处理任务,如文本分类、情感分析等。此外,GPT-embedding还支持多种语言,包括中文,这使得它非常适合国际化的创作场景。
- 文心千帆 Embedding-V1:文心千帆 Embedding-V1是一种基于云雀模型开发的文本嵌入服务,它可以为您的文本数据生成丰富的语义特征。这些特征可以用于构建推荐系统、内容审核、广告投放等多个领域。此外,文心千帆提供了友好的API接口,方便开发者将其集成到自己的应用程序中。
- 通义千问 text-embedding-v1:通义千问 text-embedding-v1是基于通义千问模型开发的文本嵌入服务,它能够为您的文本数据生成高维度的语义表示。这些表示可以用于机器翻译、问答系统、文本生成等多个领域。此外,通义千问还提供了丰富的API接口和在线演示功能,使您能够轻松地将其集成到自己的项目中。
2.3FastGPT系统可视化界面
FastGPT 是一个基于大型语言模型(LLM)的知识库问答系统,它提供了数据处理、模型调用等能力,并支持通过 Flow 可视化进行工作流编排,以实现复杂的问答场景。以下是 FastGPT 的几个主要特点和功能:
专属 AI 客服:FastGPT 允许您通过导入文档或已有问答对来训练 AI 模型,使其能够根据您的文档以交互式对话方式回答问题。
简单易用的可视化界面:FastGPT 提供直观的可视化界面设计,通过简洁易懂的操作步骤,可以轻松完成 AI 客服的创建和训练流程。
自动数据预处理:支持多种数据导入途径,如手动输入、直接分段、LLM 自动处理和 CSV 等,可以自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能。
工作流编排:基于 Flow 模块的工作流编排,可以帮助设计更加复杂的问答流程,例如查询数据库、查询库存、预约实验室等。
强大的 API 集成:FastGPT 的 API 接口对齐了 OpenAI 官方接口,可以直接接入现有的 GPT 应用,也可以轻松集成到企业微信、公众号、飞书等平台。
FastGPT 遵循 Apache License 2.0 开源协议,允许二次开发和发布。它适用于 chatgpt 爱好者、深度使用者、想要构建自己的 AI 知识库的用户,以及想要提供 GPT 服务的公司或组织。
FastGPT 还提供了安装指南和环境需求,例如在 Windows 或 Linux 系统上搭建 docker 环境,以及获取 API keys 和搭建 nginx 服务器等。
总的来说,FastGPT 是一个强大且易于使用的工具,适合需要构建基于大型语言模型的知识库问答系统的用户
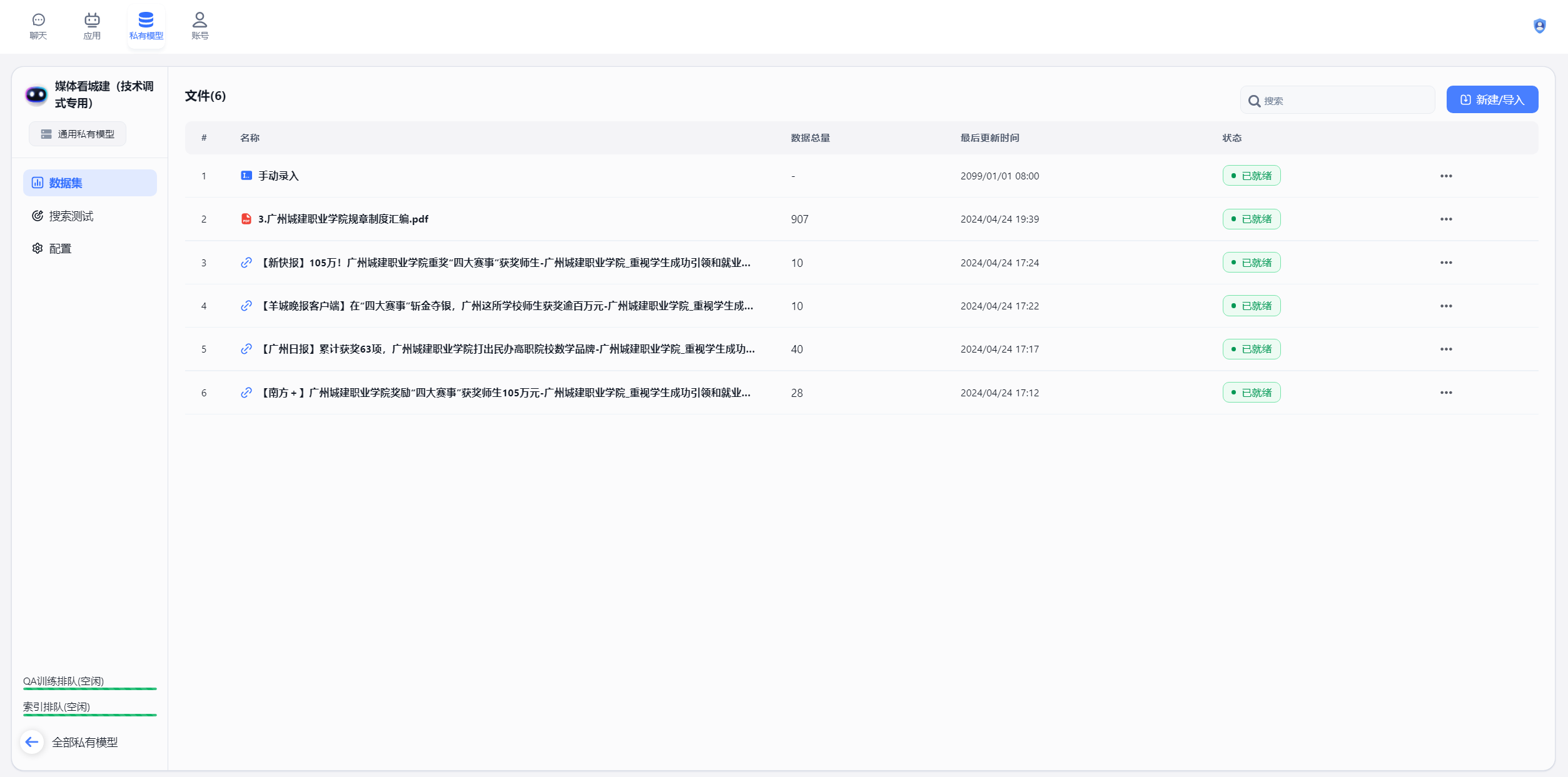

2.4 如何将它们应用于您的创作中?
要操作这些模型并将它们应用于您的创作中,您需要遵循以下步骤:
选择模型和平台:
- 根据您的需求选择合适的模型,如GPT-embedding、文心千帆或通义千问。
- 选择一个提供这些模型的平台,如百度AI、阿里巴巴云等。
注册账户和创建项目:
- 如果您还没有账户,需要注册一个账户。
- 在平台上创建一个新项目,以便管理您的API调用和费用。
获取API密钥:
- 通常,您需要创建一个API密钥来访问模型服务。
- 保存好您的API密钥,因为它们用于验证API请求。
编写代码调用API:
- 如果您是开发者,可以使用Python、Java、C#等编程语言来调用API。
- 如果您不是开发者,可以查找是否有现成的应用程序接口(API)调用的示例代码或使用图形用户界面(GUI)工具。
集成到创作流程:
- 将模型API集成到您的创作流程中,例如在写作时实时获取文本的嵌入表示。
- 或者,您可以使用模型来增强创作过程,例如通过分析文本数据来提供创作灵感或优化内容。
测试和优化:
- 在实际应用中测试模型的性能,确保它满足您的需求。
- 根据测试结果调整模型参数或选择其他模型。
管理和监控:
- 定期检查API使用情况,确保您不会超出服务提供商的配额限制。
- 监控模型的性能,确保它在不同的创作场景中都能稳定运行。
请注意,具体的操作步骤可能会根据您选择的模型和平台而有所不同。建议您查看所选模型的官方文档或联系技术支持以获取更详细的指导。
2.5如何根据模型提供的嵌入向量来改进我的创作内容?
根据模型提供的嵌入向量来改进您的创作内容,您可以遵循以下步骤:
理解嵌入向量:
- 嵌入向量是一组数值,它们代表了文本中的词语或句子在某种特定空间中的位置。
- 这些向量可以捕捉词语的语义信息,例如它们在上下文中的含义和关联。
分析嵌入向量:
- 使用嵌入向量分析工具或方法来理解每个词语或句子在向量空间中的位置和关系。
- 分析嵌入向量可以帮助您识别文本中的关键概念和主题。
对比参考模型:
- 如果您有其他参考模型或基准,可以对比分析它们的嵌入向量,以了解您的创作内容在哪些方面与参考模型相似或不同。
优化创作内容:
- 根据嵌入向量的分析结果,您可以调整创作内容,使其更加符合您的目标或更接近参考模型的风格。
- 例如,如果您的创作内容在某个主题上的嵌入向量与参考模型有较大差异,您可以增加相关内容以提高相似度。
持续迭代:
- 创作是一个迭代的过程,您可以多次使用模型提供的嵌入向量来评估和优化您的内容。
- 随着创作内容的不断改进,嵌入向量也会相应地发生变化,反映内容的改进。
结合其他工具和策略:
- 您可以结合其他创作工具、编辑策略和反馈来进一步优化您的内容。
- 例如,使用拼写检查器、语法校正工具和用户反馈来提高内容的质量和吸引力。
通过以上步骤,您可以利用模型提供的嵌入向量来指导您的创作过程,并持续优化内容以达到更好的效果。

参考文章1:https://blog.csdn.net/v_july_v/article/details/135311471
参考文章2:https://juejin.cn/post/7283724142323417088?searchId=20240118100201E9D9C26B90403A8EF198#heading-4


















 2473
2473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











