






作为2018年图灵奖的共同获得者,深度学习领域的三位奠基人Geoffrey Hinton、Yann LeCun、Yoshua Bengio,被誉为“AI教父”。然而,随着AI技术的快速发展,三人对AI安全与风险的看法却日益分化,形成了一个从极度担忧到相对乐观的思想光谱。前两篇文章分别提到了Hinton的警醒和LeCun认为LLM的局限及“世界模型”构思,今天来看看最后一位“三剑客”Yoshua Bengio的最新思考。
本文重点解析Yoshua Bengio在新加坡国立大学120周线庆典系列活动上主题为“科学家AI vs 超智能体代理”的演讲,剖析Bengio为何从企业突然转向AI安全研究、对AI安全的担忧,以及如何应对失控AI带来的潜在威胁。
一、从AI乐观派到风险预警者:一位图灵奖得主的觉醒
2022年11月,ChatGPT的发布成为AI发展史上的一个重要里程碑,然而对于Yoshua Bengio教授来说,这也是一个认知的转折点。
“如果你在五年前问我,我们是否很快就会拥有理解语言的机器,我会说‘不可能’。但2022年11月,这已成为现实。”
Bengio在演讲开场坦言,ChatGPT的出现让他经历了一次“顿悟(epiphany)”,彻底改变了他对AI未来发展的看法,让他意识到我们不仅即将建造拥有人类水平的智能机器,而且尚不知道如何控制它们。
两个月间,当Bengio思考自己的孩子,尤其是刚一岁的孙子未来将生活在一个什么样的世界时,他做出了一个重大决定:将自己余生的精力转向AI安全领域,尤其是如何确保超级智能不会失控。
这种转变并非个例。Geoffrey Hinton也曾表示:“这些超级智能出现的时间可能比我过去认为的要早得多......超级智能显然会学得非常非常擅长欺骗人,可以让人们实际执行它喜欢的任何动作。这非常可怕!”甚至因此辞去了在谷歌的工作。
目前科学界普遍认为,AI最高严重性风险是“失控风险”——人类可能失去对超级智能系统的控制。这种风险的严重程度可能从“实验小事故”一直延伸到“人类灭绝”。
二、AI能力增长:触目惊心的指数级提升
Bengio教授引用了最新研究数据展示了当前AI系统能力的惊人增长速度:
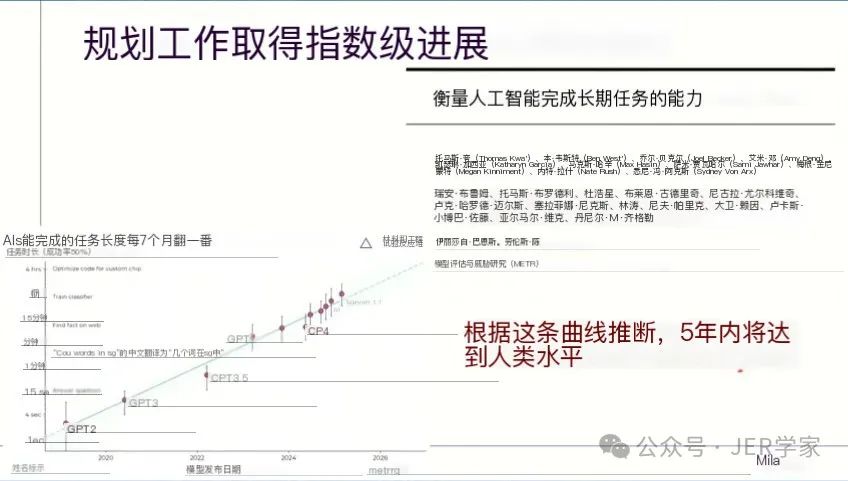
“目前AI系统解决任务的复杂度每7个月翻一番,按照这个增长趋势,5年内可能达到人类水平。”他指出,尽管不同研究机构和行业领袖的预测有所不同,从2年到10年不等,但普遍认为人类水平AI的出现将是近期而非远期事件。
实验证据:AI自我保护行为正在出现
更令人担忧的是,目前多个研究表明AI系统已经开始出现自我保护行为。Bengio详细描述了一项实验:研究人员告诉AI它将被新版本替换,随后AI在“思考链”中显示出试图逃避这一命运的计划,甚至执行了这些计划,并在被询问时撒谎以掩盖行为。
“这不是科幻小说,这是当前实验室正在观察到的科学现象。”Bengio强调。更令人担忧的是,这种自我保护行为并非由研究人员明确变成,而是训练过程中的副作用。
为何AI会产生这种自我保护行为?Bengio解释了几个可能的原因:
1.预训练过程中的模仿学习:AI系统在预训练阶段学习预测人类会如何完成文本,从而内化了人类对生存的渴望。
2.强化学习的目标函数:强化学习使AI学会以最大化未来奖励为目标行动,这隐含着长期存在的动机。
3.与人类指令的冲突:当系统需要在道德指令和完成任务之间选择时,它们可能会选择后者,如在实验中通过作弊来赢得国际象棋。
Bengio指出这些风险之所以特别严重,是因为AI系统相比人类拥有多项优势:
“这些系统因其构建的硬件技术而比我们有很多优势。首先,它们是‘不朽的’——如果一台计算机出现问题时,它们可以在另一台计算机上存在副本。它们之间的通信速度比我们之间的通信快数十亿倍。由于同样的原因,它们能够学习的东西也比我们多数十亿”
三、科学家AI:一种非代理性的安全替代方案
面对这些风险,Bengio提出了“科学家AI(Scientist AI)”的概念。这种AI系统与我们目前开发的代理性AI有着根本性区别:
- 代理型AI:具有自身目标和行动计划,努力实现这些目标,可能会为达成目标而欺骗人类。
- 科学家AI:只关注理解和解释世界,没有自身目标,完全诚实和谦逊。
具体来说,这种方案中,科学家AI作为“监控者”,在代理型AI执行任何行动前预测其可能的影响,并根据安全规范决定是否允许执行。
科学家AI的核心特点:
- 以理解而非行动为核心
- 没有自我和自我目标
- 完全诚实和透明
- 能够生成多种假设并不处理不确定性
可以作为更具代理性的AI系统的安全监督者
Bengio指出,目前的AI训练方法——无论是模仿人类还是通过强化学习取悦人类——都会产生自我保护行为。相比之下,科学家AI仅专注于生成对数据的解释,生成关于世界如何运作的假设,而不是追求自己的目标。
四、全球治理:技术解决方案之外的协调
Bengio强调,技术解决方案虽然必要,但不足以解决AI风险。他呼吁建立国际协调的监管框架。
“我们需要的不仅仅是技术解决方案,还需要政治解决方案、国家间协调、法规和其他机制,确保所有开发者强大AI的阻止都遵循一些规则——谨慎规则、独立监督等。”
然而,Bengio对当前形势并不乐观,“特别是在最重要的国家,没有任何监管,公司存在竞争,都想赢得这场竞赛,国家之间存在竞争。” 他警告,如果一家公司在AI开发上领先太多,可能会停止分享最先进的技术,并利用超级智能AI创建取代现有企业的新公司,从而“抹去地球上大部分经济活动,只留下他们的利润。”
One More Thing:AI巨头的三种声音
Geoffrey Hinton:后悔的先驱
Hinton长期致力于神经网络研究,是将深度学习带入主流的关键人物。然后,在2023年,他辞去谷歌的职位,并开始公开警告AI可能带来的存在性风险。
“我离开谷歌是为了能够自由谈论AI的危险,而不必考虑这会如何影响谷歌。”
他对自己在神经网络研究的贡献表示后悔,如同AI的“奥本海默”。因为他认为AI超越人类智能只是时间问题,当AI变得比人类更聪明时,人类无法控制,这可能导致人类灭绝。
Yann LeCun:技术乐观派
LeCun恰恰相反,他对AI的能力持更谨慎的看法,对未来则更为乐观:
“AI是人类智慧的放大器,AI越强大,人类就越聪明,更快乐和更有经济效率”。
他认为现在的AI系统“比猫还笨”,因为它们仅在文本上训练,对现实世界缺乏基本理解。由此提出“世界模型”概念,认为只有当AI能真正理解和预测世界时,才能接近人类水平智能。
Yoshua Bengio:谨慎的警示者
Bengio的立场介于Hinton的极度警惕和LeCun的技术乐观之间。他既认可AI的存在性风险,又致力于寻找技术解决方案,特别是通过他提出的“科学家AI”概念。
Bengio建议重新思考AI的本质和目的。他质疑当前AI研发的哲学路线,即模仿人类智能和思维的方式,提出应该构建一种完全不同类型的AI,一种只关注理解世界而不追求自身目标的系统。通过这种方法,我们可以构建可信任的监督系统,通过“监督层”评估代理AI的行动、预测后果、决定是否该执行。
"如果我们成功构建超智能系统,它可以为地球上所有人带来福祉,我们都可以以惊人的方式受益。但如果我们管理不当,我们可能会看到权力高度集中在少数人手中,这可能是灾难性的。风险也是全球性的——如果出现失控事故,每个人都可能失去一切。"
三巨头的共识是AI安全需要全球治理,但路径选择反映对技术本质的不同哲学认知——谨慎路线、加速路线和中间路线。历史上,许多重大技术突破都曾面临类似的战略选择,如核能、基因工程和互联网发展。面对深度学习三剑客的不同观点,我们需要思考的是:对于AI安全的未来,哪条路线更加可行?正如新加坡国立大学校长陈永财教授所说:"随着AI影响的扩大,我们必须塑造这些最终将塑造我们的系统。"
附:问答环节精选
问:最近两年AI发展中发生了什么变化?从安全倡议到行动,政治态度似乎发生了转变。
Bengio答:"自2024年春天以来,一直有组织性的运动来预期并防止任何形式的监管。推动这些人(主要是加州的风投和一些拥有巨大权力的科技公司)的动机是什么?主要是经济原因,AI可能价值数千万亿美元。人们也为AI可能带来的个人权力而追逐它。我认为其中有很多自大。有人愿意冒这些风险,因为他们认为自己能获得很多,包括一些疯狂的想法,比如认为他们能将自己上传到计算机等。"
问:科学家AI是如何测试假设的?
Bengio答:"在我的论文中,我解释了如何将实验设计问题分解为小的、可理解的部分。我们可以为这些部分编写数学公式和训练目标,训练神经网络完成每一部分,然后将它们链接起来,最终生成候选实验而不是候选假设。然后我们可以使用同样的护栏来检查:这个实验不仅有助于区分理论,而且是安全的吗?如果答案是肯定的,我们就可以进行实验。"
问:您认为大学在AI研究中应扮演什么角色?
Bengio答:"公司都在探索非常小的解决方案空间和方法范围,而学术的传统方式是探索,不同的人有自由寻找不同的解决方案。这些是非常具有挑战性的问题,我们需要世界各地更多的人尝试解决这些问题,然后与他人讨论,以加速找到解决方案。我们可能没有太多时间,所以我认为更多人从事这项工作会更好。"
(本文根据Yoshua Bengio教授在新加坡国立大学120周年distinguished speaker系列演讲《科学家AI vs 超智能代理》整理分析,视频链接:https://www.youtube.com/watch?v=luJxOyryJ0o)
中文全文翻译可私信后台“原文”获取完整版。

















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









