








强化学习的核心目标是通过不断调整策略(即根据当前状态选择动作的规则),使智能体表现得更好。在强化学习中,有几个关键元素至关重要:首先是奖励模型和价值函数,它们用于评估每个动作或策略的优劣,从而决定模型优化的方向;其次是更新规则,主要涉及损失函数的约束项,它决定了策略更新的力度和稳定性。
本文首先介绍了三类基础的强化学习算法,这三类算法主要在奖励计算和更新规则上有所不同,是 RLHF(人类反馈强化学习)的核心。接着,重点讨论了四种改进方法:REINFORCE、RLOO、PRIME 和 REINFORCE++,它们通过引入 EMA、在线采样、过程奖励等技术,使奖励更加无偏并提高密集成都。
最后,介绍了 GRPO(Group Relative Policy Optimization)方法,它在奖励函数的计算和策略更新规则上做出了进一步的改进,以提升训练的稳定性和效率。

Policy Gradient
最早的 Policy Gradient Methods 就是直接优化策略的一种方法。简单来说,策略梯度方法通过计算“策略梯度”(表示如何调整策略模型以提升表现)来更新策略,从而让智能体在长期内获得更高的奖励。
具体步骤是:
1. 计算策略梯度:通过当前策略和动作的效果(优势函数),我们可以计算出一个梯度(action 对于 policy model 的梯度),告诉我们如何调整策略。
2. 优化策略:通过梯度上升的方法调整策略参数,以提升智能体的表现。
3. 反复更新:这个过程是一个反复的采样和优化过程,每次都会根据新的数据调整策略。
策略梯度的定义如下所示:
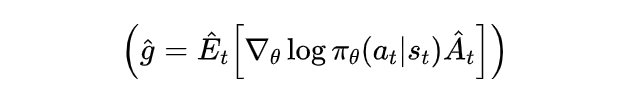
表示在状态 下,采取动作 的概率, 是策略的参数,控制策略的行为。
是策略梯度,表示策略参数变化时,策略的行为(即动作选择概率)如何变化。
是优势函数的估计值,它表示动作 相对于当前策略的“好坏”。如果 ,说明该动作相较于平均水平是好的,应该增加这种动作的概率;如果 ,则说明该动作不好,应该减少其概率。
表示对多个样本的平均,意思是我们在进行多次实验后,计算这个期望值。
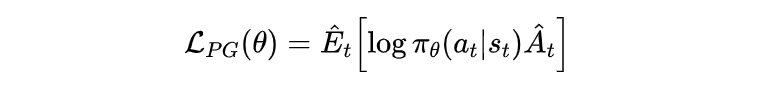
这是我们的目标函数,我们希望最大化这个目标。简而言之,就是通过调整策略参数 ,使得智能体选择的动作(那些优势高的动作)变得更加可能。
对于 LLM,也就是直接将 outcome reward 作为每个 token 的 advantage。例如有两个 sample,分别为错误和正确,第一个 sample 有 5 个 token,它的 advantage 矩阵为 [0,0,0,0,0];第二个 sample 有 6 个 token,它的 advantage 矩阵为 [1,1,1,1,1,1],不断提升正确样本的 token 概率。
这里的问题在于,如果我们对同一批数据做多次优化,可能会导致策略的更新过大(比如参数调整过猛)。这样会使得策略发生剧烈变化,导致性能反而变差。因此,过度更新会导致学习不稳定。

TRPO (Trust Region Policy Optimization)
TRPO(Trust Region Policy Optimization)是一种改进的策略优化方法,核心思想是限制策略更新的幅度,避免策略变化过大导致学习不稳定。简单来说,TRPO 通过引入“信赖区域”的概念,确保每次更新后的策略不会偏离旧策略太远,从而保证学习过程的平稳性。他的目标函数如下所示:
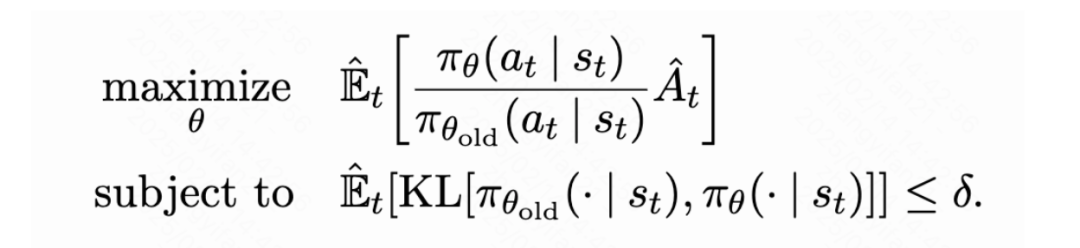
通过最大化这个目标函数,TRPO 试图找到一种策略,使得新策略在优势动作上的概率更高。同时,KL 散度用于衡量当前策略和旧策略之间的差异。这个约束确保了策略的更新不会过于激进。
当然直接求解这个问题是很困难的,TRPO 在其具体实现中做了一步近似操作来快速求解,作者对目标和约束进行了泰勒展开,并分别用一阶和二阶进行近似,最后得出的结果需要用到 hessian 矩阵 H 和 g(目标函数对 policy 的梯度)。
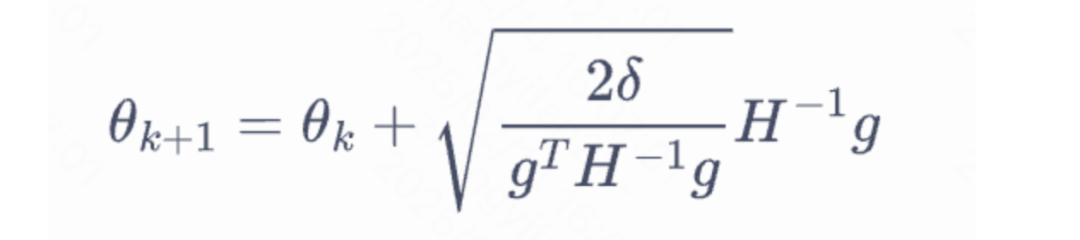
这对于 LLM 来说是不可接受的,因此作者又用了共轭梯度的方法避免存储 hessian 矩阵,总体优化比较复杂,而且因为 KL 散度和优化目标都是泰勒近似,很难保证 KL 散度的约束一定被满足。因此每一轮迭代 TRPO 还要通过先行搜索找到一个整数 i 来强行使得 KL diververge
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









