








©PaperWeekly 原创 · 作者 | 张剑清
单位 | 上海交通大学
本文介绍的是我们的一篇收录于 NeurIPS 2023 的论文。我们设计了一个领域偏差消除器(DBE)来解决联邦学习(FL)中的数据异构问题。该方法可以提升服务器-客户机之间的双向知识迁移过程,并提供了理论保障,能够在泛化能力和个性化能力两个方面进一步为其他联邦学习方法带来提升。
大量实验表明,我们可以在各种场景下为传统联邦学习方法实现最多 22.35% 的泛化能力提升,而且 FedAvg+DBE 能在个性化方面比现有的 SOTA 个性化联邦学习(pFL)方法高了 11.36 的准确率。

论文标题:
Eliminating Domain Bias for Federated Learning in Representation Space
论文链接:
https://arxiv.org/pdf/2311.14975.pdf
代码链接:
https://github.com/TsingZ0/DBE(含有PPT和Poster)
https://github.com/TsingZ0/PFLlib

联邦学习简介
不论是隐私保护的需求还是在数据财产保护的需要,将本地的私有数据进行外传都是需要尽量避免的。联邦学习是一种新型的分布式机器学习范式,它能够在保留数据在本地是前提下,以中央服务器作为媒介,进行多个客户机(设备或机构)间的协作学习和信息传递。
在联邦学习过程中,参与协作学习的客户机之间约定一种信息的传递方式(一般是传递模型参数),并以该方式进行一轮又一轮的迭代,实现本地模型(和全局模型)的学习。每一轮传递的信息,作为一种外部信息,弥补了单一客户机独自学习时本地数据不足的问题。
区别于传统的分布式机器学习范式,在联邦学习(如 FedAvg [1])中,由于各个客户机的本地数据不能进行操作和修改,没有办法保证每个客户机上的数据的分布是一致的,于是导致了关键的“数据异质性(或统计异质性)问题”。我们用下图描述了联邦学习过程,其中不同的颜色代表不同的数据分布。
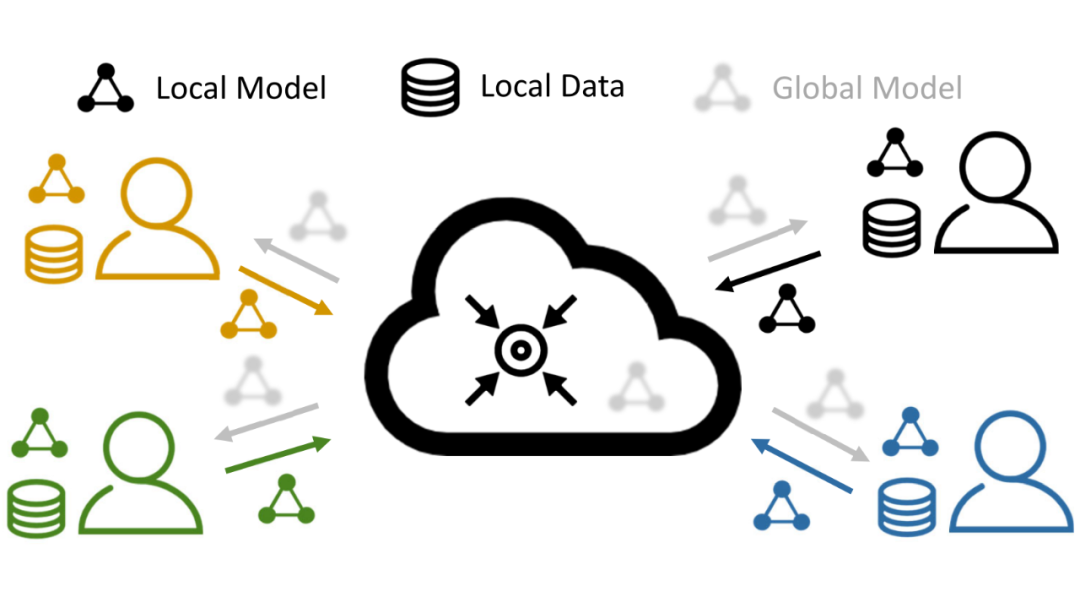
▲ 图1:联邦学习及其数据异质性问题

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









