






扩散模型介绍 & 原理 & 应用
0. 背景介绍
为了更好的理解扩散模型,我们首先需要理解生成模型。人工智能生成内容(AI Generated Content,AIGC)近年来成为了非常前沿的一个研究方向,生成模型目前有四个流派,分别是
-
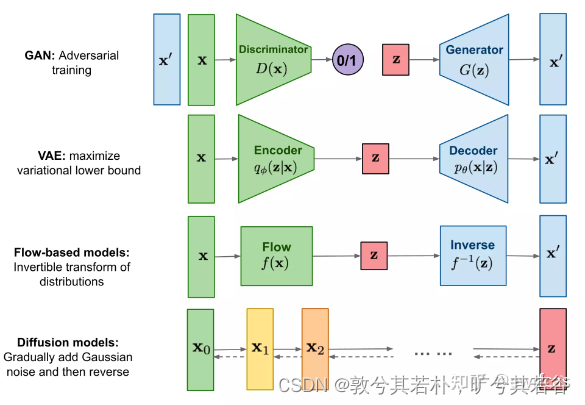
生成对抗网络(Generative Adversarial Models,GAN):生成对抗网络GAN通过一种生成对抗式的方式进行学习,其生成器G根据潜在空间的采样z生成图像x’,判别器D 则判断输入图像是真实图像x 还是生成图像x’
-
变分自编码器(Variance Auto-Encoder,VAE):变分自编码器VAE通过编码器学习图像分布p(x)到先验分布p(z)之间的转换,解码器学习p(z)到p(x)的转换关系,其在数学上可以被视为通过最大化ELBO进行优化;
-
标准化流模型(Normalization Flow,NF):标准化流模型则是通过构造一个可逆的变换,建立图像分布p(x)与某个已知分布p(z)的变换;
-
扩散模型(Diffusion Models,DM):其通过逐步增加高斯噪声将其变为纯高斯噪声z zz,再通过对z zz逐步去噪生成新的图像
它们之间的主要差异在于建模方式
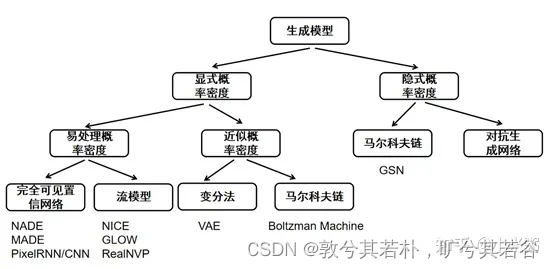
下面一幅图说明生成模型下面有多种生成方法
1. 什么是扩散模型
扩散模型是在2015年提出的,其动机来自非平衡态热力学。
扩散模型是一种生成模型,它通过模拟随机扩散过程,逐渐将随机噪声转变为目标数据分布,从而生成新的数据样本。
2. 扩散模型处理过程
简单地说,扩散模型就分为两个过程:“加噪”和“去噪”(也称为前向过程和逆向过程)。
- 加噪过程:不断地往输入数据中加入噪声,直到其就变成纯高斯噪声,每个时刻都要给图像叠加一部分高斯噪声。其中后一时刻是前一时刻增加噪声得到的。

- 去噪过程:由一个纯高斯噪声出发,逐步地去除噪声,得到一个满足训练数据分布的图片。

3. 扩散模型的基本原理
基于扩散模型的实例架构有GLIDE、DALLE-2、Imagen和完全开源的稳定扩散。
扩散模型由正向过程和反向过程这两部分组成,对应VAE中的编码和解码。在正向过程中,输入x0 会不断混入高斯噪声。经过T 次加噪声操作后,图像 xT 会变成一幅符合标准正态分布的纯噪声图像。而在反向过程中,我们希望训练出一个神经网络,该网络能够学会 T 个去噪声操作,把xT 还原回 x0。网络的学习目标是让 T 个去噪声操作正好能抵消掉对应的加噪声操作。训练完毕后,只需要从标准正态分布里随机采样出一个噪声,再利用反向过程里的神经网络把该噪声恢复成一幅图像,就能够生成一幅图片了。

图像生成网络会学习如何把一个向量映射成一幅图像。设计网络架构时,最重要的是设计学习目标,让网络生成的图像和给定数据集里的图像相似。VAE的做法是使用两个网络,一个学习把图像编码成向量,另一个学习把向量解码回图像,它们的目标是让复原图像和原图像尽可能相似。学习完毕后,解码器就是图像生成网络。扩散模型是一种更具体的VAE。它把编码过程固定为加噪声,并让解码器学习怎么样消除之前添加的每一步噪声。
4. 扩散模型的应用
- 计算机视觉:
- 图像生成:图像超分辨率和修复(Image Super Resolution and Inpainting)。图像超分辨率旨在从低分辨率 (LR) 图像中恢复高分辨率 (HR) 图像,而图像修复则是重建图像中缺失或损坏的区域。超分辨率扩散 (SRDiff) 是基于扩散的单图像超分辨率模型,通过数据可能性的变分界限进行了优化。
- 视频生成:在深度学习时代,由于视频帧的时空连续性和复杂性,高质量视频的生成仍然具有挑战性。最近的研究采用了扩散模型来提高生成视频的质量。灵活扩散模型 (FDM) 提出了一种基于 DDPM 的新视频生成框架,可在不同的现实场景中生成长期视频完成
- 自然语言处理:自然语言处理(Natural language processing)是旨在理解、建模和管理人类语言的研究领域。文本生成,也称为自然语言生成,已经成为自然语言处理中最关键和最具挑战性的任务之一
- 波信号处理:在电子学、声学和一些相关领域中,信号的波形通过图形形状来表示,它是时间的函数,与时间和量级无关。波形生成模型在语音生成任务中非常重要。WaveGrad 引入了用于估计数据密度梯度的波形生成条件模型
- 多模态学习
- 文本到图像生成:文本到图像生成是从描述性文本生成相应图像的任务,混合扩散利用预先训练的DDPM和CLIP模型,提出了一种通用的基于区域的图像编辑解决方案,该解决方案使用自然语言指导,适用于真实和多样的图像
- 文本到音频生成:文本到音频生成是将正常语言文本转换为语音输出的任务。Grad TTS提出了一种新的文本到语音模型,该模型具有基于分数的解码器和扩散模型
- 分子图建模:图形神经网络和相应的表示学习技术在许多领域取得了巨大成功,包括在从属性预测到分子生成的各种任务中建模分子图,其中分子由节点边图自然表示
- 时间序列建模
- 时间序列插补:由于多种原因,时间序列通常包含缺失值,这些原因是由机械或人为错误引起的,近年来,基于深度神经网络的插补方法在确定性插补和概率插补方面都取得了显著的成功
- 时间序列预测:时间序列预测是在一段时间内预报或推测未来值的任务。
- 对抗性净化: 表示一类使用生成模型消除对抗干扰的防御方法
5. 学习资料
| 标题 | 链接 |
|---|---|
| 扩散模型 | https://zh.wikipedia.org/wiki/%E6%89%A9%E6%95%A3%E6%A8%A1%E5%9E%8B |
| 扩散模型 | https://www.zhihu.com/question/26573810 |
| 一文详解扩散模型:DDPM | https://baijiahao.baidu.com/s?id=1761690033077829913&wfr=spider&for=pc |
| 人工智能中的扩散模型——你需要知道的一切 | https://www.unite.ai/zh-CN/diffusion-models-in-ai-everything-you-need-to-know/ |
| 一文速览扩散模型优化过程:从DDPM到条件生成模型Stable Diffusion | https://blog.csdn.net/qq_36560894/article/details/130851385 |
| 扩散模型的工作原理:从零开始的数学 | https://zhuanlan.zhihu.com/p/599538060 |
| 扩散模型:方法与应用综述(Diffusion Models: A Comprehensive Survey of Methods and Applications)金鱼马 | https://zhuanlan.zhihu.com/p/573627573 |


















 6688
6688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











