







 本文介绍了移动设备GPU优化的关键点,包括减少顶点数目、降低处理的片元数目、节省带宽以及减少计算复杂度。针对PowerVR芯片的基于瓦片的延迟渲染架构,提出了优化建议,如使用LOD技术、遮挡剔除、控制渲染顺序和减少纹理大小。此外,还讨论了CPU的draw call优化和GPU的shader LOD,强调了批处理技术在减少draw call中的作用,以及各种内存和计算资源的管理策略,以提高游戏性能和流畅度。
本文介绍了移动设备GPU优化的关键点,包括减少顶点数目、降低处理的片元数目、节省带宽以及减少计算复杂度。针对PowerVR芯片的基于瓦片的延迟渲染架构,提出了优化建议,如使用LOD技术、遮挡剔除、控制渲染顺序和减少纹理大小。此外,还讨论了CPU的draw call优化和GPU的shader LOD,强调了批处理技术在减少draw call中的作用,以及各种内存和计算资源的管理策略,以提高游戏性能和流畅度。
和PC平台相比,移动平台上有GPU架构有很大的不同。资源处理等条件的限制,移动设备上的GPU架构专注于尽可能使用更小的带宽和功能。尽可能移除那些隐藏的表面,减少overdraw(即一个像素被绘制多次),PowerVR芯片(移动设备)使用基于瓦片的延迟渲染(tiled-based Deferred Rendering,TBDR)架构,把所有渲染图像装入一个个瓦片中,再由硬件找到可见的片元,而只有这些可见片元才会执行片元着色器。由于芯片架构不同,需要对不同的芯片发布不同的版本,以便针对每个芯片进行更针对性的优化。
影响性能的因素:
GPU主要负责分辨率和CPU负责帧率,
CPU:
- 过多的draw call
- 复杂的脚本或物理模拟
GPU
- 顶点处理:过多的顶点;过多的逐顶点计算
- 片元处理:过多的片元(分辨率或overdraw造成);过多逐片元计算
带宽
- 使用了尺寸很大且未压缩的纹理
- 分辨率过高的帧缓存
对于CPU来说,限制它的主要是draw call的数目,每次通知GPU渲染之前,都需要把准备好的顶点数据(位置、法线、颜色、纹理等),调用一些列API把它们放在GPU可以访问的位置,最后调用一个绘制命令,即产生一个draw call。每次调用时CPU需要改变很多渲染状态的设置,都是非常耗时的,若一帧中调用过多的draw call,会导致CPU大部分时间都花费在提交draw call上。
对GPU来说,它负责整个渲染流水线,处理cpu传过来的模型数据开始,进行顶点着色器、片元着色器等一些列工作,最后输出到屏幕的每个像素,处理顶点数目、屏幕分辨率、显存等,优化策略:减少处理数据的规模、减少运算复杂度等。
cpu优化:
- 使用批处理技术减少draw call
gpu优化
- 减少处理的顶点数目:优化几何体、使用模型的LOD(level of Detail)技术、使用遮挡剔除(Occlusion Culling)技术
- 减少需要处理的片元数目:控制绘制顺序、警惕透明物体、减少实时光照
- 减少计算复杂度:使用Shader的LOD(Level of Detail)技术、代码方面的优化
节省内存带宽
- 减少纹理大小
- 利用分辨率缩放
渲染分析工具:渲染统计窗口(Rendering Statistics Window)、Profiler、Frame Debugger。
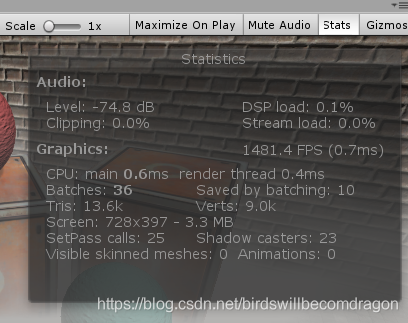
FPS(Time per frame andFPS):frames per seconds表示引擎处理和渲染一个游戏帧所花费的时间,该数字主要受到场景中渲染物体数量和 GPU性能的影响,FPS数值越高,游戏场景的动画显示会更加平滑和流畅。一般来说,超过30FPS的画面人眼不会感觉到卡,由于视觉残留的特性,光在视网膜上停止总用后人眼还会保持1/24秒左右的时间,因此游戏画面每秒帧数至
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









