






一、CLIP
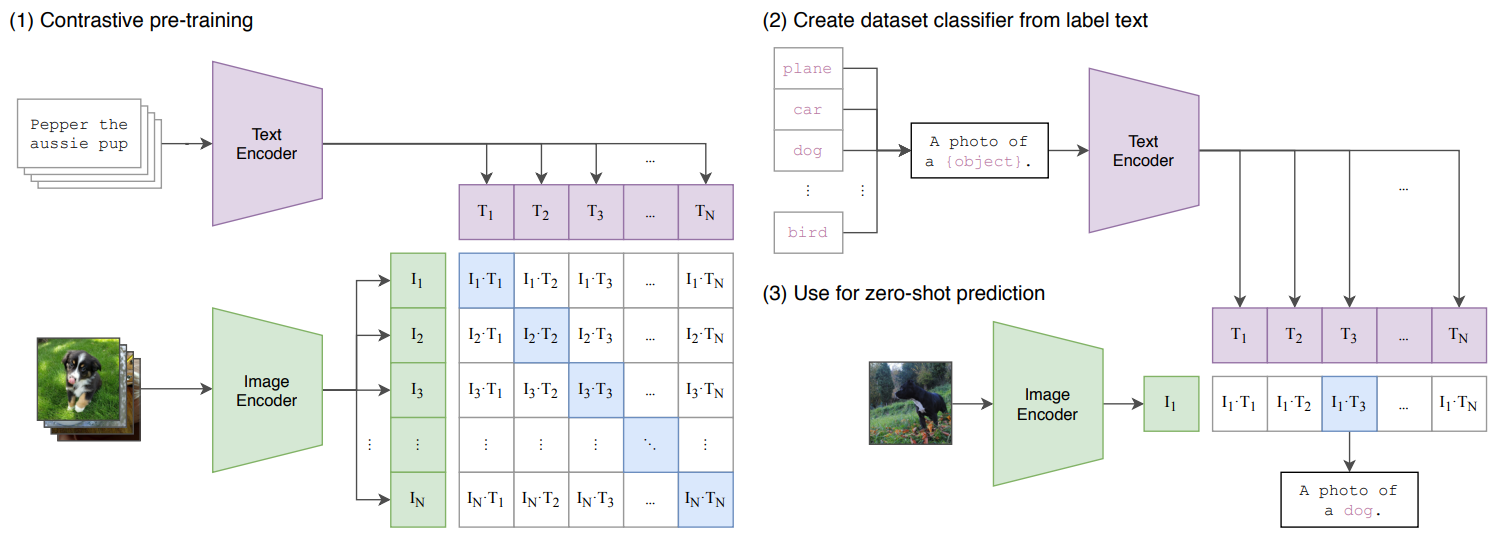
Learning Transferable Visual Models From Natural Language Supervision
CLIP是用对比学习的方式去训练一个视觉-语言的多模态模型
二、分割
LSeg (language-driven semantic segmentation)
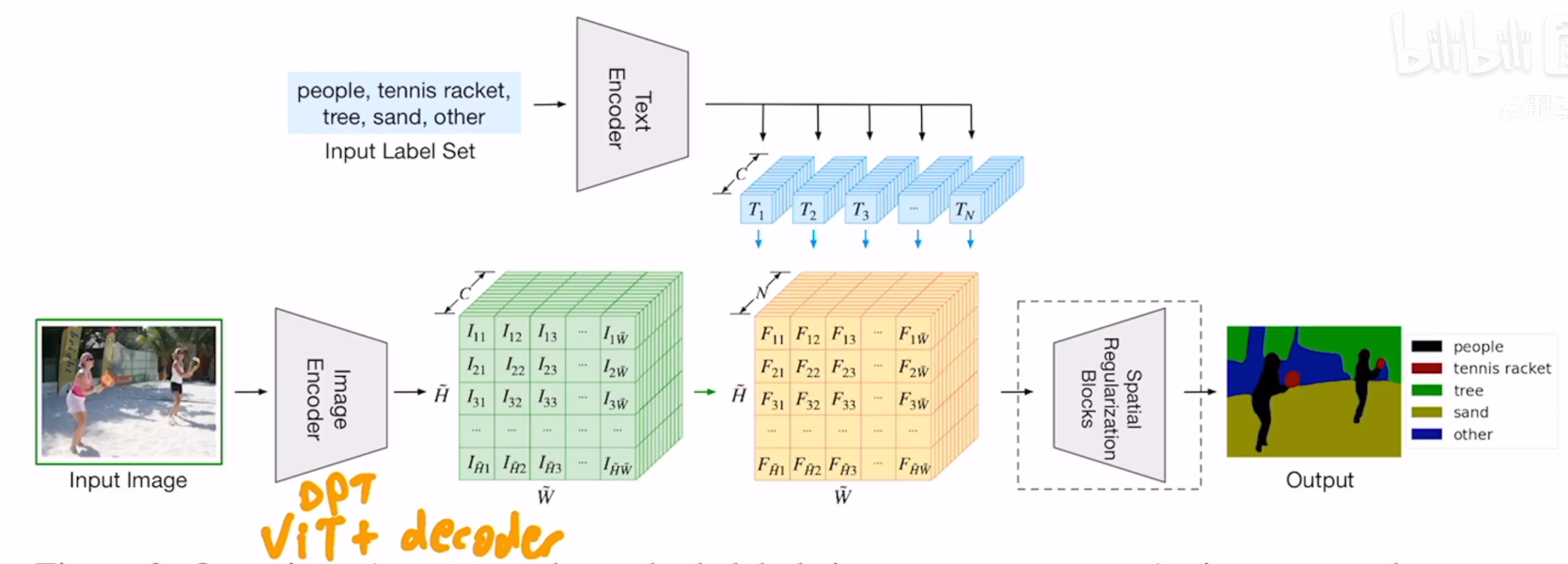
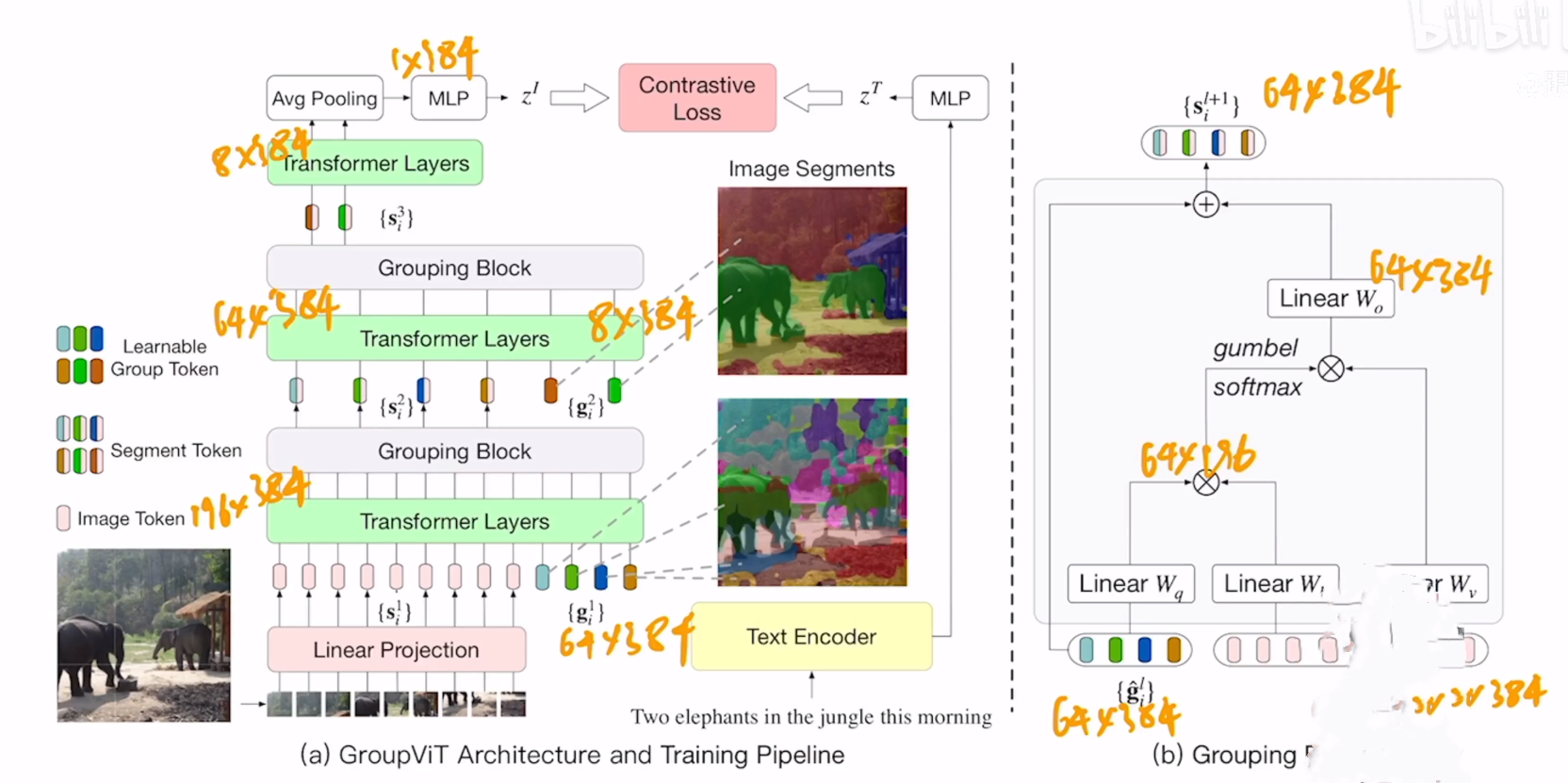
GroupViT (semantic segmentation emerges from text supervision)
Learning Transferable Visual Models From Natural Language Supervision
CLIP是用对比学习的方式去训练一个视觉-语言的多模态模型
 6215
3809
6215
3809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























