






物理优化
物理优化对的负松弛路径执行定时驱动优化设计物理优化有两种操作模式:后地点和后路线。在后置模式中,优化是基于基于单元放置的时序估计进行的。
由于逻辑优化和根据需要放置单元格。在路由后模式中,优化是基于实际的路由延迟进行的。除了在逻辑更改和放置单元格时自动更新网表,还进行物理优化根据需要自动更新路由。
重要!路由后物理优化最有效地用于有一些失败的设计路径。在WNS小于-0.200 ns或故障超过200 ns的设计上使用路由后物理优化端点可能导致长的运行时间,而QoR几乎没有改善。
整体物理优化在后位置模式下更具侵略性逻辑优化的机会。在后路由模式中,物理优化往往更保守以避免干扰定时封闭路由。运行前,进行物理优化检查设计的布线状态,以确定使用哪种模式,张贴位置或张贴布线。如果设计没有负松弛,并且基于时序的物理优化请求优化选项时,该命令会快速退出而不执行优化。到平衡运行时和设计性能,物理优化不会自动尝试以优化设计中的所有故障路径。只考虑故障路径的前百分之几以进行优化。因此,可以使用多次连续运行的物理优化来在设计中逐渐减少故障路径的数量。
可用的物理优化
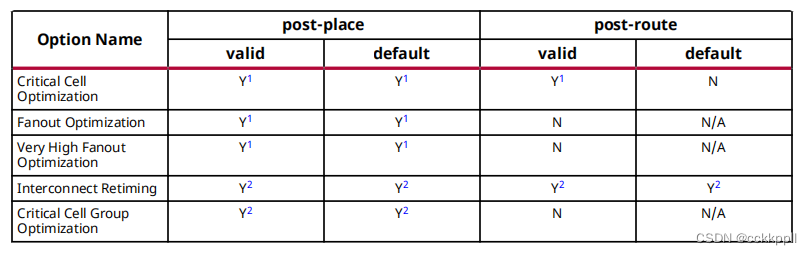
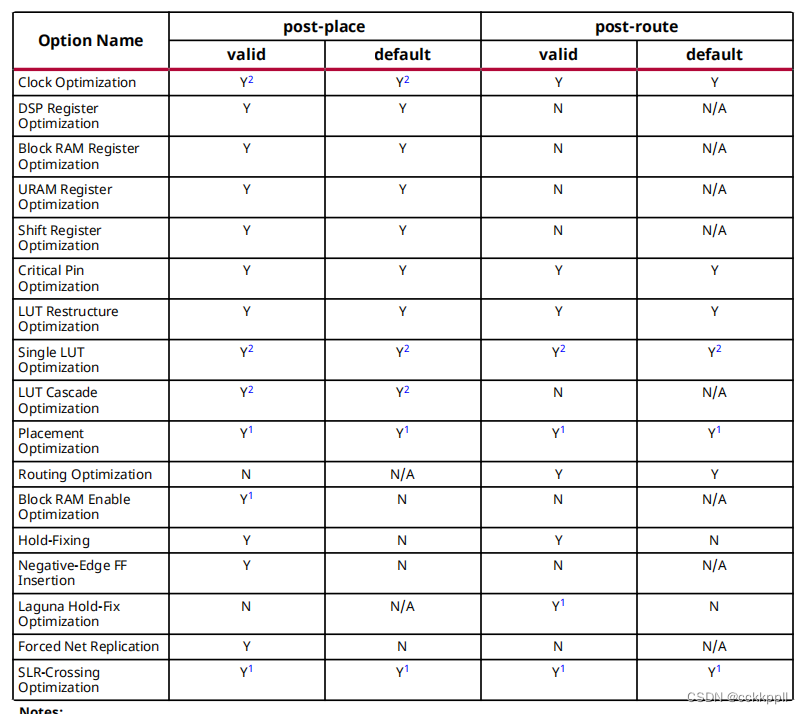
Vivado工具对内存中的设计执行物理优化,如中所示下表。
重要!物理优化可以通过选择相应的命令选项。仅运行那些指定的优化,而禁用所有其他优化,即使是那些通常默认执行的。
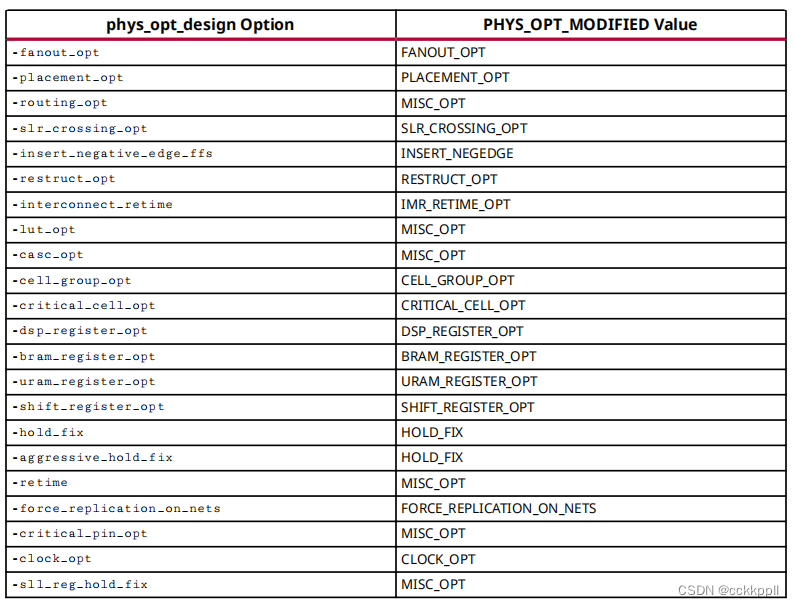
当对基元小区执行优化时,的PHYS_OPT_MODIFIED属性更新该单元以反映对该单元执行的优化。当多个在同一个小区上执行优化,PHYS_OPT_MODIFIED值包含的列表优化的顺序。下表列出了phys_opt_design触发对PHYS_OPT_MODIFIED属性和相应的更新的选项价值
扇出优化
高扇出优化的工作原理如下:
1.高扇形网,在WNS的一个百分比内具有负松弛,被考虑用于复制。
2.根据接近度对负载进行集群,并为每个负载复制和放置驱动程序簇重新分析时间安排,如果时间安排得到改善,则提交逻辑更改。
提示:通过将_replica附加到原始对象名称后,再加上已复制对象计数。
布局优化
通过重新放置关键路径中的所有单元来优化关键路径上的放置,以减少线路延迟。
路由优化
通过以较短的延迟重新路由网络和引脚,优化关键路径上的路由。
重组优化
通过交换LUT上的连接来优化关键路径,以减少逻辑级别的数量关键信号。修改LUT方程以保持设计功能。
关键单元优化
关键单元优化在故障路径中复制单元。如果将荷载放置在特定单元上相距较远的情况下,单元可能会使用放置在更靠近负载集群的位置的新驱动程序进行复制。高扇形展开不是进行此优化的要求,但路径必须失败计时,并在最差负松弛的百分比。
关键单元组优化
使用关键扇形锥组优化LUT的路径(仅适用于Versal)。
等效驱动器重新布线优化
通过将负载重新连接到等效的驱动程序来优化路径。
DSP寄存器优化
DSP寄存器优化可以将寄存器从DSP单元移到逻辑阵列中,或从如果它改善了关键路径上的延迟,则向DSP单元提供逻辑。
块RAM寄存器优化
块RAM寄存器优化可以将寄存器从块RAM单元移动到逻辑中阵列或从逻辑到块RAM单元,如果它改善了关键路径上的延迟的话。
URAM寄存器优化
UltraRAM寄存器优化可以将寄存器从UltraRAM单元移到逻辑阵列中或者如果它改善了关键路径上的延迟,则从逻辑到UltraRAM单元。
移位寄存器优化
移位寄存器优化改善了移位寄存器之间负间隙路径上的时序单元(SRL)和其他逻辑单元。
如果存在到移位寄存器单元(SRL16E或SRLC32E)或来自移位寄存器单元的定时冲突从SRL寄存器链的开始或结束处提取寄存器,并将其放入逻辑中面料,以改善计时。优化缩短了原始关键路径的导线长度。优化只将寄存器从移位寄存器移动到逻辑结构,而从不从逻辑结构移动结构转换为移位寄存器,因为后者永远不会改善时序。进行此优化的先决条件是:
•SRL地址必须是一个或多个,这样就可以移动寄存器级SRL之外。
•SRL地址必须是一个常数值,由逻辑1或逻辑0驱动。
•必须存在从SRL小区结束或开始的定时违规,该小区属于最坏的关键路径。
某些电路拓扑未优化:
•SRLC32E被链接在一起以形成更大的移位寄存器,但它们没有被优化。
•SRLC32E使用Q31输出引脚。
•SRL16E组合成一个LUT,同时使用O5和O6输出引脚。
从SRL移动到逻辑结构的寄存器是FDRE单元。FDRE和SRL INIT属性为相应地调整为SRL地址。下面是一个例子。关键路径从移位寄存器(SRL16E)srl_inste开始,如下图所示。
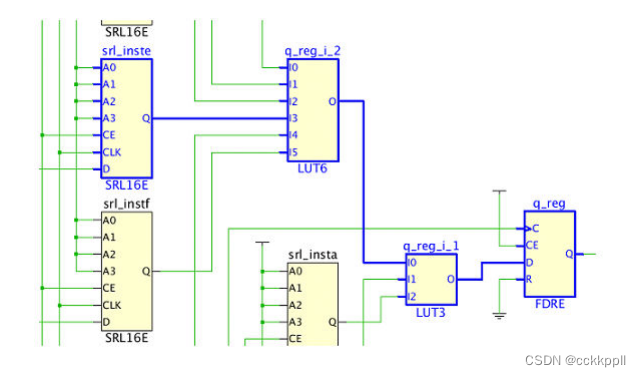
在移位寄存器优化之后,从SRL16E中取出移位寄存器的最后一级,并且放置在逻辑结构中以改进时序,如下图所示。
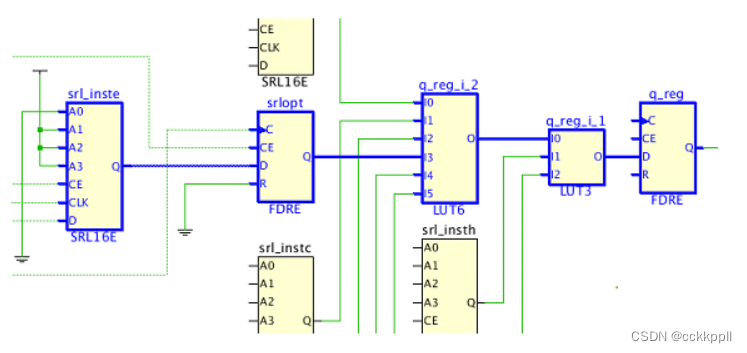
srl_inste SRL16E地址递减以反映少一个内部寄存器级。随着srlopt寄存器放置得更靠近下游,原来的关键路径现在更短了并且FDRE单元具有相对较快的时钟到输出延迟。
关键引脚优化
关键引脚优化执行逻辑LUT输入引脚到更快物理引脚的重新映射改进关键路径定时。穿过映射到慢速物理引脚的逻辑引脚的关键路径如A1或A2被重新分配给更快的物理引脚,如A6或A5。A.跳过具有LOCK_PINS属性的单元格,并且该单元格保留由指定的映射LOCK_PINS。逻辑到物理引脚映射由命令get_site_pins提供。
块RAM启用优化
块RAM启用优化改善了关键路径上的时序,包括功率优化块RAM。
预放置块RAM功率优化重构逻辑驱动块RAM读取和写使能输入以减少动态功耗。安置后,重组逻辑可能会变得至关重要。块RAM启用优化反转启用逻辑优化以改善关键使能逻辑路径上的松弛。
固定支架
Hold Fixing试图通过增加的延迟来改善高持有违规者的松懈保持关键路径。
强力固定
执行优化以插入数据路径延迟,从而修复保留时间冲突。此优化与标准保持-修复算法相比,考虑了明显更多的保持违规。
提示:保持修复仅修复超过特定阈值的保持时间冲突。这是因为路由器期望修复小于阈值的任何保持时间违规。
负边缘寄存器插入
插入负边缘触发的寄存器以修复难以保持的时间冲突。
寄存器插入
将保持关键时序路径拆分为两个半周期路径,使其更容易满足保持要求。顾名思义,只支持负边缘触发的寄存器插入这修复了两个正边缘触发的顺序单元之间的保持冲突。
互连重定时
重定时通过在组合逻辑中移动寄存器来改善关键路径上的延迟。phys_opt_design重定时优化支持前向重定时。
强制网络复制
强制网络复制强制复制网络驱动程序,而不考虑时间延迟。复制基于负载放置,需要手动分析以确定是否进行复制足够了。如果需要进一步复制,则可以通过连续的命令。尽管忽略了定时,但网络必须处于定时受限的路径中才能触发复制。
单个LUT优化
执行LUT移动/复制以改进关键路径定时。
这适用于Versal仅限设备。
LUT级联优化
执行LUT级联优化,以创建新的LUT级联或移动现有的LUT级联以改进关键路径定时。这仅适用于Versal设备。
SLR交叉口优化
执行后置或后置路由优化,以提高SLR间的路径延迟连接。优化可调整SLR上驾驶员、负载或两者的位置十字路口如果驱动程序具有SLR间和SLR内,则在路由后优化中支持复制荷载。的-TNS_cleanup开关支持TNS清理选项-slr_crossing_opt开关。TNS清理允许在以下情况下对其他路径进行一些松弛降级只要设计的总体WNS不降低对于UltraScale设备,可以将TX_REG或RX_REG SLL寄存器作为目标。在里面UltraScale+设备,同一SLR间连接上的TX_REG和RX_REG寄存器可以
Laguna Hold-Fix优化
为UltraScale+设备执行SLL寄存器保持修复优化。当路由器在解决专用之间的SLR交叉路径上的保持冲突时遇到问题REG寄存器。
时钟优化
在关键路径起点和终点之间创建有用的倾斜。为了改善设置时间,缓冲区被插入以延迟目的地时钟。
路径组优化
仅对指定的路径组执行放置后和路由后优化。
提示:使用group_path Tcl命令设置要优化的路径组。
















 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











