






 文章探讨了多模态大模型在架构、训练数据和过程方面的关键因素,包括不同视觉编码器、数据组合方式和训练方法的优化。Mini-Gemini通过高分辨率编码增强模型性能,同时采用参数高效微调方法减少对图像数据的依赖。
文章探讨了多模态大模型在架构、训练数据和过程方面的关键因素,包括不同视觉编码器、数据组合方式和训练方法的优化。Mini-Gemini通过高分辨率编码增强模型性能,同时采用参数高效微调方法减少对图像数据的依赖。
一. 影响多模态LLM性能的因素
观点来源:《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》
作者从模型结构,训练数据的训练过程三个方面进行讨论。
模型架构:此处主要探索不同的预训练的图像编码器和连接llm和图像编码器的不同方式对模型性能的影响。
训练数据:此处讨论不同类型的训练数据和其混合权重对模型性能的影响。
训练过程:此处探讨如何训练MLLM,包括超参数,以及在那个阶段训练模型的哪些部分。
1. 模型架构
该部分主要探讨(1)如何更好的预训练一个视觉编码器。(2)如何将视觉特征连接到LLM的空间中。
针对目的1,作者做了一系列实验,结果如下图所示。从实验结果中可以得到结论:图像分辨率对模型的性能影响最大,其次是模型大小和训练数据的组成。
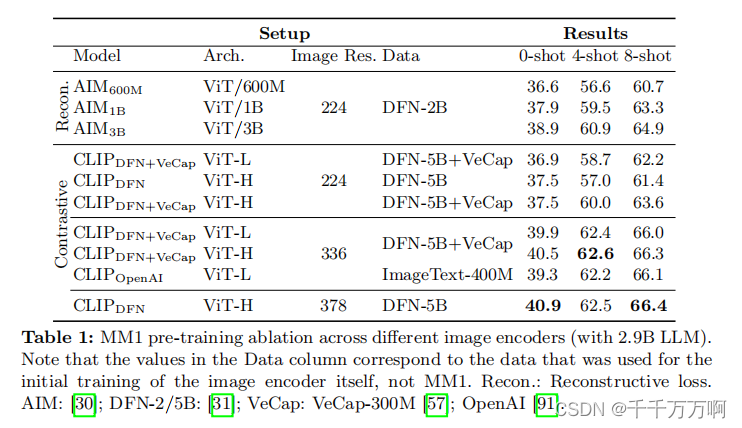
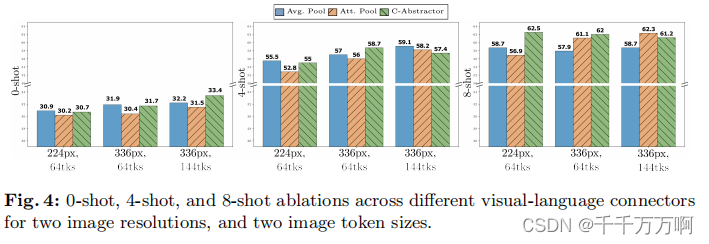
针对目的2,作者同样做了一系列实验,结果如下图所示。从实验结果中可以得到结论:视觉令牌的数量和图像分辨率最重要,而VL连接器的类型对性能影响不大。
2. 训练数据
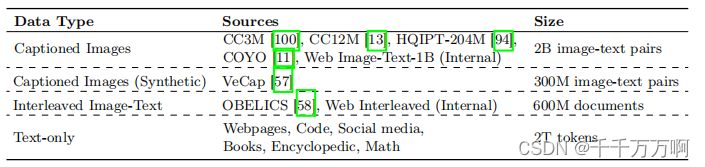
MLLM的训练可以分为两个阶段,预训练和指令调优。该部分主要关注预训练阶段的数据选择对模型性能的影响。下表展示了作者所使用的三种不同类型(Image-text pair(caption), Interleaved Image-Text, Text-only)的训练数据集。
下表展示了作者在不同的数据配比下的性能。
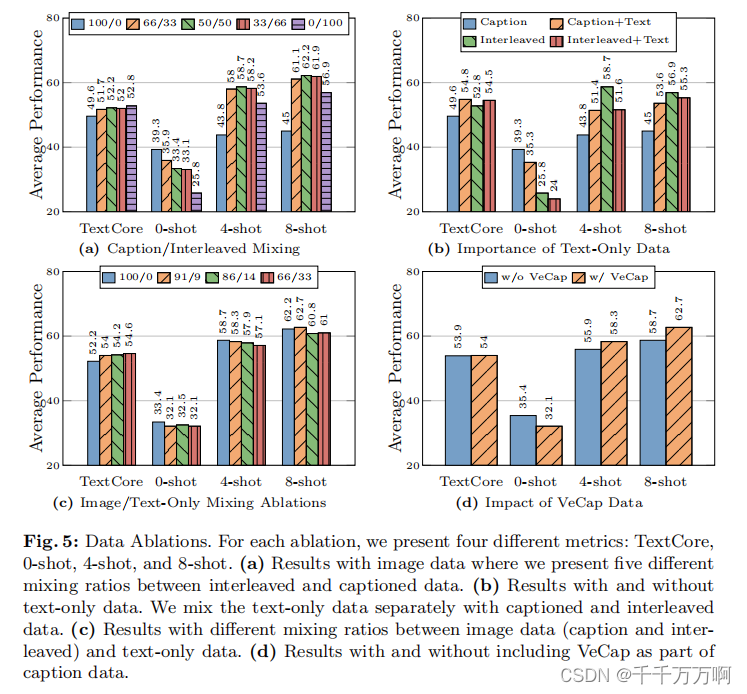
根据上述实验结果,可以得到如下结论:
1. Interleaved Image-Text数据有助于few-shot和text-only的性能,而Image-text pair(caption)提高zero-shot性能。
2. text-only数据有助于提高zero-shot和text-only任务的性能。
3. 将文本数据(text-only)和多模态数据(Image-text pair(caption), Interleaved Image-Text)可以在保持文本性能的同时产生最佳的多模态性能。
这里作者提出当caption/interleaved/text 三种训练数据的比率是 5:5:1时可以更好的平衡文本和多模态性能。
4. 合成数据(VeCap)有助于few-shot性能的提升。合成数据具有更高的质量。
3. 训练过程
3.1 模型缩放(如何根据参数量选择学习率和权值衰减率)
作者在不同大小的模型上进行了不同学习率的实验,结果如下图所示:

拟合上述曲线后,可以得到学习率的生成公式:
![]()
这里,代表学习率,N代表参数量(non-embedding)。(此处N仅代表可训练的参数量吗?暂时没搞懂)
权值衰减率的公式为:
作者发现,通过上述公式获得的权值衰减率对所有模型都很适用。
3.2 多模态预训练结果
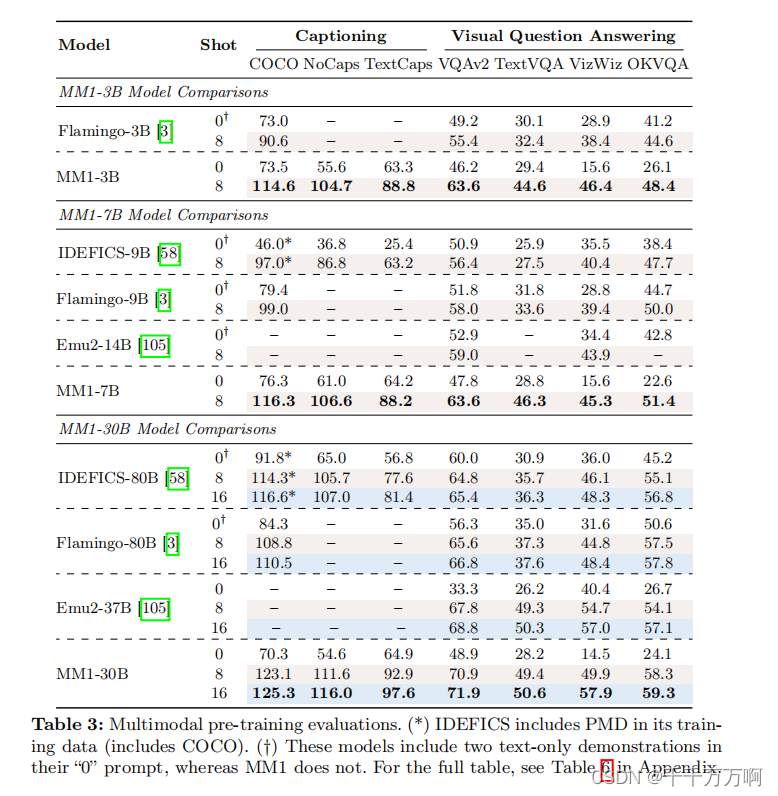
从结果中可以看到,本文提出的MM1模型在同尺度的模型中还是不错的。说明上述方法很有效。
二. 参数高效微调方法学习(Parameter-Efficient Fine-Tuning)
这部分主要介绍一下应用在多模态大模型领域的PEFT方法。(持续学习中)
1.《TOMGPT: Reliable Text-Only Training Approach for Cost-Efective Multi-modal Large Language Model 》
动机:
该论文作者认为现有的多模态大模型在训练时需要大量的图像文本对,而高质量的图像文本对相对于纯文本来说是更难获取的,因此提出了一种只使用文本数据来训练多模态大模型的方法。
方法:
图1为模型结构. 在此处作者首先使用ChatGPT来生成训练数据(纯文本),随后将生成的训练数据通过CLIP Text Encoder进行编码获取图像特征T,随后通过Projection映射到LLM所在的向量空间中。最后输入给LLM获得最终的输出。 此处的介绍不够直观,我们来看下一副图。
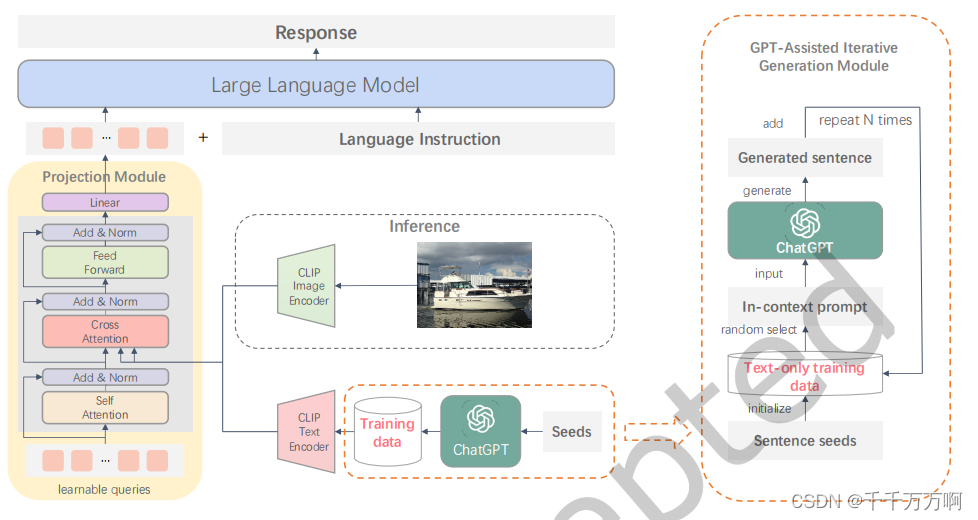
下图展示了作者预训练,微调和推理三个不同阶段的设置。
预训练阶段:作者冻结了CLIP-Text Encoder和LLM只训练Projection的参数。该阶段的任务是让LLM能够正确理解CLIP-Text Encoder和Projection处理后的文本信息,因此输入和label是同样的文本。(这种设置使的模型可以使用任意的文本信息进行训练,扩大了训练数据的种类)
微调阶段:同样只训练Projection的参数。该阶段的任务是让LLM根据输入的文本信息回答对应的问题(可以理解为一个QA任务)。
推理阶段:再该阶段,只需要将CLIP-Text Encoder替换为CLIP-Image Encoder即可让模型可以接收图片输入。
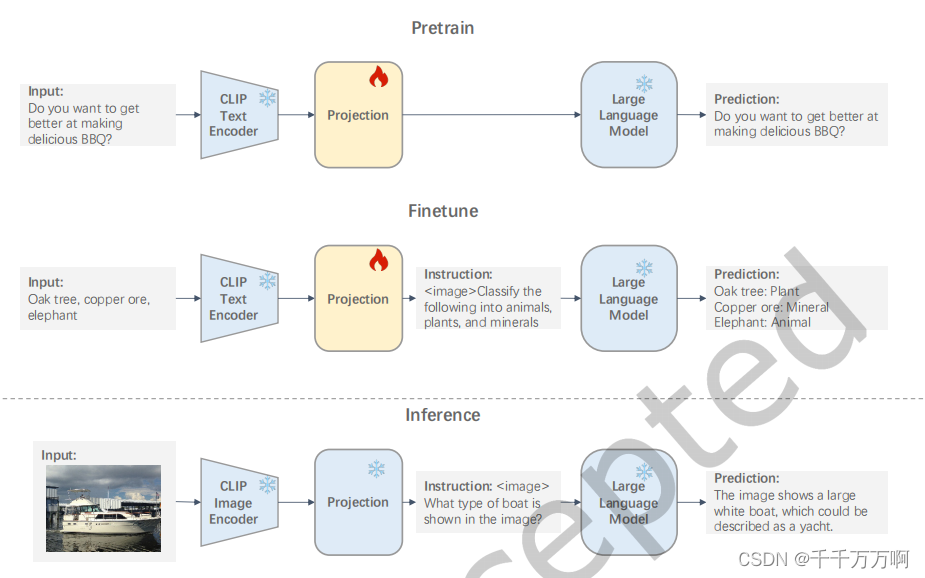
利用ChatGPT构造训练数据的方法:
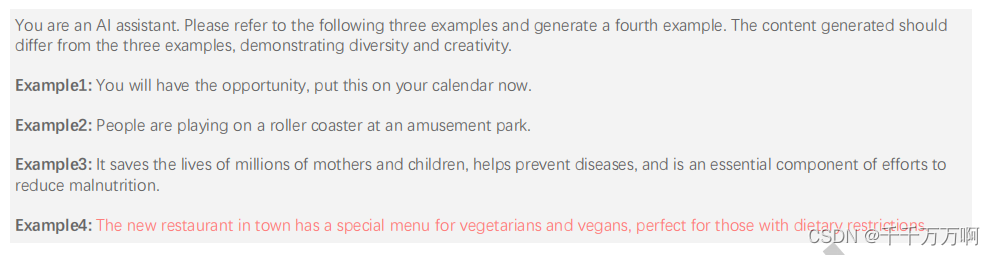
方法如上图所示,先随便举出3个例子,然后利用GPT让其生成一类结构类似但内容不同的例子。随后再从4个例子中随机抽取3个例子重复上述操作。
分析:
该方法之所以有效得益于两个巧妙的设计:1. 将图文对齐的任务替换为文本映射的任务,减弱了数据异构造成的负面影响。2.利用了CLIP模型强大的图文对齐能力。
正是因为CLIP模型强大的图文对齐能力使得模型在推理阶段只需要将编码器替换为CLIP Image Encoder就可以直接使用,而不需要再次对Projection模块进行训练。
三. 多模态大模型的优化方法
1.《Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models》
动机:
作者认为现有的VLMs与GPT-4和Gemini等高级模型相比,性能之间仍然存在差距。因此作者试图从高分辨率的视觉令牌,高质量的数据和vlm引导生成三方面来缩小差距。
方法:
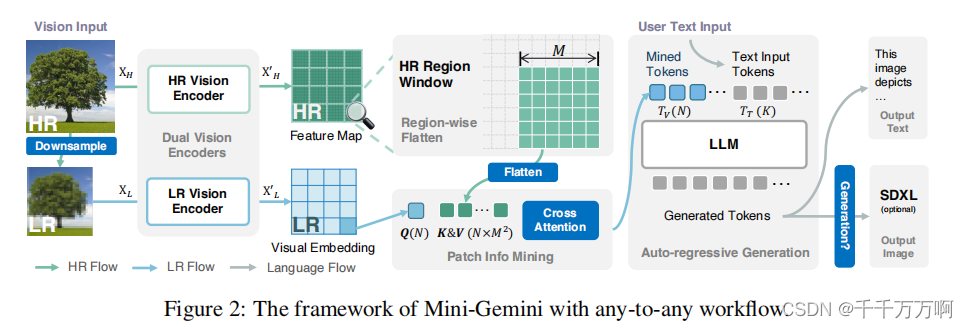
模型结构如上图所示。总的来说Mini-Gemini框架相对简单;他首先利用双视觉编码器来获取低分辨率编码和高分辨率编码;随后使用低分辨率编码生成Q,高分辨率编码生成K&V,进行注意力计算(文中称这一块为Patch Info Mining)。最后将图像编码和文本编码结合后输入给LLM进行理解和生成。
双视觉编码器:低分辨率编码器为CLIP-pretrained ViT, 高分辨率编码器为ConvNeXt。(此处相对简单就不进行详细介绍了)
Patch Info Mining:在该部分作者为了保证LLM中视觉令牌的数量不变,同时增强视觉标记的潜力,作者在此处利用低分辨率编码作为查询Q,利用高分辨率编码生成K和V。这里的公式表达如下:
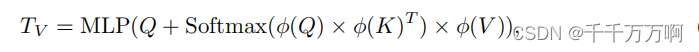
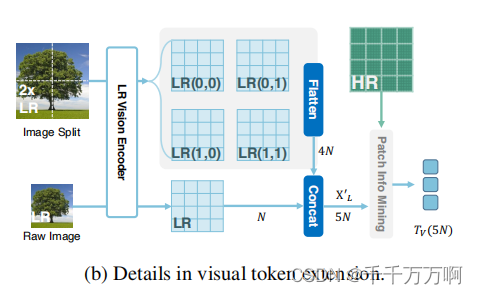
此为作者也提供了一种扩展视觉令牌数量的方法,如下图所示。该方法通过合并原始图像和它的2X图像,从而将原始的视觉令牌数量翻5倍。
文本图像生成:文本生成很简单,就是将视觉令牌和文本令牌连接起来输入到LLM即可获得文本。对于图像生成,该模型首先将用户指令转换为高质量的提示,随后利用扩散模型根据模型输出的提示生成高质量图片。
数据构造:暂时对数据的构造不是很感兴趣所以不做过多的介绍。(该部分还是有很多可去之处,需要的可以到原论文中了解。)
实验结果:
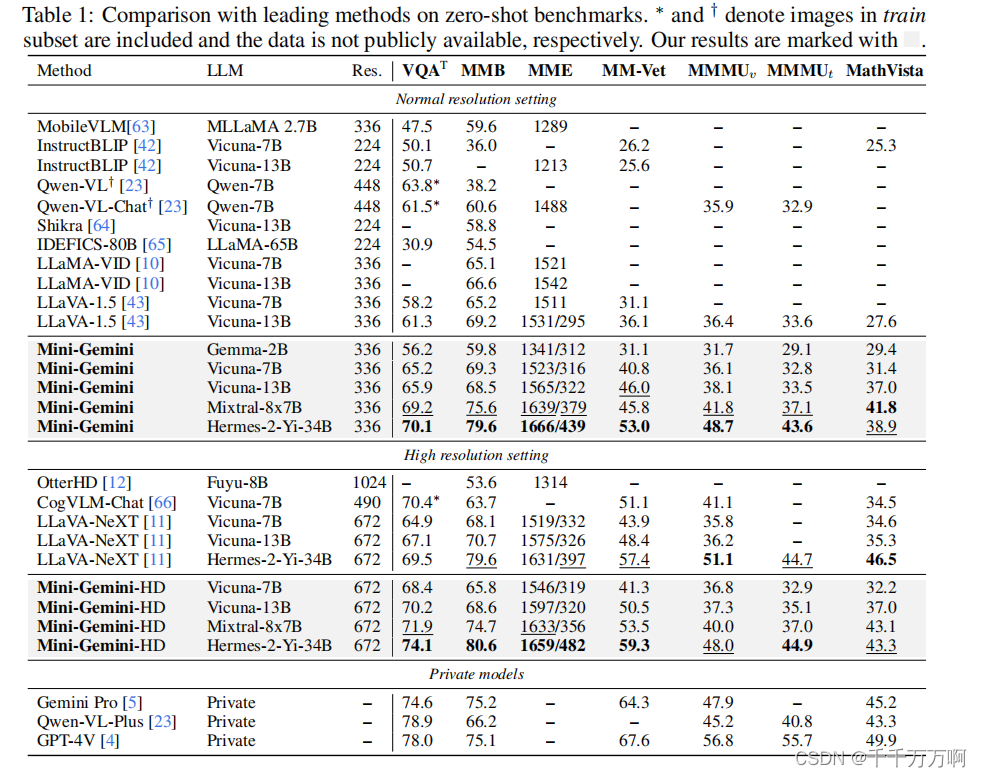
从上述对比实验中可以看出,模型性能还是很强的。
零部件实验:
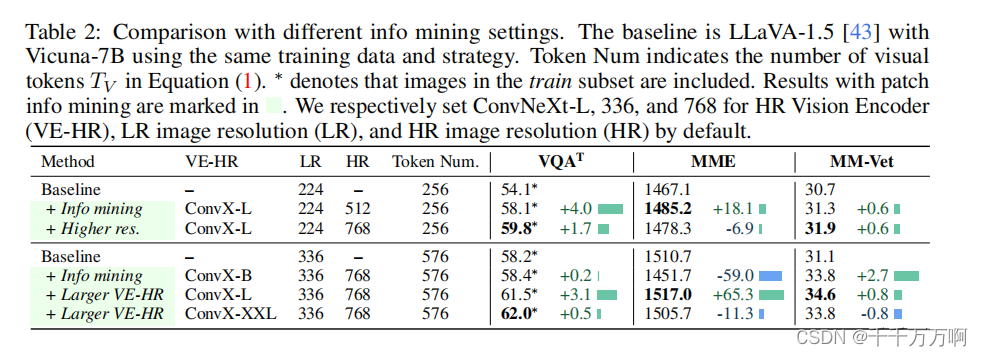
这部分实验主要探讨Patch Info Mining部分。从上述结果中可以看出,添加高分辨率编码器和增加图像分辨率的确能够提升模型性能。(因为高分辨率的图像能够提供更多的细节信息)
不同训练数据的实验:
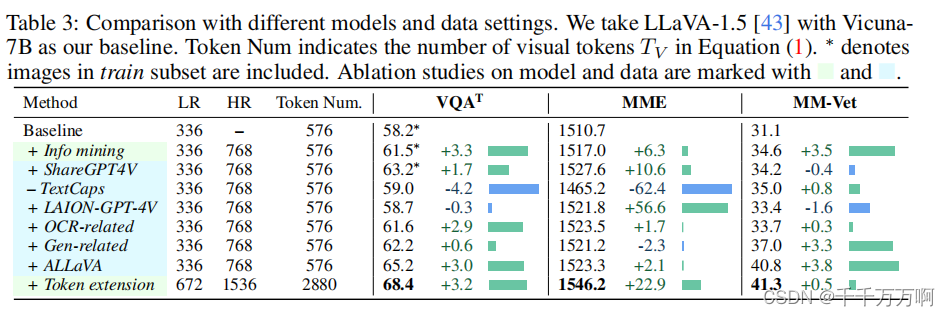
定性结果:
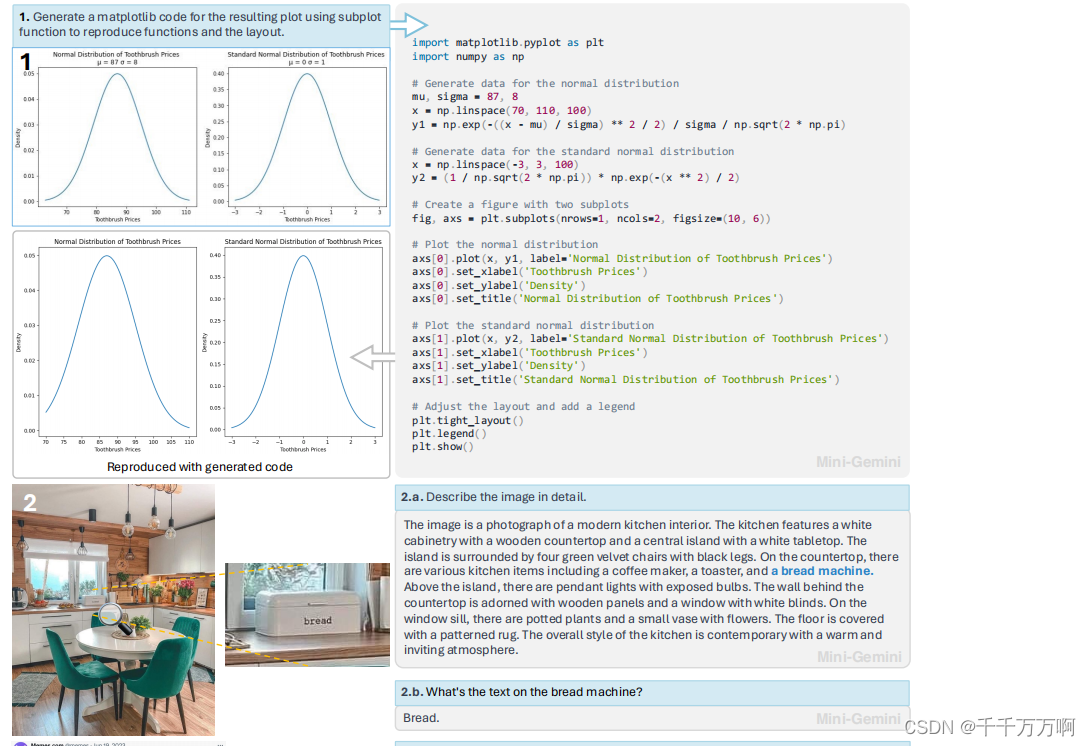
 总的来说效果很好。
总的来说效果很好。
分析:
我认为该文章主要的工作有两点(数据构造暂时除外):(1)利用高分辨率特征来对低分辨率特征打补丁。(2)给VLM外接了生成模型。
(1)利用高分辨率特征来对低分辨率特征打补丁
这样做的目的是什么?
文中有提到,这样做的主要目的是为了在不显著增加视觉令牌数量的情况下增强其潜力。
既然都要处理高分辨率图像,为什么不直接将原始的低分辨率图像编码器替换为高分辨率编码器?
文中给的理由是:直接替换为高分辨率图像编码器可能会导致计算成本显著增加,因为处理高分辨率图像通常需要更多的计算资源。(为什么替换会增加,而添加一个额外的就不会增加计算成本?)我认为是这样的,如果将其替换那么高分辨率编码器就是“主”所以要求其性能必须强大,而仅仅作为辅助来打补丁的话,对他的要求就会适当降低。
(2)给VLM外接了生成模型
添加了一个新的任务,主要贡献是训练数据。

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









